Command Palette
Search for a command to run...
تجاوز حجم المعاملات الرقمية لأول مرة لـ Liu Qiangdong 50 مليونًا! إنشاء إنسان رقمي يتحدث في الوقت الفعلي باستخدام GeneFace++
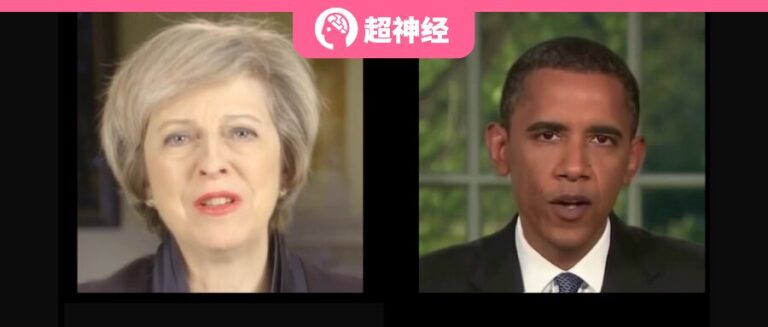
في الآونة الأخيرة، تحول مؤسس شركة JD.com، ليو تشيانغ دونغ، إلى "الإنسان الرقمي للذكاء الاصطناعي في قسم الشراء والمبيعات" وبدأ ظهوره الأول في البث المباشر في غرفة البث المباشر للمشتريات والمبيعات الخاصة بالأجهزة المنزلية ومفروشات المنزل ومحلات السوبر ماركت في شركة JD.com. وجذب البث المباشر أكثر من 20 مليون مشاهد، وتجاوز إجمالي حجم المعاملات 50 مليونًا.إنه يوضح تمامًا الإمكانات الهائلة للأشخاص الرقميين ذوي الذكاء الاصطناعي في مجال البث المباشر للتجارة الإلكترونية.
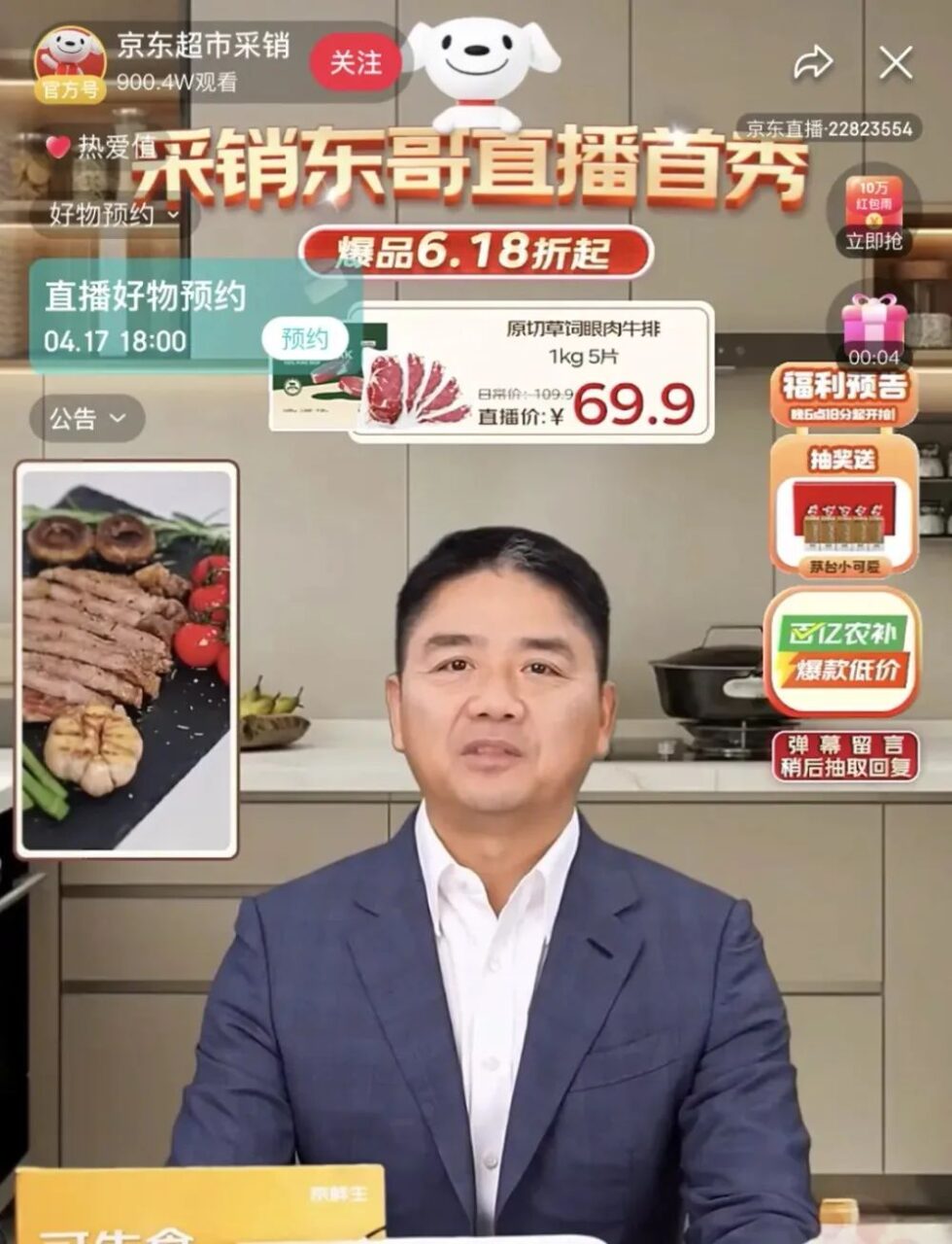
مصدر الصورة: Guanchazhe.com
ومن المفهوم أن "الإنسان الرقمي للذكاء الاصطناعي للشراء والمبيعات" يمكنه عرض تعبيرات ليو تشيانغ دونغ الشخصية، ومواقفه، وإيماءاته، وخصائص جرس صوته بدقة من خلال تعلم وتدريب صورته وصوته. من الصعب التمييز بين الإنسان الرقمي والإنسان الحقيقي بالعين المجردة خلال 120 ثانية.

ذكرت شركة IDC في تقريرها "تحليل حالة وفرص سوق الذكاء الاصطناعي الرقمي في الصين لعام 2022" أن حجم سوق الذكاء الاصطناعي الرقمي في الصين من المتوقع أن يصل إلى 10.24 مليار يوان بحلول عام 2026. تجدر الإشارة إلى أن الذكاء الاصطناعي الرقمي قابل للتكرار، ومنخفض التكلفة، ويمكنه العمل على مدار الساعة. قد يصبح تطبيقها في سيناريوهات مثل عمليات الوسائط الذاتية، ومبيعات مقاطع الفيديو القصيرة، والبث البشري الرقمي، ومساعدة البشر في إكمال المهام المختلفة، اتجاهًا رئيسيًا في المستقبل.
في هذا المجال، يعد توليد الوجوه المتحدثة بواسطة الصوت موضوعًا ساخنًا. بناءً على هذه التقنية، كل ما عليك فعله هو إدخال مقطع صوتي لإنشاء فيديو يتحدث عن وجه الشخص المستهدف، مما يمكن أن يساعد الشخص المستهدف على حضور بعض المشاهد التي يكون فيها الأشخاص الحقيقيون غير مرتاحين أو غير قادرين على الظهور. في،GeneFace++ هي تقنية عامة ومستقرة لتوليد الوجوه ثلاثية الأبعاد تعتمد على الصوت في الوقت الفعلي، وهي الأولى التي تحقق توليد الوجوه الناطقة في الوقت الفعلي من خلال تحسين مزامنة الشفاه وجودة الفيديو وكفاءة النظام.
على وجه التحديد، يقوم GeneFace++ بتدريب وحدة تحويل الصوت إلى حركة ووحدة تحويل الحركة الفورية إلى فيديو بشكل مستقل. تتضمن عملية التدريب رسم الخرائط التعليمية بين الصوت وحركات الوجه، ونقل التعلم من أجل التكيف مع المجال، والتعلم من تقنية عرض الصور ثلاثية الأبعاد في الوقت الفعلي، والتي تمكن النموذج في النهاية من إنشاء مقاطع فيديو عالية الجودة، في الوقت الفعلي، ومتزامنة مع الشفاه، لوجوه تتحدث ثلاثية الأبعاد بناءً على صوت عشوائي.
ومع ذلك، فإن إنشاء إنسان رقمي واقعي متزامن مع حركة الشفاه ليس بالمهمة السهلة. من أجل مساعدة المبتدئين على البدء بسرعة وتجنب صعوبات البناء البيئية والتقنية الشائعة،هايبر ايه ايسوبر نيوروتم إطلاق البرنامج التعليمي "GeneFace++ Digital Human Demo".لقد قام هذا البرنامج التعليمي ببناء بيئة مناسبة للجميع وبسّط عملية إنشاء البشر الرقميين. لا داعي للقلق بشأن مشكلات مثل تكوين البيئة ومتطلبات الأجهزة وتوافق الإصدارات. ما عليك سوى النقر فوق "استنساخ" لبدء تشغيله بنقرة واحدة، وسيكون التأثير واقعيًا للغاية!
عنوان البرنامج التعليمي العام لـ HyperAI Hyperneural:
https://hyper.ai/tutorials/31157
التحضير الأولي
إعداد فيديو لمدة 3-5 دقائق:
* يجب أن تكون الصورة واضحة ومربعة الحجم (يفضل أن تكون 512*512)؛
* لكي يتمكن النموذج من استخراج الخلفية بشكل أفضل، يجب أن تكون خلفية الفيديو بلون ثابت بدون عوامل تدخل أخرى؛
* يجب أن تكون وجوه الأشخاص في الفيديو واضحة وكبيرة نسبيًا، ويجب أن تكون في المقدمة. يفضل أن تكون الصور الملتقطة أعلى من الكتفين، ويجب ألا تكون حركات الأشخاص كبيرة جدًا أو صغيرة جدًا؛
* الصوت في الفيديو خالي من الضوضاء؛
*من الأفضل تسمية الفيديو باللغة الإنجليزية.
ملحوظة: سيتم استخدام هذا الفيديو للتدريب النموذجي. كلما كانت جودة الفيديو أفضل، كلما كانت النتائج أفضل. لذلك، من الضروري قضاء المزيد من الوقت والجهد في جزء إعداد البيانات.
وفيما يلي مثال لشاشة الفيديو:

تشغيل تجريبي
1. قم بتسجيل الدخول إلى hyper.ai، وفي صفحة البرنامج التعليمي، حدد GeneFace++ Digital Human Demo. انقر فوق تشغيل هذا البرنامج التعليمي عبر الإنترنت.
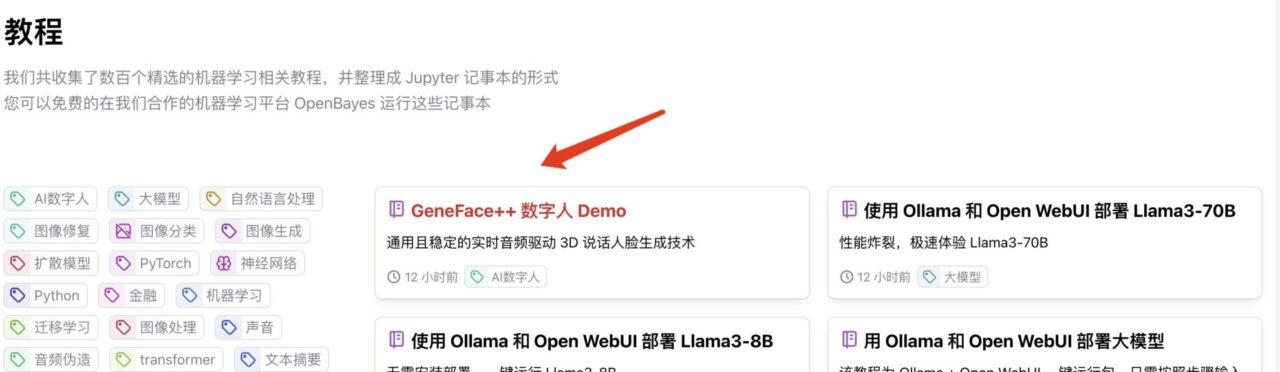

2. بعد الانتقال إلى الصفحة التالية، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.

3. انقر فوق "التالي: حدد معدل التجزئة" في الزاوية اليمنى السفلية.

4. بعد القفزة، حدد "NVIDIA GeForce RTX 4090" وانقر فوق "التالي: المراجعة".يمكن للمستخدمين الجدد التسجيل باستخدام رابط الدعوة أدناه للحصول على 4 ساعات من RTX 4090 + 5 ساعات من وقت الحوسبة المجاني لوحدة المعالجة المركزية!
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح للتسجيل):
https://openbayes.com/console/signup?r=6bJ0ljLFsFh_Vvej

5. انقر فوق "متابعة" وانتظر حتى يتم تخصيص الموارد. ستستغرق عملية الاستنساخ الأولى حوالي 3-5 دقائق. عندما تتغير الحالة إلى "قيد التشغيل"، انقر فوق "فتح مساحة العمل". إذا استمرت المشكلة لأكثر من 10 دقائق وظلت في حالة "تخصيص الموارد"، فحاول إيقاف الحاوية وإعادة تشغيلها. إذا لم تؤد إعادة التشغيل إلى حل المشكلة، فيرجى الاتصال بخدمة عملاء المنصة على الموقع الرسمي.



6. بعد فتح مساحة العمل، قم بإنشاء جلسة طرفية جديدة على صفحة بدء التشغيل، ثم أدخل الكود التالي في سطر الأوامر لبدء تشغيل البيئة. فقط انسخه ولصقه.
تصدير بيئة conda -p /output/geneface
تفعيل conda /output/geneface


7. انتظر لحظة ثم قم بتشغيل الأمر التالي في المحطة الطرفية لتكوين متغيرات البيئة.
مصدر bashrc

8. انتظر قليلاً، وأدخل الكود التالي في سطر الأوامر لبدء تشغيل WebUI، وانتظر لمدة دقيقة تقريبًا.
/openbayes/home/start_web.sh
9. عندما يعرض سطر الأوامر "جاري التشغيل على عنوان URL المحلي: https://0.0.0.0:8080"، انسخ عنوان API الموجود على اليمين إلى شريط عنوان المتصفح للوصول إلى واجهة GeneFace++.يرجى ملاحظة أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام وظيفة الوصول إلى عنوان API.

عرض التأثير
1. بعد فتح واجهة GeneFace++، قم باستيراد الفيديو المُعد مسبقًا، وحدد عدد خطوات التدريب "50000"، ثم انقر فوق "تدريب" لبدء التدريب.
ملحوظة: هذه الخطوة تتطلب الانتظار لمدة تزيد عن ساعتين. خلال هذه الفترة، يمكنك التحقق مرة أو مرتين من أن التدريب يتم بشكل طبيعي لتجنب فقدان الوقت الناجم عن مقاطعة العملية ولكن لا تزال تنتظر.
عدد خطوات التدريب هنا هو "50000" افتراضيًا. إذا كانت نتائج 50000 خطوة من التدريب ضعيفة، فيرجى تغيير بيانات التدريب وإعادة التدريب.

2. عند ظهور "نجاح التدريب"، قم بتحديث واجهة GeneFace++.

3. في واجهة GeneFace++، قم بتحميل الصوت على اليسار ولا تقم بتعديل معلمات الوحدة الوسطى.
حدد نموذج برنامج تشغيل الصوت "model_ckpt_steps_400000.ckpt" من النموذج الموجود على اليمين.
قم باختيار نموذج الجذع "model_ckpt_steps_50000.ckpt" الذي يتوافق مع التدريب الذي يقل عن 50000 خطوة.
قم باختيار نموذج الرأس "model_ckpt_steps_50000.ckpt" المقابل للتدريب الذي يقل عن 50000 خطوة.
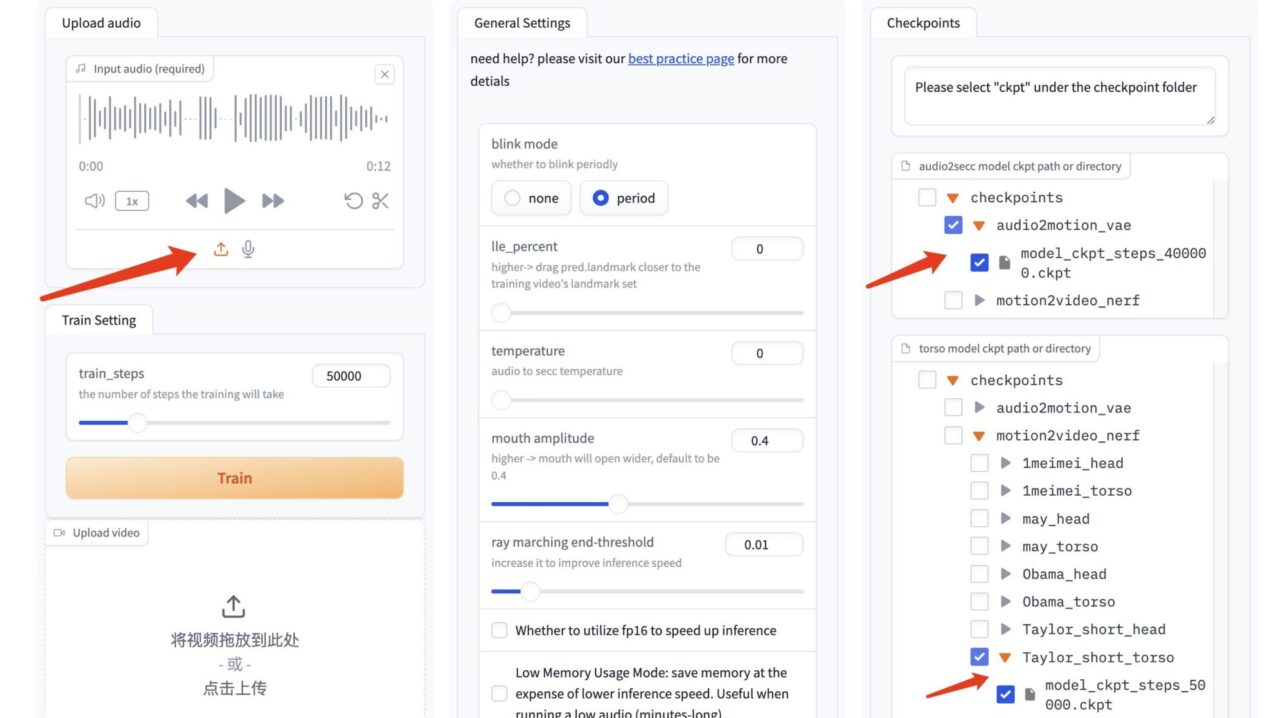
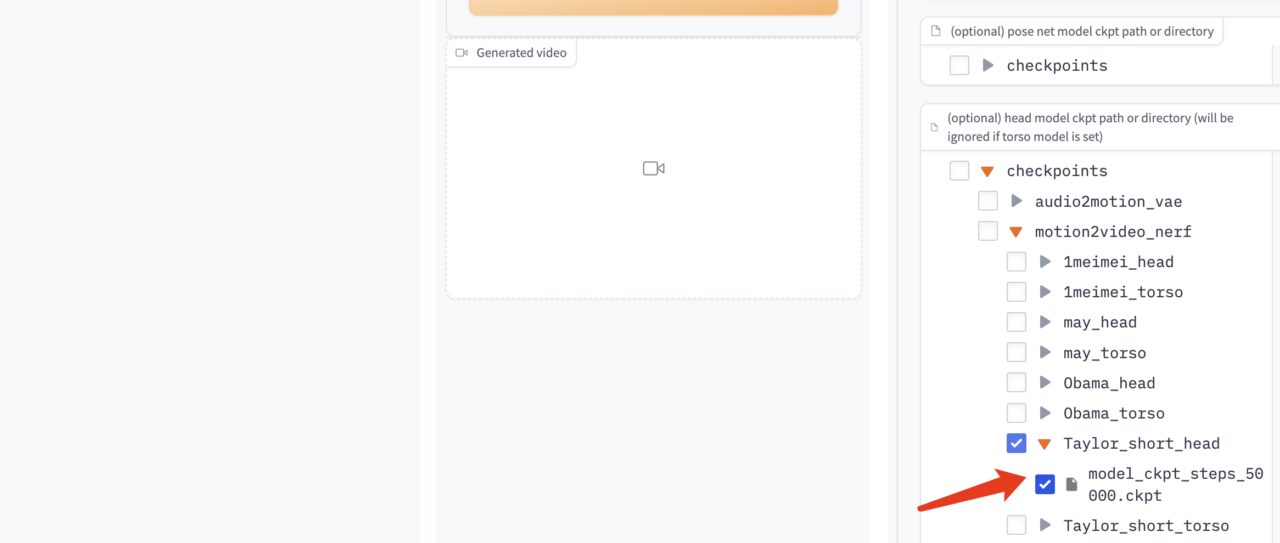
4. انقر فوق "إنشاء" لإنشاء التأثير.

5. إذا كنت تريد تدريبًا إضافيًا. احذف مجلد head_done ومجلد torso_done ضمن النموذج المقابل.
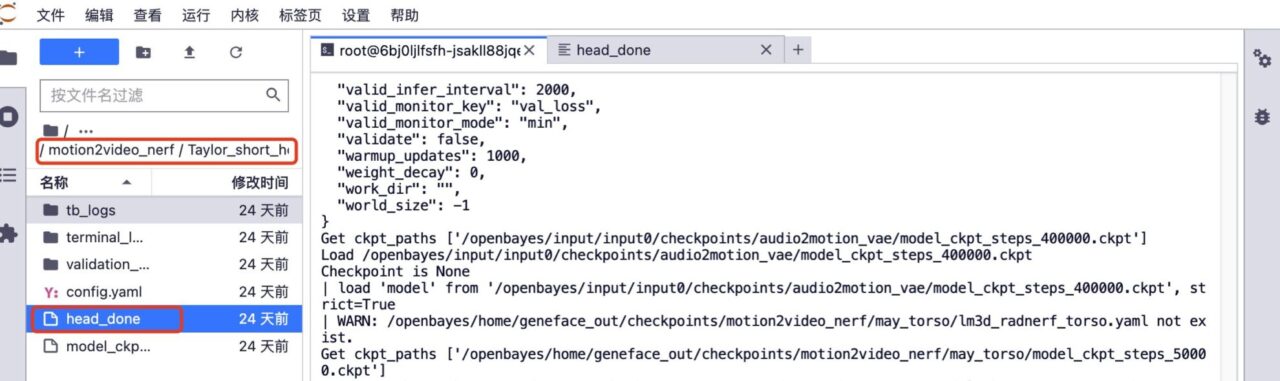
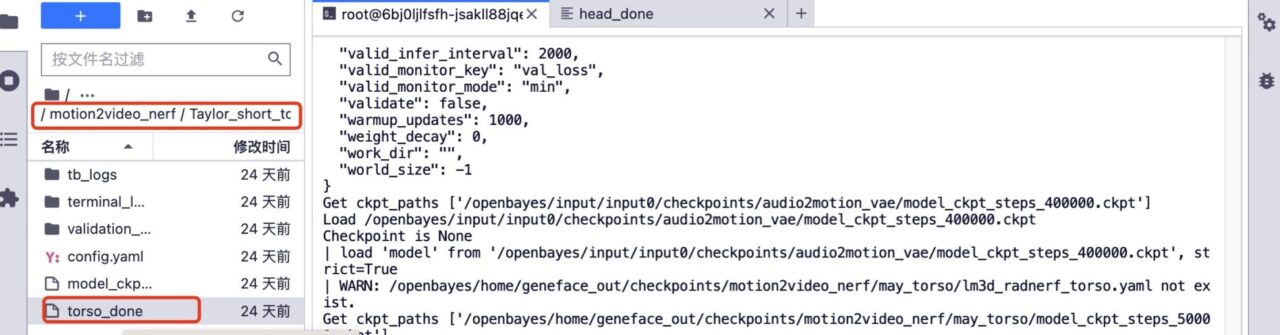
6. قم بتحميل فيديو التدريب السابق، مع الاحتفاظ باسم ملف الفيديو دون تغيير، وزيادة عدد خطوات التدريب، ثم انقر فوق "تدريب" لبدء التدريب.


7. بعد اكتمال التدريب، في واجهة GeneFace++، حدد نموذج الصوت الافتراضي، ونموذج الجذع المقابل لتدريب 150000 خطوة، ونموذج الرأس المقابل لتدريب 150000 خطوة. انقر فوق "إنشاء" لتوليد التأثير النهائي.
في الوقت الحاضر، أطلق الموقع الرسمي لـ HyperAI مئات من البرامج التعليمية المختارة المتعلقة بالتعلم الآلي، والتي تم تنظيمها في شكل Jupyter Notebook.
انقر على الرابط للبحث عن الدروس ومجموعات البيانات ذات الصلة:
ما سبق هو كل المحتوى الذي شاركه المحرر هذه المرة. آمل أن يكون هذا المحتوى مفيدًا لك. إذا كنت تريد أن تتعلم دروس تعليمية أخرى مثيرة للاهتمام، يرجى ترك رسالة أو إرسال رسالة خاصة لنا عنوان المشروع. سيقوم المحرر بتصميم دورة تدريبية مخصصة لك وتعليمك كيفية اللعب باستخدام الذكاء الاصطناعي.
مراجع:
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/128895215








