Command Palette
Search for a command to run...
أطلقت شركة DeepMind برنامج DreamerV3، وهو خوارزمية تعلم تعزيزي عامة يمكنها تعليم نفسها كيفية التقاط الماس
ماين كرافت لا يلعبها البشر فقط. كما قامت شركة DeepMind المعروفة بتكنولوجيا الذكاء الاصطناعي بتطوير ذكاء اصطناعي مخصص للعب Minecraft!
المحتويات في لمحة:التعلم التعزيزي هو منتج متعدد التخصصات، وجوهره هو تحقيق اتخاذ القرارات بشكل تلقائي ومستمر. ستقدم هذه المقالة أحدث نتائج البحث والتطوير التي توصلت إليها شركة DeepMind: DreamerV3، وهي خوارزمية عامة تعمل على توسيع نطاق تطبيق التعلم المعزز. الكلمات المفتاحية:التعلم التعزيزي خوارزمية DeepMind العامة
في 12 يناير بتوقيت بكين، نشر الحساب الرسمي لشركة DeepMind على تويتر:تم الإعلان رسميًا عن Dreamer V3،هذه هي أول خوارزمية عامة يمكنها جمع الماس من الصفر في لعبة "ماين كرافت" دون الرجوع إلى البيانات البشرية، مما يحل تحديًا مهمًا آخر في مجال الذكاء الاصطناعي.

يُعد التعلم التعزيزي مشكلة من حيث قابلية التوسع، وهناك حاجة إلى خوارزميات عامة لتطويره
يتيح التعلم التعزيزي لأجهزة الكمبيوتر حل مهمة من خلال التفاعل، مثل قدرة AlphaGo على هزيمة البشر في لعبة Go وقدرتها على هزيمة اللاعبين البشر الهواة في لعبة Dota 2.

ومع ذلك، لتطبيق الخوارزمية على سيناريوهات تطبيق جديدة، مثل الانتقال من ألعاب الطاولة إلى ألعاب الفيديو أو مهام الروبوتات،يُطلب من المهندسين تطوير خوارزميات متخصصة بشكل مستمر.مثل التحكم المستمر، والمكافآت المتفرقة، ومدخلات الصور، والبيئات المكانية.
يتطلب هذا قدرًا كبيرًا من الخبرة وموارد الحوسبة لضبط الخوارزميات.وهذا يعوق بشكل كبير توسيع النموذج. لقد أصبح إنشاء خوارزميات عامة قادرة على تعلم وإتقان مجالات جديدة دون الحاجة إلى ضبط طريقة مهمة لتوسيع نطاق تطبيقات التعلم المعزز وحل مشكلات اتخاذ القرار.
وكنتيجة لذلك، ظهر برنامج DreamerV3، الذي تم تطويره بشكل مشترك من قبل شركة DeepMind وجامعة تورنتو.
DreamerV3: خوارزمية عامة تعتمد على نموذج العالم
DreamerV3 هي خوارزمية عامة وقابلة للتطوير تعتمد على نموذج العالم.يمكن تطبيقه على مجموعة واسعة من المجالات تحت فرضية المعلمات الفائقة الثابتة، وهو أفضل من الخوارزميات المتخصصة.
تتضمن هذه المجالات الفعل المستمر والفعل المنفصل، والمدخلات البصرية والمدخلات منخفضة الأبعاد، والعالم ثنائي الأبعاد والعالم ثلاثي الأبعاد، وميزانيات البيانات المختلفة، وترددات المكافأة ومقاييس المكافأة، وما إلى ذلك.

يتكون DreamerV3 من 3 شبكات عصبية تم تدريبها في وقت واحد من تجربة أعيد تشغيلها دون مشاركة التدرجات:
1. نموذج العالم:التنبؤ بالنتائج المستقبلية للإجراءات المحتملة
2. الناقد:تحديد قيمة كل حالة
3. الممثل:تعلم كيفية جعل المواقف القيمة ممكنة

كما هو موضح في الشكل أعلاه، يقوم نموذج العالم بتشفير المدخلات الحسية في تمثيل منفصل zt. يتم التنبؤ بـ zt بواسطة نموذج تسلسل بحالة متكررة ht ويتم إعطاء إجراء عند. يتم إعادة بناء المدخلات إلى إشارة تعليمية ثم إلى تمثيل الشكل.
ويتعلم الممثل والناقد من مسار التمثيل المجرد الذي تنبأ به نموذج العالم.
من أجل التكيف بشكل أفضل مع المهام عبر المجالات،وتحتاج هذه المكونات إلى التكيف مع أحجام الإشارات المختلفة وتحقيق التوازن القوي بين الشروط بين أهدافها.
قام المهندسون باختبار DreamerV3 على أكثر من 150 مهمة ذات معلمات ثابتة وقارنوها بأفضل الطرق المسجلة في الأدبيات. وأظهرت التجارب أن DreamerV3 يتمتع بقدرة عالية على التنوع وقابلية التوسع للمهام في مجالات مختلفة.
حقق DreamerV3 نتائج ممتازة في 7 معايير وأسس مستويات SOTA جديدة في التحكم المستمر في الحالة والصورة وBSuite وCrafter.
ومع ذلك، لا يزال DreamerV3 يعاني من بعض القيود.على سبيل المثال، عندما تكون خطوات البيئة أقل من 100 مليون، لا تستطيع الخوارزمية التقاط الماس في جميع المشاهد مثل اللاعبين البشريين، ولكن فقط في بعض الأحيان.
الوقوف على أكتاف العمالقة، ومراجعة تاريخ تطور عائلة دريمر
الجيل الأول: الحالم
وقت الإصدار:ديسمبر 2019
المؤسسات المشاركة:جامعة تورنتو، DeepMind، Google Brain
عنوان الورقة:https://arxiv.org/pdf/1912.01603.pdf
مقدمة الخوارزمية:
Dreamer هو وكيل التعلم التعزيزي الذي يمكنه حل المهام طويلة المدى من الصور باستخدام الخيال الكامن فقط.
ويستخدم نموذج العالم لتحقيق التعلم السلوكي الفعال استنادًا إلى الانتشار الخلفي لتوقعات النموذج. في 20 مهمة تحكم بصرية صعبة، تفوق Dreamer على الطرق السائدة من حيث كفاءة البيانات، ووقت الحساب، والأداء النهائي.
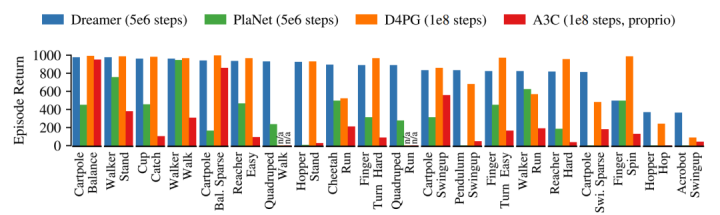
يرث Dreamer كفاءة البيانات الخاصة بـ PlaNet مع تجاوز الأداء المقارب لأفضل وكيل خالٍ من النماذج في ذلك الوقت. بعد 5×106 خطوات بيئية، وصل متوسط أداء Dreamer في كل مهمة إلى 823، بينما كان أداء PlaNet 332 فقط. وكان أعلى أداء لوكيل D4PG الخالي من النماذج هو 786 بعد 108 خطوات.
الجيل الثاني: DreamerV2
وقت الإصدار:أكتوبر 2020
المؤسسات المشاركة:أبحاث جوجل، DeepMind، جامعة تورنتو
عنوان الورقة:https://arxiv.org/pdf/2010.02193.pdf
مقدمة الخوارزمية:
DreamerV2 هو وكيل التعلم التعزيزي الذي يتعلم السلوكيات من التوقعات في مساحة كامنة مضغوطة لنموذج عالمي.
ملاحظة: يستخدم نموذج العالم تمثيلات منفصلة ويتم تدريبه بشكل منفصل عن السياسة.
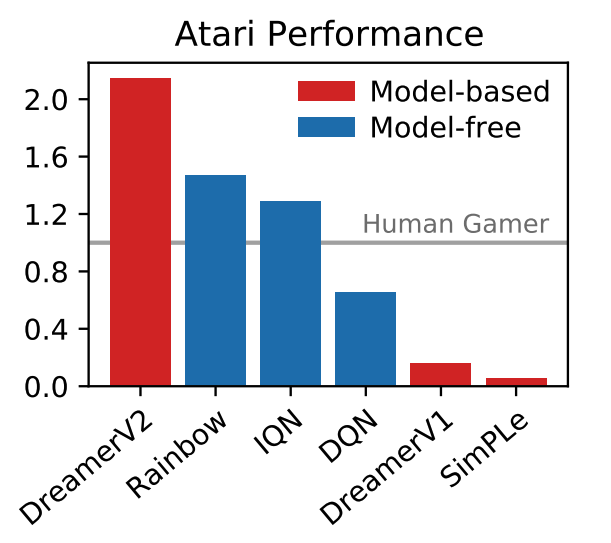
DreamerV2 هو أول وكيل يحقق أداءً على مستوى الإنسان في 55 مهمة من معايير Atari من خلال تعلم السلوكيات من نموذج عالمي تم تدريبه بشكل منفصل. باستخدام نفس الميزانية الحسابية والوقت المحدد، يحقق DreamerV2 200 مليون إطار، متجاوزًا الأداء النهائي لأفضل وكلاء وحدة معالجة الرسوميات الفردية IQN وRainbow.
بالإضافة إلى ذلك، يعد DreamerV2 مناسبًا أيضًا للمهام ذات الإجراءات المستمرة. ويتعلم نموذجًا عالميًا معقدًا لروبوت يشبه الإنسان ويحل مشاكل الوقوف والمشي فقط من خلال إدخال البكسل.
يتصدر مستخدمو تويتر استخدام الميمات في قسم التعليقات
وفيما يتعلق بميلاد DreamerV3، قام العديد من مستخدمي الإنترنت أيضًا بإلقاء النكات في قسم التعليقات على موقع تويتر الخاص بشركة DeepMind.

حرر البشرية ولن تضطر إلى لعب Minecraft مرة أخرى.

توقف عن لعب الألعاب وافعل شيئًا حقيقيًا! @DeepMind والرئيس التنفيذي ديميس هاسابيس

الزعيم النهائي في "ماين كرافت"، Ender Dragon، يرتجف.
في السنوات الأخيرة، أصبحت لعبة "ماين كرافت" محورًا لأبحاث التعلم التعزيزي، وتم عقد مسابقات دولية حول جمع الماس في "ماين كرافت" عدة مرات.
ويعتبر حل هذا التحدي دون الحاجة إلى بيانات بشرية بمثابة إنجاز كبير في مجال الذكاء الاصطناعي.نظرًا للعقبات المتمثلة في المكافآت القليلة، والاستكشاف الصعب، والفترات الزمنية الطويلة في بيئة العالم المفتوح التي يتم إنشاؤها إجرائيًا، فإن الأساليب السابقة تحتاج إلى أن تعتمد على البيانات البشرية أو البرامج التعليمية.
DreamerV3 هي أول خوارزمية قامت بتعليم نفسها بالكامل كيفية جمع الماس في Minecraft من الصفر.ويؤدي ذلك إلى توسيع نطاق تطبيق التعلم المعزز.كما قال مستخدمو الإنترنت، DreamerV3 هي بالفعل خوارزمية عامة ناضجة. لقد حان الوقت لتتعلم كيفية ترقية وقتل الوحوش بنفسك ومحاربة الزعيم النهائي، Ender Dragon!

عرض الرابط الأصلي:أطلقت شركة DeepMind برنامج DreamerV3، وهو خوارزمية تعلم تعزيزي عامة يمكنها تعليم نفسها كيفية التقاط الماس
تابع HyperAI لتتعرف على المزيد من خوارزميات وتطبيقات الذكاء الاصطناعي المثيرة للاهتمام. نقوم أيضًا بتحديث البرامج التعليمية بانتظام، لذا دعونا نتعلم ونتحسن معًا!








