Command Palette
Search for a command to run...
أطلقت شركة NVIDIA Huang Renxun معالج GB200، الذي يتمتع بقدرة استدلال أعلى بمقدار 30 مرة من H100 واستهلاك طاقة أقل بمقدار 25 مرة، مما يحول قدرات AI4S إلى خدمات مصغرة

"لقد حانت لحظة الذكاء الاصطناعي في الآيفون." لا تزال الكلمات الذهبية التي ألقاها هوانغ رينكسون في مؤتمر NVIDIA GTC 2023 حاضرة في أذهاننا. وفي هذا العام أيضًا، أثبت تطور الذكاء الاصطناعي أن ما قاله صحيح.
على مر السنين، ومع تسارع تطوير الذكاء الاصطناعي وصعوبة هز تكنولوجيا Nvidia والخندق البيئي، تطورت GTC تدريجيًا من مؤتمر فني أولي إلى حدث صناعي للذكاء الاصطناعي يحظى باهتمام سلسلة الصناعة بأكملها. قد تكون "العضلة" التي استعرضتها شركة Nvidia بمثابة حافز مهم للابتكار في الصناعة.
مؤتمر GTC AI لعام 2024 هنا كما هو مقرر. من 18 مارس إلى 21 مارس، سيكون هناك أكثر من 900 اجتماع وأكثر من 20 محاضرة تقنية. وبطبيعة الحال، كان الخطاب الأكثر لفتاً للانتباه هو خطاب "الجلد الأصفر". وفقًا للجدول المعلن عنه مسبقًا، سيبدأ خطاب هوانغ رينكسون في الساعة الرابعة صباحًا يوم 19 مارس بتوقيت بكين، ويستمر حتى السادسة صباحًا. في هذه الأثناء، ألقى هوانغ سلسلة من "القنابل النووية للذكاء الاصطناعي" في جلسة مشاركة استمرت ساعتين:
* Blackwell، منصة GPU من الجيل الجديد
* أول شريحة تعتمد على بلاكويل، GB200 Grace Blackwell
* الجيل القادم من أجهزة الكمبيوتر العملاقة ذات الذكاء الاصطناعي DGX SuperPOD
* منصة الحوسبة الفائقة للذكاء الاصطناعي DGX B200
* الجيل الجديد من مفاتيح الشبكة سلسلة X800
* خدمة الحوسبة الكمومية السحابية
* Earth-2، منصة سحابية توأمية رقمية للمناخ
* خدمات الذكاء الاصطناعي التوليدية
* 5 واجهات برمجة تطبيقات Omniverse Cloud جديدة
* DRIVE Thor، وهي منصة حوسبة داخل السيارة مصممة لتطبيقات الذكاء الاصطناعي التوليدية
* نموذج قاعدة BioNeMo
رابط إعادة البث المباشر:
https://www.bilibili.com/video/BV1Z6421c7V6/?spm_id_from=333.337.search-card.all.click
cuLitho في العمل
في مؤتمر GTC العام الماضي، أطلقت NVIDIA مكتبة الطباعة الحجرية الحاسوبية - cuLitho، مدعية أنها قادرة على تسريع الطباعة الحجرية الحاسوبية بما يزيد عن 40 مرة. أعلن هوانج رينكسون اليوم أن شركتي TSMC وSynopsys قامتا بدمج تقنية NVIDIA cuLipo مع برمجياتهما وعمليات التصنيع وأنظمتهما لتسريع تصنيع الرقائق.عند اختبار cuLitho على سير عمل مشترك، حققت الشركتان بشكل مشترك تسريعًا بمقدار 45 ضعفًا للتدفقات المنحنية وتحسينًا في الكفاءة بمقدار 60 ضعفًا تقريبًا للتدفقات التقليدية على طراز مانهاتن.
بالإضافة إلى ذلك، قامت NVIDIA بتطوير خوارزميات لتطبيق الذكاء الاصطناعي التوليدي لتعزيز قيمة منصة cuLitho بشكل أكبر. على وجه التحديد، بناءً على تحسين كفاءة عملية الإنتاج استنادًا إلى cuLitho،هذه الخوارزمية التوليدية للذكاء الاصطناعي أسرع أيضًا بمرتين.
يُقال أنه من خلال تطبيق الذكاء الاصطناعي التوليدي، يمكن إنشاء حل قناع عكسي مثالي تقريبًا، مع الأخذ في الاعتبار حيود الضوء، ثم استخلاص القناع النهائي من خلال الطرق الفيزيائية التقليدية، مما يؤدي في النهاية إلى زيادة سرعة عملية تصحيح القرب البصري (OPC) بالكامل بمقدار 2 مرات.
منصة بلاكويل للذكاء الاصطناعي التوليدي على نطاق تريليون معلمة

إن المقدمة أعلاه لتطبيق cuLitho هي بمثابة "مقبلات"، توضح آفاق تطوير تقنية الطباعة الحجرية الحاسوبية، وإلى حد ما، توفر ضمانة أساسية للترقية إلى جيل جديد من شرائح الذكاء الاصطناعي من NVIDIA.
وبعد ذلك يبدأ الطبق الرئيسي. وبعد اتباع تقليد NVIDIA المتمثل في تحديث بنية وحدة معالجة الرسوميات الخاصة بها كل عامين، فإن أول منتج ناجح قدمه هوانغ هو وحدة معالجة الرسوميات الجديدة الأكبر حجمًا - منصة Blackwell. وقال:يعتبر Hopper رائعًا، لكننا نحتاج إلى وحدات معالجة رسومية أكثر قوة.
تم تسمية مبنى بلاكويل تكريمًا لديفيد هارولد بلاكويل، أول أمريكي من أصل أفريقي يتم انتخابه لعضوية الأكاديمية الوطنية للعلوم.

من حيث الأداء، تمتلك بلاكويل 6 تقنيات ثورية:
* أقوى شريحة في العالم:يتم تصنيع وحدة معالجة الرسوميات ذات بنية Blackwell باستخدام عملية TSMC 4NP مخصصة وتحتوي على 208 مليار ترانزستور. يقوم بربط شريحتي GPU متطرفتين في وحدة معالجة رسوميات موحدة من خلال رابط من شريحة إلى شريحة بسرعة 10 تيرابايت/ثانية. محرك المحولات من الجيل الثاني: سيدعم Blackwell مضاعفة حجم الحوسبة والنموذج استنادًا إلى قدرات الاستدلال بالذكاء الاصطناعي ذات النقطة العائمة المكونة من 4 بتات الجديدة.
* الجيل الخامس من NVLink:توفر أحدث نسخة من NVIDIA NVLink معدل نقل بيانات ثنائي الاتجاه يبلغ 1.8 تيرابايت/ثانية لكل وحدة معالجة رسومية، مما يضمن اتصالاً سلسًا عالي السرعة بين ما يصل إلى 576 وحدة معالجة رسومية لتنفيذ أكثر أنظمة LLM تعقيدًا.
* محرك RAS:تتضمن وحدات معالجة الرسومات التي تعمل بتقنية Blackwell محركًا مخصصًا للموثوقية والتوافر والقدرة على الخدمة. بالإضافة إلى ذلك، تضيف بنية Blackwell قدرات على مستوى الشريحة لتشغيل التشخيص والتنبؤ بمشكلات الموثوقية باستخدام الصيانة الوقائية القائمة على الذكاء الاصطناعي. ويعمل هذا على تعظيم وقت تشغيل النظام، وتحسين مرونة عمليات نشر الذكاء الاصطناعي على نطاق واسع، وتمكينها من العمل دون انقطاع لأسابيع أو حتى أشهر، وتقليل تكاليف التشغيل.
* الذكاء الاصطناعي الآمن:كما أنه يحمي نماذج الذكاء الاصطناعي وبيانات العملاء دون المساس بالأداء ويدعم بروتوكولات تشفير الواجهة الأصلية الجديدة، وهو أمر بالغ الأهمية للصناعات الحساسة للخصوصية مثل الرعاية الصحية والخدمات المالية.
* محرك الضغط:يدعم محرك فك الضغط المخصص أحدث التنسيقات ويسرع استعلامات قاعدة البيانات، مما يوفر أعلى أداء لتحليلات البيانات وعلوم البيانات.
في الوقت الحاضر، تولت AWS وGoogle وMeta وMicrosoft وOpenAI وTesla وشركات أخرى زمام المبادرة في "حجز" منصة Blackwell.
GB200 جريس بلاكويل

تمت تسمية الشريحة الأولى المعتمدة على Blackwell باسم GB200 Grace Blackwell Superchip.يقوم هذا النظام بربط وحدتي معالجة رسوميات NVIDIA B200 Tensor Core بوحدة المعالجة المركزية NVIDIA Grace عبر اتصال NVLink من شريحة إلى شريحة بسرعة 900 جيجابايت/ثانية وباستهلاك منخفض للغاية للطاقة.
ومن بينها، تحتوي وحدة معالجة الرسوميات B200 على عدد من الترانزستورات يزيد عن ضعف عدد الترانزستورات الموجودة في وحدة معالجة الرسوميات H100 الحالية، أي 208 مليار ترانزستور. كما يمكنها توفير 20 بيتافلوب من أداء الحوسبة العالية من خلال وحدة معالجة رسومية واحدة، في حين أن H100 واحد لا يمكنه توفير سوى 4 بيتافلوب كحد أقصى من قوة الحوسبة بالذكاء الاصطناعي. علاوة على ذلك، تم تجهيز وحدة معالجة الرسوميات B200 بذاكرة HBM3e بحجم 192 جيجابايت، مما يوفر ما يصل إلى 8 تيرابايت/ثانية من النطاق الترددي.

GB200 هو أحد المكونات الرئيسية لـ NVIDIA GB200 NVL72.NVL72 هو نظام متعدد العقد، مبرد بالسائل، مثبت على الرف.إنه مثالي لأحمال العمل التي تتطلب قدرًا كبيرًا من الحوسبة، فهو يجمع 36 شريحة فائقة من Grace Blackwell، بما في ذلك 72 وحدة معالجة رسومية من Blackwell و36 وحدة معالجة مركزية من Grace، مترابطة بواسطة NVLink من الجيل الخامس.
بالإضافة إلى ذلك، يتضمن GB200 NVL72 وحدة معالجة البيانات NVIDIA BlueField®-3، والتي تعمل على تمكين تسريع الشبكة السحابية، والتخزين القابل للتكوين، وأمان الثقة الصفرية، ومرونة الحوسبة بواسطة وحدة معالجة الرسومات في السحب ذات الذكاء الاصطناعي واسع النطاق. توفر GB200 NVL72 أداءً أفضل بما يصل إلى 30 مرة في أحمال عمل الاستدلال LLM بتكلفة أقل واستهلاك طاقة أقل بما يصل إلى 25 مرة من وحدة معالجة الرسومات NVIDIA H100 Tensor Core مع نفس عدد وحدات معالجة الرسومات.
حاسوب الذكاء الاصطناعي العملاق من الجيل التالي DGX SuperPOD
يستخدم NVIDIA DGX SuperPOD بنية جديدة مثبتة على الرف ومبردة بالسائل ويتم بناؤها من أنظمة NVIDIA DGX GB200.إنه يوفر 11.5 إكسافلوب من قوة الحوسبة الفائقة للذكاء الاصطناعي بدقة FP4 و240 تيرابايت من الذاكرة السريعة.ويمكن توسيعها لتحقيق أداء أعلى باستخدام رفوف إضافية. يتميز DGX SuperPOD بإدارة تنبؤية ذكية تراقب باستمرار آلاف نقاط البيانات عبر الأجهزة والبرامج للتنبؤ بمصادر التوقف عن العمل وانعدام الكفاءة واعتراضها، مما يوفر الوقت والطاقة وتكاليف الحوسبة.
تم تجهيز نظام DGX GB200 بـ 36 شريحة NVIDIA GB200 فائقة، بما في ذلك 36 وحدة معالجة مركزية NVIDIA Grace و72 وحدة معالجة رسومية NVIDIA Blackwell، متصلة بجهاز كمبيوتر فائق عبر NVLink من الجيل الخامس.
يمكن لكل DGX SuperPOD أن يحمل ثمانية أو أكثر من شرائح DGX GB200، والتي يمكن توسيع نطاقها إلى عشرات الآلاف من شرائح GB200 الفائقة المتصلة عبر NVIDIA Quantum InfiniBand. على سبيل المثال، يستطيع المستخدمون توصيل 576 وحدة معالجة رسومية من Blackwell إلى ثمانية أجهزة DGX GB200 استنادًا إلى التوصيل البيني NVLink.
منصة الحوسبة الفائقة للذكاء الاصطناعي DGX B200
DGX B200 عبارة عن منصة حوسبة لتدريب نماذج الذكاء الاصطناعي والضبط الدقيق والاستدلال باستخدام تصميم DGX التقليدي المثبت على الرف والمبرد بالهواء. يحقق نظام DGX B200 دقة FP4 في بنية Blackwell الجديدة، مما يوفر ما يصل إلى 144 بيتافلوب من أداء الحوسبة بالذكاء الاصطناعي، و1.4 تيرابايت من ذاكرة وحدة معالجة الرسومات الضخمة، و64 تيرابايت/ثانية من عرض النطاق الترددي للذاكرة.تمت زيادة سرعة الاستدلال في الوقت الفعلي للنماذج التي تحتوي على تريليون معلمة بمقدار 15 مرة مقارنة بالجيل السابق.
يعتمد جهاز DGX B200 على بنية Blackwell الجديدة، وهو مزود بثمانية وحدات معالجة رسومية من Blackwell ومعالجين من الجيل الخامس من Intel Xeon. يمكن للمستخدمين أيضًا إنشاء DGX SuperPOD باستخدام نظام DGX B200. من أجل الاتصال بالشبكة، تم تجهيز DGX B200 بثمانية بطاقات شبكة NVIDIA ConnectX™-7 ووحدتي معالجة بيانات BlueField-3، مما يوفر ما يصل إلى 400 جيجابايت في الثانية من عرض النطاق الترددي.
سلسلة مفاتيح الشبكة من الجيل الجديد - X800
وتشير التقارير إلى أن الجيل الجديد من مفاتيح الشبكة سلسلة X800 مصمم للذكاء الاصطناعي على نطاق واسع، مما يكسر حدود أداء الشبكة لأحمال عمل الحوسبة والذكاء الاصطناعي.
تتضمن المنصة مفاتيح NVIDIA Quantum Q3400 وبطاقات الشبكة الفائقة NVIDIA ConnectX@-8، مما يحقق معدل نقل بيانات من البداية إلى النهاية يبلغ 800 جيجابايت في الثانية، وهو معدل رائد في الصناعة.تمت زيادة سعة النطاق الترددي بمقدار 5 مرات مقارنة بالجيل السابق من المنتجات.وفي الوقت نفسه، ومن خلال اعتماد بروتوكول التجميع والتخفيض الهرمي القابل للتطوير (SHARPv4) من NVIDIA، فقد حققت ما يصل إلى 14.4 تيرا فلوب من قوة الحوسبة داخل الشبكة.تمت زيادة الأداء بما يصل إلى 9 مرات مقارنة بالجيل السابق.
خدمات الحوسبة الكمومية السحابية تعمل على تسريع البحث العلمي
تعتمد خدمة الحوسبة الكمومية السحابية من NVIDIA على منصة الحوسبة الكمومية مفتوحة المصدر CUDA-Q الخاصة بالشركة.ثلاثة أرباع الشركات التي تنشر حاليًا وحدات المعالجة الكمومية (QPUs) في الصناعة تستخدم هذه المنصة. تتيح خدمة الحوسبة الكمية السحابية من Nvidia للمستخدمين بناء واختبار خوارزميات وتطبيقات كمية جديدة في السحابة لأول مرة، بما في ذلك أجهزة محاكاة قوية وأدوات برمجة هجينة كمية.
تتمتع سحابة الحوسبة الكمومية بإمكانيات قوية وتكاملات برمجية مع جهات خارجية لتسريع الاكتشاف العلمي، بما في ذلك:
* مُحَلِّل ذاتي كمي توليدي، تم تطويره بالتعاون مع جامعة تورنتو، والذي يستخدم نماذج لغوية كبيرة لتمكين أجهزة الكمبيوتر الكمومية من العثور على طاقة الحالة الأرضية للجزيئات بسرعة أكبر.
* يتيح تكامل Classiq مع CUDA-Q للباحثين الكموميين إنشاء برامج كمية كبيرة ومعقدة وتحليل الدوائر الكمية وتنفيذها بشكل عميق.
* يمكن لـ QC Ware Promethium حل مشاكل الكيمياء الكمومية المعقدة مثل المحاكاة الجزيئية.
إطلاق Earth-2، منصة سحابية توأمية رقمية للمناخ
يهدف مشروع Earth-2 إلى محاكاة وتصور الطقس والمناخ على نطاق واسع، وبالتالي تمكين التنبؤ بالطقس المتطرف. توفر واجهة برمجة التطبيقات Earth-2 نماذج الذكاء الاصطناعي وتستخدم نموذج CorrDiff.
CorrDiff هو نموذج ذكاء اصطناعي توليدي جديد أطلقته شركة NVIDIA. ويستخدم نموذج انتشار SOTA.تتمتع الصور الناتجة بدقة أعلى بنحو 12.5 مرة من النماذج الرقمية الموجودة، وهي أسرع بنحو 1000 مرة، وأكثر كفاءة في استخدام الطاقة بنحو 3000 مرة.ويتغلب على عدم دقة التنبؤات ذات الدقة الخشنة ويدمج المقاييس التي تعتبر حاسمة لاتخاذ القرار.

CorrDiff هو نموذج الذكاء الاصطناعي التوليدي الأول من نوعه والذي يوفر دقة فائقة ويقوم بتوليف مقاييس مهمة جديدة ويتعلم الفيزياء الخاصة بالطقس المحلي الدقيق من مجموعات البيانات عالية الدقة.
إطلاق خدمات الذكاء الاصطناعي التوليدية لتعزيز تطوير الأدوية وتكرار التكنولوجيا الطبية والصحة الرقمية
تتضمن مجموعة خدمات الرعاية الصحية المصغرة الجديدة من NVIDIA نماذج الذكاء الاصطناعي NVIDIA NIM™ المحسّنة وتدفقات عمل واجهة برمجة التطبيقات القياسية في الصناعة والتي تعمل كعناصر أساسية لإنشاء ونشر التطبيقات السحابية الأصلية. تتضمن هذه الخدمات المصغرة قدرات مثل التصوير المتقدم واللغة الطبيعية والتعرف على الكلام وتوليد علم الأحياء الرقمي والتنبؤ والمحاكاة.
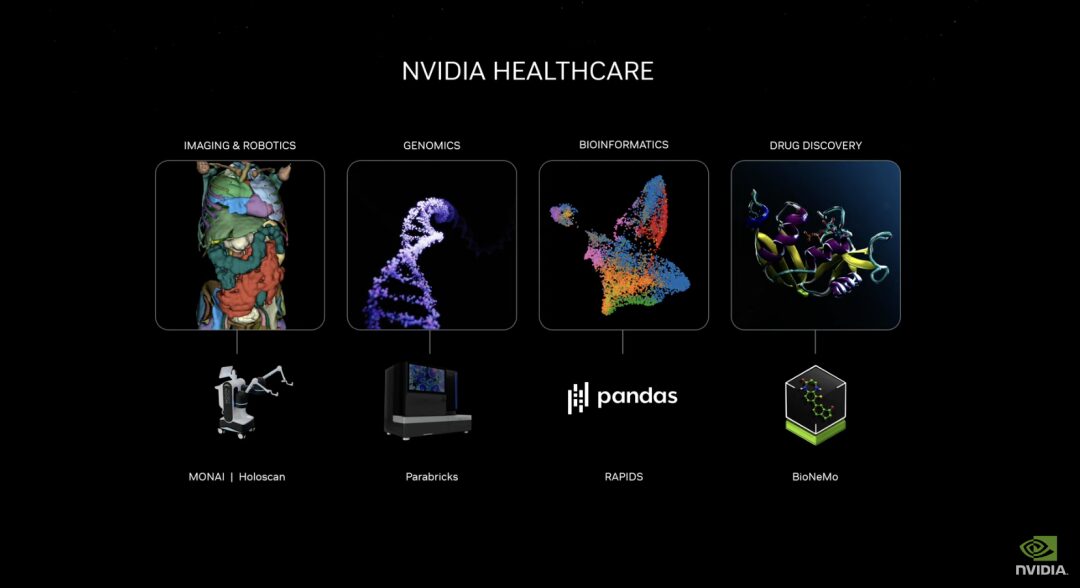
بالإضافة إلى ذلك، أصبحت مجموعات تطوير البرامج المعجلة من NVIDIA والأدوات ذات الصلة، بما في ذلك Parabricks® وMONAI وNeMo™ وRiva وMetropolis، متاحة الآن من خلال الخدمات المصغرة NVIDIA CUDA-X™.
خدمة الاستدلال المصغرة
إصدار العشرات من خدمات الذكاء الاصطناعي التوليدية على مستوى المؤسسات والتي يمكن للشركات استخدامها لإنشاء ونشر تطبيقات مخصصة على أنظمتها الخاصة مع الاحتفاظ بملكيتها الفكرية.
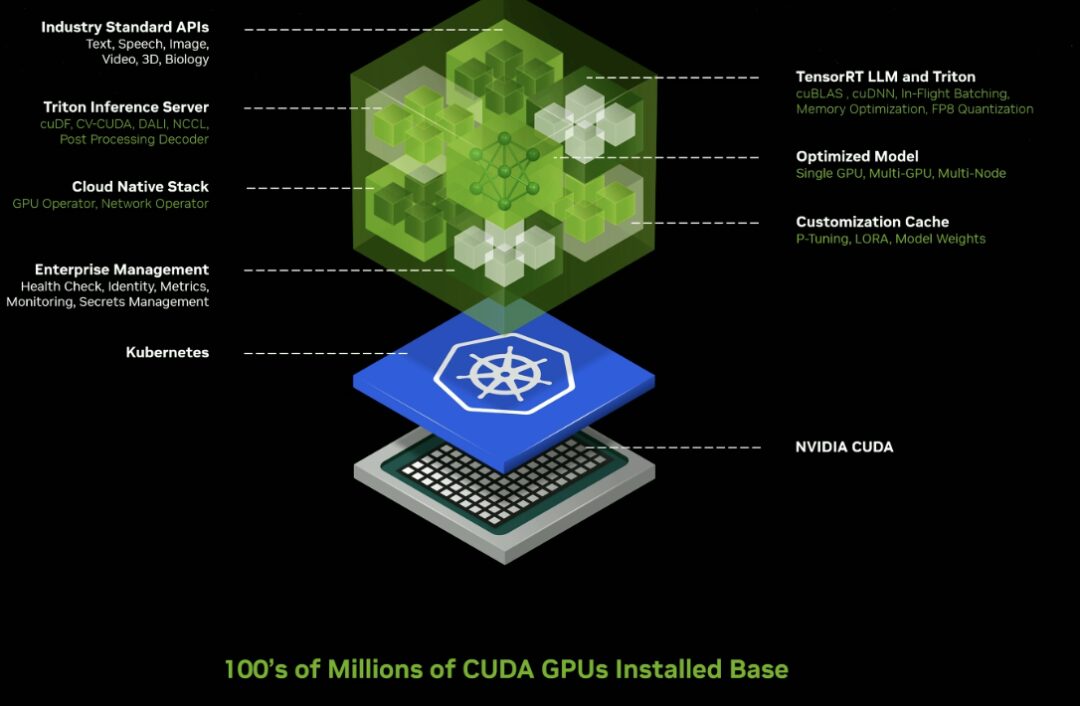
خدمات NVIDIA NIM Microservices وCloud Endpoints الجديدة المعجلة بواسطة وحدة معالجة الرسوميات للنماذج الذكية المدربة مسبقًا والمُحسّنة للعمل على مئات الملايين من وحدات معالجة الرسوميات الممكّنة بتقنية CUDA عبر السحابات ومراكز البيانات ومحطات العمل وأجهزة الكمبيوتر الشخصية.
يمكن للمؤسسات استخدام الخدمات المصغرة لتسريع معالجة البيانات، وتخصيص LLM، والاستدلال، وتعزيز الاسترجاع، والحماية؛
تم اعتماده من قبل منظومة واسعة من الذكاء الاصطناعي، بما في ذلك موفري منصات التطبيقات الرائدين Cadence وCrowdStrike وSAP وServiceNow وغيرهم.
توفر NIM Microservices حاويات جاهزة مسبقًا مدعومة ببرنامج الاستدلال NVIDIA، بما في ذلك Triton Inference Server™ وTensorRT™-LLM، مما يمكن أن يقلل وقت النشر من أسابيع إلى دقائق.
إصدار واجهة برمجة التطبيقات السحابية Omniverse لتمكين أدوات برمجيات التوأم الرقمي الصناعي
باستخدام خمس واجهات برمجة تطبيقات سحابية جديدة من Omniverse، يمكن للمطورين دمج تقنيات Omniverse الأساسية مباشرة في تطبيقات برمجيات التصميم والأتمتة الرقمية الحالية، بالإضافة إلى سير عمل المحاكاة لاختبار وتحقق الروبوتات أو السيارات ذاتية القيادة، مثل بث التوائم الرقمية الصناعية التفاعلية إلى Apple Vision Pro.
تتضمن واجهات برمجة التطبيقات هذه ما يلي:
* عرض الدولار الأمريكي:إنشاء عرض NVIDIA RTX™ لبيانات OpenUSD العالمية المتتبعة بالأشعة
* كتابة الدولار الأمريكي:يسمح للمستخدمين بتعديل بيانات OpenUSD والتفاعل معها.
* استعلام بالدولار الأمريكي:دعم استعلام المشهد والتفاعل مع المشهد.
* إشعار بالدولار الأمريكي:تتبع تغييرات الدولار الأمريكي وتوفير التحديثات.
* قناة أومنيفرس:ربط المستخدمين والأدوات والواقع لتحقيق التعاون بين السيناريوهات
يعتقد هوانغ رينكسون أنه في المستقبل، كل شيء يتم تصنيعه سيكون له توأم رقمي. Omniverse هو نظام التشغيل لبناء وتشغيل التوائم الرقمية للواقع المادي. تشكل تقنية Omniverse والذكاء الاصطناعي التوليدي التقنيات الأساسية لرقمنة سوق الصناعات الثقيلة التي تبلغ قيمتها 50 تريليون دولار.
DRIVE Thor: الذكاء الاصطناعي التوليدي مع بنية Blackwell لدعم القيادة الذاتية
DRIVE Thor عبارة عن منصة حوسبة داخل السيارة مصممة لتطبيقات الذكاء الاصطناعي التوليدي، حيث توفر قيادة محاكاة غنية بالميزات بالإضافة إلى قدرات قيادة آلية للغاية على منصة مركزية. باعتباره الجيل القادم من الكمبيوتر المركزي للسيارات ذاتية القيادة، فهو آمن وموثوق به، ويوحد الوظائف الذكية في نظام واحد لتحسين الكفاءة وتقليل تكلفة النظام بأكمله.
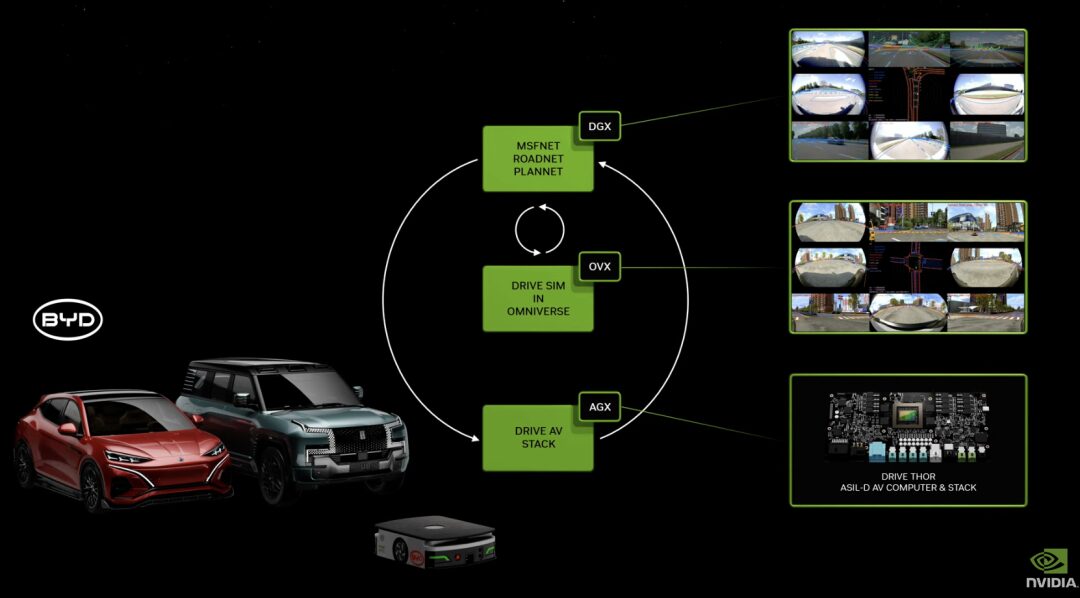
سيتم أيضًا دمج بنية NVIDIA Blackwell الجديدة في DRIVE Thor.تم تصميم الهندسة المعمارية لتناسب أحمال عمل Transformer وLLM والذكاء الاصطناعي التوليدي.
بيونيمو: المساعدة في اكتشاف الأدوية
النموذج الأساسي لـ BioNeMo قادر على تحليل تسلسلات الحمض النووي، والتنبؤ بتغيرات شكل البروتينات تحت تأثير جزيئات الدواء، وتحديد وظيفة الخلايا على أساس الحمض النووي الريبي.
حاليًا، يعتمد أول نموذج جينوم DNABERT الذي تقدمه BioNeMo على تسلسلات الحمض النووي ويمكن استخدامه للتنبؤ بوظائف مناطق محددة من الجينوم، وتحليل آثار الطفرات والاختلافات الجينية، وما إلى ذلك. أما نموذجها الثاني، scBERT، والذي سيتم إطلاقه قريبًا، فيتم تدريبه بناءً على بيانات تسلسل الحمض النووي الريبي أحادي الخلية. يمكن للمستخدمين تطبيقه على المهام اللاحقة مثل التنبؤ بتأثيرات إخراج الجينات (أي حذف أو إلغاء تنشيط جينات معينة) وتحديد أنواع الخلايا مثل الخلايا العصبية أو خلايا الدم أو خلايا العضلات.
ويقال إن هناك حاليًا أكثر من 100 شركة حول العالم تعمل على تطوير عملية البحث والتطوير الخاصة بها استنادًا إلى BioNeMo، بما في ذلك شركة Astellas Pharma التي يقع مقرها في طوكيو، وشركة تطوير البرامج الحاسوبية Cadence، وشركة تطوير الأدوية Iambic، وغيرها.
الكلمات الأخيرة
بالإضافة إلى العديد من المنتجات الجديدة المذكورة أعلاه، قدم هوانغ رينكسون أيضًا تخطيط NVIDIA في مجال الروبوتات. وأضاف هوانج أن كل ما يتحرك هو روبوت، وصناعة السيارات ستكون جزءا مهما منه. في الوقت الحالي، يتم استخدام أجهزة كمبيوتر NVIDIA في السيارات والشاحنات وروبوتات التوصيل وسيارات الأجرة الروبوتية. وفي وقت لاحق، أطلقت الشركة أيضًا مجموعة تطوير البرامج Isaac Perceptor، والنموذج الأساسي العالمي GR00T للروبوتات البشرية، وجهاز الكمبيوتر الجديد Jetson Thor للروبوتات البشرية المستندة إلى نظام NVIDIA Thor على الشريحة، وأجرت ترقيات رئيسية لمنصة الروبوت NVIDIA Isaac.
باختصار، كانت جلسة المشاركة التي استمرت لمدة ساعتين مليئة بالمنتجات عالية الأداء وعروض النماذج. إن هذا المؤتمر الصحفي السريع الوتيرة والغني بالمحتوى يشبه تمامًا حالة التطور الحالية لصناعة الذكاء الاصطناعي - سريعة ومزدهرة.
باعتبارها الأساس لعصر الذكاء الاصطناعي، فإن قوة الحوسبة التي تمثلها الرقائق عالية الأداء هي المفتاح لتحديد دورة التطوير واتجاه الصناعة. ليس هناك شك في أن شركة Nvidia لديها حاليًا خندق لا يتزعزع. وعلى الرغم من أن العديد من الشركات بدأت في مهاجمة هوانغ، وتقوم شركات OpenAI وMicrosoft وGoogle وغيرها أيضًا بتكوين "جيوشها" الخاصة، فقد يكون هذا حافزًا أكبر لشركة Nvidia، التي لا تزال تتحرك للأمام بسرعة عالية.
الآن انتهى البث المباشر عبر الإنترنت. بعد كل إصدار لمنتج جديد، سوف يقوم هوانغ رينكسون بالتعريف بالشركاء الذين "حجزوا" الخدمات الجديدة، وجميع الشركات الكبرى موجودة في القائمة دون استثناء. وفي المستقبل، نتوقع أيضًا أن تتمكن الشركات الموجودة حاليًا في طليعة الصناعة من الاستفادة من الإنتاجية المتقدمة في الصناعة لتقديم المزيد من المنتجات والتطبيقات المبتكرة.








