Command Palette
Search for a command to run...
خذ تطبيق الرسوم المتحركة كمثال واستخدم TorchServe لضبط النموذج
محتويات قدم القسم السابق الخطوات الخمس لنشر نموذج TorchServe وضبطه لنشر النموذج في بيئة الإنتاج. يستخدم هذا القسم تطبيق الرسومات المتحركة كمثال لإظهار تأثير تحسين النموذج لـ TorchServe. تم نشر هذه المقالة لأول مرة على الحساب الرسمي لـ WeChat:مجتمع مطوري PyTorch
في العام الماضي، استخدمت شركة Meta تطبيق Animated Drawings لجعل رسومات الأطفال المرسومة يدويًا "حيوية" باستخدام الذكاء الاصطناعي، وتحويل الرسومات الثابتة إلى رسوم متحركة في ثوانٍ.


رسومات متحركةsketch.metademolab.com/
وهذا ليس سهلاً بالنسبة للذكاء الاصطناعي. تم تصميم الذكاء الاصطناعي في الأصل لمعالجة الصور في العالم الحقيقي. بالمقارنة مع الصور الحقيقية، فإن رسومات الأطفال تختلف كثيرًا في الشكل والأسلوب، وهي أكثر تعقيدًا ولا يمكن التنبؤ بها. لذلك، قد لا تكون أنظمة الذكاء الاصطناعي السابقة مناسبة لمعالجة المهام المشابهة للرسومات المتحركة.
ستتخذ هذه المقالة الرسومات المتحركة كمثال لشرح كيفية استخدام TorchServe بالتفصيل لضبط النموذج الذي سيتم نشره في بيئة الإنتاج.
4 عوامل تؤثر على ضبط النموذج في بيئات الإنتاج
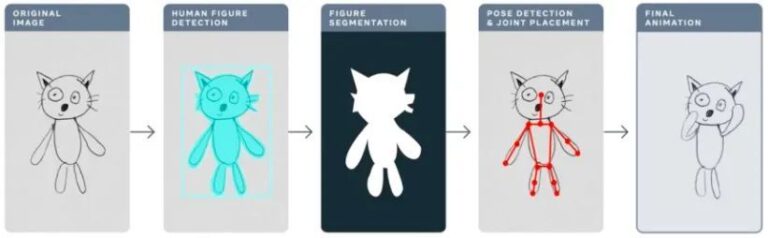
يوضح سير العمل التالي الفكرة العامة لاستخدام TorchServe لنشر نموذج في بيئة إنتاجية.

في معظم الحالات، يتم تحسين النماذج المنشورة في بيئات الإنتاج استنادًا إلى اتفاقيات مستوى الخدمة (SLAs) الخاصة بالإنتاجية أو زمن الوصول.
عادةً ما تكون التطبيقات في الوقت الفعلي أكثر اهتمامًا بالزمن الكامن، في حين أن التطبيقات غير المتصلة بالإنترنت أكثر اهتمامًا بالإنتاجية.
هناك العديد من العوامل التي تؤثر على أداء النماذج المستخدمة في بيئات الإنتاج. تسلط هذه المقالة الضوء على أربعة منها:
1. تحسينات النموذج
هذه خطوة أولية لنشر النماذج في الإنتاج وتتضمن التكميم والتقليم واستخدام الرسوم البيانية IR (TorchScript في PyTorch) ودمج النوى والعديد من التقنيات الأخرى. حاليًا، تتوفر العديد من التقنيات المشابهة في TorchPrep كأدوات CLI.
2. الاستدلال الدفعي
يشير إلى إدخال مدخلات متعددة في نموذج. يتم استخدامه بشكل متكرر أثناء عملية التدريب ويساعد أيضًا في التحكم في التكاليف أثناء مرحلة الاستدلال.
يتم تحسين مسرعات الأجهزة للتوازي، وتساعد الدفعات على الاستفادة الكاملة من قوة الحوسبة، مما يؤدي غالبًا إلى زيادة الإنتاجية. الفرق الرئيسي في الاستدلال هو أنك لست مضطرًا إلى الانتظار لفترة طويلة للحصول على دفعة من العميل، وهو ما نسميه غالبًا الدفعة الديناميكية.
3. أعداد العمال
يقوم TorchServe بنشر النموذج من خلال العمال. العاملون في TorchServe هم عمليات Python التي تحتوي على نسخة من أوزان النموذج المستخدمة للاستدلال. لن يستفيد عدد قليل جدًا من العمال من التوازي الكافي؛ سيؤدي وجود عدد كبير جدًا من العمال إلى انخفاض التنافس بين العمال وانخفاض الأداء الشامل.
4. الأجهزة
اختر الأجهزة المناسبة من TorchServe ووحدة المعالجة المركزية ووحدة معالجة الرسومات وAWS Inferentia استنادًا إلى طرازك وتطبيقك ووقت الاستجابة وميزانية الإنتاج.
تم تصميم بعض تكوينات الأجهزة للحصول على أفضل أداء في فئتها، في حين تم تصميم البعض الآخر لتحقيق المزيد من التحكم في التكلفة المتوقعة. تظهر التجارب أن وحدة معالجة الرسوميات (GPU) تكون أكثر ملاءمة عندما يكون حجم الدفعة كبيرًا؛ عندما يكون حجم الدفعة صغيرًا أو يتطلب زمن وصول منخفضًا، تكون وحدة المعالجة المركزية وAWS Inferentia أكثر فعالية من حيث التكلفة.
نصائح: أشياء يجب مراعاتها عند تحسين أداء TorchServe
قبل أن تبدأ،دعونا أولاً نشارك بعض النصائح حول نشر النماذج باستخدام TorchServe والحصول على أفضل أداء.
* تعلم البرنامج التعليمي الرسمي لـ PyTorch
يرتبط اختيار الأجهزة أيضًا ارتباطًا وثيقًا باختيار تحسين النموذج.
* يرتبط اختيار الأجهزة المستخدمة في نشر النموذج ارتباطًا وثيقًا بالزمن الكامن، وتوقعات الإنتاجية، وتكلفة كل استنتاج.
بسبب الاختلافات في حجم النموذج والتطبيق، فإن بيئات إنتاج وحدة المعالجة المركزية عادة لا تكون قادرة على تحمل تكاليف نشر نماذج رؤية الكمبيوتر المماثلة.يمكنك التسجيل لاستخدام OpenBayes.com، وستحصل على 3 ساعات من RTX3090 مجانًا عند التسجيل، و10 ساعات من RTX3090 مجانًا كل أسبوع لتلبية احتياجات وحدة معالجة الرسومات العامة.
علاوة على ذلك، فإن التحسينات مثل IPEX التي تمت إضافتها مؤخرًا إلى TorchServe تجعل مثل هذه النماذج أرخص في النشر وأكثر ملاءمة لوحدة المعالجة المركزية.
للحصول على تفاصيل حول نشر نموذج تحسين IPEX، يرجى الرجوع إلى
* ينتمي العامل في TorchServe إلى عملية Python.يمكن أن توفر موازية،ينبغي تحديد عدد العمال بحذر.بشكل افتراضي، يبدأ TorchServe عددًا من العمال يساوي عدد وحدات المعالجة المركزية الافتراضية أو وحدات معالجة الرسومات المتوفرة على المضيف، مما قد يضيف وقتًا كبيرًا إلى بدء تشغيل TorchServe.
يعرض TorchServe خاصية تكوين لتعيين عدد العمال. من أجل توفير التوازي الفعال للعاملين المتعددين وتجنب تنافسهم على الموارد، يوصى بتعيين الخطوط الأساسية التالية على وحدة المعالجة المركزية ووحدة معالجة الرسومات:
وحدة المعالجة المركزية:مجموعة في المعالج torch.set_num_threads(1) . ثم قم بتعيين عدد العمال إلى عدد النوى المادية / 2 . ولكن من الممكن تحقيق أفضل تكوين للخيط من خلال الاستفادة من البرنامج النصي لتشغيل وحدة المعالجة المركزية Intel.
وحدة معالجة الرسومات:يمكن تعيين عدد وحدات معالجة الرسومات المتاحة في config.properties عدد وحدات معالجة الرسومات لإعداده. يستخدم TorchServe نظام التناوب الدوري لتعيين العمال إلى وحدات معالجة الرسوميات. اقتراح:عدد العاملين = (عدد وحدات معالجة الرسومات المتاحة) / (عدد النماذج الفريدة). لاحظ أن وحدات معالجة الرسوميات السابقة لـ Ampere لا توفر أي عزل للموارد مع وحدات معالجة الرسوميات متعددة المثيلات.
* يؤثر حجم الدفعة بشكل مباشر على زمن الوصول والإنتاجية.من أجل الاستفادة بشكل أفضل من موارد الحوسبة، يجب زيادة حجم الدفعة. هناك مقايضة بين زمن الوصول والإنتاجية؛ يمكن أن يؤدي حجم الدفعة الأكبر إلى زيادة الإنتاجية ولكن أيضًا إلى زيادة زمن الوصول.
هناك طريقتان لتعيين حجم الدفعة في TorchServe.الطريقة الأولى هي من خلال تكوين النموذج في config.properties، والطريقة الثانية هي تسجيل النموذج باستخدام واجهة برمجة التطبيقات الإدارية.
يوضح القسم التالي كيفية استخدام مجموعة معايير TorchServe لتحديد أفضل مزيج من الأجهزة والعمال وحجم الدفعة لتحسين النموذج.
تعرف على TorchServe Benchmark Suite
لاستخدام مجموعة معايير TorchServe، تحتاج أولاً إلى ملف مؤرشف، وهو الملف المذكور أعلاه. .مار وثيقة. يحتوي هذا الملف على النموذج والمعالج وجميع القطع الأثرية الأخرى المستخدمة لتحميل الاستدلال وتشغيله. يستخدم تطبيق الرسم المتحرك نموذج اكتشاف الكائنات Mask-rCNN من Detectron2
تشغيل مجموعة المعايير
يمكن لمجموعة معايير الأداء الآلية في TorchServe معايرة نماذج متعددة تحت أحجام دفعات مختلفة وإعدادات العمال وتقارير الإخراج.
يتعلم مجموعة معايير الأداء الآلية
ابدأ بالجري:
استنساخ git https://github.com/pytorch/serve.git cd Serve/benchmarks pip install -r requirements-ab.txt apt-get install apache2-utils
تكوين إعدادات مستوى النموذج في ملف yaml:
اسم النموذج: وضع الحرص: محرك المعيار: "ab" عنوان URL: "مسار ملف .mar" العاملون: - 1 - 4 تأخير الدفعة: 100 حجم الدفعة: - 1 - 2 - 4 - 8 الطلبات: 10000 التزامن: 10 الإدخال: "مسار إدخال النموذج" تحليل الخلفية: خطأ بيئة التنفيذ: "محلي" المعالجات: - "وحدة المعالجة المركزية" - "وحدة معالجة الرسومات": "الكل"
سيتم إنشاء ملف yaml هذا قالب benchmark_config_template.yaml يقتبس. يحتوي ملف YAML على إعدادات إضافية لإنشاء التقارير وعرض السجلات باستخدام AWS Cloud.
معايير بايثون/auto_benchmark.py --input benchmark_config_template.yaml
قم بتشغيل المعيار وسيتم حفظ النتائج في ملف csv. _/tmp/benchmark/ab_report.csv_ أو التقرير الكامل /tmp/ts_benchmark/report.md تم العثور عليها في.
تتضمن النتائج متوسط زمن انتقال TorchServe، وزمن انتقال النموذج P99، والإنتاجية، والتزامن، وعدد الطلبات، ووقت المعالج، وغيرها من المقاييس.
ركز على تتبع العوامل التالية التي تؤثر على ضبط النموذج: التزامن، وزمن انتقال النموذج P99، والإنتاجية.
يتعين النظر إلى هذه الأرقام بالتزامن مع حجم الدفعة والمعدات المستخدمة وعدد العمال وما إذا كان قد تم تنفيذ تحسين النموذج.
تم ضبط زمن الوصول SLA لهذا النموذج على 100 مللي ثانية. هذا تطبيق في الوقت الفعلي، ويعد زمن الوصول مشكلة مهمة، ويجب أن يكون معدل الإنتاج مرتفعًا قدر الإمكان دون انتهاك اتفاقية مستوى الخدمة الخاصة بزمن الوصول.
من خلال البحث في الفضاء، قمنا بإجراء سلسلة من التجارب على أحجام دفعات مختلفة (1-32)، وأعداد العمال (1-16)، والأجهزة (وحدة المعالجة المركزية، وحدة معالجة الرسومات)، ولخصنا أفضل النتائج التجريبية، كما هو موضح في الجدول التالي:

لقد جرب هذا النموذج كل زمن الوصول على وحدة المعالجة المركزية، وحجم الدفعة، والتزامن وعدد العمال، ولكن كل ذلك فشل في تلبية اتفاقية مستوى الخدمة، بل ونجح في الواقع في تقليل زمن الوصول بمقدار 13 مرة.
أدى نقل نشر النموذج إلى وحدة معالجة الرسوميات إلى تقليل زمن الوصول على الفور من 305 مللي ثانية إلى 23.6 مللي ثانية.
أحد أبسط التحسينات التي يمكنك القيام بها لنموذجك هو تقليل دقته إلى fp16، وهو عبارة عن رمز مكون من سطر واحد (النموذج.النصف()) ، يمكن أن يقلل من زمن انتقال النموذج P99 الخاص بـ 32% ويزيد الإنتاجية بنفس المقدار تقريبًا.
هناك طريقة أخرى لتحسين النموذج وهي تحويل النموذج إلى TorchScript واستخدامه تحسين الاستدلال أو تقنيات أخرى (بما في ذلك تحسينات وقت تشغيل onnx أو tensor) التي تستفيد من الاندماجات العدوانية.
على وحدة المعالجة المركزية ووحدة معالجة الرسومات، قم بتعيين عدد العمال=1 يعمل هذا بشكل أفضل في الحالة المذكورة في هذه المقالة.
* نشر النموذج على وحدة معالجة الرسوميات وتعيينه عدد العمال = 1، حجم الدفعة = 1، تم زيادة الإنتاجية بمقدار 12 مرة وتم تقليل زمن الوصول بمقدار 13 مرة مقارنةً بوحدة المعالجة المركزية.
* نشر النموذج على وحدة معالجة الرسوميات وتعيينه نموذج.نصف()، عدد العمال = 1 ، حجم الدفعة = 8، يمكن تحقيق أفضل النتائج من حيث الإنتاجية والزمن المحتمل. وبالمقارنة مع وحدة المعالجة المركزية، زاد الإنتاج بمقدار 25 مرة، وظل زمن الوصول متوافقًا مع متطلبات اتفاقية مستوى الخدمة (94.4 مللي ثانية).
ملاحظة: إذا كنت تقوم بتشغيل مجموعة معايير، فتأكد من تعيين الإعدادات المناسبة تأخير الدفعة، يقوم بتعيين تزامن الطلبات إلى رقم متناسب مع حجم الدفعة. يشير التزامن هنا إلى عدد الطلبات المتزامنة المرسلة إلى الخادم.
تلخيص
تقدم هذه المقالة الاعتبارات الخاصة بضبط نموذج TorchServe في بيئة الإنتاج ومجموعة معايير TorchServe لتحسين الأداء، مما يمنح المستخدمين فهمًا أعمق للاختيارات الممكنة لتحسين النموذج واختيار الأجهزة والتكلفة الإجمالية.
قم بالتركيز على مجتمع مطوري PyTorchالحساب الرسمي للحصول على المزيد من تحديثات تقنية PyTorch وأفضل الممارسات والمعلومات ذات الصلة!








