Command Palette
Search for a command to run...
إنجاز عالمي للروبوتات! يقترح معهد ماساتشوستس للتكنولوجيا إطار عمل لمزيج الاستراتيجيات PoCo لحل مشكلة مصادر البيانات غير المتجانسة وتمكين التنفيذ المرن للروبوتات متعددة المهام

18 روبوتًا بشريًا قاموا بدور "المرحّبين" ولوحوا للضيوف في انسجام تام. كان هذا مشهدًا صادمًا في مؤتمر الذكاء الاصطناعي العالمي لعام 2024، مما سمح للناس أن يشعروا بشكل حدسي بالتطور السريع للروبوتات هذا العام.

في عام 1954، تم تشغيل أول روبوت قابل للبرمجة في العالم "Unimate" رسميًا على خط التجميع لشركة جنرال موتورز. بعد أكثر من نصف قرن من الزمان، تطورت الروبوتات تدريجيا من عمالقة صناعية ضخمة إلى مساعدين بشريين أكثر ذكاء ومرونة. ومن بينها تكنولوجيا الذكاء الاصطناعي، وخاصة التقدم المذهل في معالجة اللغة الطبيعية والرؤية الحاسوبية، والتي مهدت الطريق بسرعة عالية لتطوير الروبوتات، باستخدام قوة حوسبة هائلة وبيانات ضخمة.تدريب استراتيجيات الروبوتات العامة من خلال خوارزميات بسيطة مثل الاستنساخ السلوكي،يتم إطلاق العنان للإمكانات غير المحدودة للروبوتات المستقبلية تدريجياً.

ومع ذلك، يتم تدريب معظم خطوط أنابيب التعلم الروبوتية الحالية على مهمة محددة.وهذا يجعلهم غير قادرين على التعامل مع المواقف الجديدة أو أداء مهام مختلفة.بالإضافة إلى ذلك، تأتي بيانات تدريب الروبوت بشكل أساسي من سيناريوهات المحاكاة والعرض البشري وتشغيل الروبوت عن بعد.هناك تباين كبير بين مصادر البيانات المختلفة.ومن الصعب أيضًا على نموذج التعلم الآلي دمج البيانات من العديد من المصادر، وكان تدريب الروبوتات باستخدام استراتيجيات عامة يشكل دائمًا تحديًا كبيرًا.
وردا على ذلك،اقترح باحثو معهد ماساتشوستس للتكنولوجيا إطار عمل لتكوين سياسة الروبوت يسمى PoCo (تكوين السياسة).يستخدم هذا الإطار التوليف الاحتمالي لنماذج الانتشار لدمج البيانات من مجالات ووسائل مختلفة، ويطور أساليب توليف استراتيجية على مستوى المهمة ومستوى السلوك ومستوى المجال لبناء مجموعات استراتيجية روبوت معقدة. يمكنه حل مشاكل عدم تجانس البيانات وتنوع المهام في مهام استخدام أدوات الروبوت. وقد تم نشر البحث ذي الصلة على arXiv تحت عنوان "PoCo: تكوين السياسات من وإلى التعلم الروبوتي غير المتجانس".
أبرز الأبحاث:
* لا حاجة لإعادة التدريب، حيث يمكن لإطار عمل PoCo الجمع بشكل مرن بين استراتيجيات تدريب البيانات من مجالات مختلفة
* تتميز PoCo بالتفوق في مهام استخدام الأدوات في كل من المحاكاة والعالم الحقيقي، وتُظهر تعميمًا عاليًا للمهام في بيئات مختلفة مقارنة بالطرق المدربة على مجال واحد

عنوان الورقة:
https://arxiv.org/abs/2402.02511
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
ثلاث مجموعات بيانات رئيسية، تغطي البيانات البشرية والآلية، والبيانات الحقيقية والمحاكاة، وما إلى ذلك.
تتكون مجموعات البيانات المشاركة في هذه الدراسة بشكل أساسي من بيانات فيديو العرض البشري، وبيانات الروبوتات الحقيقية، وبيانات المحاكاة.
مجموعة بيانات فيديو توضيحية للبشر
من الممكن جمع مقاطع فيديو توضيحية للبشر من كاميرات غير معايرة في البرية، مع جمع ما يصل إلى 200 مسار في المجموع.

مجموعة بيانات الروبوت الحقيقي
يتم الحصول على وجهات نظر محلية وعالمية للمشهد من خلال كاميرا المعصم المثبتة والكاميرا العلوية، ويتم جمع وضع الأداة وشكل الأداة والمعلومات اللمسية عندما تلامس الأداة الكائن باستخدام GelSight Svelte Hand. يتم جمع 50-100 عرضًا للمسار لكل مهمة.
مجموعة بيانات المحاكاة
تتبع مجموعة البيانات المحاكاة أدوات الأسطول، حيث يتم إنشاء عروض توضيحية من الخبراء من خلال تحسين مسار النقطة الرئيسية، ويتم جمع ما مجموعه حوالي 50000 نقطة بيانات محاكاة. خلال عملية التدريب اللاحقة، قام الباحثون بزيادة البيانات على كل من بيانات سحابة النقاط وبيانات الحركة، وحفظوا مشاهد المحاكاة الثابتة للاختبار.
بالإضافة إلى ذلك، أضاف الباحثون ضوضاء نقطية وإسقاطًا عشوائيًا إلى 512 أداة و512 سحابة نقاط كائن من صور العمق والأقنعة لتحسين قوة النموذج.
دمج الاستراتيجيات من خلال حاصل توزيع الاحتمالات
في تركيبة الاستراتيجية، قدم الباحثون معلومات المسار المشفرة بواسطة توزيعين احتماليين pDM(⋅|c,T) وpD′M′(⋅|c′,T′)، ودمجوا بشكل مباشر معلومات هذين التوزيعين الاحتماليين عن طريق أخذ العينات في توزيع المنتج أثناء الاستدلال.
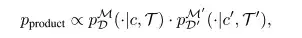
في،المنتج ويظهر احتمالية عالية لجميع المسارات التي تلبي كلا توزيعي الاحتمالات.يمكنه ترميز المعلومات الخاصة بكلا التوزيعين بشكل فعال.
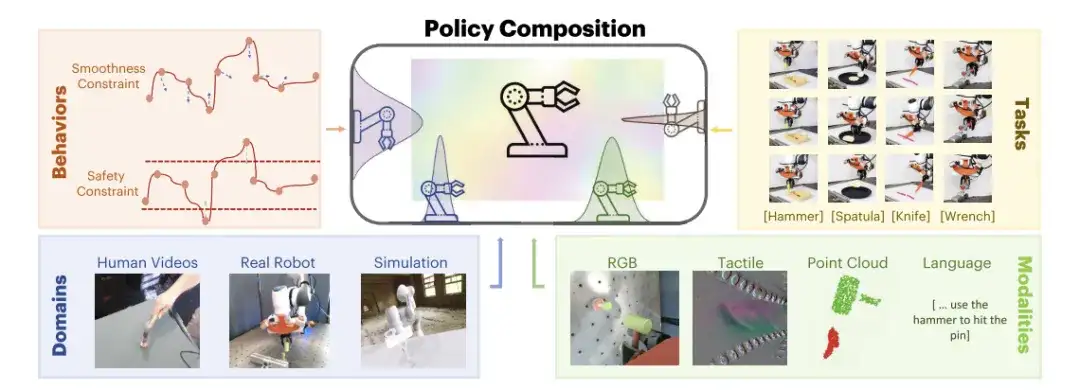
PoCo اقترحه الباحثون،جمع المعلومات عبر السلوكيات والمهام والقنوات والمجالات،لا يتطلب الأمر إعادة التدريب؛ يتم دمج المعلومات بطريقة معيارية أثناء التنبؤ، ويمكن تحقيق تعميم مهام استخدام الأدوات من خلال الاستفادة من المعلومات من حقول متعددة.
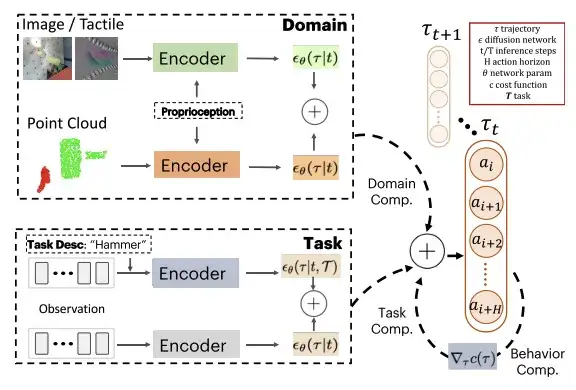
من المفترض أن يكون ناتج الانتشار لكل نموذج في نفس المساحة، أي أن بُعد الفعل ومجال زمن الفعل هما نفس الشيء. في وقت الاختبار، يتم دمج PoCo مع توقعات التدرج. يمكن تطبيق هذا النهج على مجموعة من السياسات من مجالات مختلفة، مثل الجمع بين السياسات المدربة باستخدام وسائل مختلفة مثل الصور وسحب النقاط والصور اللمسية. يمكن أيضًا استخدامه لدمج الاستراتيجيات لمهام مختلفة، بالإضافة إلى توفير وظائف تكلفة إضافية للسلوكيات المرغوبة من خلال الجمع بين السلوكيات.
وفي هذا الصدد، قدم الباحثون ثلاثة أمثلة: تكوين مستوى المهمة، وتكوين مستوى السلوك، وتكوين مستوى المجال لتوضيح كيف يمكن لـ PoCo تحسين أداء السياسات.
تكوين مستوى المهمة
تضيف مجموعة مستوى المهمة أوزانًا إضافية للمسارات التي يمكنها إكمال المهمة T، مما قد يحسن الجودة النهائية للمسار المركب دون الحاجة إلى تدريب منفصل لكل مهمة.وبدلاً من ذلك، يتم تدريب سياسة عامة يمكنها تحقيق أهداف متعددة المهام.
تكوين على مستوى السلوك
يمكن أن يجمع هذا المزيج بين المعلومات حول توزيع المهام وهدف التكلفة.تأكد من أن المسار المركب يكمل المهمة ويحسن هدف التكلفة المحدد.
تكوين على مستوى المجال
يمكن أن تستفيد هذه المجموعة من المعلومات الملتقطة من وسائط ومجالات استشعار مختلفة.مفيد جدًا لاستكمال البيانات التي تم جمعها في حقول منفصلة.على سبيل المثال، عندما تكون بيانات الروبوت الحقيقية مكلفة في التجميع ولكنها أكثر دقة، وتكون بيانات عرض المحاكاة أرخص في التجميع ولكنها أقل دقة، يمكن إجراء سلسلة من الميزات على البيانات من أوضاع مختلفة في نفس المجال لتبسيط المعالجة.
مهمة استخدام أداة التصور، تقييم 3 مجموعات استراتيجية رئيسية

أثناء التدريب، استخدم الباحثون بنية U-Net زمنية مع نموذج احتمالي لانتشار الضوضاء (DDPM) وأجروا 100 خطوة من التدريب؛ أثناء الاختبار، استخدموا نموذج الانتشار الضمني لإزالة الضوضاء (DDIM) وأجروا 32 خطوة من الاختبار. من أجل الجمع بين نماذج الانتشار المختلفة بين المجالات المختلفة D والمهام T، استخدم الباحثون نفس مساحة العمل لجميع النماذج وأجروا تطبيعًا ثابتًا على حدود عمل الروبوت.
قام الباحثون بتقييم PoCo المقترح من خلال مهام استخدام الروبوت للأدوات الشائعة (المفتاح، والمطرقة، والمجرفة، والمفتاح). تم تحديد المهمة على أنها ناجحة عندما تم الوصول إلى حد معين، على سبيل المثال، تم اعتبار مهمة الطرق ناجحة عندما تم دفع دبوس.
يمكن أن تؤدي التركيبات على مستوى السلوك إلى تحسين الأهداف السلوكية المرغوبة
استخدم الباحثون الاستدلال على وقت الاختبار للجمع بين السلوكيات مثل السلاسة وقيود مساحة العمل، مع تثبيت وزن التوليف عند γc=0.1.
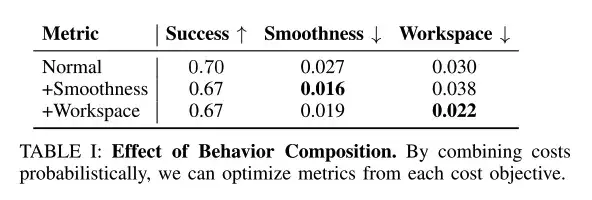
كما هو موضح في الجدول أعلاه، يمكن لمجموعات مستوى السلوك ووقت الاختبار أن تعمل على تحسين الأهداف السلوكية المرغوبة مثل السلاسة وقيود مساحة العمل.
تعتبر التركيبات على مستوى المهام هي الأمثل في تقييم السياسات متعددة المهام
عندما يكون وزن المهمة α=0، يتم تعيين سياسة الجمع على مستوى المهمة إلى سياسة تعدد المهام غير المشروطة، وعندما يكون α=1، يتم تعيينها إلى سياسة المهمة المشروطة القياسية، وعندما يكون 0 < α < 1، يقوم الباحثون بالتداخل بين السياسات المشروطة بالمهمة والسياسات غير المشروطة بالمهمة. عندما تكون α > 1، يمكن الحصول على مسارات أكثر صلة بظروف المهمة.
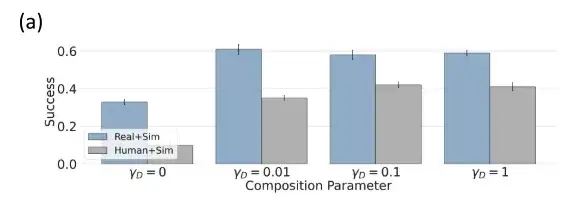
يوضح الشكل أعلاه أنه بالمقارنة مع استراتيجية الانتشار لاستخدام أداة متعددة المهام مشروطة وغير مشروطة ومحددة للمهمة، فإن استراتيجية استخدام أداة متعددة المهام مشروطة وغير مشروطة لها مزيج أفضل من المهام.
البيانات البشرية + المحاكاة، والجمع على مستوى المجال له أداء أفضل
قام الباحثون بتدريب نماذج سياسة منفصلة باستخدام مجموعة بيانات محاكاة θsim، ومجموعة بيانات بشرية θhuman، ومجموعة بيانات روبوت θrobot، وقاموا بتقييم مجموعات على مستوى المجال في بيئة محاكاة.
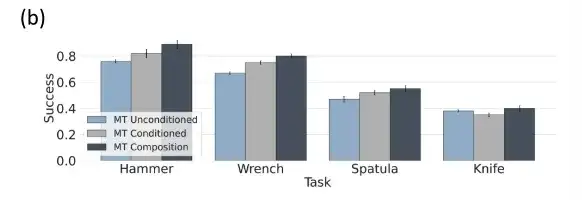
نظرًا لأن θsim ليس لديه فجوة في مجال التدريب/الاختبار، فإنه يعمل بشكل جيد ويمكنه تحقيق معدل نجاح 92%. وفي مجالات مثل البيانات البشرية، قام الباحثون بدمجها مع سياسة θsim ذات الأداء الأفضل، مما أدى إلى تحسين الأداء بشكل كبير.
إن أداء مجموعة الإستراتيجية يتجاوز أداء مكوناتها الفردية وهو أكثر تنوعًا
قام الباحثون بتطبيق PoCo على مهام استخدام الأدوات الروبوتية، من خلال الجمع بين البيانات من مجالات ومهام مختلفة لتحسين قدرتها على التعميم. المهام الأربع هي: شد البراغي باستخدام مفتاح ربط، وضرب المسامير بمطرقة، وإخراج الفطائر من المقلاة باستخدام مجرفة، وقطع البلاستيسين بالسكين.

من خلال الجمع بين السياسات المدربة في المحاكاة والبشر والبيانات الحقيقية، يمكننا التعميم عبر عوامل تشتيت متعددة (الصف 1)، ووضعيات مختلفة للكائنات والأدوات (الصف 2)، وحالات جديدة للكائنات والأدوات (الصف 3).
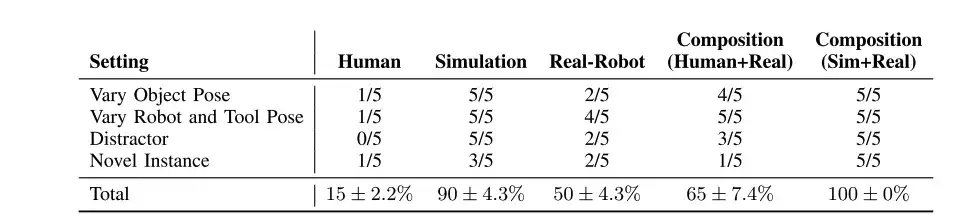
كما هو موضح في الجدول أعلاه، على الرغم من أن الاستراتيجيات المدربة ببيانات بشرية والاستراتيجيات المدربة ببيانات روبوت حقيقي تعمل بشكل ضعيف في سيناريوهات مختلفة (مقارنة بالمحاكاة)،لكن مزيجهم (الإنسان + الواقع) يمكن أن يتجاوز كل مكون على حدة.
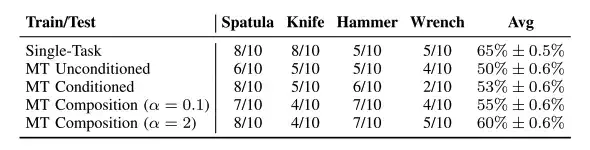
من خلال العالم الحقيقي، قام الباحثون بتقييم الأداء الاستراتيجي للروبوت في أربع مهام مختلفة باستخدام الأدوات ووجدوا أنه في المهام التي تستخدم الأدوات،تم تحسين أداء استراتيجية الجمع بين المهام بشكل أفضل.كما هو موضح في الجدول أعلاه، فإن أداء استراتيجية المهام المتعددة هو نفسه تقريبًا مثل أداء المهام المحددة المشروطة بـ Tspatula و Thammer، وكلها تظهر استقرارًا معينًا في الإجراءات الدقيقة. علاوة على ذلك، يجب إبقاء المعلمات الفائقة المركبة ضمن نطاق لتكون فعالة ومستقرة.
أفضل الظروف للعالمية: الروبوتات الشبيهة بالبشر ترتفع بقوة
لقد ازدهرت الروبوتات متعددة الأغراض في العامين الماضيين، ولكن الظاهرة المثيرة للاهتمام هي أن الصناعة تبدو حاليًا أكثر ميلًا إلى تعزيز تطوير الروبوتات متعددة الأغراض بطريقة بشرية.لماذا يجب أن تكون الروبوتات متعددة الأغراض ذات شكل إنساني؟قال تشين تشي، المدير الإداري لشركة 5Y Capital: "لأن الروبوتات الشبيهة بالبشر فقط هي القادرة على التكيف مع سيناريوهات التفاعل المختلفة في بيئة المعيشة البشرية!" وبما أن الروبوتات سوف تساعد البشر على العمل، فمن الأفضل لها أن تقلد البشر وتتعلم بمظهر يشبه الإنسان.
كمعيار للصناعة، أطلقت شركة تسلا في وقت مبكر من سبتمبر 2022 الروبوت البشري متعدد الأغراض Optimus. ورغم أنه لم يكن قادرًا على المشي بثبات في البداية، إلا أنه يمتلك نموذجًا أوليًا كاملًا لروبوت يشبه الإنسان ويلبي متطلبات العمل الماهر الأساسي الذي يستطيع البشر القيام به. مع التكرار المستمر لتكنولوجيا البرمجيات والأجهزة الخاصة بشركة Tesla، سيكون لدى Optimus وظائف أكثر إثارة، وقد ثبت أن الحقائق صحيحة.

في مؤتمر الذكاء الاصطناعي العالمي لعام 2024، أظهرت تسلا للجميع أحدث تقدم في أبحاث روبوتها البشري أوبتيموس: زادت سرعة المشي المستقيم بمقدار 30%، كما تطورت الأصابع العشرة أيضًا في الإدراك واللمس، حتى تتمكن من حمل البيض الهش بلطف وحمل الصناديق الثقيلة بثبات. ومن المفهوم أن شركة Optimus جربت تطبيقات عملية في مصانع Tesla، مثل استخدام الشبكات العصبية البصرية وشرائح FSD لمحاكاة العمليات البشرية لإجراء تدريب على فرز البطاريات. ومن المتوقع أن يكون هناك في العام المقبل أكثر من 1000 روبوت على شكل إنسان في مصانع تسلا لمساعدة البشر في إكمال مهام الإنتاج.
وعلى نحو مماثل، جلبت شركة شنغهاي فورييه للتكنولوجيا الذكية المحدودة، وهي شركة رائدة في صناعة الروبوتات العامة تأسست في عام 2015، روبوتها البشري GR-1 إلى المؤتمر. منذ إطلاقه في عام 2023، كان GR-1 رائداً في تحقيق الإنتاج والتسليم بكميات كبيرة، وحقق ترقيات متقدمة في الإدراك البيئي، ونماذج المحاكاة، وتحسين التحكم في الحركة، وغيرها من الجوانب.
بالإضافة إلى ذلك، في شهر مارس من هذا العام، أطلقت NVIDIA أيضًا مشروع روبوت على شكل إنسان يسمى GR00T في مؤتمر مطوري GTC السنوي. من خلال مراقبة السلوك البشري لفهم اللغة الطبيعية وتقليد الأفعال، يمكن للروبوت أن يتعلم بسرعة التنسيق والمرونة والمهارات الأخرى للتنقل والتكيف والتفاعل مع العالم الحقيقي.
مع التقدم المستمر في العلوم والتكنولوجيا، لدينا سبب للاعتقاد بأن الروبوتات البشرية قد تصبح جسراً يربط بين البشر والآلات، والواقع والمستقبل، مما يقودنا إلى مجتمع أكثر ذكاءً وأفضل.
مراجع:
https://m.163.com/dy/article/J69LAFDR0512MLBG.html
https://36kr.com/p/1987021834257154
https://hub.baai.ac.cn/view/211








