Command Palette
Search for a command to run...
أصدرت جامعة ستانفورد وأبل و23 مؤسسة أخرى معايير DCLM. هل يمكن لمجموعات البيانات عالية الجودة أن تهز قوانين التوسع؟ يعمل الطراز الأساسي على قدم المساواة مع Llama3 8B

مع استمرار الناس في الاهتمام بنماذج الذكاء الاصطناعي، أصبح النقاش حول قوانين التوسع ساخنًا بشكل متزايد.
اقترحت OpenAI لأول مرة قوانين التوسع في ورقة بحثية بعنوان "قوانين التوسع لنماذج اللغة العصبية" في عام 2020. ويُعتبر هذا بمثابة قانون مور لنماذج اللغة الكبيرة. ويمكن تلخيص معناها باختصار على النحو التالي:مع زيادة حجم النموذج وحجم مجموعة البيانات وعدد العمليات الحسابية ذات الفاصلة العائمة (المستخدمة للتدريب)، سيتحسن أداء النموذج.
تحت تأثير قوانين التوسع، لا يزال العديد من المتابعين يعتقدون أن "الكبير" لا يزال هو المبدأ الأول لتحسين أداء النموذج. تعتمد الشركات الكبيرة ذات الموارد المالية الكبيرة بشكل خاص على مجموعات البيانات الكبيرة والمتنوعة.
وفي هذا الصدد، يقول تشين يوجيا، الحاصل على درجة الدكتوراه: أشار أحد الباحثين من قسم علوم الحاسوب بجامعة تسينغهوا إلى أن "نموذج LLaMA 3 يُظهر لنا واقعًا متشائمًا: لا حاجة لتغيير بنية النموذج، وزيادة حجم البيانات من 2 تيرا بايت إلى 15 تيرا بايت يُمكن أن تُحدث فرقًا كبيرًا. من جهة، يُشير هذا إلى أن النموذج الأساسي يُمثل فرصة للشركات الكبرى على المدى الطويل؛ ومن جهة أخرى، وبالنظر إلى التأثير الهامشي لقوانين التوسع، إذا أردنا أن نرى الجيل التالي من النماذج يُظهر تحسينات من GPT3 إلى GPT4، فقد نحتاج إلى إزالة ما لا يقل عن 10 أوامر من حيث الحجم من البيانات الإضافية (على سبيل المثال، 150 تيرا بايت)."

ردًا على الزيادة المستمرة في كمية البيانات المطلوبة لتدريب نموذج اللغة وقضايا مثل جودة البيانات، اقترحت 23 مؤسسة، بما في ذلك جامعة واشنطن وجامعة ستانفورد وشركة Apple، منصة اختبار تجريبية DataComp لنماذج اللغة (DCLM). إن جوهر هذه المنصة هو مفردات المرشح الجديدة 240T من Common Crawl. من خلال إصلاح كود التدريب، يتم تشجيع الباحثين على اقتراح مجموعات تدريب جديدة للابتكار، وهو أمر ذو أهمية كبيرة لتحسين مجموعات تدريب نماذج اللغة.
تم نشر بحث ذي صلة على المنصة الأكاديمية تحت عنوان "DataComp-LM: بحثًا عن الجيل القادم من مجموعات التدريب لنماذج اللغة" http://arXiv.org أرقى.
أبرز ما جاء في البحث
* يمكن للمشاركين في معيار DCLM تجربة استراتيجيات إدارة البيانات على نماذج تتراوح من 412 مليون إلى 7 مليارات معلمة
* يعد التصفية القائمة على النموذج هي المفتاح لبناء مجموعات تدريب عالية الجودة. تدعم مجموعة البيانات المولدة DCLM-BASELINE تدريب نموذج لغة المعلمات 7B من الصفر على MMLU باستخدام رموز تدريب 2.6T، مما يحقق دقة 5 طلقات تبلغ 64%
* يعمل نموذج DCLM الأساسي بشكل مماثل مع Mistral-7B-v0.3 وLlama3 8B على MMLU

عنوان الورقة:
https://arxiv.org/pdf/2406.11794v3
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
معيار DCLM: تصميم متعدد المقاييس من 400M إلى 7B لتلبية متطلبات مقياس الحوسبة المختلفة
DCLM عبارة عن منصة تجريبية لمجموعة البيانات لتحسين نماذج اللغة وهي المعيار الأول لإدارة بيانات تدريب نموذج اللغة.
كما هو موضح في الشكل أدناه،يتكون سير عمل DCLM بشكل أساسي من أربع خطوات: تحديد مقياس، وبناء مجموعة بيانات، وتدريب نموذج، وتقييم النموذج بناءً على 53 مهمة لاحقة.
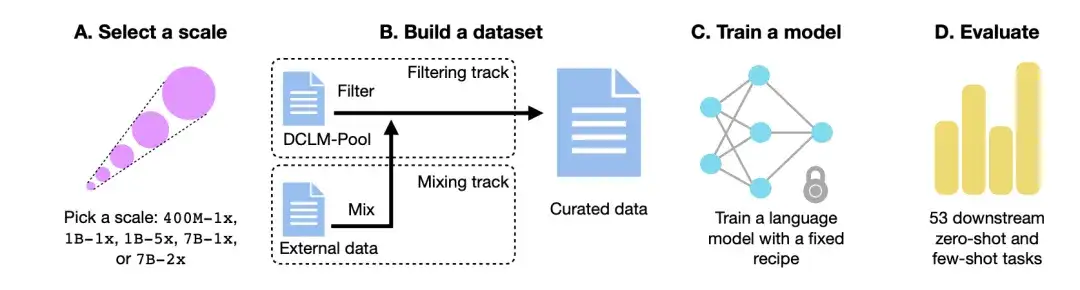
اختر مقياس الحوسبة
أولاً، من حيث مقياس الحوسبة، أنشأ الباحثون خمسة مستويات مختلفة للمنافسة تمتد على ثلاثة أوامر من حيث حجم مقياس الحوسبة. يحدد كل مستوى (أي 400M-1x، و1B-1x، و1B-5x، و7B-1x، و7B-2x) مقدار معلمة النموذج (على سبيل المثال، 7B) ومضاعف شينشيلا (على سبيل المثال، 1x). عدد رموز التدريب لكل حجم هو 20 مرة عدد المعلمات مضروبًا في مضاعف شينشيلا.
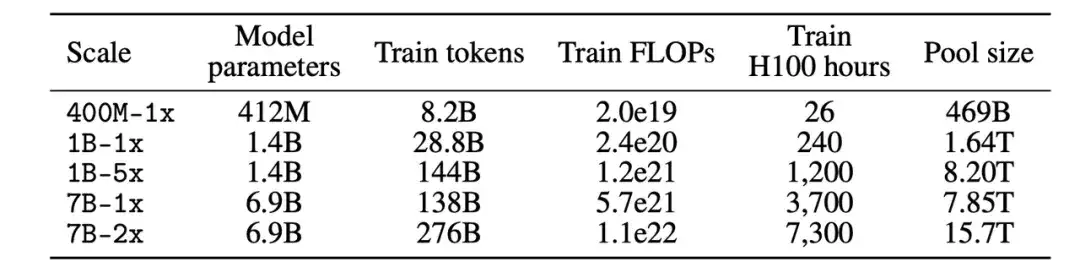
بناء مجموعة بيانات
ثانياً، بعد تحديد مقياس المعلمة، في عملية بناء مجموعة البيانات، يمكن للمشاركين إنشاء مجموعة بيانات عن طريق تصفية (Filter) أو خلط (Mix) البيانات.
في مسار التصفية،قام الباحثون باستخراج مجموعة موحدة من 240T من الرموز من موقع الزاحف غير المفلتر Common Crawl، وقاموا ببناء DCLM-Pool، وقسموها إلى 5 مجموعات بيانات وفقًا لمقياس الحوسبة. يقترح المشاركون خوارزميات ويختارون بيانات التدريب من مجموعة البيانات.
في مسار المزيج،يتمتع المشاركون بحرية الجمع بين البيانات من مصادر متعددة. على سبيل المثال، قم بتجميع مستندات البيانات من DCLM-Pool، والبيانات المخصصة التي تم الزحف إليها، وStack Overflow، وWikipedia.
تدريب النموذج
OpenLM هي مكتبة أكواد تعتمد على PyTorch وتركز على وحدة FSDP للتدريب الموزع. ولإزالة تأثير تداخل مجموعة البيانات، استخدم الباحثون طريقة ثابتة لتدريب النموذج عند كل مقياس بيانات.
استنادًا إلى دراسات الاستئصال السابقة حول بنية النموذج والتدريب، اعتمد الباحثون بنية المحول التي تعتمد على فك التشفير فقط مثل GPT-2 وLlama، وأخيرًا قاموا بتدريب النموذج في OpenLM.
تقييم النموذج
أخيرا،قام الباحثون بتقييم النموذج باستخدام سير عمل LLM-Foundry، باستخدام 53 مهمة لاحقة مناسبة لتقييم النموذج الأساسي.تتضمن هذه المهام اللاحقة الإجابة على الأسئلة، والتوليد المفتوح، وتغطي مجموعة متنوعة من المجالات مثل الترميز، ومعرفة الكتب المدرسية، والتفكير السليم.
لتقييم خوارزمية معالجة البيانات، ركز الباحثون على ثلاثة مؤشرات للأداء: دقة MMLU 5-shot، ودقة مركز CORE، ودقة المركز EXTENDED.
مجموعة البيانات: استخدم DCLM لبناء مجموعات بيانات تدريبية عالية الجودة
كيف تقوم DCLM ببناء مجموعة البيانات عالية الجودة DCLM-BASELINE وتحديد مدى فعالية أساليب إدارة البيانات؟
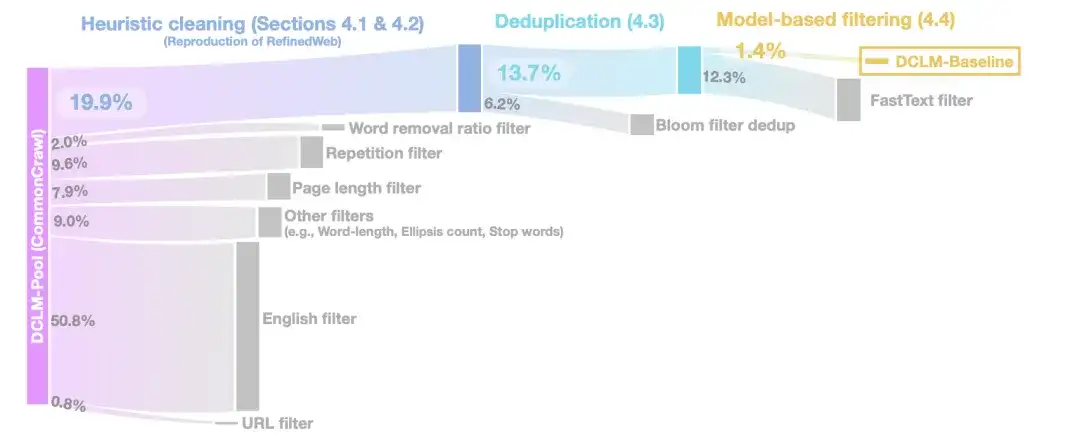
في مرحلة التنظيف الاستدلالي،استخدم الباحثون طريقة RefinedWeb لتنظيف البيانات، بما في ذلك إزالة عناوين URL (فلتر URL)، ومرشحات اللغة الإنجليزية (فلتر اللغة الإنجليزية)، ومرشحات طول الصفحة (فلتر طول الصفحة)، ومرشحات المحتوى المكرر (فلتر التكرار).
في مرحلة إزالة التكرار،استخدم الباحثون مرشحات بلوم لإزالة التكرارات من بيانات النص المستخرجة ووجدوا أن مرشحات بلوم المعدلة كانت قابلة للتوسع بسهولة أكبر إلى مجموعات بيانات بحجم 10 تيرابايت.
لتحسين جودة البيانات بشكل أكبر،في مرحلة التصفية القائمة على النموذج، قام الباحثون بمقارنة سبع طرق تصفية قائمة على النموذج.بما في ذلك التصفية باستخدام درجات PageRank، وإزالة التكرار الدلالي (SemDedup)، ومصنف fastText الثنائي، وما إلى ذلك، وجد أن التصفية القائمة على fastText تفوقت على جميع الطرق الأخرى.
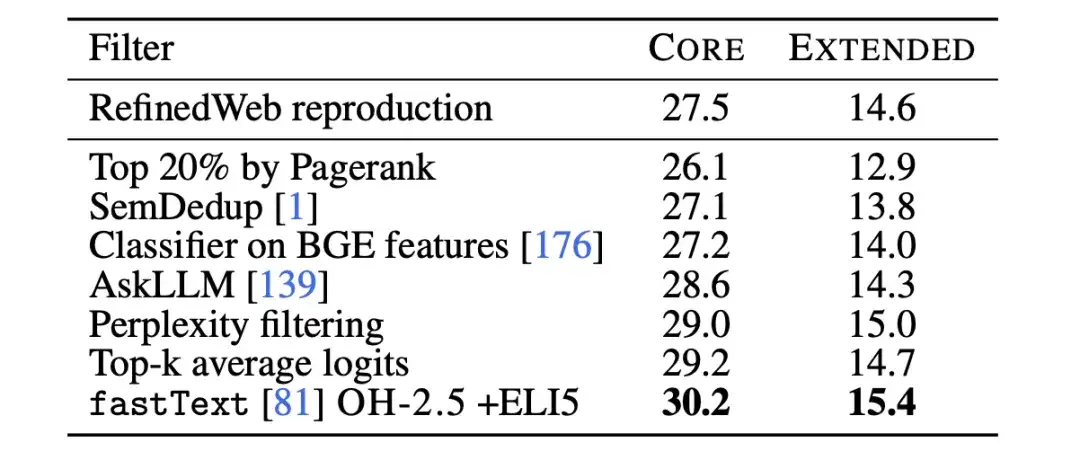
وبعد ذلك، استخدم الباحثون عمليات حذف مصنف النص لمزيد من دراسة القيود المفروضة على تصفية البيانات استنادًا إلى fastText. قام الباحثون بتدريب العديد من المتغيرات المختلفة، واستكشاف خيارات مختلفة لبيانات المرجع، ومساحة الميزة، وعتبات التصفية، كما هو موضح في الشكل أدناه. بالنسبة لبيانات المرجع، اختار الباحثون موسوعة ويكيبيديا الشائعة الاستخدام، وOpenWebText2، وRedPajama-books، وهي كلها بيانات مرجعية يستخدمها GPT-3.
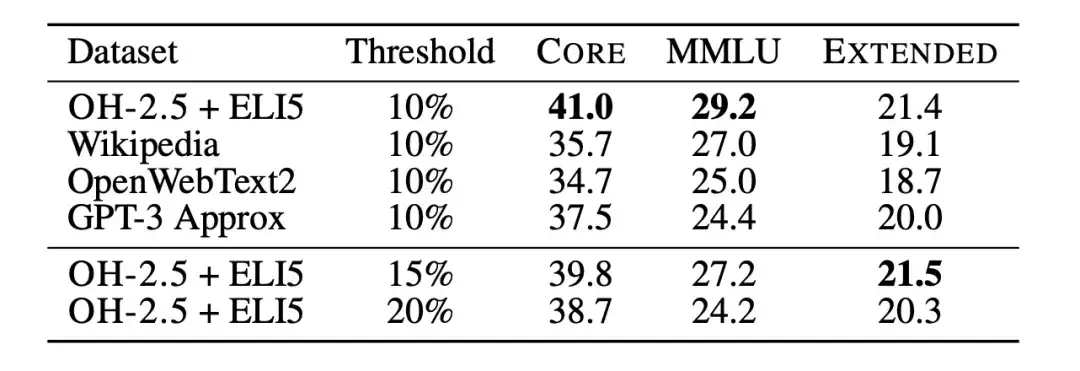
في نفس الوقت،كما استخدم الباحثون البيانات بشكل مبتكر في شكل تعليمات، واستخرجوا أمثلة من المنشورات ذات الدرجات العالية في subreddits OpenHermes 2.5 (OH-2.5) و r/ExplainLikeImFive (ELI5).وتظهر النتائج أن طريقة OH-2.5 + ELI5 تعمل على تحسين 3.5% على CORE مقارنة ببيانات المرجع المستخدمة بشكل شائع.
وبالإضافة إلى ذلك، وجد الباحثون أن عتبة صارمة (أي عتبة 10%) يمكن أن تحقق أداء أفضل. لذا،استخدم الباحثون درجات تصنيف fastText OH-2.5 + ELI5 لتصفية البيانات، مع الاحتفاظ بأول مستندات 10% للحصول على DCLM-BASELINE.
نتائج البحث: التصفية القائمة على النموذج هي المفتاح لإنشاء مجموعات بيانات عالية الجودة
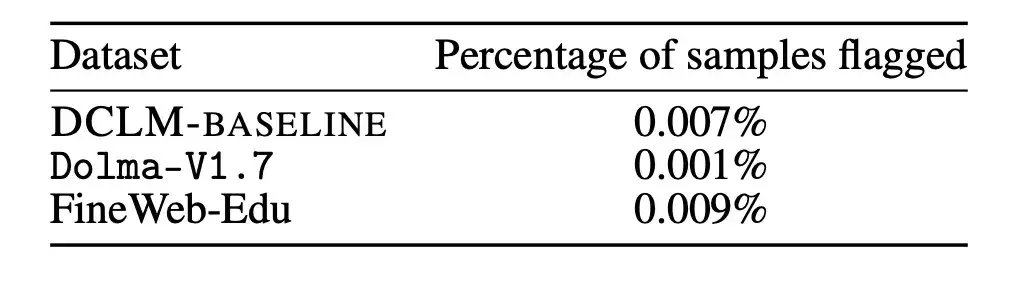
أولاً، قام الباحثون بتحليل ما إذا كان تلوث بيانات التدريب المسبق غير المقيمة يمكن أن يؤثر على النتائج.
يعد اختبار MMLU معيارًا لقياس أداء نماذج اللغة الكبيرة، ويهدف إلى فحص قدرة النموذج على فهم اللغات المختلفة بشكل أكثر شمولاً. لذلك، استخدم الباحثون MMLU كمجموعة تقييم وقاموا باكتشاف وإزالة المشاكل الموجودة في DCLM-BASELINE من MMLU. قام الباحثون بعد ذلك بتدريب نموذج 7B-2x استنادًا إلى DCLM-BASELINE دون استخدام تداخل MMLU المكتشف.
وتظهر النتائج في الشكل أدناه. إن إزالة العينات الملوثة لا يؤدي إلى انخفاض أداء النموذج. ومن هذا يمكن أن نرى أنإن التحسن في أداء DCLM-BASELINE على معيار MMLU لا يرجع إلى تضمين البيانات في MMLU في مجموعة البيانات الخاصة به.

بالإضافة إلى ذلك، قام الباحثون أيضًا بتطبيق استراتيجية الإزالة المذكورة أعلاه على Dolma-V1.7 وFineWeb-Edu لقياس الاختلافات في التلوث بين DCLM-BASELINE وهذه المجموعات من البيانات. وجد أن إحصائيات التلوث الخاصة بـ DLCM-BASELINE متشابهة تقريبًا مع إحصائيات مجموعات البيانات الأخرى عالية الأداء.
ثانيًا، قام الباحثون أيضًا بمقارنة النموذج الجديد المدرب مع نماذج أخرى بمقياس المعلمات 7B-8B. تظهر النتائج أن النموذج الذي تم إنشاؤه بناءً على مجموعة بيانات DCLM-BASELINE يتفوق على النماذج المدربة على مجموعات البيانات مفتوحة المصدر ويتنافس مع النماذج المدربة على مجموعات البيانات مغلقة المصدر.
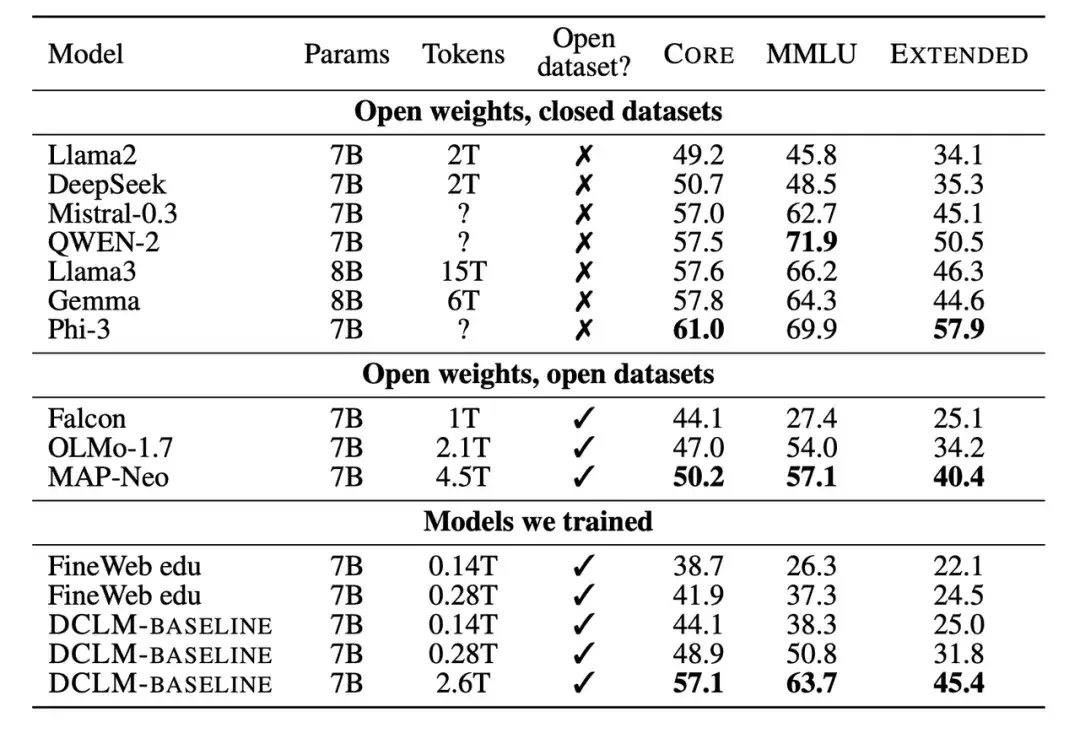
يظهر عدد كبير من النتائج التجريبية أنيعد التصفية القائمة على النموذج أمرًا أساسيًا لتشكيل مجموعة بيانات عالية الجودة، كما أن تصميم مجموعة البيانات مهم جدًا لتدريب نماذج اللغة.تدعم مجموعة البيانات المولدة DCLM-BASELINE تدريب نموذج لغة المعلمات 7B من الصفر على MMLU باستخدام رموز تدريب 2.6T، مما يحقق دقة 5 طلقات تبلغ 64%.
بالمقارنة مع نموذج لغة البيانات المفتوحة الأكثر تقدمًا السابق MAP-Neo،تعمل مجموعة البيانات المولدة DCLM-BASELINE على تحسين MMLU بمقدار 6.6 %، مع تقليل مقدار الحساب المطلوب للتدريب بمقدار 40%.
النموذج الأساسي لـ DCLM قابل للمقارنة مع Mistral-7B-v0.3 و Llama3 8B على MMLU (63% و 66%)، ويؤدي بشكل مماثل في 53 مهمة فهم اللغة الطبيعية، ولكنه يتطلب 6.6 مرات أقل من الحسابات للتدريب من Llama3 8B.
قوانين التوسع: الاتجاه المستقبلي غير واضح، والبحث عن الجيل التالي من مجموعات التدريب لنماذج اللغة
باختصار، يتمثل جوهر DCLM في تشجيع الباحثين على بناء مجموعات تدريبية عالية الجودة من خلال التصفية القائمة على النموذج، وبالتالي تحسين أداء النموذج. وهذا يوفر أيضًا نهجًا جديدًا لحل المشكلات في ظل اتجاه التدريب النموذجي "الكبير جميل".
كما يقول تشين يوجيا، الحاصل على درجة الدكتوراه. من قسم علوم الكمبيوتر في جامعة تسينغهوا، قال: "لقد حان الوقت لتقليص حجم البيانات". من خلال تحليل وتلخيص أوراق بحثية متعددة، وجد أن "البيانات النظيفة بعد التنظيف + نموذج أصغر يمكن أن تكون أقرب إلى تأثير البيانات المتسخة + نموذج كبير".
في أوائل شهر يوليو/تموز، ذكر بيل جيتس موضوع التحول النموذجي في تكنولوجيا الذكاء الاصطناعي في الحلقة الأخيرة من البودكاست Next Big Idea، وأعرب عن اعتقاده بأن قوانين التوسع تقترب من نهايتها. لم تصل بعد ثورة الذكاء الاصطناعي في التفاعل مع الكمبيوتر، لكن تقدمها الحقيقي يكمن في تحقيق قدرات معرفية أقرب إلى البشر، وليس مجرد زيادة حجم النموذج.

قبل ذلك، أجرى العديد من قادة الصناعة المحلية مناقشات معمقة حول الاتجاه المستقبلي لقوانين التوسع في مؤتمر بكين تشي يوان 2024.
قال كاي فو لي، الرئيس التنفيذي لشركة Zero One Everything، إن قانون التوسع أثبت فعاليته ولم يصل إلى ذروته بعد، ولكن لا يمكن استخدام قانون التوسع لتكديس وحدات معالجة الرسوميات بشكل أعمى. إن الاعتماد ببساطة على تجميع المزيد من قوة الحوسبة لتحسين تأثيرات النموذج لن يؤدي إلا إلى فوز الشركات أو البلدان التي لديها ما يكفي من وحدات معالجة الرسوميات.
قال تشانغ يا تشين، عميد معهد الصناعات الذكية بجامعة تسينغهوا، إن تحقيق قانون التوسع يرجع بشكل أساسي إلى استخدام البيانات الضخمة والتحسين الكبير في قوة الحوسبة. وسيظل هذا هو الاتجاه الرئيسي للتنمية الصناعية في السنوات الخمس المقبلة.

يعتقد الرئيس التنفيذي لشركة Dark Side of the Moon يانغ تشيلين أنه لا توجد مشكلة جوهرية في قانون التوسع. طالما أن هناك المزيد من قوة الحوسبة والبيانات، وأصبحت معلمات النموذج أكبر، يمكن للنموذج الاستمرار في توليد المزيد من الذكاء. ويعتقد أن قانون التوسع سوف يستمر في التطور، ولكن أساليب قانون التوسع قد تتغير بشكل كبير في هذه العملية.
ويعتقد وانغ شياو تشوان، الرئيس التنفيذي لشركة بايتشوان إنتليجنس، أنه بالإضافة إلى قانون التوسع، يتعين علينا البحث عن تحولات جديدة في قوة الحوسبة، والخوارزميات، والبيانات، وغيرها من النماذج، بدلاً من تحويلها ببساطة إلى ضغط المعرفة. لا يمكننا أن نحظى بفرصة التحرك نحو الذكاء الاصطناعي العام إلا من خلال الخروج من هذا النظام.
يعود نجاح النماذج الكبيرة إلى حد كبير إلى وجود قوانين التوسع، والتي توفر إرشادات قيمة لتطوير النماذج، وتخصيص الموارد، واختيار بيانات التدريب المناسبة. ربما لا نعرف حتى الآن ما هي نهاية قوانين القياس، ولكن معيار DCLM يوفر نموذج تفكير جديد وإمكانية لتحسين أداء النموذج.
مراجع:
https://arxiv.org/pdf/2406.11794v3
https://arxiv.org/abs/2001.08361








