Command Palette
Search for a command to run...
سيوان فينج: Apache TVM وتطوير تجميع التعلم الآلي

تم نشر هذه المقالة لأول مرة على الحساب الرسمي لـ HyperAI WeChat~
مساء الخير، مرحبًا بكم جميعًا في 2023 Meet TVM اليوم. بصفتي Apache TVM PMC،اسمحوا لي أن أشارك معكم حول تطوير TVM وإطار Unity المستقبلي لـ TVM.
أباتشي TVM إيفولوشن
أولاً، لماذا يوجد MLC (تجميع التعلم الآلي)؟ مع استمرار توسع نماذج الذكاء الاصطناعي، ستظهر المزيد من الطلبات في تطبيقات الإنتاج الفعلية. تتم مشاركة تطبيقات الذكاء الاصطناعي من الطبقة الأولى للعديد من التطبيقات (كما هو موضح في الشكل)، بما في ذلك ResNet وBERT وStable Diffusion ونماذج أخرى.

السيناريو في المستوى الثاني مختلف. ويحتاج المطورون إلى نشر هذه النماذج في سيناريوهات مختلفة، بدءًا من الحوسبة السحابية والحوسبة عالية الأداء، والتي تتطلب تسريع وحدة معالجة الرسومات. مع تسارع مجال الذكاء الاصطناعي، فإن المهمة الأكثر أهمية هي إدخاله إلى آلاف المنازل، أي أجهزة الكمبيوتر الشخصية والهواتف المحمولة وأجهزة الحافة.
ومع ذلك، فإن السيناريوهات المختلفة لها متطلبات مختلفة، بما في ذلك خفض التكاليف وتحسين الأداء. يجب أن يضمن Out of the Box أن يتمكن المستخدمون من استخدامه فورًا بعد فتح صفحة ويب أو تنزيل تطبيق. يحتاج الهاتف المحمول إلى توفير الطاقة. يجب تشغيل Edge على الأجهزة دون نظام التشغيل. في بعض الأحيان، تحتاج التكنولوجيا أيضًا إلى التشغيل على شرائح منخفضة الطاقة ومنخفضة الحوسبة. هذه هي الصعوبات التي يواجهها الجميع في التطبيقات المختلفة. كيفية حلها؟
هناك إجماع في مجال MLC، ألا وهو تصميم الأشعة تحت الحمراء متعدد المستويات.يحتوي النواة على ثلاث طبقات، الطبقة الأولى Graph-Level IR، والطبقة الوسطى Tensor-Level IR، والطبقة التالية Hardware-Level IR. هذه الطبقات ضرورية لأن النموذج عبارة عن رسم بياني، والطبقة الوسطى هي Tensor-Level IR، وجوهر MLC هو تحسين الحوسبة Tensor. الطبقتان أدناه، Hardware-Level IR وHardware، مرتبطتان ببعضهما البعض، مما يعني أن TVM لن تشارك في إنشاء تعليمات التجميع بشكل مباشر، لأنه ستكون هناك بعض تقنيات التحسين الأكثر تفصيلاً في المنتصف، والتي سيتم حلها بواسطة الشركة المصنعة أو المترجم.

تم تصميم ML Compiler مع وضع الأهداف التالية في الاعتبار:
- تقليل التبعية
أولاً، قم بتقليل نشر التبعيات.السبب وراء عدم انتشار تطبيقات الذكاء الاصطناعي بشكل كبير هو أن عتبة النشر مرتفعة للغاية. لقد قام عدد أكبر من الأشخاص بتشغيل ChatGPT مقارنة بـ Stable Diffusion، ليس لأن Stable Diffusion ليس قويًا بما يكفي، ولكن لأن ChatGPT يوفر بيئة يمكن استخدامها جاهزة للاستخدام. في رأيي، مع Stable Diffusion، تحتاج إلى تنزيل نموذج من GitHub أولاً، ثم فتح خادم GPU لنشره، ولكن ChatGPT يعمل جاهزًا للاستخدام. إن النقطة الأساسية في الاستخدام الجاهز للتطبيق هي تقليل التبعيات بحيث يمكن للجميع استخدامه وفي جميع البيئات.
- دعم الأجهزة المختلفة
النقطة الثانية هي أنه يمكنه دعم أجهزة مختلفة.إن نشر الأجهزة المتنوعة ليس هو القضية الأكثر أهمية في المراحل المبكرة من التطوير، ولكن مع تطوير شرائح الذكاء الاصطناعي في الداخل والخارج، سيصبح الأمر أكثر وأكثر أهمية، خاصة بالنظر إلى البيئة المحلية الحالية والوضع الراهن لشركات الشرائح المحلية، الأمر الذي يتطلب منا أن يكون لدينا دعم جيد لجميع أنواع الأجهزة.
- تحسين التجميع
النقطة الثالثة هي تحسين التجميع العام.من خلال تجميع طبقات IR السابقة، يمكن تحسين الأداء، بما في ذلك تحسين كفاءة التشغيل وتقليل استخدام الذاكرة.
الآن يعتبر معظم الأشخاص أن التجميع والتحسين هما النقطة الأكثر أهمية، ولكن بالنسبة للمجتمع بأكمله، فإن النقطتين الأوليين مهمتان للغاية. نظرًا لأن هذا من وجهة نظر المترجم، وهاتين النقطتين تمثلان اختراقات من الصفر إلى واحد، فإن تحسين الأداء غالبًا ما يكون بمثابة الكريمة على الكعكة.
العودة إلى موضوع الخطاب،أقوم بتقسيم تطور TVM إلى أربع مراحل:هذا مجرد رأيي الشخصي.
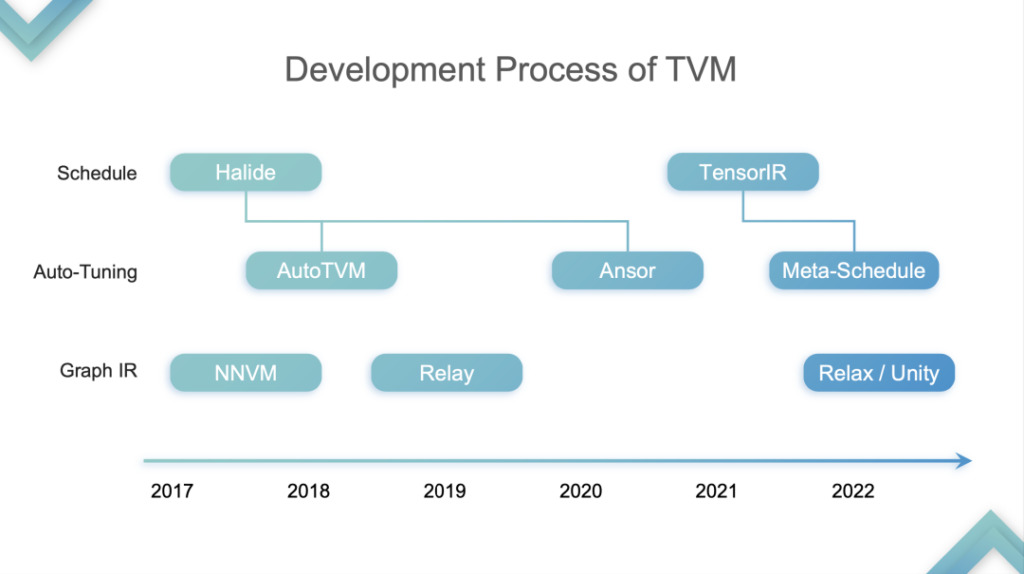
تجريد TensorIR
المرحلة 1:في هذه المرحلة، يقوم TVM بتحسين وتسريع الاستدلال على وحدة المعالجة المركزية ووحدة معالجة الرسومات. تشير وحدة معالجة الرسوميات (GPU) على وجه التحديد إلى الجزء المادي من SIMT. في هذه المرحلة، بدأ العديد من بائعي الحوسبة السحابية في استخدام TVM لأنهم وجدوا أنه يمكنه تسريع كل من وحدة المعالجة المركزية ووحدة معالجة الرسومات. لماذا؟ لقد ذكرت سابقًا أن وحدة المعالجة المركزية ووحدة معالجة الرسومات لا تدعم Tensorization. كان الجيل الأول من TVM TE Schedule يعتمد على Halide ولم يكن لديه دعم Tensorization جيد. لذلك، فإن التطوير اللاحق لـ TVM اتبع المسار الفني لتطوير Halide، بما في ذلك Auto TVM وAnsor، والتي لم تكن صديقة لدعم Tensorization.
أولاً، دعونا نلقي نظرة على عملية تطوير الأجهزة. من وحدة المعالجة المركزية إلى وحدة معالجة الرسومات كان حوالي عامي 2015 و2016، ومن وحدة معالجة الرسومات إلى وحدة معالجة الرسومات كان حوالي عام 2019. لدعم Tensorization،قامت TVM أولاً بتحليل خصائص البرامج Tensorized.
- أعشاش حلقة مُحسّنة مع ربط الخيط
أولاً، هناك حاجة إلى اختبار الحلقة، وهو مطلوب لجميع البرامج Tensorized. هناك تحميل بيانات متعددة الأبعاد في الأسفل. وهذا يختلف عن CMT و CPU. يتم تخزينه وحسابه في المتجهات وليس في القياسات القياسية.
- تحميل البيانات متعددة الأبعاد/تخزينها في مخزن ذاكرة متخصص
ثانياً، يتم تخزينه في مخزن ذاكرة خاص.
- جسم حسابي موتر معتم لضرب مصفوفة 16×16
ثالثًا، سيكون هناك مجموعة من الأجهزة التي تسمح بإجراء العمليات الحسابية. يتم استخدام البدائية الموترية التالية كمثال لحساب عملية ضرب المصفوفة 16*16. لم يعد يتم التعبير عن هذا الحساب كنمط حسابي مع مجموعة قياسية، بل يتم حسابه كوحدة حسابية بتعليمات واحدة.

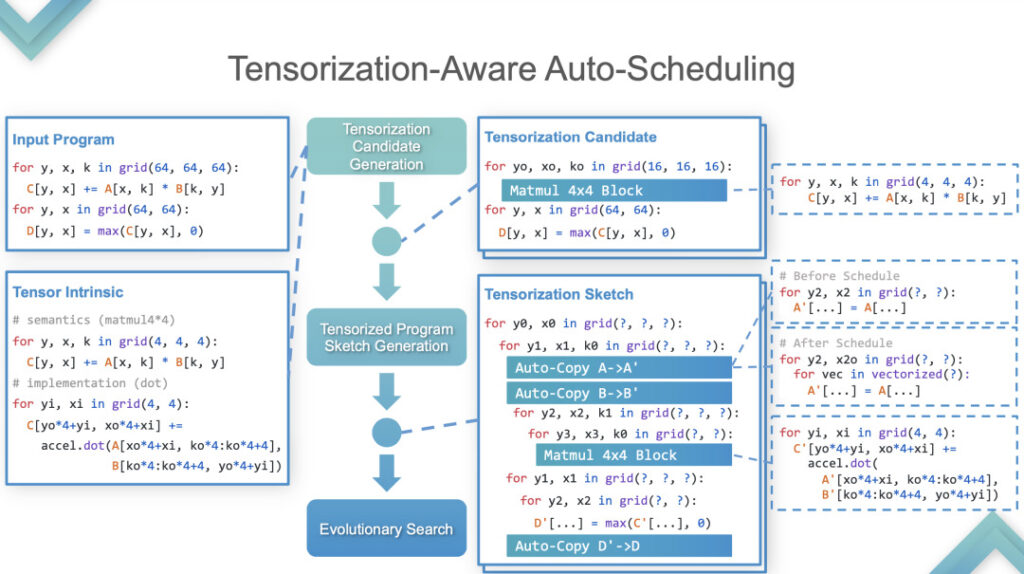
استنادًا إلى التحليلات النوعية الثلاثة المذكورة أعلاه لبرنامج Tensorized، قدمت TVM الكتلة الحسابية. الكتلة هي وحدة حوسبة، مع التعشيش في الطبقة الخارجية، ومكرر التكرار والعلاقات التبعية في الوسط، والجسم في الأسفل. مفهومها هو فصل حساب الطبقات الداخلية والخارجية، أي عزل الحساب الداخلي عن الحساب الموتر.
المرحلة الثانية:في هذه المرحلة، يقوم TVM بإجراء عملية Auto-Tensorrization. فيما يلي مثال لتوضيح كيفية تنفيذه بالتفصيل.

التوسّع التلقائي
برنامج الإدخال والموتر الداخلي هما المدخلان. تظهر النتائج أن TensorIR و TensorRT متساويان بشكل أساسي في وحدة معالجة الرسومات، ولكن أداء بعض النماذج القياسية ليس جيدًا جدًا. نظرًا لأن النموذج القياسي هو المقياس القياسي لـ ML Perf، فإن مهندسي NVIDIA يقضون الكثير من الوقت في القيام بذلك. من النادر نسبيًا التفوق على TensorRT في النماذج القياسية، وهو ما يعادل التغلب على أحدث التقنيات في الصناعة.
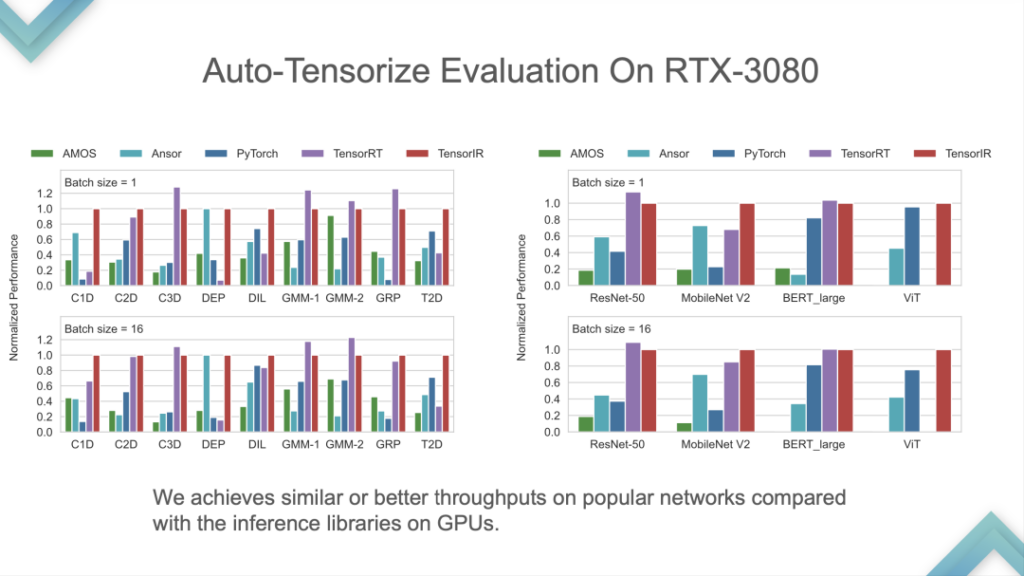
هذه مقارنة أداء لوحدة المعالجة المركزية التي طورتها ARM بنفسها. يمكن أن يكون TensorIR و ArmComputeLib أسرع بنحو مرتين من Ansor و PyTorch من البداية إلى النهاية. الأداء ليس هو الأكثر أهمية، ففكرة AutoTensorization هي الأساس.
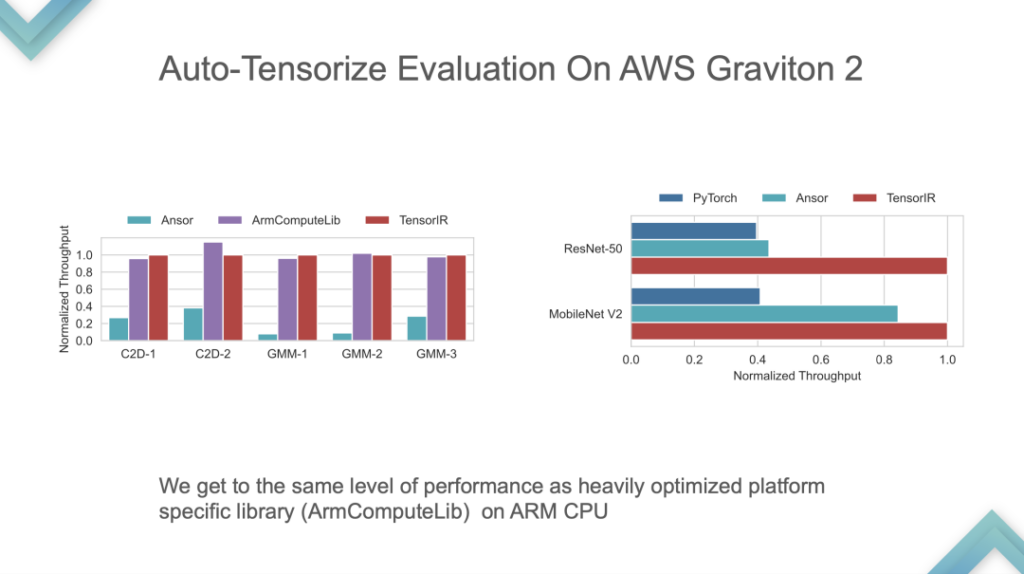
المرحلة 3:مُجمِّع ML متكامل للأجهزة المُدارة بواسطة Tensorized. في هذه المرحلة، يمكن إلقاؤه على وحدة معالجة الرسوميات أو شريحة تسريع مدعومة بالفعل، يليه الضبط التلقائي واستيراد النموذج، لتشكيل نظام متسق ذاتيًا. في هذه المرحلة، جوهر TVM هو من البداية إلى النهاية. من الممكن تطوير نموذج للاستخدام المباشر، ولكن التخصيص أمر صعب للغاية.
بعد ذلك، سأتحدث عن تطوير والتفكير في Relax وUnity ببطء قليلاً، لأن:
- أنا شخصيا أعتقد أن الاسترخاء والوحدة أكثر أهمية؛
- إنه لا يزال في مرحلة تجريبية، والعديد من الأشياء هي مجرد أفكار، تفتقر إلى العرض التوضيحي الشامل والرمز الكامل.
حدود Apache TVM Stack:
- فجوة كبيرة بين Relay وTIR. المشكلة الأكبر مع TVM هي أن نموذج التجميع من التتابع إلى TIR شديد الانحدار؛
- خط أنابيب ثابت لمعظم الأجهزة. العملية القياسية لـ TVM هي Relay to TIR إلى؟ بعد التجميع، وجدت أن العديد من الأجهزة إما تدعم BYOC فقط أو تريد استخدام BYOC+TIR، لكن Relay لا يدعمها بشكل جيد، سواء TIR أو المكتبة. باستخدام تسريع وحدة معالجة الرسوميات كمثال، تم إصلاح الأشياء الأساسية لـ Relay. يمكنك إما كتابة CUDA للضبط التلقائي، أو استخدام BYOC لـ TensorRT، أو استخدام cuBLAS لضبط مكتبات الطرف الثالث. على الرغم من وجود العديد من الخيارات، فإن الأمر يتعلق دائمًا باختيار واحد أو الآخر. هذه المشكلة لها تأثير كبير ويصعب حلها على Relay.
الحل: TVM Unity.
أباتشي TVM Unity
يتم التعامل مع طبقتي IR، Relax وTIR، كوحدة واحدة ودمجها في نموذج برمجة Graph-TIR. شكل الاندماج: إذا أخذنا أبسط نموذج خطي كمثال، ففي هذه الحالة يكون نظام الأشعة تحت الحمراء بأكمله قابلاً للتحكم والبرمجة. تحل لغة Graph-TIR مشكلة الطبقة السفلية شديدة الانحدار. يمكن تعديل المشغلين رفيعي المستوى خطوة بخطوة، ويمكن حتى تغييرهم إلى أي BYOC أو مكالمات وظيفية.

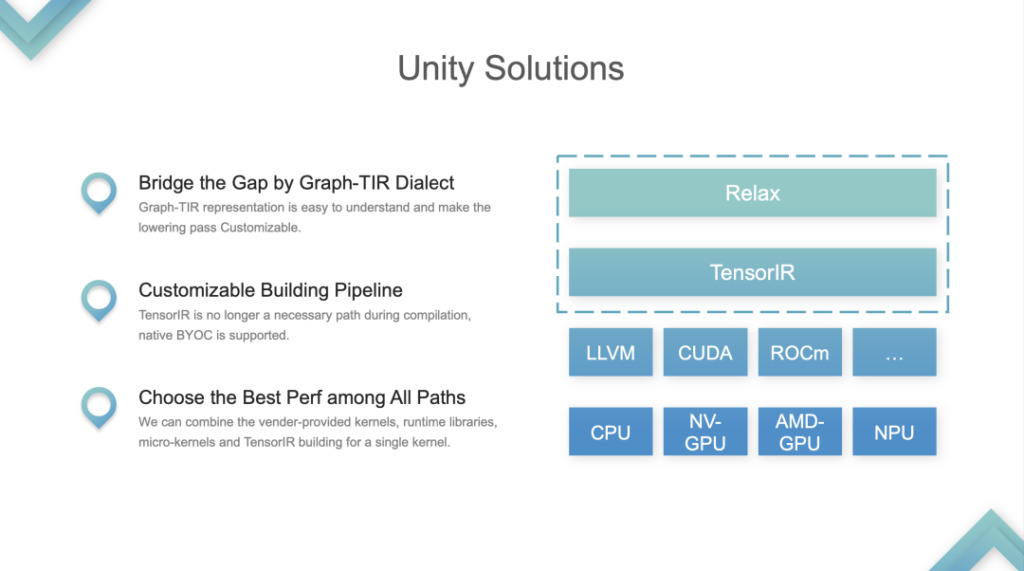
1. دعم الحلول المخصصة لمشاكل بناء خطوط الأنابيب. كان خط أنابيب TVM الأصلي هو نقل TIR إضافي، ثم إجراء الضبط على TIR، ثم تمريره إلى LLVM أو CUDA بعد الضبط. كان هذا خط أنابيب مبنى ثابت. الآن تغير خط الأنابيب.
2. اختر أفضل أداء بين جميع المسارات. يمكن للمطورين الاختيار بين المكتبة أو TIR واستدعاء أي شيء. هذه هي المشكلة الأكثر أهمية التي تم حلها بواسطة Unity، ويعتبرها المجتمع الحل الموحد لتجميع ML.
سوء الفهم
- TVM و MLIR في منافسة
في الواقع، لا توجد علاقة تنافسية واضحة على نفس المستوى بين TVM وMLIR. يركز TVM على تجميع التعلم الآلي MLC، بينما يركز MLIR على متعدد المستويات، ويمكن أيضًا استخدام ميزاته لتجميع ML. يستخدم المطورون MLIR لتجميع التعلم الآلي، من ناحية لأن MLIR يتمتع بالتكامل الأصلي مع الأطر مثل PyTorch، ومن ناحية أخرى لأنه قبل Unity، كانت قدرات التخصيص الخاصة بـ TVM ضعيفة نسبيًا.
- TVM = محرك الاستدلال لوحدة المعالجة المركزية/وحدة معالجة الرسومات
لم يكن TVM محرك استدلال على الإطلاق. يمكنه القيام بالتجميع، ويمكن للمطورين استخدامه لتسريع الاستدلال. TVM عبارة عن بنية أساسية للمترجم، ولكنها ليست محرك استنتاج. إن فكرة أن "TVM لا يمكن استخدامها إلا للتسريع" خاطئة. السبب وراء إمكانية استخدام TVM للتسريع هو في الأساس بسبب المترجم، الذي يكون أسرع من طرق تنفيذ الوضع المتلهف مثل PyTorch.
- TVM = الضبط التلقائي
قبل ظهور Relax، كان رد فعل الجميع الأول تجاه TVM هو أنهم يستطيعون الحصول على أداء أفضل من خلال الضبط التلقائي. الاتجاه التنموي القادم لـ TVM هو تخفيف هذا المفهوم. يوفر TVM طرقًا مختلفة لتحقيق أداء أفضل وتخصيص عملية التجميع بأكملها. ما يجب على TVM Unity فعله هو توفير إطار عمل يجمع بين المزايا المختلفة.
الخطوة التالية
في الخطوة التالية، سوف يتطور TVM إلى بنية أساسية لمجمع التعلم الآلي متعدد الطبقات ويسعى جاهداً ليصبح خط أنابيب بناء قابل للتخصيص لبرامج خلفية مختلفة، ويدعم التخصيص على أجهزة مختلفة. ويتطلب هذا الجمع بين الأساليب المختلفة ودمج نقاط القوة لدى الأطراف المختلفة.
الأسئلة والأجوبة
س1: هل لدى TVM أي خطط لتحسين النماذج الكبيرة؟
ج1: فيما يتعلق بالنماذج الكبيرة، لدينا بعض الأفكار الأولية. في الوقت الحالي، بدأ TVM في تنفيذ التفكير الموزع وبعض التدريب البسيط، ولكن الأمر سيستغرق بعض الوقت قبل أن يتم تنفيذه فعليًا.
س2: ما هو الدعم والتطور الذي سيحظى به Relax في Dynamic Shape في المستقبل؟
أ 2: يدعم Relay vm الشكل الديناميكي، لكنه لا يولد الاستنتاج الرمزي. على سبيل المثال، يكون خرج عملية ضرب مصفوفة nmk هو n وm، ولكن في Relay، تسمى nmks الثلاثة بشكل جماعي Any، مما يعني البعد غير المعروف، ويكون خرجها أيضًا بعدًا غير معروف. يمكن لـ Relay VM تشغيل هذه المهام، ولكن سيتم فقد بعض المعلومات أثناء مرحلة التجميع، لذا فإن Relax يحل هذه المشكلات. هذا هو تحسين Relax على Relay في الشكل الديناميكي.
س3: الجمع بين تحسين TVM وتحسين الجهاز. إذا كنت تستخدم Graph لإنشاء التعليمات بشكل مباشر، فلا يبدو أن TE وTIR يُستخدمان كثيرًا في تحسين الجهاز. إذا تم استخدام BYOC، فيبدو أنه يتم تخطي TE وTIR أيضًا. تم ذكره في المشاركة أن Relax قد يحتوي على بعض التخصيصات، والتي يبدو أنها قادرة على حل هذه المشكلة.
ج3: في الواقع، لقد اتخذ العديد من مصنعي الأجهزة بالفعل مسار TIR، في حين لم ينتبه بعض المصنعين إلى التقنيات ذات الصلة وما زالوا يختارون طريقة BYOC. BYOC ليس تجميعًا بالمعنى الدقيق للكلمة، ولديه قيود على نمط البناء. وبشكل عام، لا يعني هذا أن المؤسسات لا تستطيع استخدام التكنولوجيا المجتمعية، بل إنها تتخذ خيارات مختلفة بناء على ظروفها الخاصة.
س4: هل سيؤدي ظهور TVM Unity إلى ارتفاع تكاليف الهجرة؟ من وجهة نظر TVM PMC، كيف يمكننا مساعدة المستخدمين على الانتقال بسلاسة إلى TVM Unity؟
ج4: لم يتخل مجتمع TVM عن Relay، بل أضاف خيار Relax فقط. لذلك، سوف يستمر الإصدار القديم في التطور، ولكن من أجل استخدام بعض الميزات الجديدة، قد تكون هناك حاجة إلى بعض التعليمات البرمجية ونقل الإصدار.
بعد إصدار Relax بالكامل، سيوفر المجتمع دروسًا تعليمية للهجرة ودعمًا معينًا للأدوات لدعم الاستيراد المباشر لنماذج Relay إلى Relax. ومع ذلك، فإن نقل الإصدار المخصص الذي تم تطويره استنادًا إلى Relay إلى Relax لا يزال يتطلب قدرًا معينًا من العمل، والذي سيستغرق حوالي شهر لفريق يتكون من أكثر من اثني عشر شخصًا في الشركة.
س5: لقد حقق TensorIR تقدمًا كبيرًا في Tensor مقارنة بالسابق، ولكنني لاحظت أن TensorIR يستهدف بشكل أساسي نماذج البرمجة مثل SIMT و SIMD، وهي طرق برمجة ناضجة. هل هناك أي تقدم في TensorIR في العديد من شرائح الذكاء الاصطناعي ونماذج البرمجة الجديدة؟
ج 5: من وجهة نظر المجتمع، فإن السبب وراء استخدام TensorIR لنموذج SIMT هو أنه لا يمكن استخدام سوى أجهزة SIMT الآن. إن مجموعات الأجهزة والتعليمات الخاصة بالعديد من الشركات المصنعة ليست مفتوحة المصدر. الأجهزة التي يمكن الوصول إليها من الشركات المصنعة الكبرى هي في الأساس وحدة المعالجة المركزية ووحدة معالجة الرسومات وبعض أنظمة الهواتف المحمولة فقط. لا تتمتع مجتمعات الشركات المصنعة الأخرى بإمكانية الوصول إليها بشكل أساسي، وبالتالي لا يمكن أن تعتمد على نماذج البرمجة الخاصة بها. علاوة على ذلك، حتى لو عمل المجتمع والمؤسسات معًا لإنشاء TIR بمستوى مماثل، فإنه لا يمكن أن يكون مفتوح المصدر بسبب الاعتبارات التجارية.
ما ورد أعلاه هو ملخص لخطاب فنغ سي يوان في محطة Meet TVM شنغهاي لعام 2023.وبعد ذلك، سيتم أيضًا إصدار المحتوى التفصيلي الذي شاركه الضيوف الآخرون لهذا الحدث على هذا الحساب الرسمي واحدًا تلو الآخر. من فضلك استمر في الاهتمام!
احصل على PPT:اتبع حساب WeChat العام "HyperAI Super Neural Network" ورد بالكلمة الرئيسية في الخلفية TVM شنغهاي،احصل على العرض التقديمي الكامل.
وثائق TVM الصينية:https://tvm.hyper.ai/
عنوان GitHub:https://github.com/apache/tvm








