Command Palette
Search for a command to run...
تم اختياره ل ICML! استخدم فريق جامعة رينمين الشبكة العصبية ذات الرسم البياني المتغير المتساوي للتنبؤ بمواقع ربط البروتين المستهدف، مع أعلى تحسن في الأداء لـ 20%
في الأنظمة الحية، تتضمن جميع العمليات البيولوجية والدوائية تقريبًا تفاعلات بين المستقبلات (البروتينات المستهدفة) والربيطات (الجزيئات الصغيرة). تحدث هذه التفاعلات في مناطق محددة من بنية البروتين المستهدف.تُعرف باسم "مواقع الارتباط" - حيث يلعب التنبؤ بمواقع ارتباط البروتينات المستهدفة دورًا أساسيًا في العديد من المهام اللاحقة مثل اكتشاف الأدوية.
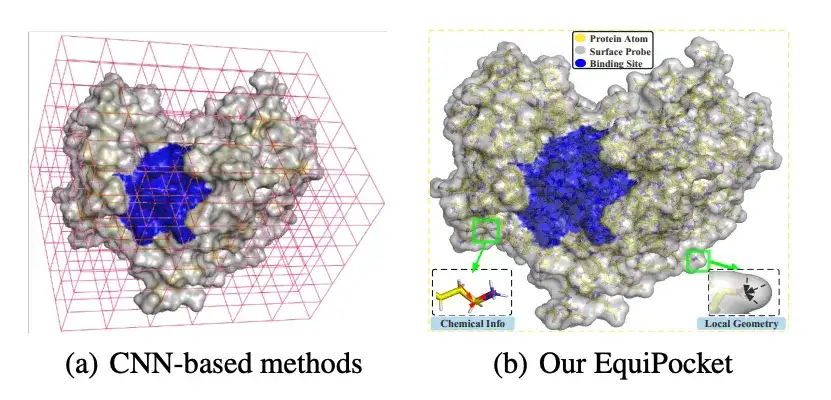
في السنوات الأخيرة، وبفضل التقدم الهائل في مجال التعلم العميق، تم تطبيق الشبكات العصبية التلافيفية (CNNs) بنجاح في التنبؤ بموقع ربط الربيطة. تتعامل الطرق المعتمدة على CNN مع البروتينات كصور ثلاثية الأبعاد عن طريق تجميع ذرات البروتينات مكانيًا في أقرب وحدات بكسل، ثم نمذجة توقع موقع الارتباط كمشكلة في اكتشاف الكائنات أو مهمة تقسيم دلالي على شبكة ثلاثية الأبعاد. تتمتع هذه الأساليب بمزايا معينة، ولكن لا تزال هناك تحديات، مثلإنها تعاني من عيوب في تمثيل الهياكل البروتينية غير المنتظمة؛ فهو حساس للدوران؛ فهو لا يصف بشكل كاف السمات الهندسية لأسطح البروتين؛ وهو غير حساس للتغيرات في حجم البروتين.
ولتحقيق هذه الغاية، نشر فريق بحثي من كلية جاولينج للذكاء الاصطناعي بجامعة رينمين الصينية مؤخرًا ورقة بحثية بعنوان "EquiPocket: شبكة عصبية هندسية متكافئة المتغيرات E(3) للتنبؤ بموقع ربط الربيطة" في مؤتمر ICML 2024، وهو المؤتمر الأكاديمي الأبرز في مجال الذكاء الاصطناعي. هذه الدراسة هي الأولى التي تطبق شبكة عصبية بيانية متماثلة E (3) (GNN) للتنبؤ بموقع ربط الربيطة.اقترح إطار عمل يسمى EquiPocket،تمت معالجة التحديات التي تواجهها الأساليب المعتمدة على CNN.
أبرز الأبحاث:
* أول تطبيق لـ GNN المتماثل E (3) للتنبؤ بموقع ربط الربيطة
* بالمقارنة مع الطرق التقليدية القائمة على CNN، لا يتطلب EquiPocket التكعيب، ويمكنه نمذجة هياكل البروتين غير المنتظمة، وهو غير حساس لأي تحويل إقليدي، وبالتالي حل التحديات مثل "العيوب في تمثيل هياكل البروتين غير المنتظمة" و"الحساسية للدوران"
* أظهرت التجارب المكثفة على طرق المقارنة التمثيلية تفوق EquiPocket على الطرق الحديثة المتطورة، والتي يمكن أن تكون مفيدة للعديد من المهام اللاحقة مثل اكتشاف الأدوية
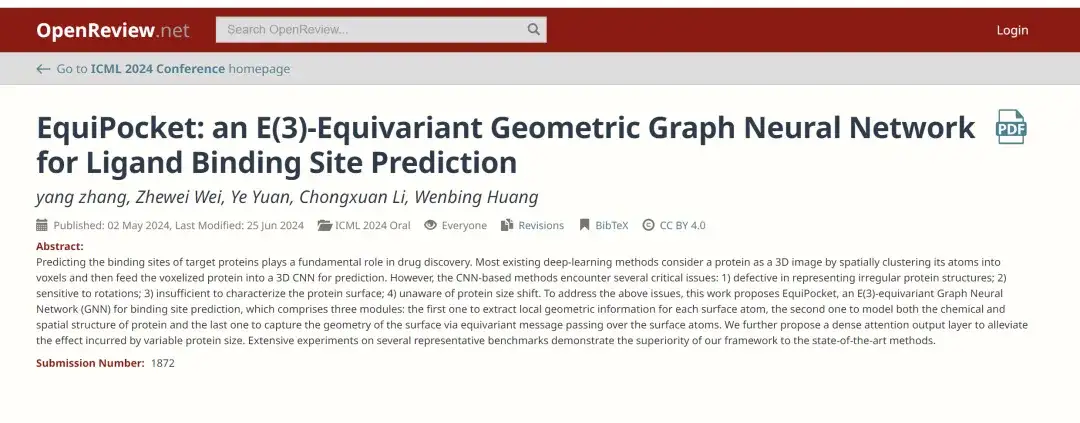
عنوان الورقة:
https://openreview.net/forum?id=1vGN3CSxVs
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
مجموعة البيانات: التحقق الشامل من مجموعات البيانات المهنية المتعددة
قام الباحثون باختيار العديد من مجموعات البيانات المتخصصة وتقييمها باستخدام مجموعة فرعية من mlig من كل مجموعة بيانات تحتوي على ربيطات ذات صلة للتنبؤ بموقع الارتباط.
في،scPDB عبارة عن مجموعة بيانات معروفة للتنبؤ بموقع الارتباط.يحتوي على البروتين والربيطة وهياكل تجويف ثلاثية الأبعاد التي تم إنشاؤها بواسطة VolSite. استخدمت هذه الدراسة إصدار عام 2017 للتدريب والتحقق المتبادل، والذي يحتوي على 17,594 بنية، و16,034 إدخالاً، و4,782 بروتينًا، و6,326 ربيطة.
PDBbind هي مجموعة بيانات شائعة الاستخدام لدراسة مجمعات البروتين والربيطة.يحتوي على البنية ثلاثية الأبعاد للبروتين والربيطة وموقع الارتباط ونتائج تقارب الارتباط الدقيقة التي تم تحديدها في المختبر. استخدمت هذه الدراسة إصدار 2020 للتقييم، والذي يتكون من جزأين: مجموعة مشتركة (14127 مجمعًا) ومجموعة مُحسّنة (5316 مجمعًا). تحتوي المجموعة العامة على جميع مجمعات البروتين والربيطة، وتقوم المجموعة المكررة باختيار المركبات ذات الجودة الأفضل من المجموعة العامة للاختبار التجريبي.
COACH 420 وHOLO4K هما مجموعتان من البيانات الاختبارية المستخدمة للتنبؤ بموقع الارتباط.تم تقديمه لأول مرة بواسطة (Krivák & Hoksza، 2018).
هندسة النموذج: يتكون الإطار العام لـ EquiPocket من ثلاث وحدات
يتكون الإطار العام لـ EquiPocket من 3 وحدات:كما هو موضح في الشكل التالي:
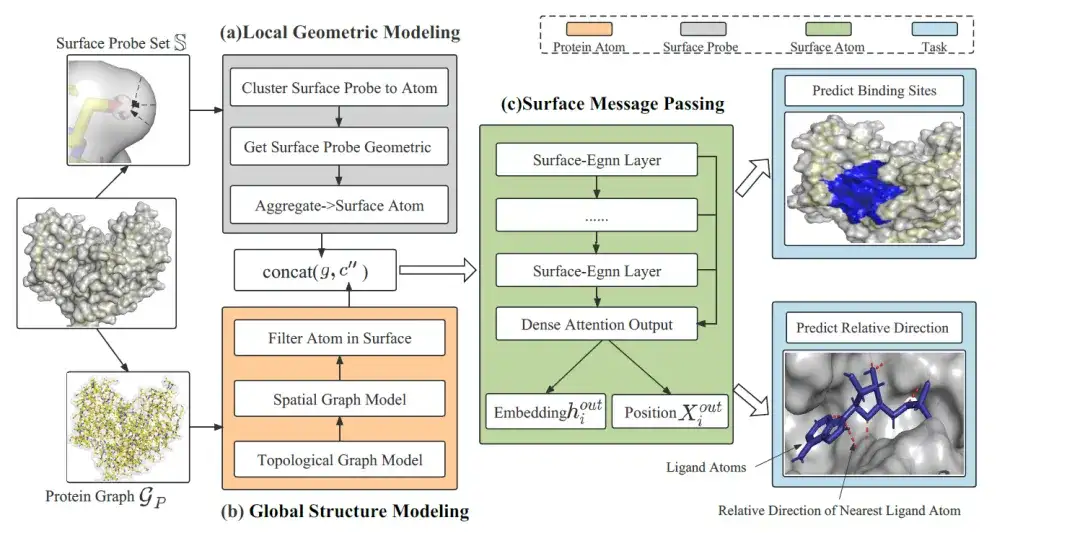
الوحدة الأولى هي وحدة النمذجة الهندسية المحلية، والتي تستخدم لاستخراج المعلومات الهندسية المحلية لكل ذرة سطحية؛ الوحدة الثانية هي وحدة نمذجة البنية العالمية، والتي تستخدم لوصف البنية الكيميائية والمكانية للبروتينات؛ الوحدة الأخيرة هي وحدة تمرير الرسائل السطحية، والتي تلتقط هندسة السطح عن طريق إرسال معلومات متماثلة على ذرات السطح.
وحدة نمذجة الهندسة المحلية
يحدد الشكل الهندسي المحلي لكل ذرة بروتين ما إذا كانت المنطقة القريبة منها مناسبة لتكون جزءًا من موقع الارتباط.
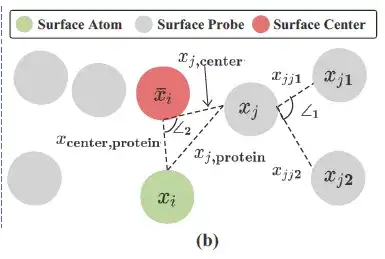
وكما هو موضح في الشكل أعلاه، استخدم الباحثون مجسات سطحية (باللون الرمادي في الشكل أعلاه) حول كل ذرة سطحية من ذرات البروتين (الذرة السطحية، باللون الأخضر في الشكل أعلاه) لوصف المعلومات الهندسية المحلية. على وجه التحديد، بالنسبة لكل ذرة سطح i ∈ VS، يتم إرجاع المجسات السطحية حولها بواسطة مجموعة فرعية من S، وهي:
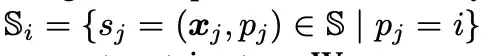
قام الباحثون ببناء معلومات هندسية على أساس Si وسجلوا قيمة المركز/المتوسط لجميع إحداثيات 3D في Si (مركز السطح، باللون الأحمر في الشكل أعلاه) على أنها xi¯.
وحدة النمذجة الهيكلية العالمية
على الرغم من أن مواقع الارتباط تتكون في المقام الأول من ذرات السطح، فإن البنية العامة للبروتين غالبًا ما تؤثر على تفاعلات الربيطة بالإضافة إلى تكوين موقع الارتباط وبالتالي تحتاج إلى نمذجة.
وتمكن الباحثون من تحقيق هذا الهدف من خلال عمليتين مترابطتين: النمذجة الكيميائية البيانية والنمذجة المكانية البيانية. تكون وحدة النمذجة البنيوية العالمية الناتجة مسؤولة عن معالجة المعلومات حول البروتين بأكمله، بما في ذلك أنواع الذرات، والروابط الكيميائية، والمواقع المكانية النسبية، وما إلى ذلك.
وحدة نقل المعلومات السطحية
نظرًا للميزات الهندسية المحلية لذرات السطح وميزات الترميز العالمية، ستقوم هذه الوحدة بنقل المعلومات المتغيرة على خريطة السطح لتحديث جميع ميزات ذرات سطح البروتين.
نتائج البحث: EquiPocket يحسن الأداء بمقدار 10-20% مقارنة بالنماذج الأساسية
في التجربة، اختار الباحثون مقارنة EquiPocket مع النماذج الأساسية التالية:
* الأساليب القائمة على الهندسة: Fpocket
* طريقة التعلم الآلي: P2rank
* الطرق المعتمدة على CNN: DeepSite، Kalasanty، DeepSurf، RecurPocket
* النماذج القائمة على الطوبولوجيا: GAT وGCN وGCN2
* النماذج القائمة على الرسم البياني المكاني: SchNet، EGNN
تتضمن المقاييس المستخدمة لتقييم النموذج DCC (المسافة بين مركز موقع الارتباط المتوقع ومركز موقع الارتباط الحقيقي)، وDCA (أقصر مسافة بين مركز موقع الارتباط المتوقع وأي شبكة ربيطة)، ومعدل الفشل (معدل أخذ العينات بدون أي مركز موقع ارتباط متوقع). يوضح الجدول أدناه نتائج التنبؤ بموقع الارتباط على COACH 420 وHOLO4K وPDBbind.
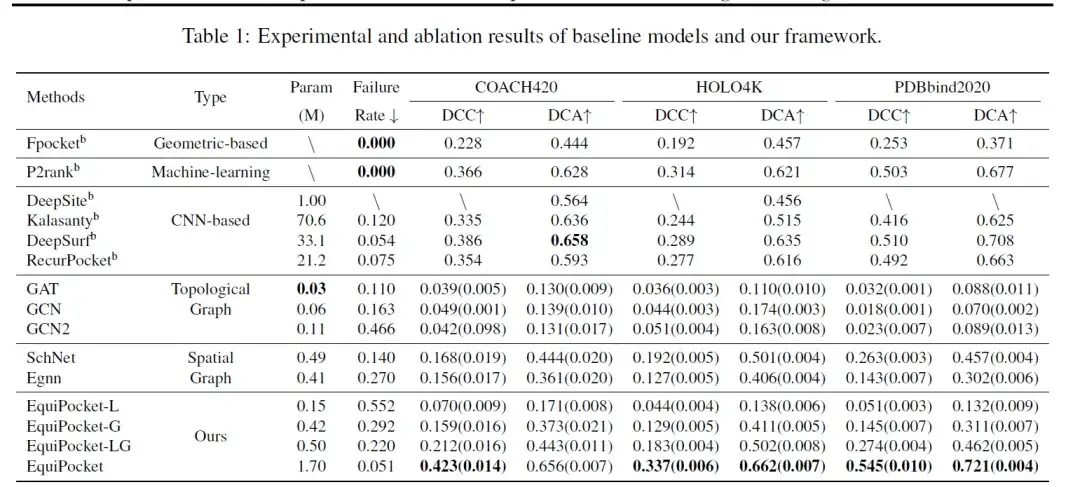
كما هو موضح في البيانات الموجودة في الجدول،طريقة Fpocket المعتمدة على الهندسة لها أداء ضعيف.نظرًا لأن هذه الطريقة تستخدم فقط السمات الهندسية للبروتين، فإن معدل الفشل هو 0؛ تجمع طريقة التعلم الآلي P2rank بين الغابات العشوائية والمعلومات الهندسية لسطح البروتين، مما يؤدي إلى تحسين الأداء بشكل كبير.
تحقق الطرق المعتمدة على CNN (DeepSite، Kalasanty، DeepSurf، RecurPocket) أداءً أفضل بكثير من الطرق المعتمدة على الهندسة.ومن بينها، تعمل DCC وDCA على تحسين أكثر من 50%، ولكنها تتطلب عددًا كبيرًا من المعلمات وموارد الحوسبة. ومن بين هذه الطرق المقترحة سابقًا DeepSite وKalasanty محدودة بسبب اختلاف حجم البروتين وعدم القدرة الكافية على التعامل مع البروتينات الكبيرة، مما قد يؤدي إلى فشل التنبؤ.
بالنسبة لنماذج الرسم البياني،أداء نماذج الرسم البياني الطوبولوجي (GCN، GAT، GCN2) ضعيف.يرجع ذلك أساسًا إلى أنهم يأخذون في الاعتبار فقط معلومات الرابطة الذرية والكيميائية ويتجاهلون البنية المكانية للبروتينات؛ عادةً ما يكون أداء نماذج الرسم البياني المكاني (SchNet، EGNN) أفضل من أداء نماذج الرسم البياني الطوبولوجي. يستخدم EGNN خصائص الذرات بالإضافة إلى مواقعها المكانية النسبية/المطلقة، وهو ما يعمل بشكل أفضل؛ تقوم SchNet بتحديث التضمينات بناءً على المسافات النسبية للذرات فقط، ولكن أداء نماذج الرسم البياني المكاني أسوأ من الأساليب القائمة على CNN والأساليب القائمة على الهندسة لأن الأولى لا يمكنها الحصول على ميزات هندسية كافية ولا يمكنها حل مشكلة تغيرات حجم البروتين.
وتظهر النتائج أعلاه أنتعتبر المعلومات الهندسية والمعلومات البنيوية متعددة المستويات لسطح البروتين ضرورية للتنبؤ بموقع الارتباط.
بالإضافة إلى ذلك، يعكس هذا أيضًا قيود نموذج GNN الحالي، أي أنه من الصعب جمع معلومات هندسية كافية من سطح البروتين أو أن موارد الحوسبة المطلوبة كبيرة جدًا، مما يجعل من الصعب تطبيقه على الأنظمة الجزيئية الكبيرة مثل البروتينات. لذلك، لا يستطيع إطار عمل EquiPocket تحديث المعلومات الكيميائية والمكانية على المستوى الذري فحسب، بل يمكنه أيضًا جمع المعلومات الهندسية بكفاءة دون الحاجة إلى موارد حسابية مفرطة.ويتحسن أداؤه عن النتائج السابقة بمقدار 10-20%.
من ربيطات الجزيئات الصغيرة إلى الجزيئات البيولوجية الكبيرة، يفسر الذكاء الاصطناعي بنية البروتين بعمق
هناك مليارات من الآلات الجزيئية داخل كل خلية نباتية وحيوانية وبشرية، مكونة من جزيئات مثل البروتينات والأحماض النووية والسكريات، ولا يمكن لأي جزء منها أن يعمل بمفرده - فقط من خلال فهم كيفية تفاعلها في ملايين التركيبات يمكننا اكتساب فهم أعمق للحياة.
في مايو/أيار من هذا العام، أصدرت شركة Google DeepMind نموذج AlphaFold3، القادر على إجراء تنبؤات هيكلية مشتركة للمجمعات بما في ذلك البروتينات والأحماض النووية والجزيئات الصغيرة والأيونات والبقايا المعدلة. يعد التفاعل بين البروتينات والربيطات الجزيئية الصغيرة هو جوهر آلية عمل الدواء. بفضل خوارزمية التعلم العميق المتقدمة، يمكن لـ AlphaFold3 التنبؤ بدقة بالهيكل ثلاثي الأبعاد لربط البروتين بالربيط، بدقة تتجاوز بكثير دقة أدوات الالتحام الحالية.
من حيث تطوير الأدوية الجديدة،من خلال هياكل البروتين والربيطة التي تنبأ بها AlphaFold3، يمكن للباحثين فحص وتصميم مرشحين جدد للأدوية بشكل أكثر فعالية وتسريع عملية اكتشاف الأدوية. من حيث تحسين الأدوية الموجودة، يمكن أيضًا استخدام هذه الأداة لتحسين الأدوية الموجودة من خلال تحسين طريقة ارتباطها بالبروتين المستهدف لتعزيز الفعالية أو تقليل الآثار الجانبية.
بالإضافة إلى ربيطات الجزيئات الصغيرة،تحتاج البروتينات أيضًا إلى الاتحاد مع الجزيئات البيولوجية الكبيرة مثل الحمض النووي والسكريات لممارسة وظائفها البيولوجية.في الوقت الحالي، تم إيداع الآلاف من مجمعات بنية البروتين في قاعدة بيانات البروتين من خلال الأساليب التجريبية. ومع ذلك، فإن الطرق التجريبية التقليدية تستغرق وقتا طويلا وتكون مكلفة، في حين أن طرق التنبؤ القائمة على التعلم الآلي يمكن أن تحل التحديات بسهولة.
في فبراير من هذا العام، نشر فريق بحثي من جامعة نانجينغ الزراعية ورقة بحثية على الإنترنت بعنوان "ULDNA: دمج نماذج اللغة متعددة المصادر غير الخاضعة للإشراف مع شبكة LSTM-Attention للتنبؤ بموقع ربط البروتين والحمض النووي عالي الدقة" في Briefings in Bioinformatics، وهي مجلة مهمة في مجال علم الأحياء.تم تطوير طريقة جديدة للتنبؤ بالتعلم العميق تسمى ULDNA للتنبؤ بمواقع ارتباط البروتين بالحمض النووي.
عنوان الورقة:
https://academic.oup.com/bib/article/25/2/bbae040/7606634

الفكرة الأساسية لـ ULDNA هي استخدام نموذج لغة البروتين لتصميم تمثيل الميزات للتسلسل، ثم الجمع بين شبكة الذاكرة الطويلة الأمد (LSTM-Attention Network) مع آلية الانتباه لتدريب نموذج التنبؤ بموقع ربط الحمض النووي. قام الباحثون باختيار سبع مجموعات بيانات مرجعية، بما في ذلك PDNA-128، وPDNA-316، وPDNA-335 (حيث يتراوح عدد تسلسلات البروتين من 40 إلى 600)، وأجروا اختبارًا شاملاً على ULDNA. وتظهر النتائج التجريبية أنيحقق ULDNA أداءً جيدًا في جميع مجموعات البيانات، كما أن أداء التنبؤ الخاص به أفضل بشكل ملحوظ من أداء الطرق التسع الرئيسية الأخرى.
بالإضافة إلى الحمض النووي، تتواجد السكريات في كل مكان على أسطح خلايا جميع الكائنات الحية، حيث تتفاعل مع العديد من عائلات البروتين مثل الليكتينات والأجسام المضادة والإنزيمات والناقلات لتنظيم العمليات البيولوجية الرئيسية مثل الاستجابات المناعية وتمايز الخلايا والتطور العصبي.إن فهم آلية التفاعل بين الكربوهيدرات والبروتينات يشكل الأساس لتطوير أدوية الكربوهيدرات.ومع ذلك، فإن تنوع وتعقيد هياكل الكربوهيدرات، وخاصة تباين مواقع ارتباطها بالبروتين، يشكل تحديات أمام الحصول على البيانات التجريبية وتصميم الأدوية.
ومؤخرا، قام فريق من الأكاديمية الصينية للعلوم بتطوير نموذج التعلم العميق DeepGlycanSite، والذي يمكنه التنبؤ بدقة بمواقع ربط السكر في بنية بروتينية معينة. يقوم DeepGlycanSite بدمج السمات الهندسية والتطورية للبروتينات في شبكة عصبية بيانية متغايرة عميقة تعتمد على بنية المحول.إن أدائها يتفوق بشكل كبير على الطرق المتقدمة السابقة ويمكنها التنبؤ بشكل فعال بمواقع ربط جزيئات السكر المختلفة.
بالتزامن مع دراسات الطفرات، يكشف DeepGlycanSite عن موقع التعرف على سكر الغوانوزين-5'- ثنائي الفوسفات لمستقبلات البروتين G المهمة المقترنة. تشير هذه النتائج إلى أن DeepGlycanSite ذو قيمة للتنبؤ بموقع ربط السكر ويمكن أن يوفر رؤى حول الآليات الجزيئية وراء تنظيم الكربوهيدرات للبروتينات المهمة علاجيًا.

نُشرت الدراسة، التي تحمل عنوان "التنبؤ الدقيق للغاية بموقع ربط الكربوهيدرات باستخدام DeepGlycanSite"، في مجلة Nature Communications في 17 يونيو 2024.
عنوان الورقة:
https://www.nature.com/articles/s41467-024-49516-2
باختصار، يعد البروتين جزيئًا مهمًا في الكائنات الحية ويلعب دورًا رئيسيًا في بنية الخلايا ووظيفتها. إن دراسة بنية البروتين لها أهمية كبيرة لفهم العمليات الحيوية، وكشف آليات المرض وتطوير الأدوية. اليوم، يفتح التعلم الآلي بابًا جديدًا أمام العلماء لفهم أسرار الحياة.
مراجع:
1.https://openreview.net/forum?id=1vGN3CSxVs
2.https://mp.weixin.qq.com/s/aGzcr0ncQA-jBy-vTGC35Q
3.https://www.jiqizhixin.com/articles/2024-05-09
4.https://news.njau.edu.cn/2024/0








