Command Palette
Search for a command to run...
من المقرر عقد اجتماع 2024 Meet AI Compiler Beijing دون اتصال بالإنترنت! InfinityInstruct، وهي مجموعة بيانات لضبط عشرات الملايين من التعليمات، أصبحت الآن مفتوحة المصدر

تُعد بيانات التعليمات عالية الجودة موردًا لا غنى عنه لتدريب نماذج اللغة الكبيرة وتحسينها، كما أنها حجر الأساس لتحسين أداء النموذج. أصدرت أكاديمية بكين للذكاء الاصطناعي مؤخرًا مشروع InfinityInstruct مفتوح المصدر، والذي يحتوي على عشرات الملايين من مجموعات بيانات ضبط التعليمات عالية الجودة، بما في ذلك البيانات عالية الجودة التي تم فحصها بناءً على مجموعات بيانات مفتوحة المصدر وبيانات تعليمات عالية الجودة تم إنشاؤها من خلال طرق تجميع البيانات.
تم في هذا المؤتمر إتاحة الدفعة الأولى المكونة من 3 ملايين مجموعة بيانات تعليمية عالية الجودة باللغتين الصينية والإنجليزية InfInstruct-3M، والتي تم التحقق من نموذجها، كمصدر مفتوح.متاح الآن على الموقع الرسمي لـhyper.ai. يمكنك استخدام مجموعة البيانات هذه وضبط النموذج الأساسي باستخدام بيانات التطبيق الخاصة بك لبناء نموذج حوار ثنائي اللغة عالي الجودة وحصري باللغتين الصينية والإنجليزية بسرعة.
من 10 يونيو إلى 14 يونيو، تحديثات الموقع الرسمي لـ hyper.ai:
* مجموعات البيانات العامة عالية الجودة: 10
* دروس تعليمية مختارة عالية الجودة: 2
* اختيار المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
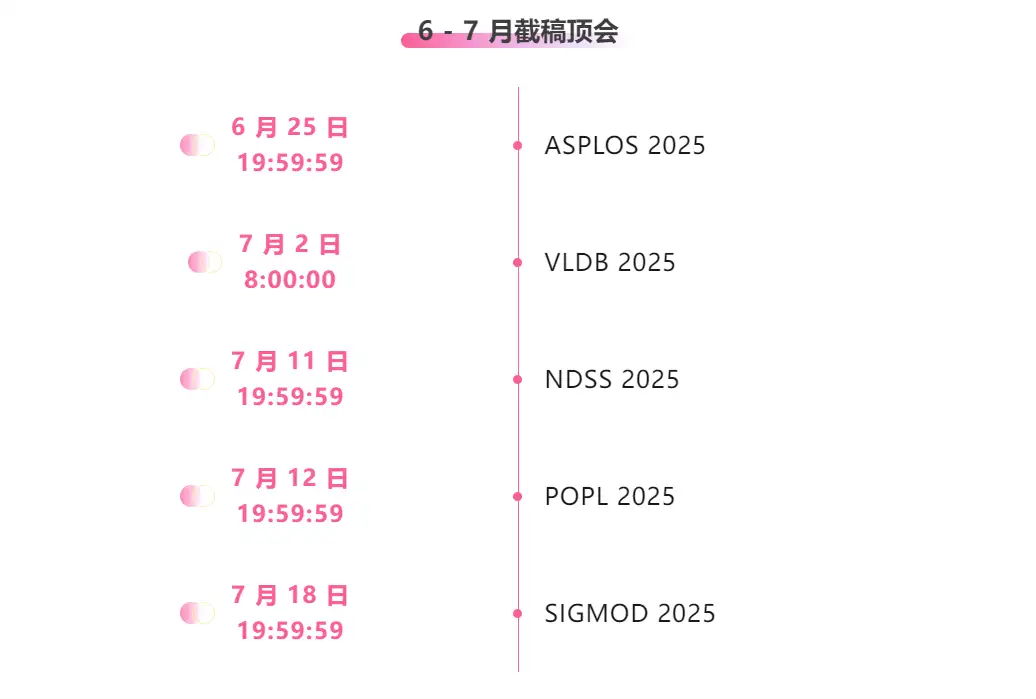
* أفضل المؤتمرات التي لها مواعيد نهائية في شهري يونيو ويوليو: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. أطلقت InfInstruct-3M مجموعة بيانات مكونة من 10 ملايين تعليمة للضبط الدقيق
تم إطلاق مجموعة البيانات هذه بواسطة أكاديمية بكين للذكاء الاصطناعي. يهدف المشروع إلى تطوير مجموعة بيانات تحتوي على ملايين التعليمات لدعم قدرات تتبع التعليمات في نماذج اللغة الكبيرة وبالتالي تحسين أداء النموذج. هذه النسخة هي مجموعة بيانات تعليمات InfinityInstruct-3M، ومن المتوقع إصدار النسخة النهائية في نهاية شهر يونيو.
الاستخدام المباشر:https://go.hyper.ai/iG7gN
2. مجموعة بيانات معيارية لفهم السياق الطويل لـ LooGLE
تُعد مجموعة البيانات هذه مجموعة بيانات مرجعية مصممة لتقييم وتحسين قدرات أنظمة الذكاء الاصطناعي في الفهم طويل الأمد. وقد تم قبول ورقة البحث ذات الصلة من قبل ACL2024.
الاستخدام المباشر:https://go.hyper.ai/S6dSZ
3. InternVid - مجموعة بيانات نصية وفيديو كاملة عالية الجودة وواسعة النطاق
تحتوي مجموعة البيانات على أكثر من 7 ملايين مقطع فيديو مع أوصاف نصية مفصلة، تغطي 16 مشهدًا وحوالي 6000 وصف للأحداث، بمدة إجمالية تبلغ حوالي 760 ألف ساعة. حصلت الورقة ذات الصلة على الضوء في المؤتمر الدولي لعام 2024 حول التعلم التمثيلي (ICLR 2024).
الاستخدام المباشر:https://go.hyper.ai/AnaLl
4. مجموعة بيانات LoveDA للاستشعار عن بُعد للغطاء الأرضي للتجزئة الدلالية التكيفية للمجال
هذه المجموعة من البيانات هي مجموعة بيانات غطاء أرضي للاستشعار عن بعد، مصممة خصيصًا للتجزئة الدلالية التكيفية للمجال، وتحتوي على 5,987 صورة عالية الدقة و166,768 كائنًا دلاليًا معلقًا.
الاستخدام المباشر:https://go.hyper.ai/ShKyN
5. مجموعة بيانات صور المباني الحضرية من CityGen
هذه المجموعة من البيانات عبارة عن مجموعة بيانات صور تركز على المباني الحضرية. ويحتوي عادةً على عدد كبير من صور المباني الحضرية. يمكن استخدام هذه الصور لتدريب وتقييم نماذج الرؤية الحاسوبية، وخاصة في المهام مثل اكتشاف المباني، والتجزئة الدلالية، وتجزئة المثيلات. وقد تم تضمين النتائج ذات الصلة في CVPR 2024.
الاستخدام المباشر:https://go.hyper.ai/ddNqv
6. تصنيف النفايات: مجموعة بيانات تصنيف النفايات القابلة لإعادة التدوير والنفايات المنزلية
تحتوي مجموعة البيانات على 15000 صورة (256 × 256 بكسل لكل منها) تغطي مختلف المواد القابلة لإعادة التدوير، والنفايات العامة، والأدوات المنزلية في 30 فئة مختلفة، مما يوفر موردًا غنيًا ومتنوعًا للبحث والتطوير في مجال فرز النفايات وإعادة التدوير.
الاستخدام المباشر:https://go.hyper.ai/kOiKG
7. الطيور 525 نوعًا مجموعة بيانات صور 525 طائرًا
تحتوي مجموعة البيانات على 525 نوعًا من الطيور، و84,635 صورة تدريبية، و2,625 صورة اختبار، و2,625 صورة للتحقق.
الاستخدام المباشر:https://go.hyper.ai/pfw5d
8. مجموعة بيانات معيارية لرسم خرائط الغطاء الأرضي العالمية عالية الدقة من OpenEarthMap
تتكون مجموعة البيانات من 2.2 مليون مقطع من 5000 صورة جوية وصور الأقمار الصناعية تغطي 97 منطقة في 44 دولة عبر 6 قارات، مع تسميات غطاء الأرض الموضحة يدويًا من 8 فئات على مسافة أخذ عينات أرضية تتراوح من 0.25 إلى 0.5 متر. وقد تم تضمين نتائج الورقة ذات الصلة في WACV 2023.
الاستخدام المباشر:https://go.hyper.ai/ubxmO
9. مجموعة بيانات تقييم الترجمة الآلية للقصص المصورة OpenMantra
هذه المجموعة من البيانات عبارة عن مجموعة بيانات لتقييم الترجمة الآلية للقصص المصورة اليابانية. يحتوي على قصص مصورة بخمسة أنماط مختلفة (خيال، رومانسية، قتال، تشويق، وحياة). تحتوي مجموعة البيانات على إجمالي 1,593 جملة، و848 مشهدًا، و214 صفحة من القصص المصورة. تم إصداره من قبل فريق مانترا بجامعة طوكيو.
الاستخدام المباشر:https://go.hyper.ai/ISqUR
10. مجموعة بيانات التعرف على نسيج DTD
تتكون مجموعة البيانات من 5640 صورة، مقسمة إلى 47 فئة وفقًا للإدراك البشري، مع 120 صورة في كل فئة. بالنسبة لكل صورة، يتم أيضًا توفير قائمة بالسمات الرئيسية والسمات المشتركة.
الاستخدام المباشر:https://go.hyper.ai/aUYi3
لمزيد من مجموعات البيانات العامة، يرجى زيارة:
دروس تعليمية عامة مختارة
1. قم بتشغيل العرض التوضيحي لنموذج TripoSR عبر الإنترنت
تم تطوير TripoSR بشكل مشترك بين Stability AI وTripo AI. يمكنه إنشاء نماذج ثلاثية الأبعاد عالية الجودة من صورة واحدة في غضون ثانية واحدة، ولديه متطلبات طاقة حوسبة منخفضة، لذلك يمكن للمستخدمين العاديين استخدامه بسهولة على الأجهزة المحلية. لقد قام هذا البرنامج التعليمي بإعداد البيئة المناسبة لك.
تشغيل عبر الإنترنت:https://go.hyper.ai/is9qe
2. عرض توضيحي لإنشاء نموذج غاوسي متعدد المشاهد كبير الحجم LGM
LGM، أو نموذج غاوسي متعدد المشاهد الكبير، هو إطار عمل مبتكر لإنشاء نماذج ثلاثية الأبعاد عالية الدقة من المطالبات النصية أو الصور ذات العرض الفردي. يمكن لهذه الطريقة إنشاء كائنات ثلاثية الأبعاد في غضون 5 ثوانٍ وزيادة دقة التدريب إلى 512، وبالتالي تحقيق إنشاء محتوى ثلاثي الأبعاد عالي الدقة. هذا البرنامج التعليمي عبارة عن تنفيذ تجريبي لـ LGM.
تشغيل عبر الإنترنت:https://go.hyper.ai/pFnhg
لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~
مقالات المجتمع
1. معاينة الحدث | من المقرر أن يتم عرض أول مؤتمر Meet AI Compiler في بكين في 6 يوليو 2024!
سيُعقد أول اجتماع لـ Meet AI Compiler Beijing في 6 يوليو 2024 في قاعة المحاضرات في الطابق الأول من معهد تكنولوجيا الحوسبة، التابع للأكاديمية الصينية للعلوم! في هذا اللقاء، يسعدنا دعوة العديد من كبار خبراء مُجمّعات الذكاء الاصطناعي من جامعة شنغهاي جياو تونغ، ومعهد تكنولوجيا الحوسبة التابع للأكاديمية الصينية للعلوم، ومايكروسوفت ريسيرش آسيا، وغيرها. سيقدمون لكم كلمات رئيسية رائعة ومناقشات مستديرة، ويناقشون معكم تطبيقات وإنجازات تقنية مُجمّعات الذكاء الاصطناعي في السيناريوهات العملية.انقر فوق "قراءة النص الأصلي" للتسجيل والمشاركة!
عرض معلومات الحدث الكاملة:https://go.hyper.ai/EA1uw
في الأسبوع الماضي، أصدرت شركة Apple تطبيق Apple Intelligence وقدمت تحديثات رئيسية لنظام التشغيل iOS 18 وSiri. تم الإعلان رسميًا أخيرًا عن التعاون الذي أشيع سابقًا بين Apple و OpenAI. أصبحت Siri، التي تتكامل مع ChatGPT، أكثر طبيعية وأكثر سياقية وأكثر تخصيصًا، ويمكنها تبسيط المهام اليومية وتسريعها. تقدم هذه المقالة تحديثات Apple Intelligence وSiri وiOS 18، كما تستعرض تاريخ تطوير Siri، مما قد يوضح بشكل أكبر أهمية ترقية قدرات الذكاء الاصطناعي من Apple إلى Siri.
شاهد التقرير الكامل:https://go.hyper.ai/kWmHC
اقترح فريق مشترك من كلية الكمبيوتر والبرمجيات بجامعة شنتشن ومركز أبحاث الصحة الذكية بجامعة هونج كونج للفنون التطبيقية نموذجًا جديدًا لتقسيم فيديو تخطيط صدى القلب يسمى MemSAM. يحقق النموذج أداءً متطورًا مع عدد صغير من الإشارات النقطية وأداءً مماثلاً للطرق الخاضعة للإشراف الكامل مع التعليقات التوضيحية المحدودة، مما يقلل بشكل كبير من متطلبات الإشارات والتعليقات التوضيحية المطلوبة لمهام تقسيم الفيديو. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/2s73Q
قام الدكتور جيانمين وانج وآخرون من جامعة يونسي بدمج التعلم العميق مع الذكاء الاصطناعي التوليدي، باستخدام شبكة عصبية توليدية تعتمد على المحول لتعلم واستكشاف المجموعة التكوينية لمجمعات البروتين-البروتين، ومعرفة البقايا الرئيسية التي تؤثر على التكوين والآلية الديناميكية لمجمعات البروتين-البروتين من مسارات ديناميكية جزيئية متعددة، مما يوفر رؤى ميكانيكية في ربط البروتين-البروتين. هذه المقالة عبارة عن تفسير مفصل ومشاركة للبحث.
شاهد التقرير الكامل:https://go.hyper.ai/MdgoV
مقالات موسوعية شعبية
1. اندماج الترتيب المتبادل RRF
2. نمذجة اللغة المقنعة (MLM)
3. معدل التعلم
4. YOLOv10 الكشف عن الكائنات من البداية إلى النهاية في الوقت الفعلي
5. نظرية كولموغوروف-أرنولد للتمثيل
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
معاينة البث المباشر لمحطة B
جيف دين هو باحث أول وعالم كمبيوتر في جوجل، وهو معروف بعمله الرائد في الأنظمة الموزعة والذكاء الاصطناعي، بما في ذلك تطوير MapReduce و TensorFlow، وهو أحد الشخصيات الرئيسية في التطوير التكنولوجي لشركة جوجل. هذا الأسبوع، سوف تبث قناة Super Neuro TV خطابات ومقابلات جيف دين على الهواء مباشرة.
الجدول التالي هو معاينة للمحتوى الذي حدده المحرر↓↓↓
| تاريخ | وقت | محتوى |
| الاثنين 17 يونيو | 18:00 | جيف دين يتحدث عن الاتجاهات الخمسة في التعلم الآلي |
| الثلاثاء 18 يونيو | 18:00 | دع الذكاء الاصطناعي يخدم الجميع |
| الأربعاء 19 يونيو | 18:00 | نظرة جيف دين الإيجابية لمستقبل الذكاء الاصطناعي |
| الخميس 20 يونيو | 18:00 | كلمة جيف دين في مؤتمر ستانفورد للبيانات الطبية الضخمة |
| الجمعة 21 يونيو | 18:00 | محاضرة جيف دين عن التعلم العميق |
| السبت 22 يونيو | 18:00 | برنامج جوجل للدماغ والإقامة الدماغية |
| الأحد 23 يونيو | 18:00 | يناقش جيف دين كيفية استخدام التعلم العميق لحل المشكلات |
تبث قناة Super Neuro TV بثًا مباشرًا على مدار 24 ساعة طوال أيام الأسبوع. انقر للحصول على "المخللات الإلكترونية" في مجال الذكاء الاصطناعي:
http://live.bilibili.com/26483094
تتبع شامل لأفضل المؤتمرات الأكاديمية في مجال الذكاء الاصطناعي:https://hyper.ai/events
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* توفير عقد تنزيل محلية سريعة لأكثر من 1300 مجموعة بيانات عامة
* يتضمن أكثر من 400 برنامج تعليمي كلاسيكي وشائع عبر الإنترنت
* تفسير أكثر من 100 حالة بحثية من AI4Science
* دعم البحث عن أكثر من 500 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








