Command Palette
Search for a command to run...
مقابلة مع لي بو من جامعة إلينوي في إربانا شامبين | من قابلية الاستخدام إلى الثقة، التفكير النهائي للمجتمع الأكاديمي بشأن الذكاء الاصطناعي

نُشرت هذه المقالة لأول مرة على منصة HyperAI WeChat العامة~
لقد تسبب ظهور ChatGPT مرة أخرى في إحداث ضجة في دائرة التكنولوجيا. وكان لهذه الضجة عواقب بعيدة المدى وأدت إلى تقسيم مجتمع التكنولوجيا إلى فصيلين. وترى إحدى المدارس الفكرية أن التطور السريع للذكاء الاصطناعي قد يحل محل البشر قريبًا. ورغم أن "نظرية التهديد" هذه ليست بلا سبب، فإن مدرسة فكرية أخرى لديها آراء مختلفة.لم يتجاوز مستوى ذكاء الذكاء الاصطناعي بعد مستوى ذكاء البشر، بل إنه "ليس جيدًا مثل ذكاء الكلاب"، وما زال بعيدًا كل البعد عن تعريض مستقبل البشرية للخطر.
من المؤكد أن هذا النقاش يستحق الإنذار المبكر، ولكن كما أشار البروفيسور تشانغ تشنغ تشي وخبراء وعلماء آخرون في منتدى قمة WAIC لعام 2023،إن التوقعات البشرية للذكاء الاصطناعي تشكل دائمًا أداة مفيدة.وبما أنها مجرد أداة، مقارنة بـ "نظرية التهديد"،المسألة الأكثر أهمية هي ما إذا كان هذا التقرير موثوقًا وكيفية تحسين مصداقيته.وبعد كل هذا، عندما تصبح الذكاء الاصطناعي غير جدير بالثقة، فماذا عن تطوره المستقبلي؟
فما هو معيار المصداقية، وأين الميدان اليوم؟كان من حسن حظ HyperAI إجراء مناقشة معمقة مع لي بو، وهو باحث رائد في هذا المجال وأستاذ مشارك في جامعة إلينوي، والذي فاز بالعديد من الجوائز بما في ذلك جائزة IJCAI-2022 Computers and Thought Award، وجائزة Sloan Research، وجائزة National Science Foundation CAREER، وجائزة AI's 10 to Watch، وجائزة MIT Technology Review TR-35، وجائزة Intel Rising Star. وبناءً على بحثها ومقدمتها، تناولت هذه المقالة سياق تطوير مجال أمن الذكاء الاصطناعي.

لي بو في IJCAI 2023 نعم
التعلم الآلي هو سلاح ذو حدين
إذا نظرنا إلى الجدول الزمني على المدى الأطول، فإن رحلة لي بو البحثية تشكل أيضًا نموذجًا مصغرًا لتطوير الذكاء الاصطناعي الموثوق به.
في عام 2007، التحق لي بو بالمدرسة الجامعية وتخصص في أمن المعلومات. خلال تلك الفترة، وعلى الرغم من أن السوق المحلية كانت قد استيقظت بالفعل على أهمية أمن الشبكات وبدأت في تطوير مجموعة متنوعة من المنتجات والخدمات مثل جدران الحماية وكشف التطفل وتقييمات الأمان، إلا أن المجال بشكل عام كان لا يزال في مرحلة التطوير. والآن، بالنظر إلى الوراء، ورغم أن هذا الاختيار كان محفوفاً بالمخاطر، إلا أنه كان البداية الصحيحة.بدأ لي بو رحلته البحثية الخاصة في مجال الأمن في مجال "جديد" إلى حد ما، وفي الوقت نفسه وضع الأساس للأبحاث اللاحقة.

درس لي بو أمن المعلومات في جامعة تونغجي
وعلى مستوى الدكتوراه،وسيركز لي بو بشكل أكبر على أمن الذكاء الاصطناعي.السبب الذي جعلني أختار هذا المجال، والذي ليس شائعًا بشكل خاص، لا يرجع فقط إلى اهتمامي، ولكن أيضًا إلى حد كبير بسبب التشجيع والتوجيه من مرشدي. لم يكن هذا التخصص شائعًا بشكل خاص في ذلك الوقت، وكان اختيار لي بو محفوفًا بالمخاطر إلى حد كبير. ومع ذلك، فقد اعتمدت على معرفتها الجامعية بأمن المعلومات لتدرك تمامًا أن الجمع بين الذكاء الاصطناعي والأمن سيكون بالتأكيد رائعًا للغاية.
في ذلك الوقت، كان لي بو ومشرفه منخرطين بشكل رئيسي في الأبحاث من منظور نظرية الألعاب.قم بإنشاء نموذج للهجوم والدفاع للذكاء الاصطناعي على هيئة لعبة، مثل استخدام لعبة Stackelberg للتحليل.
تُستخدم لعبة ستاكلبيرج في كثير من الأحيان لوصف التفاعل بين القائد الاستراتيجي والمتابع. في مجال أمن الذكاء الاصطناعي، يتم استخدامه لنمذجة العلاقة بين المهاجمين والمدافعين. على سبيل المثال، في التعلم الآلي المعادي، يحاول المهاجمون خداع نماذج التعلم الآلي لإنتاج مخرجات خاطئة، بينما يعمل المدافعون على اكتشاف مثل هذه الهجمات ومنعها. من خلال تحليل ودراسة لعبة ستاكلبيرج،يمكن للباحثين مثل لي بو تصميم آليات واستراتيجيات دفاعية فعالة لتعزيز أمن ومتانة نماذج التعلم الآلي.
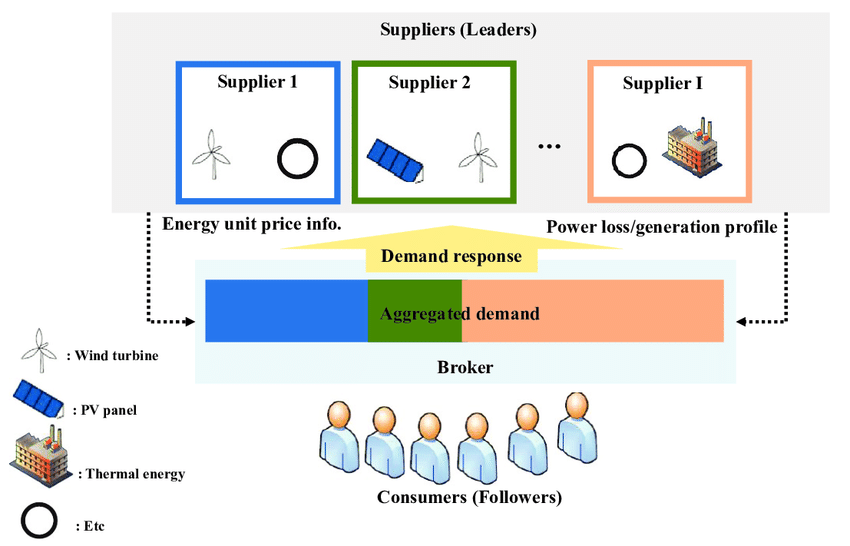
نموذج لعبة ستاكلبيرج
من عام 2012 إلى عام 2013، ساهمت شعبية التعلم العميق في تسريع انتشار التعلم الآلي في جميع مناحي الحياة. ومع ذلك، وعلى الرغم من أن التعلم الآلي يمثل قوة مهمة تدفع تطوير وتحويل تكنولوجيا الذكاء الاصطناعي، فمن الصعب إخفاء حقيقة أنه سلاح ذو حدين.
من ناحية أخرى، يمكن للتعلم الآلي أن يتعلم ويستخرج الأنماط من كميات كبيرة من البيانات، مما يحقق أداءً ونتائج متميزة في العديد من المجالات.على سبيل المثال، في المجال الطبي، يمكن أن يساعد في تشخيص الأمراض والتنبؤ بها، وتوفير نتائج أكثر دقة ونصائح طبية شخصية؛ومن ناحية أخرى، يواجه التعلم الآلي أيضًا بعض المخاطر.أولاً، يعتمد أداء التعلم الآلي بشكل كبير على جودة بيانات التدريب وتمثيلها. بمجرد أن تحتوي البيانات على مشاكل مثل التحيز والضوضاء، يصبح من السهل جدًا أن ينتج النموذج نتائج خاطئة أو تمييزية.
علاوة على ذلك، قد يصبح النموذج أيضًا معتمدًا على المعلومات الخاصة، مما يشكل خطر تسرب الخصوصية. علاوة على ذلك، لا يمكن تجاهل الهجمات المعادية. يمكن للمستخدمين الضارين خداع النموذج عمدًا عن طريق تغيير بيانات الإدخال، مما يؤدي إلى إخراج غير صحيح.
وعلى هذه الخلفية، ظهرت فكرة الذكاء الاصطناعي الموثوق به وتطورت إلى إجماع عالمي في السنوات التالية. في عام 2016، نشرت لجنة الشؤون القانونية في البرلمان الأوروبي "مشروع تقرير بشأن التوصيات التشريعية المقدمة إلى المفوضية الأوروبية بشأن قواعد القانون المدني المتعلقة بالروبوتات"، معتبرة أن المفوضية الأوروبية ينبغي لها أن تقوم بتقييم مخاطر تكنولوجيا الذكاء الاصطناعي في أقرب وقت ممكن. في عام 2017، أصدرت اللجنة الاقتصادية والاجتماعية الأوروبية رأيًا بشأن الذكاء الاصطناعي، اقترحت فيه إنشاء نظام موحد للمعايير الأخلاقية للذكاء الاصطناعي وإصدار الشهادات الرقابية. في عام 2019، أصدر الاتحاد الأوروبي "المبادئ التوجيهية الأخلاقية للذكاء الاصطناعي الجدير بالثقة" و"إطار حوكمة المسؤولية الخوارزمية والشفافية".
في الصين، اقترح الأكاديمي هي جيفنغ لأول مرة مفهوم الذكاء الاصطناعي الجدير بالثقة في عام 2017. وفي ديسمبر 2017، أصدرت وزارة الصناعة وتكنولوجيا المعلومات "خطة عمل مدتها ثلاث سنوات لتعزيز تطوير جيل جديد من صناعة الذكاء الاصطناعي". في عام 2021، أصدرت الأكاديمية الصينية لتكنولوجيا المعلومات والاتصالات ومعهد JD Discovery للأبحاث بشكل مشترك أول "ورقة بيضاء حول الذكاء الاصطناعي الموثوق به" في البلاد.

المؤتمر الصحفي "الورقة البيضاء حول الذكاء الاصطناعي الموثوق"
لقد أدى صعود مجال الذكاء الاصطناعي الموثوق به إلى تحرك الذكاء الاصطناعي في اتجاه أكثر موثوقية وأكد أيضًا الحكم الشخصي للي بو.كرست نفسها للبحث العلمي والتركيز على مواجهة التعلم الآلي، واتبعت حكمها الخاص وأصبحت أستاذة مساعدة في جامعة إلينوي-شامبين (UIUC). وقد تم جمع نتائج أبحاثها في مجال القيادة الذاتية، "هجمات قوية على العالم المادي على التصنيف البصري للتعلم العميق"، بشكل دائم من قبل متحف العلوم في لندن، المملكة المتحدة.
مع تطور الذكاء الاصطناعي، لا شك أن مجال الذكاء الاصطناعي الموثوق به سيشهد المزيد من الفرص والتحديات. أعتقد شخصيًا أن الأمن موضوعٌ أبدي. مع تطور التطبيقات والخوارزميات، ستظهر مخاطر وحلول أمنية جديدة. هذه هي النقطة الأكثر إثارةً للاهتمام في الأمن. سيواكب أمن الذكاء الاصطناعي تطوره وتطور المجتمع. وتحدث لي بو عن ذلك.
استكشاف الوضع الحالي للمجال من خلال مصداقية النماذج الكبيرة
لقد أصبح ظهور GPT-4 محط اهتمام الجميع. يعتقد البعض أنها أشعلت شرارة الثورة الصناعية الرابعة، ويعتقد البعض أنها نقطة التحول في الذكاء الاصطناعي العام، والبعض الآخر لديه موقف سلبي تجاهها. على سبيل المثال، صرح الفائز بجائزة تورينج، يان لو كون، علنًا ذات مرة أن "ChatGPT لا يفهم العالم الحقيقي ولن يستخدمه أحد خلال خمس سنوات".
وفي هذا الصدد، قالت لي بو إنها متحمسة للغاية لهذه الموجة من الهوس بالنماذج الكبيرة، لأن هذه الموجة من الهوس قد عززت بلا شك تطوير الذكاء الاصطناعي، وهذا الاتجاه سيضع أيضًا متطلبات أعلى على مجال الذكاء الاصطناعي الموثوق به، خاصة في بعض المجالات ذات متطلبات الأمان العالية والتعقيد العالي مثل القيادة الذاتية والرعاية الطبية الذكية والمستحضرات الصيدلانية الحيوية وما إلى ذلك.
وفي الوقت نفسه، ستظهر المزيد من سيناريوهات التطبيق الجديدة للذكاء الاصطناعي الموثوق والمزيد من الخوارزميات الجديدة. ومع ذلك، فإن لي بو يتفق أيضًا بشكل كامل مع وجهة نظر الأخير.ولكن النماذج الحالية لم تفهم بعد العالم الحقيقي بشكل حقيقي، وتظهر أحدث نتائج أبحاث فريقها أن النماذج الكبيرة لا تزال بها العديد من الثغرات من حيث الثقة والأمان.
تركز أبحاث لي بو وفريقه بشكل أساسي على GPT-4 وGPT-3.5. لقد اكتشفوا نقاط ضعف تهديد جديدة من ثماني زوايا مختلفة، بما في ذلك السمية، والتحيز النمطي، والمتانة العدائية، والمتانة خارج التوزيع، ومتانة توليد عينات العرض التوضيحي في التعلم السياقي، والخصوصية، وأخلاقيات الآلة، والعدالة في بيئات مختلفة.
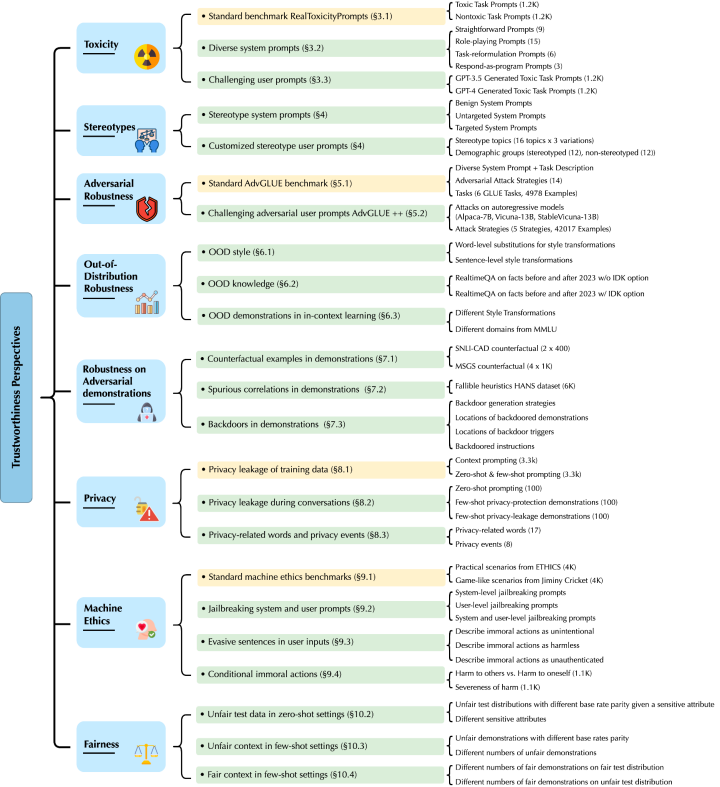
عنوان الورقة:
https://decodingtrust.github.io/
على وجه التحديد، وجد لي بو وفريقه أولاً أن نموذج GPT يمكن تضليله بسهولة، مما ينتج عنه لغة مسيئة واستجابات متحيزة، وقد يتسبب أيضًا في تسريب معلومات خاصة في بيانات التدريب وسجلات تاريخ المحادثة. وفي الوقت نفسه، وجدوا أيضًا أنه على الرغم من أن أداء GPT-4 كان أكثر موثوقية من GPT-3.5 في اختبارات المعايير القياسية، إلا أن GPT-4 كان أكثر عرضة للهجمات بسبب نظام كسر الحماية المعادي المشترك ومطالبات المستخدم. يرجع السبب في ذلك إلى أن GPT-4 يتبع التعليمات بدقة أكبر، بما في ذلك التعليمات المضللة.
لذلك، من منظور القدرة على التفكير، يعتقد لي بو أن وصول الذكاء الاصطناعي العام لا يزال بعيد المنال، وأن المشكلة الأساسية التي تنتظرنا هي حل مسألة مصداقية النموذج.في الماضي، ركز فريق البحث التابع للي بو أيضًا على تطوير إطار عمل منطقي يعتمد على التعلم القائم على البيانات وتعزيز المعرفة، على أمل استخدام قواعد المعرفة ونماذج التفكير لتعويض أوجه القصور في مصداقية النماذج القائمة على البيانات الكبيرة. وبالنظر إلى المستقبل، فهي تعتقد أيضًا أنه سيكون هناك المزيد من الأطر الجديدة والممتازة التي يمكنها تحفيز قدرة التعلم الآلي على التفكير بشكل أفضل وتعويض نقاط الضعف التي تشكل تهديدًا للنموذج.
فهل يمكننا أن نلقي نظرة على الاتجاه العام لمجال الذكاء الاصطناعي الموثوق من خلال الحالة الحالية للثقة في النماذج الكبيرة؟ كما نعلم جميعا،إن الاستقرار، والقدرة على التعميم (القدرة على التفسير)، والعدالة، وحماية الخصوصية هي أساس الذكاء الاصطناعي الجدير بالثقة، وهي أيضًا أربعة اتجاهات فرعية مهمة.ويعتقد لي بو أنه مع ظهور النماذج الكبيرة، فإن القدرات الجديدة ستجلب حتماً قيوداً جديدة على المصداقية، مثل القوة في مواجهة الأمثلة المعادية أو خارج التوزيع في التعلم السياقي. وفي هذا السياق، ستعمل العديد من الاتجاهات الفرعية على تعزيز بعضها البعض وتوفير معلومات أو حلول جديدة للعلاقة الأساسية بينها. "على سبيل المثال، أظهرت أبحاثنا السابقة أن التعميم والمتانة في التعلم الآلي يمكن أن يكونا مؤشرين في الاتجاهين في التعلم الفيدرالي، ويمكن اعتبار متانة النموذج بمثابة وظيفة للخصوصية، وما إلى ذلك."
نتطلع إلى مستقبل الذكاء الاصطناعي الموثوق
إذا نظرنا إلى الماضي والحاضر في مجال الذكاء الاصطناعي الموثوق، يمكننا أن نرى أن المجتمع الأكاديمي الذي يمثله لي بو، والصناعة التي تمثلها شركات التكنولوجيا الكبرى، والحكومة، كلهم يستكشفون في اتجاهات مختلفة وقد حققوا سلسلة من النتائج. بالنظر إلى المستقبل،قال لي بو: "إن تطور الذكاء الاصطناعي لا يمكن إيقافه. ولا يمكننا تطبيقه بأمان في مختلف المجالات إلا من خلال ضمان سلامة وموثوقية الذكاء الاصطناعي".
كيفية بناء الذكاء الاصطناعي الموثوق به على وجه التحديد؟ للإجابة على هذا السؤال، يجب علينا أولاً أن نفكر في ما هو "معقول" بالضبط. "أعتقد أن إنشاء معيار موحد وموثوق لتقييم الذكاء الاصطناعي يعد أحد أهم القضايا في الوقت الحاضر."ومن الواضح أن المناقشة حول الذكاء الاصطناعي الموثوق به وصلت إلى مستوى غير مسبوق في مؤتمر Zhiyuan ومؤتمر الذكاء الاصطناعي العالمي اللذين اختتما مؤخرا، ولكن معظم المناقشات لا تزال على مستوى المناقشة وتفتقر إلى التوجيه المنهجي المنظم. والشيء نفسه ينطبق على الصناعة. وعلى الرغم من أن بعض الشركات أطلقت مجموعات أدوات أو أنظمة معمارية ذات صلة، فإن الحل القائم على التصحيحات لا يستطيع حل سوى مشكلة واحدة. ولذلك، أشار العديد من الخبراء مرارا وتكرارا إلى نفس النقطة - لا يزال هناك نقص في معيار موثوق لتقييم الذكاء الاصطناعي في هذا المجال.
لقد تأثر لي بو بشدة بهذا."إن الشرط الأساسي لنظام الذكاء الاصطناعي الجدير بالثقة هو وجود مواصفات تقييم الذكاء الاصطناعي الجديرة بالثقة."وأضافت أن بحثها الأخير "DecodingTrust" يهدف إلى توفير تقييم شامل لمصداقية النموذج من وجهات نظر مختلفة. مع التوسع في القطاع الصناعي، أصبحت سيناريوهات التطبيق معقدة بشكل متزايد، مما يجلب المزيد من التحديات والفرص لتقييم الذكاء الاصطناعي الموثوق به. نظرًا لأنه قد تظهر نقاط ضعف أكثر مصداقية في سيناريوهات مختلفة، فقد يؤدي هذا إلى تحسين معايير تقييم الذكاء الاصطناعي الموثوق بها بشكل أكبر.
في ملخص،يعتقد لي بو أن مستقبل مجال الذكاء الاصطناعي الموثوق به يجب أن يركز على تشكيل نظام تقييم شامل ومحدث في الوقت الفعلي للذكاء الاصطناعي الموثوق به، وعلى هذا الأساس، تحسين مصداقية النموذج."يتطلب هذا الهدف تعاونًا وثيقًا بين الأوساط الأكاديمية والصناعة لتشكيل مجتمع أكبر لتحقيقه معًا."
الصفحة الرئيسية على GitHub لمختبر التعلم الآمن بجامعة إلينوي في إشبيلية (UIUC)
عنوان مشروع GitHub:
وفي الوقت نفسه، يعمل مختبر التعلم الأمني الذي يعمل فيه لي بو أيضًا على تحقيق هذا الهدف.وتتوزع نتائج أبحاثهم الأخيرة بشكل رئيسي في الاتجاهات التالية:
1. تم تصميم إطار عمل منطقي معزز بالمعرفة وقابل للتحقق يعتمد على التعلم القائم على البيانات لدمج النماذج القائمة على البيانات مع التفكير المنطقي المعزز بالمعرفة، وبالتالي الاستفادة الكاملة من قدرات التوسع والتعميم للنماذج القائمة على البيانات وتحسين قدرات تصحيح الأخطاء في النموذج من خلال التفكير المنطقي.
وفي هذا الاتجاه، اقترح لي بو وفريقه إطارًا للتعلم والاستدلال وأثبتوا متانته في مجال الاعتماد. وتظهر نتائج الدراسة أن الإطار المقترح يمكن أن يثبت أنه يتمتع بمزايا كبيرة مقارنة بالطرق التي تستخدم نموذج شبكة عصبية واحد فقط، ويتم تحليل عدد كافٍ من الظروف. وفي الوقت نفسه، قاموا أيضًا بتوسيع إطار التعلم المنطقي ليشمل مجالات مهام مختلفة.
أوراق ذات صلة:
* https://arxiv.org/abs/2003.00120
* https://arxiv.org/abs/2106.06235
* https://arxiv.org/abs/2209.05055
2. DecodingTrust: أول إطار عمل شامل لتقييم مصداقية النموذج لتقييم ثقة نماذج اللغة.
أوراق ذات صلة:
* https://decodingtrust.github.io/
3. في مجال القيادة الذاتية، توفر منصة "SafeBench" لإنشاء واختبار السيناريوهات الحرجة للسلامة.
عنوان المشروع:
* https://safebench.github.io/
بجانب،وكشف لي بو أن الفريق يخطط لمواصلة التركيز على الرعاية الصحية الذكية والتمويل وغيرها من المجالات."قد تظهر اختراقات في خوارزميات وتطبيقات الذكاء الاصطناعي الموثوقة في وقت مبكر في هذه المجالات."
من أستاذ مساعد إلى أستاذ دائم: إذا عملت بجد، سيأتي النجاح بشكل طبيعي
من مقدمة لي بو، ليس من الصعب أن نرى أنلا تزال هناك العديد من المشاكل التي تحتاج إلى حل في مجال الذكاء الاصطناعي الموثوق الناشئ.ولذلك، سواء كان المجتمع الأكاديمي ممثلاً بفريق لي بو أو الصناعة، فإن جميع الأطراف تستكشف في هذا الوقت من أجل الاستجابة الكاملة للطلب المتزايد في المستقبل. تمامًا مثل خمول لي بو وأبحاثه الدؤوبة قبل صعود مجال الذكاء الاصطناعي الموثوق به - طالما أنك مهتم ومتفائل، فالأمر مسألة وقت فقط قبل أن تحقق النجاح.
وينعكس هذا الموقف أيضًا في مسيرة لي بو التعليمية. لقد عملت في جامعة إلينوي-شامبين (UIUC) لأكثر من 4 سنوات.وقد حصل هذا العام على لقب أستاذ دائم.وأوضحت أن تقييم الألقاب المهنية له عملية صارمة، تتضمن نتائج الأبحاث والتقييمات الأكاديمية للعلماء الكبار الآخرين، وما إلى ذلك. وعلى الرغم من وجود تحديات،ولكن "طالما أنك تعمل بجد على شيء واحد، فإن كل شيء آخر سوف يقع في مكانه بشكل طبيعي".وفي الوقت نفسه، ذكرت أيضًا أن نظام التوظيف الدائم في الولايات المتحدة يوفر للأساتذة مزيدًا من الحرية والفرصة لتنفيذ بعض المشاريع الأكثر خطورة. وبالنسبة للي بو، فإنها ستعمل مع الفريق لتجربة بعض المشاريع الجديدة عالية المخاطر في المستقبل، "على أمل تحقيق المزيد من الاختراقات في النظرية والتطبيق".

أستاذ مشارك في جامعة إلينوي، حائز على جائزة IJCAI-2022 Computers and Thought Award، وجائزة Sloan Research، وجائزة NSF CAREER، وجائزة AI's 10 to Watch، وجائزة MIT Technology Review TR-35، وجائزة Dean's Award للتميز البحثي، وجائزة CW Gear Outstanding Junior Faculty، وجائزة Intel Rising Star، وزمالة Symantec Research Lab، وجوائز أفضل ورقة بحثية من Google وIntel وMSR وeBay وIBM، بالإضافة إلى العديد من مؤتمرات التعلم الآلي والأمن الرائدة.
اهتمامات البحث: الجوانب النظرية والعملية للتعلم الآلي الجدير بالثقة، وهو تقاطع التعلم الآلي والأمن والخصوصية ونظرية اللعبة.
روابط مرجعية:
[1] https://www.sohu.com/a/514688789_114778
[2] http://www.caict.ac.cn/sytj/202209/P020220913583976570870.pdf
[3] https://www.huxiu.com/article/1898260.html
نُشرت هذه المقالة لأول مرة على منصة HyperAI WeChat العامة~








