Command Palette
Search for a command to run...
الحوسبة المحاكاة: بناء مُجمِّع الذكاء الاصطناعي DSA استنادًا إلى TVM

مرحباً بالجميع، أنا دان شياو تشيانغ من شركة شيم للحوسبة. اليوم، سأشارك معكم أنا وثلاثة من زملائي كيفية دعم NPU على TVM.
المشكلة الأساسية التي يحلها مُجمِّع DSA هي أن هناك حاجة إلى نشر نماذج مختلفة على الأجهزة، باستخدام أساليب التحسين على مستويات مجردة مختلفة لجعل النموذج يملأ الشريحة قدر الإمكان، أي ضغط الفقاعات. وفيما يتعلق بكيفية الجدولة، فإن مثلث الجدولة الذي وصفه هاليد هو جوهر المشكلة.
ما هي المشكلة الرئيسية التي يحلها مُجمِّع DSA؟ أولاً، نقوم بتلخيص بنية DSA. كما هو موضح في الشكل، فإن Habana وAscend وIPU كلها تجسيدات لهذا العمارة المجردة. بشكل عام، يحتوي كل نواة على وحدات حسابية متجهة، ومقياسية، وموترية. من منظور عمليات التعليمات وحبيبات البيانات، قد تميل العديد من أدوات تحليل البيانات إلى استخدام تعليمات ذات حبيبات خشنة نسبيًا، مثل تعليمات المتجهات والموتر ثنائية الأبعاد وثلاثية الأبعاد. هناك أيضًا العديد من الأجهزة التي تستخدم تعليمات دقيقة، مثل SIMD أحادية البعد وVLIW. يتم الكشف عن بعض التبعيات بين التعليمات من خلال واجهات صريحة للتحكم في البرامج، في حين يتم التحكم في البعض الآخر بواسطة الأجهزة نفسها. الذاكرة عبارة عن ذاكرة متعددة المستويات، وهي في الغالب ذاكرة مسودة. هناك حبيبات وأبعاد مختلفة للتوازي، مثل التوازي التدفقي، والتوازي العنقودي، والتوازي متعدد النواة، والتوازي في خطوط الأنابيب بين مكونات الحوسبة المختلفة.
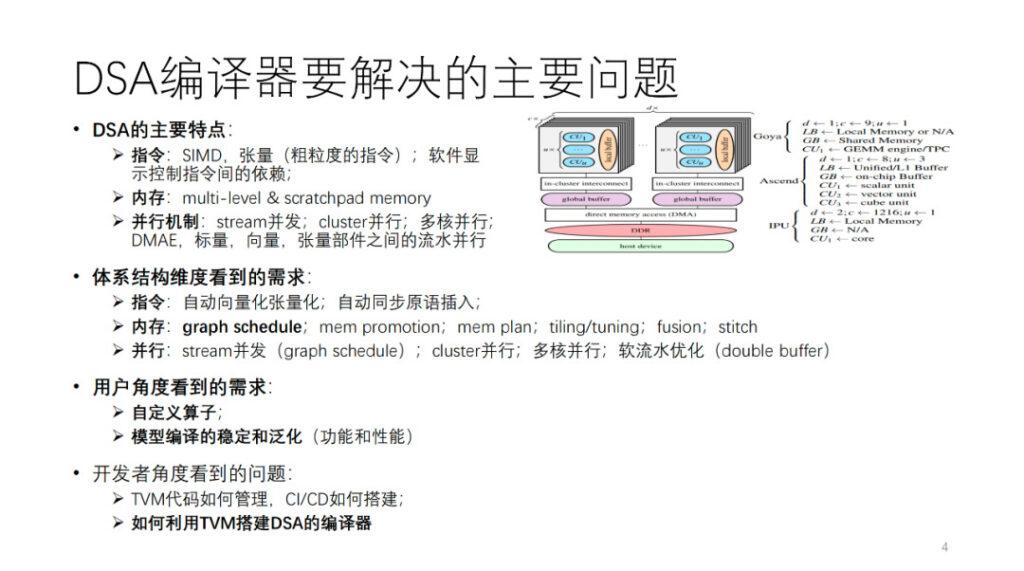
لدعم هذا النوع من الهندسة المعمارية، من وجهة نظر مطوري المترجم، يتم طرح متطلبات مختلفة لمترجم الذكاء الاصطناعي من عدة جوانب للهندسة المعمارية المذكورة أعلاه. وسوف نتوسع في هذا الجزء لاحقًا.
من وجهة نظر المستخدم، أولاً وقبل كل شيء، يجب أن يكون هناك مُجمِّع مستقر ومعمم يمكنه تجميع أكبر عدد ممكن من النماذج أو المشغلات بنجاح. بالإضافة إلى ذلك، يأمل المستخدمون أن يتمكن المترجم من توفير واجهة قابلة للبرمجة لتخصيص الخوارزميات والمشغلات لضمان إمكانية تنفيذ بعض أعمال الابتكار الرئيسية في الخوارزمية بشكل مستقل. أخيرًا، قد تكون الفرق مثل فرقنا أو منافسينا أيضًا مهتمة بكيفية استخدام TVM لبناء مُجمِّع الذكاء الاصطناعي، مثل كيفية إدارة أكواد TVM التي تم تطويرها ذاتيًا والمفتوحة المصدر، وكيفية بناء CI فعال، وما إلى ذلك. وهذا ما سنشاركه اليوم. سيتحدث زميلي الآن عن جزء تحسين التجميع.
وانغ تشنغكي من شركة شيم للحوسبة: عملية تحسين تجميع DSA
تم مشاركة هذا الجزء في الموقع بواسطة Wang Chengke، مهندس الحوسبة في Shim.
أولاً، اسمحوا لي أن أقدم لكم العملية الشاملة لممارسة التجميع الخاصة بشيم.
استجابةً للميزات المعمارية المذكورة أعلاه، قمنا ببناء عملية تحسين تم تطويرها ذاتيًا استنادًا إلى بنية بيانات TVM وأعدنا استخدام TVM لتشكيل تنفيذ نموذج جديد: tensorturbo.
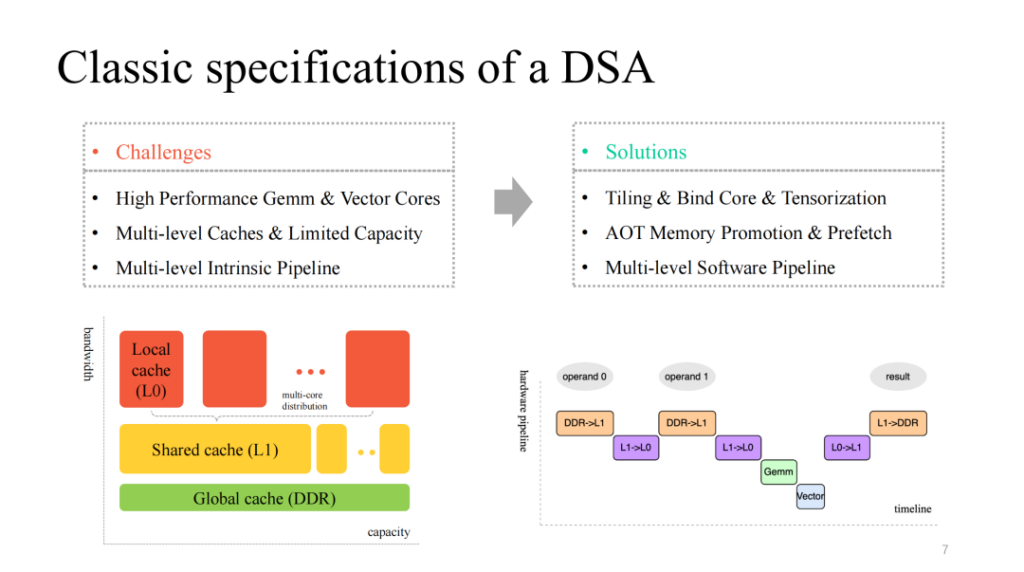
نرى بنية DSA كلاسيكية نسبيًا، والتي توفر عمومًا بعض أنوية الحوسبة متعددة النواة ذات الطبقات المصفوفة والمتجهة والفعالة والمخصصة، ولديها آلية تخزين مؤقت متعددة الطبقات لتتناسب معها، وتوفر أيضًا وحدات تنفيذ متعددة الوحدات يمكن تشغيلها بالتوازي. وعليه، يتعين علينا أن نتعامل مع القضايا التالية:
- تقسيم حسابات البيانات، وربط النوى بكفاءة، وتوجيه التعليمات المخصصة بكفاءة؛
- إدارة ذاكرة التخزين المؤقت المحدودة الموجودة على الشريحة بشكل دقيق وجلب البيانات مسبقًا وفقًا لذلك على مستويات ذاكرة التخزين المؤقت المختلفة؛
- تحسين خط الأنابيب متعدد المراحل الذي يتم تنفيذه بواسطة وحدات متعددة، والسعي للحصول على نسبة تسريع أفضل.
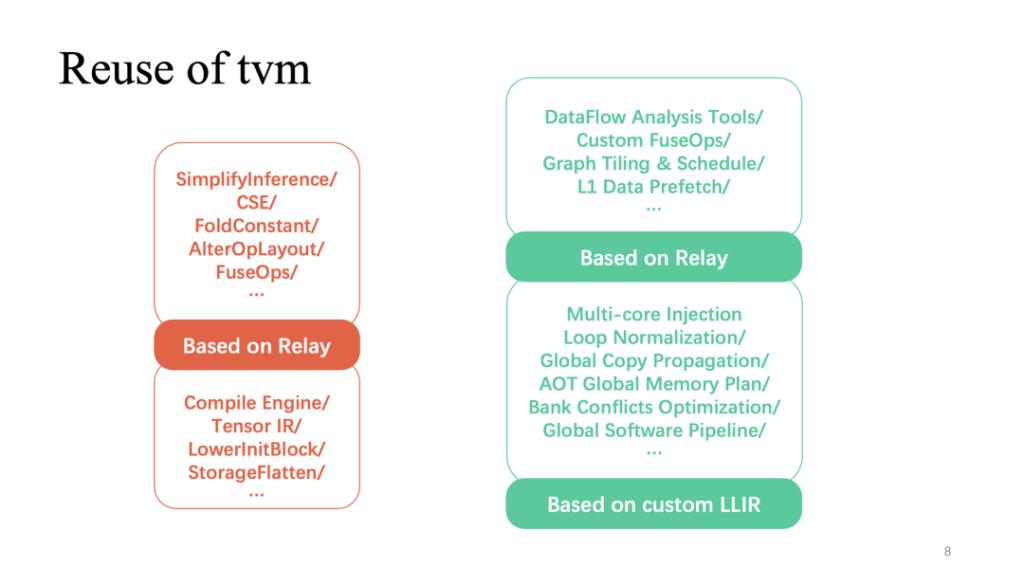
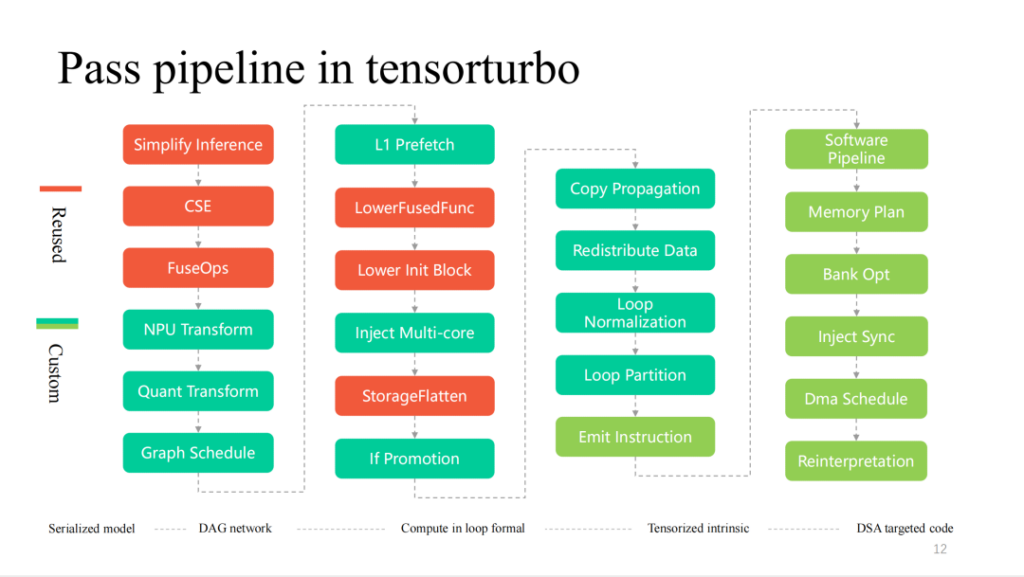
الجزء الأحمر (أعلاه) يوضح الجزء الذي يحتوي على أعلى معدل إعادة استخدام لـ TVM في العملية بأكملها. يمكن إعادة استخدام التحسينات الأكثر شيوعًا المتعلقة بالطبقة والتي تم تنفيذها على التتابع بشكل مباشر. بالإضافة إلى ذلك، يتم إعادة استخدام تنفيذ المشغل المستند إلى TensorIR وLLIR المخصص بشكل كبير أيضًا. يتطلب التحسين المخصص المتعلق بميزات الأجهزة، كما ذكرنا للتو، المزيد من أعمال البحث الذاتي.
أولاً، دعونا نلقي نظرة على العمل الذي تم تطويره ذاتيًا حول الطبقات.
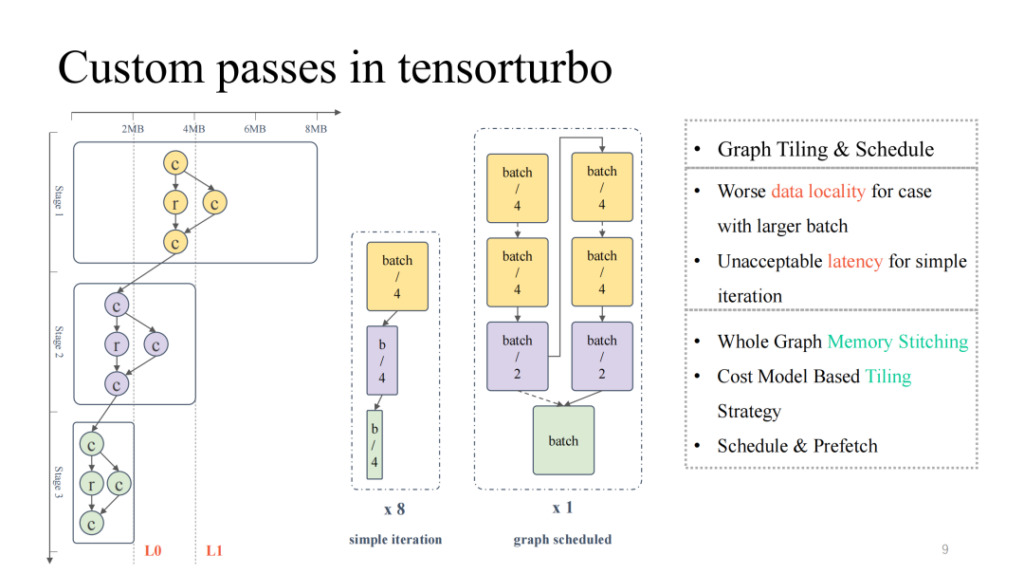
عند النظر إلى مخطط تدفق الحوسبة الأكثر نموذجية الموجود في أقصى اليسار، يمكننا أن نرى أنه من أعلى إلى أسفل، يتناقص إجمالي إشغال ذاكرة التخزين المؤقت وإشغال الحوسبة باستمرار، مما يمثل حالة هرم مقلوب. بالنسبة للنصف الأول، عندما يكون حجم النموذج كبيرًا، نحتاج إلى التركيز على حل مشكلة إقامة ذاكرة التخزين المؤقت على الشريحة؛ أما في النصف الثاني، عندما يكون حجم النموذج صغيرًا، فنحن بحاجة إلى التعامل مع مشكلة انخفاض استخدام وحدة الحوسبة. إذا قمت ببساطة بتعديل حجم النموذج، مثل تعديل حجم الدفعة، فإن حجم الدفعة الأصغر قد يؤدي إلى انخفاض زمن الوصول، ولكن سيتم تقليل الإنتاجية المقابلة؛ وبالمثل، فإن حجم الدفعة الأكبر سيؤدي إلى زمن وصول أعلى، ولكنه قد يحسن الإنتاجية الإجمالية.
ومن ثم يمكننا استخدام جدولة الرسم البياني لحل هذه المشكلة. أولاً، يُسمح بإدخال حجم دفعة كبير نسبيًا لضمان الاستخدام العالي نسبيًا للحساب طوال العملية. بعد ذلك يتم إجراء تحليل تخزين على الرسم البياني بأكمله، ويتم إضافة استراتيجية التجزئة والجدولة بحيث يمكن تخزين نتائج النصف الأول من النموذج بشكل أفضل على الشريحة، مع تحقيق استخدام أعلى لنواة الحوسبة. في الممارسة العملية، يمكننا تحقيق نتائج جيدة في كل من زمن الوصول والإنتاجية (للحصول على التفاصيل، يرجى الانتباه إلى مقالة OSDI 23 Shim: جدولة الرسوم البيانية الحسابية للشبكات العصبية العميقة نحو مسرعاتها الخاصة بالمجال بشكل فعال، والتي ستكون متاحة في يونيو).
وفيما يلي عمل آخر لتسريع تدفق المياه الناعمة.
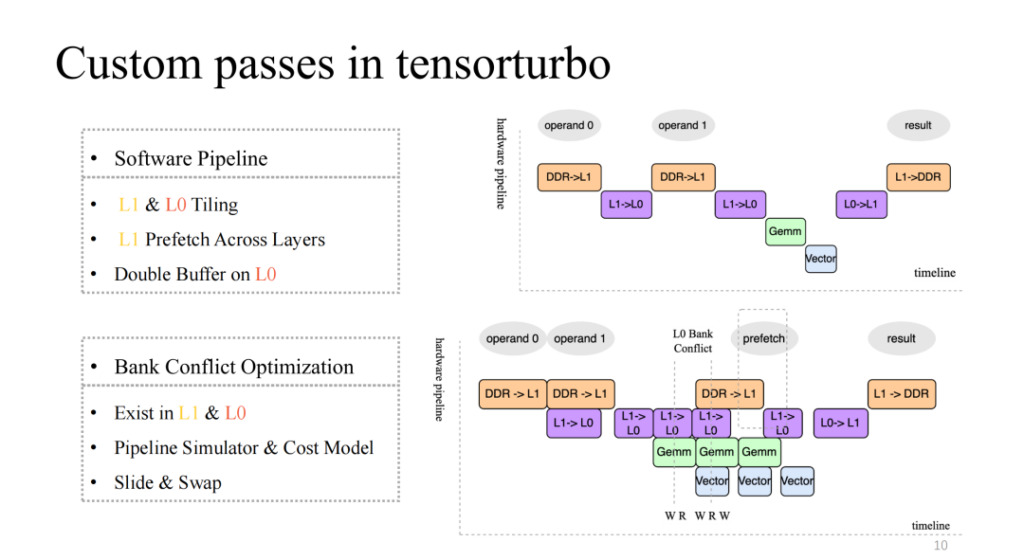
انتبه إلى الصورة الموجودة في أعلى اليمين، والتي تنفذ خط أنابيب أصليًا نسبيًا مكونًا من أربع مراحل، ولكن من الواضح أنه ليس خط أنابيب فعالًا. بشكل عام، يجب أن يكون خط الأنابيب الفعال قادرًا على مزامنة وتوازي وحدات التنفيذ الأربع بعد عدة تكرارات. يتطلب هذا بعض العمل، بما في ذلك التجزئة على L1 وL0، وجلب البيانات مسبقًا عبر الطبقات على L1، وعمليات المخزن المؤقت المزدوج على مستوى L0. ومن خلال هذا العمل، يمكننا تحقيق خط أنابيب ذو تسارع مرتفع نسبيًا كما هو موضح في الشكل الموجود في الأسفل على اليمين.
وسوف يؤدي هذا أيضًا إلى ظهور مشكلة جديدة. على سبيل المثال، عندما يكون عدد عمليات القراءة والكتابة المتزامنة لوحدات التنفيذ المتعددة في ذاكرة التخزين المؤقت أعلى من التزامن الذي تدعمه ذاكرة التخزين المؤقت الحالية، فسوف تحدث المنافسة. ستؤدي هذه المشكلة إلى انخفاض كفاءة الوصول إلى الذاكرة بشكل كبير، وهي مشكلة تعارض البنك. لتناول هذه المشكلة، سنقوم بمحاكاة خط الأنابيب بشكل ثابت في وقت التجميع، واستخراج الكائنات المتضاربة، واستخدام نموذج التكلفة لمبادلة ونقل العناوين المخصصة، مما قد يقلل بشكل كبير من تأثير هذه المشكلة.
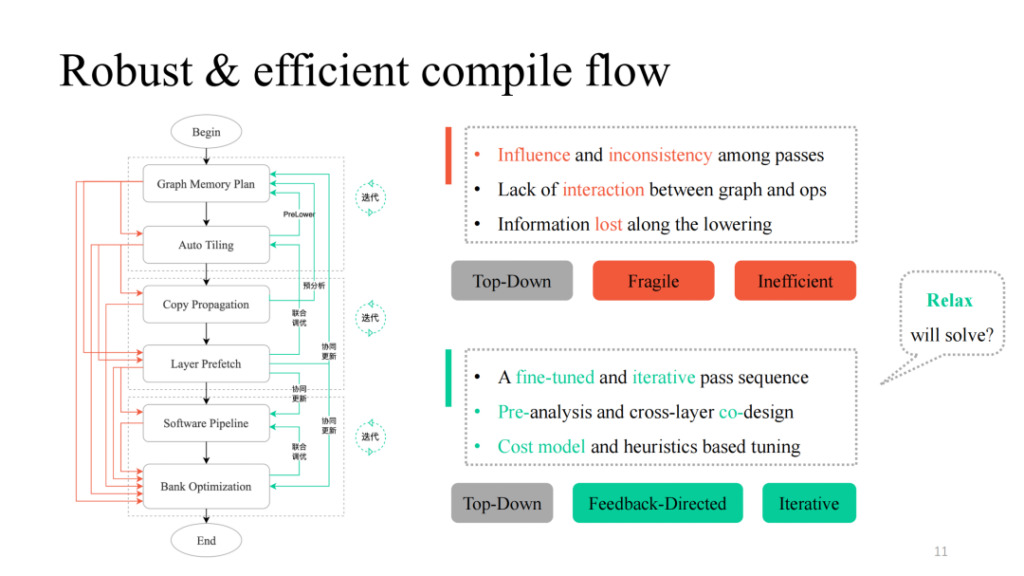
بعد الحصول على التمريرات المختلفة، يمكننا دمجها بطريقة بسيطة من الأعلى إلى الأسفل. باتباع العملية السوداء في الشكل الأيسر، يمكننا الحصول على خط أنابيب تجميع قابل للتنفيذ وظيفيًا. ومع ذلك، تم العثور على العديد من المشاكل في الممارسة العملية، بما في ذلك التأثير المتبادل بين التمريرات التي ذكرها سي يوان، والافتقار إلى منطق التفاعل، والافتقار إلى منطق الاتصال بين الطبقات والمشغلين. يمكنك رؤية العملية المشار إليها بالجزء الأحمر في الشكل الأيسر. وفي الممارسة العملية، وجد أن كل مسار أو مجموعة منهما سوف تتسبب في فشل التجميع. كيف نجعله أكثر قوة؟ يوفر Shim مسار ردود فعل في كل تمريرة قد تفشل، ويقدم منطقًا تفاعليًا بين الطبقات والمشغلين، ويقوم بعمليات التحليل المسبق والخفض المسبق، ويقدم بعض آليات الضبط التكرارية في الأجزاء الرئيسية، مما يؤدي في النهاية إلى الحصول على تنفيذ خط أنابيب شامل مع تعميم عالي وقدرات ضبط قوية.
لقد لاحظنا أيضًا أن تحويل بنية البيانات وأفكار التصميم ذات الصلة في العمل أعلاه لها العديد من أوجه التشابه مع تصميم TVM Unity الحالي. نتوقع أيضًا أن يوفر Relax المزيد من الإمكانيات.
فيما يلي المزيد من التمريرات التفصيلية في عملية تجميع Xim. من اليسار إلى اليمين، إنها عملية التناقص طبقة بعد طبقة. يتم إعادة استخدام الجزء الأحمر بشكل كبير بواسطة TVM. كلما اقتربت ميزات الأجهزة، كلما زاد عدد التمريرات المخصصة.
وفيما يلي مقدمة تفصيلية لبعض الوحدات.
ليو فاي، الحوسبة المحاكاة: المتجهات والتنسوريات لـ DSA
تم مشاركة هذا الجزء على الموقع بواسطة Liu Fei، مهندس الحوسبة في Shim.
سوف يقدم هذا الفصل عمل متجهات شيم وتكميم الموتر. من منظور حبيبات التعليمات، كلما كانت حبيبات التعليمات أكثر خشونة، كلما اقتربت من تعبير الحلقة متعددة الطبقات لـ Tensor IR، وبالتالي تصبح صعوبة كمية الموتر المتجهة أسهل. على العكس من ذلك، كلما كانت تفاصيل التعليمات أدق، كلما زادت الصعوبة. تدعم تعليمات NPU الخاصة بنا حسابات بيانات الموتر أحادية الأبعاد/ثنائية الأبعاد/ثلاثية الأبعاد. كما أخذ شيم في الاعتبار عملية Tensorize الأصلية لـ TVM، ولكن مع الأخذ في الاعتبار القدرة المحدودة لـ Compute Tensorize على التعبير عن التعبيرات المعقدة، فمن الصعب تحويل التعبيرات المعقدة إلى Tensorize مثل الشرط if، وبعد تحويل المتجهات إلى Tensorize، لا يمكن جدولتها.
بالإضافة إلى ذلك، كان TensorIR Tensorize قيد التطوير في ذلك الوقت ولم يتمكن من تلبية احتياجات التطوير، لذلك قدم Shim مجموعة خاصة به من عمليات متجهات التعليمات، والتي نسميها إصدار التعليمات. في ظل هذه العملية، ندعم حوالي 120 تعليمة Tensor، بما في ذلك تعليمات ذات أبعاد مختلفة.

يتم تقسيم تدفق التعليمات لدينا تقريبًا إلى ثلاث وحدات:
- تحسين ما قبل الإطلاق. يؤدي تحويل محور الدورة إلى توفير المزيد من الظروف والإمكانيات لإصدار الأوامر؛
- وحدة نقل الأوامر. تحليل نتائج ومعلومات الحلقة واختيار طريقة توليد التعليمات المثلى؛
- الوحدة بعد إصدار الأمر. معالجة الإرسال المحدد بعد فشله لضمان التنفيذ الصحيح على وحدة المعالجة المركزية.
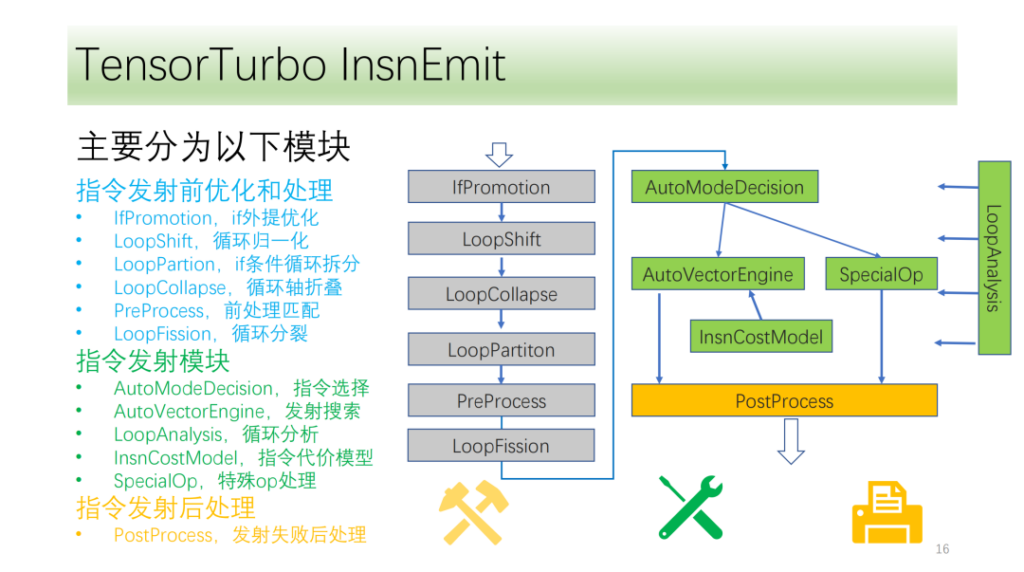
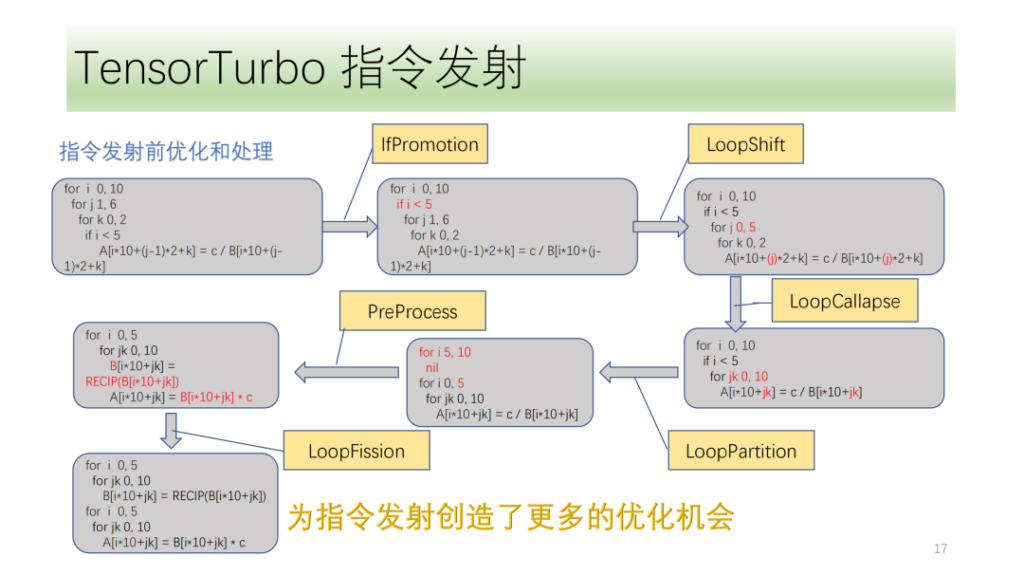
أدناه هووحدة التحسين والمعالجة قبل إصدار الأمر،تتكون جميعها من مجموعة من عمليات التحسين، من بينها IfPromotion لإزالة عبارات if التي تعيق إصدار محاور الحلقة قدر الإمكان، وPreProcess لتقسيم المشغلين الذين ليس لديهم تعليمات مقابلة، وLoopShift لتطبيع حدود محاور الحلقة، وLoopCallapse لدمج محاور الحلقة المتتالية قدر الإمكان، وLoopPartition لتقسيم محاور الحلقة المرتبطة بـ if، وLoopFission لتقسيم عبارات المتجر المتعددة في الحلقة.
من هذا المثال، يمكننا أن نرى أنه في البداية لا يمكن للأشعة تحت الحمراء إصدار أي تعليمات. بعد التحسين، يمكنه أخيرًا إصدار تعليمات Tensor ويمكن لجميع محاور الحلقة إصدار التعليمات.
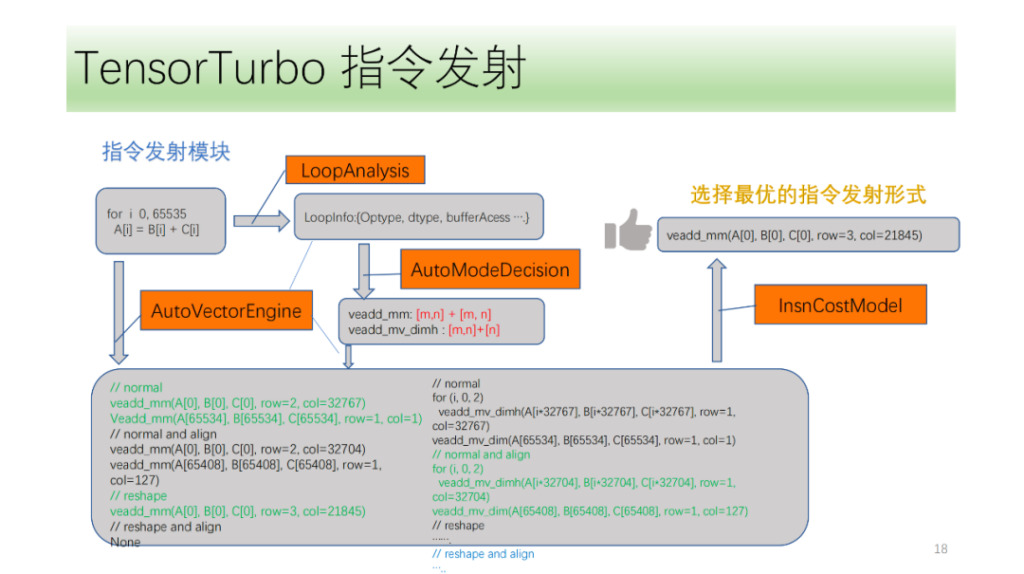
ثم هناك وحدة نقل الأوامر. أولاً، ستقوم وحدة إصدار التعليمات بتحليل البنية في الحلقة بشكل دوري والحصول على معلومات مثل Optype وdtype وbufferAcess وما إلى ذلك. بعد الحصول على هذه المعلومات، ستحدد وحدة التعرف على التعليمات التعليمات التي قد يصدرها محور الحلقة. نظرًا لأن بنية IR واحدة قد تتوافق مع تعليمات NPU متعددة، فسنقوم بتحديد جميع التعليمات المحتملة التي سيتم إصدارها، ونسمح لمحرك البحث VectorEngine بالبحث عن إمكانية إصدار كل تعليمة استنادًا إلى سلسلة من المعلومات مثل محاذاة التعليمات وإعادة تشكيلها. أخيرًا، سيقوم CostModel بحساب والعثور على نموذج الانبعاث الأمثل للانبعاث.
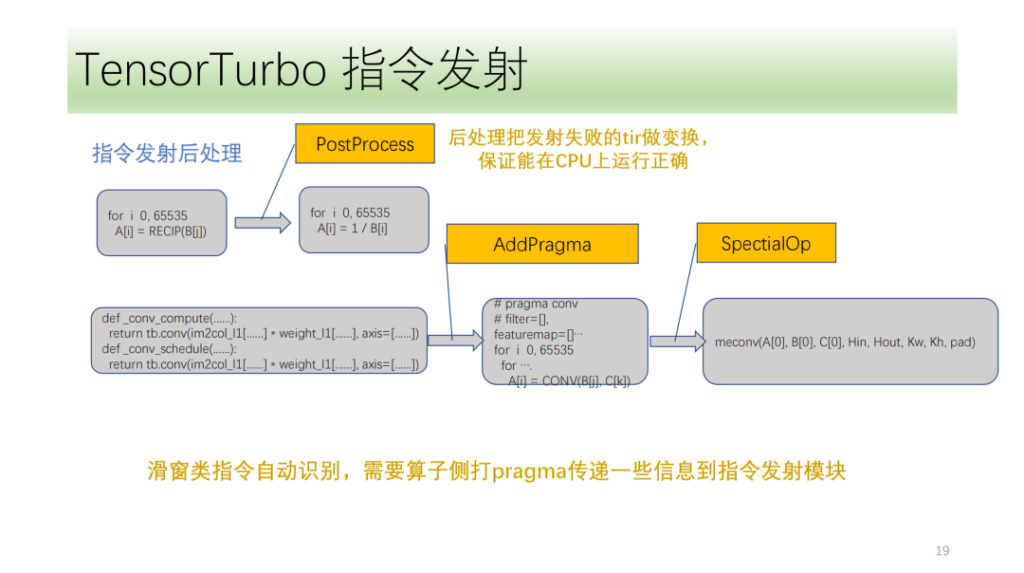
والأخيرة هي وحدة معالجة ما بعد التعليمات. الغرض الرئيسي هو معالجة البرنامج الذي فشل في إصدار التعليمات للتأكد من أنه يمكن تشغيله بشكل صحيح على وحدة المعالجة المركزية. هناك أيضًا بعض التعليمات الخاصة التي يتعين على Shim تحديدها في الجزء الأمامي من الخوارزمية. تستخدم وحدة نقل التعليمات هذه العلامات وتحليل الأشعة تحت الحمراء الخاص بها لنقل التعليمات المقابلة بشكل صحيح.
ما ورد أعلاه هو عملية التكميم والمتجه لموتر DSA بالكامل التي قام بها Shim. لقد استكشفنا أيضًا بعض الاتجاهات، مثل حل النواة الدقيقة، وهو أيضًا موضوع تمت مناقشته بشدة مؤخرًا. فكرتها الأساسية هي تقسيم عملية الحوسبة إلى طبقتين، يتم ربط الطبقة الأولى على شكل نواة صغيرة مدمجة، ويتم البحث في الطبقة الأخرى. وأخيرا يتم دمج نتائج الطبقتين معًا لاختيار النتيجة المثالية. وتكمن ميزة هذا في أنه يستغل موارد الأجهزة بشكل كامل مع تقليل تعقيد البحث وتحسين كفاءته.
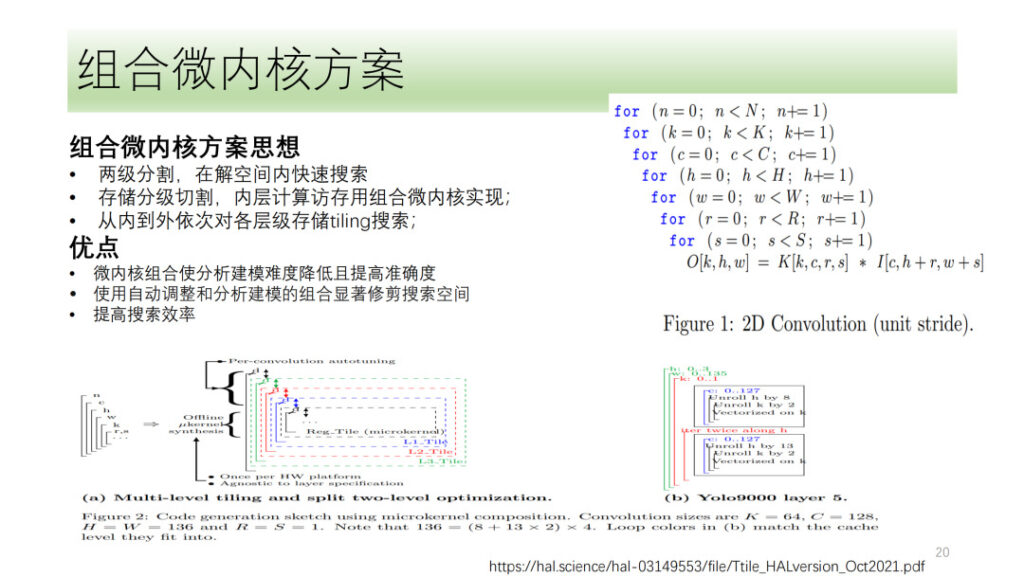

وقد استكشفت شركة Shim أيضًا النواة الدقيقة، ولكن بالنظر إلى أن حل النواة الدقيقة لم يحسن الأداء بشكل كبير مقارنة بالحلول الحالية، فإن شركة Shim لا تزال في مرحلة الاستكشاف في اتجاه النواة الدقيقة.
يوان شنغ، شيم للحوسبة: مشغلات مخصصة لـ DSA
تم مشاركة هذا الجزء على الموقع بواسطة مهندس الحوسبة في شركة Shim Yuan Sheng.
أولاً وقبل كل شيء، نحن نعلم أن تطوير المشغل يواجه حاليًا أربع مشكلات رئيسية:
- هناك العديد من مشغلي الشبكات العصبية التي تحتاج إلى الدعم. بعد التصنيف، هناك أكثر من 100 مشغل أساسي.
- نظرًا لأن بنية الأجهزة تتكرر باستمرار، فمن الضروري تغيير التعليمات والمنطق المقابل المتضمن في المشغلات؛
- اعتبارات الأداء. دمج المشغل (الذاكرة المحلية، والذاكرة المشتركة) ونقل معلومات الحوسبة البيانية (التجزئة، وما إلى ذلك) التي ذكرتها سابقًا؛
- يجب أن يكون المشغلون مفتوحين للمستخدمين، ولا يمكن للمستخدمين الدخول إلى البرنامج إلا لتخصيص المشغلين.
لقد قمت بتقسيمها بشكل أساسي إلى الجوانب الثلاثة التالية. الأول هو مشغل الرسم البياني، والذي يعتمد على واجهة برمجة التطبيقات الخاصة بالتتابع ويتم تخصيصه لمشغلي اللغة الأساسية.
خذ الشكل التالي كمثال:
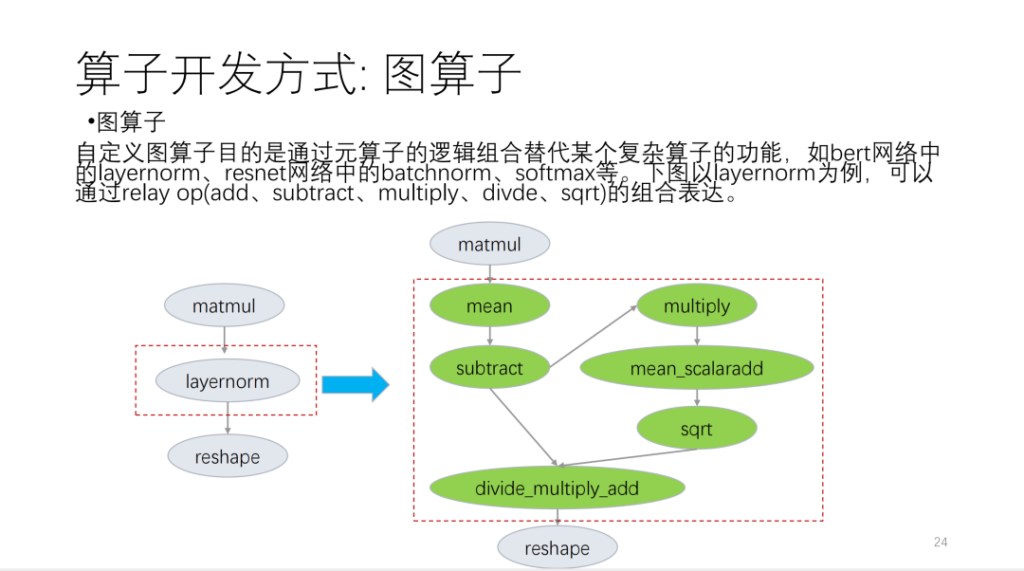
الثاني هو المشغل الميتا. يعتمد ما يسمى بالمشغل الفوقي على TVM Topi ويستخدم الحوسبة/الجدولة لوصف منطق خوارزمية المشغل ومنطق التحويل الحلقي المرتبط. عندما نقوم بتطوير المشغلين، نجد أن العديد من جداول المشغلين يمكن إعادة استخدامها. بناءً على هذا الموقف، يوفر Shim مجموعة من القوالب المشابهة للجداول الزمنية. الآن، نقوم بتقسيم المشغلين إلى العديد من الفئات. بناءً على هذه الفئات، سيعيد المشغلون الجدد استخدام عدد كبير من قوالب الجدول.
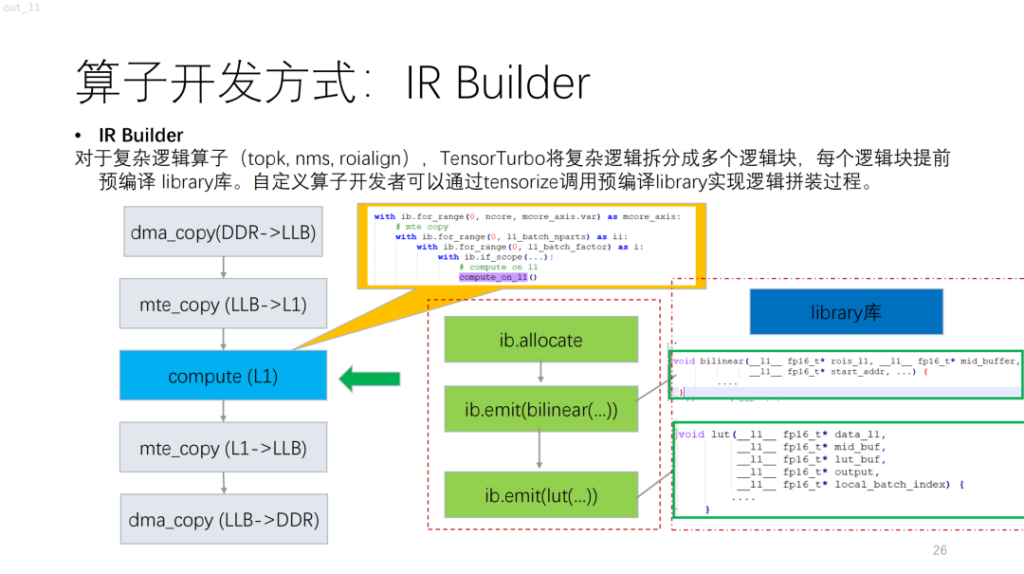
التالي هو مشغل أكثر تعقيدًا. استنادًا إلى NPU، ستجد أن الخوارزميات ذات تدفق التحكم مثل topk وnms تحمل الكثير من الحسابات القياسية، والتي يصعب وصفها حاليًا باستخدام الحوسبة/الجدولة. ولحل هذه المشكلة، يوفر Shim مكتبة مماثلة. إنه يعادل تجميع المنطق المعقد في المكتبة أولاً، ثم إخراج منطق المشغل بأكمله عن طريق دمجه مع IR Builder.
ويأتي بعد ذلك تقسيم المشغلين. بالنسبة لوحدة NPU، بالمقارنة مع وحدة معالجة الرسوميات ووحدة المعالجة المركزية، ستعمل كل تعليمة من TVM على كتلة ذاكرة مستمرة وسيكون هناك حد لحجم الذاكرة. وفي الوقت نفسه، في هذه الحالة، مساحة البحث ليست كبيرة. وبناء على هذه المشاكل، قدم شيم الحلول. أولاً، سيكون هناك مجموعة مرشحة، ويتم وضع الحلول الممكنة في مجموعة المرشحين. ثانيًا، يتم شرح الجدوى، مع الأخذ في الاعتبار بشكل أساسي متطلبات الأداء وقيود تعليمات NPU. وأخيرا، تم تقديم دالة التكلفة، والتي تأخذ في الاعتبار خصائص المشغل وخصائص وحدات الحوسبة التي يمكن استخدامها.
الجانب الأكثر تحديًا في تطوير المشغل هو مشغل الاندماج. نحن نواجه حاليا مشكلتين خطيرتين. الأول هو أننا لا نعرف كيفية الجمع بين مشغلينا مع مشغلين آخرين. الثاني هو أننا نستطيع أن نرى أن هناك العديد من مستويات الذاكرة في وحدة المعالجة العصبية، وهناك اندماج متفجر لمستويات الذاكرة. سيحتوي برنامج Shim LLB على مزيج من الذاكرة المشتركة والذاكرة المحلية. وبناءً على هذا الوضع، فإننا نقدم أيضًا إطار عمل للتوليد التلقائي. أولاً، وفقًا لمعلومات الجدولة التي تقدمها الطبقة، يتم إدراج عملية نقل البيانات، ثم يتم تحسين معلومات الجدول وفقًا للعملية الرئيسية والعملية الاحتياطية في الجدول. وأخيرًا، يتم إجراء المعالجة اللاحقة بناءً على قيود التعليمات الحالية والمشكلات الأخرى.

وأخيرًا، يتم عرض المشغلين الذين يدعمهم Shim بشكل أساسي. يوجد حوالي 124 مشغل ONNX، ويتم حاليًا دعم حوالي 112 منهم، وهو ما يمثل 90.3%. في الوقت نفسه، لدى Shim مجموعة من الاختبارات العشوائية التي يمكنها اختبار الأعداد الأولية الكبيرة، ومجموعات الاندماج، وبعض مجموعات اندماج الأنماط.
تلخيص
تم مشاركة هذا الجزء على الموقع بواسطة مهندس الحوسبة في شركة Shim، دان شياو تشيانغ.
هذا هو CI الذي بناه Shim استنادًا إلى TVM، والذي يقوم بتشغيل أكثر من 200 نموذج والعديد من اختبارات الوحدة. إذا لم يشغل MR موارد CI، فسيستغرق إرسال الرمز أكثر من 40 دقيقة. كمية الحساب كبيرة جدًا، وهي تتضمن أكثر من 20 بطاقة حوسبة تم تطويرها ذاتيًا وبعض أجهزة وحدة المعالجة المركزية.
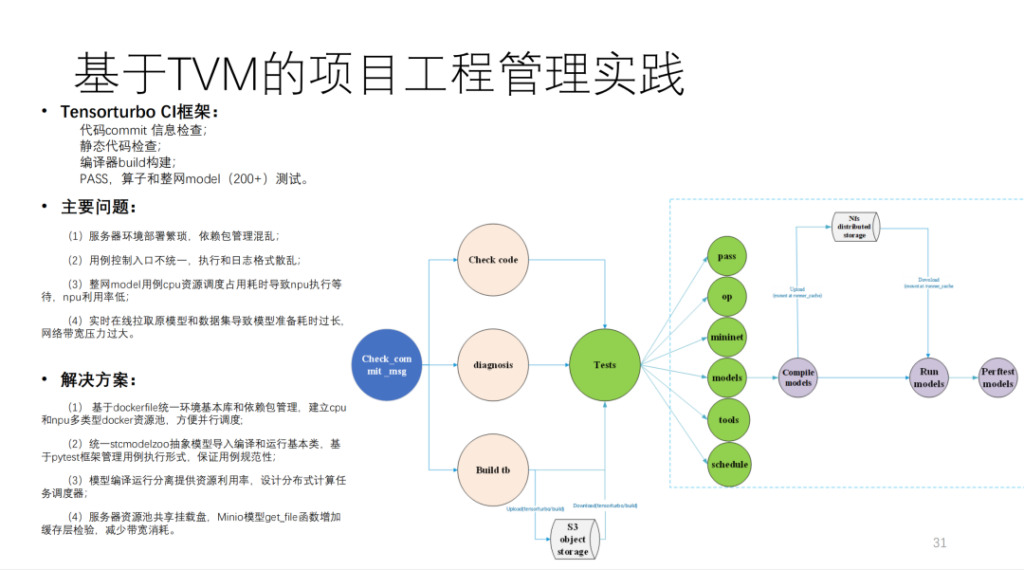
باختصار، هذا هو الرسم التخطيطي للهندسة المعمارية لشيم، كما هو موضح أدناه:
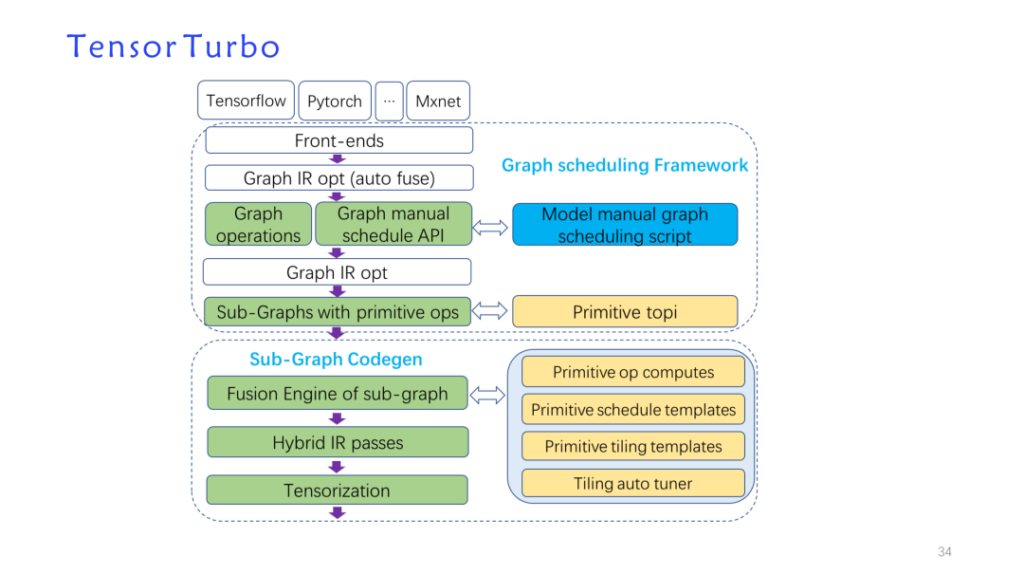
ومن خلال النتائج، تم تحسين الأداء بشكل كبير. بالإضافة إلى ذلك، إذا تمت مقارنة التوليد التلقائي بفريق نموذج خط اليد الآخر، فيمكنه الوصول بشكل أساسي إلى 90% أو أعلى.

هذا هو وضع الكود Xim. يُظهر الجانب الأيسر كيفية إدارة TVM والأكواد التي تم تطويرها ذاتيًا. يتم استخدام TVM كهيكل بيانات في الطرف الثالث. لدى Xim مصدره الخاص وأشياء Python. إذا كنا بحاجة إلى إجراء تغييرات على TVM، فيمكننا تعديل TVM في مجلد التصحيح. هناك ثلاثة مبادئ هنا:
- يستخدم معظمهم التمريرات التي تم تطويرها ذاتيًا ويقومون أيضًا بتطوير وحدات مخصصة؛
- سيعمل التصحيح على الحد من تعديل كود مصدر TVM ورفعه إلى أعلى في الوقت المناسب إذا كان ذلك ممكنًا؛
- قم بمزامنة البيانات بانتظام مع مجتمع TVM وقم بتحديث أحدث التعليمات البرمجية إلى المستودع.
يظهر أيضًا إجمالي كمية الكود في الشكل أعلاه.
تلخيص:
- نحن ندعم شرائح الجيل الأول والثاني من HIMU من البداية إلى النهاية استنادًا إلى TVM؛
- تنفيذ جميع متطلبات تحسين التجميع استنادًا إلى التتابع و tir؛
- تم الانتهاء من التوليد التلقائي لأكثر من 100 تعليمة متجهية مبنية على tir؛
- تم تنفيذ حل مشغل مخصص يعتمد على TVM؛
- الجيل الأول من النموذج يدعم 160+، والجيل الثاني يتيح 20+؛
- أداء النموذج قريب من الكتابة اليدوية.
الأسئلة والأجوبة
س1: أنا مهتم بمشغل الاندماج. كيف يتم دمجه مع TIR الخاص بـ TVM؟
أ1: بالنسبة للشكل الصحيح، لنفس مستوى المشغل، أولاً، إذا كان لدى المشغل مدخلين ومخرج واحد، فسيكون هناك 27 شكلًا للمشغل. ثانياً، عندما يتم ربط مشغلين مختلفين، قد يكون النطاق أحد الثلاثة، وبالتالي لا نفترض نمطًا ثابتًا. إذن كيف يمكن تنفيذ ذلك على TVM؟ أولاً، وفقًا لجدولة الطبقة، حدد مكان الإضافة الأمامية والخلفية والنطاق الوسيط. الطبقة هي عملية معقدة للغاية. تتمثل نتيجة الإخراج في تحديد ذاكرة التخزين المؤقت التي يتواجد فيها المشغل ومدى مساحة ذاكرة التخزين المؤقت المتوفرة. بفضل نتيجة هذا الجدول، نقوم تلقائيًا بإنشاء مشغلين مدمجين في طبقة المشغل. على سبيل المثال، نقوم تلقائيًا بإدراج عمليات ترحيل البيانات استنادًا إلى معلومات النطاق لاستكمال بناء تدفق البيانات.
إن الآلية الموجودة في معلومات الجدول مشابهة جدًا لتلك الموجودة في TVM الأصلية. يجب أن يؤخذ الحجم الذي يستخدمه كل نطاق عضو في الاعتبار أثناء عملية الدمج. لذا فهذه أشياء أصلية من TVM. نحن نستخدم إطار عمل خاص لدمجه هنا وجعله تلقائيًا.
على هذا الأساس، يتم عمل الجدول المطلوب من قبل المطور، وقد يكون هناك أيضًا بعض المعالجة اللاحقة.

س2: هل يمكنك من فضلك مشاركة المزيد من التفاصيل حول CostModel؟ هل تم تصميم دالة التكلفة على أساس ميزات مستوى المشغل أم ميزات مستوى الأجهزة؟
ج1: الفكرة العامة هنا. أولاً، يتم إنشاء مجموعة المرشحين. ترتبط عملية التوليد بهيكل NPL. ثم هناك عملية التقليم، مع الأخذ في الاعتبار قيود التعليمات والتحسينات اللاحقة، والتعدد في النواة، والمخزن المؤقت المزدوج، وما إلى ذلك. وأخيرًا، هناك دالة التكلفة لفرزها.
نحن نعلم أن جوهر روتين التحسين هو كيفية إخفاء حركة البيانات في الحسابات. لا يعد هذا الأمر أكثر من محاكاة العملية وفقًا لهذا المعيار وحساب التكلفة في النهاية.
س3: بالإضافة إلى قواعد الاندماج الافتراضية التي يدعمها TVM، هل قام TVM بإنشاء قواعد اندماج جديدة، مثل الاندماج الفريد المخصص لأجهزة مختلفة في طبقة الحوسبة؟
ج3: فيما يتعلق بالاندماج، هناك في الواقع مستويين. الأول هو اندماج المخزن المؤقت، والثاني هو اندماج الحلقة. في الواقع، تهدف طريقة دمج TVM إلى هذا الأخير. يتبع Shim بشكل أساسي نمط اندماج TVM الذي ذكرته، ولكن مع بعض القيود.








