Command Palette
Search for a command to run...
تم إصدار PyTorch 2.0: قم بالتجميع، والتجميع، والتجميع!

نظرة عامة على المحتوى: في مؤتمر PyTorch 2022 الذي عقد الليلة الماضية، تم إصدار PyTorch 2.0 رسميًا. ستقوم هذه المقالة بتوضيح أكبر الاختلافات بين PyTorch 2.0 و 1.x. الكلمات الرئيسية: PyTorch 2.0 Compiler Machine Learning تم نشر هذه المقالة لأول مرة على WeChat الحساب الرسمي: HypeAI
في مؤتمر PyTorch 2022، أصدرت PyTorch رسميًا PyTorch 2.0. كان معدل "التجميع" للحدث بأكمله مرتفعًا جدًا. بالمقارنة مع الإصدار السابق 1.x، خضع الإصدار 2.0 لتغييرات "مزعجة".
أصدرت PyTorch 2.0 الكثير من الميزات الجديدة الكافية لتغيير الطريقة التي تستخدم بها PyTorch.إنه يوفر نفس الوضع المتحمس وتجربة المستخدم، مع إضافة وضع التجميع من خلال torch.compile.يمكن تسريع النموذج أثناء التدريب والاستدلال، مما يوفر أداءً أفضل ودعمًا للأشكال الديناميكية والموزعة.
ستوفر هذه المقالة مقدمة مفصلة حول PyTorch 2.0.
طويل جدًا للقراءة
- يحتفظ PyTorch 2.0 بمزاياه الأصلية مع دعم التجميع بشكل كبير
- torch.compile هي وظيفة اختيارية يمكنها تشغيل التجميع باستخدام سطر واحد فقط من التعليمات البرمجية
- 4 تقنيات مهمة: TorchDynamo وAOTAutograd وPrimTorch وTorchInductor
- لقد حاولت تجميعه منذ 5 سنوات، لكن النتائج لم تكن مرضية.
- لا يلزم ترحيل كود PyTorch 1.x إلى 2.0* ومن المتوقع إصدار إصدار PyTorch 2.0 المستقر في مارس من العام المقبل
دعم أسرع وأفضل ومجمع
في مؤتمر PyTorch 2022 الذي أقيم الليلة الماضية،تم إطلاق torch.compile رسميًا.كما أنه يعمل على تحسين أداء PyTorch ويبدأ في نقل أجزاء من PyTorch مرة أخرى من C++ إلى Python.
تتضمن أحدث التقنيات في PyTorch 2.0 ما يلي:
TorchDynamo، وAOTAutograd، وPrimTorch، وTorchInductor.
1. تورش دينامو
يمكنك الحصول على برامج PyTorch بأمان بمساعدة Python Frame Assessment Hooks. يعد هذا الابتكار الرئيسي ملخصًا لنتائج البحث والتطوير التي قامت بها PyTorch في مجال التقاط الرسوم البيانية بشكل آمن على مدار السنوات الخمس الماضية.
2. AOTAutograd
قم بتحميل محرك PyTorch autograd باعتباره تتبعًا تلقائيًا لإنشاء تتبعات خلفية متقدمة.
3. بريم تورش
يتم تلخيص أكثر من 2000 مشغل PyTorch في مجموعة مغلقة مكونة من حوالي 250 مشغل بدائي، ويمكن للمطورين إنشاء واجهة خلفية PyTorch كاملة لهذه المشغلات. يقوم PrimTorch بتبسيط عملية كتابة وظائف PyTorch أو الواجهة الخلفية بشكل كبير.
4. محث الشعلة مُجمِّع تعلُّم عميق يُولِّد كودًا سريعًا للعديد من المُسرِّعات والواجهات الخلفية. بالنسبة لوحدات معالجة الرسومات NVIDIA، فإنها تستخدم OpenAI Triton ككتلة بناء أساسية.
تمت كتابة TorchDynamo وAOTAutograd وPrimTorch وTorchInductor بلغة Python.كما أن دعم الشكل الديناميكي (القدرة على إرسال متجهات بأحجام مختلفة دون إعادة التجميع) يجعلها مرنة وسهلة التعلم، مما يخفض حاجز الدخول للمطورين والبائعين.
للتحقق من صحة هذه التقنيات،يستخدم PyTorch رسميًا 163 نموذجًا مفتوح المصدر في مجال التعلم الآلي.وتشمل هذه المهام مثل تصنيف الصور، واكتشاف الكائنات، وتوليد الصور، ومهام معالجة اللغة الطبيعية المختلفة مثل نمذجة اللغة، والإجابة على الأسئلة، وتصنيف التسلسل، وأنظمة التوصية، والتعلم التعزيزي.وتنقسم هذه المعايير إلى ثلاث فئات:
- 46 نموذجًا من HuggingFace Transformers
- 61 نموذجًا من TIMM: مجموعة نماذج صور SoTA PyTorch من تأليف Ross Wightman
- 56 نماذج من TorchBench: مجموعة من المستودعات الشهيرة على GitHub.
بالنسبة للنماذج مفتوحة المصدر،لم يقم PyTorch بإجراء أي تغييرات رسميًا، ولكنه أضاف استدعاء torch.compile للتغليف.
بعد ذلك، قام مهندسو PyTorch بقياس السرعة والتحقق من الدقة في هذه النماذج، نظرًا لأن عمليات التسريع قد تعتمد على نوع البيانات.لذلك، تم قياس التسريع الرسمي على كل من float32 والدقة المختلطة التلقائية (AMP).نظرًا لأن AMP أكثر شيوعًا في الممارسة العملية، يتم ضبط نسبة الاختبار على: 0.75 * AMP + 0.25 * float32.
ومن بين هذه النماذج مفتوحة المصدر البالغ عددها 163،يمكن تشغيل torch.compile بشكل طبيعي على الطراز 93%.بعد التشغيل، حقق النموذج تحسنًا قدره 43% في سرعة التشغيل على وحدة معالجة الرسوميات NVIDIA A100. في ظل دقة Float32، يتم زيادة سرعة التشغيل بمعدل 21%؛ تحت دقة AMP، يتم زيادة سرعة التشغيل بمعدل 51%.
ملاحظة: في وحدات معالجة الرسومات من فئة سطح المكتب (مثل NVIDIA 3090)، ستكون السرعات المقاسة أقل من تلك الموجودة في وحدات معالجة الرسومات من فئة الخادم (مثل A100). اعتبارًا من الآن، يدعم البرنامج الخلفي الافتراضي TorchInductor من PyTorch 2.0 بالفعل وحدة المعالجة المركزية ووحدات معالجة الرسومات NVIDIA Volta وAmpere، ولكنه لا يدعم حاليًا وحدات معالجة الرسومات الأخرى أو وحدات xPU أو وحدات معالجة الرسومات NVIDIA الأقدم.
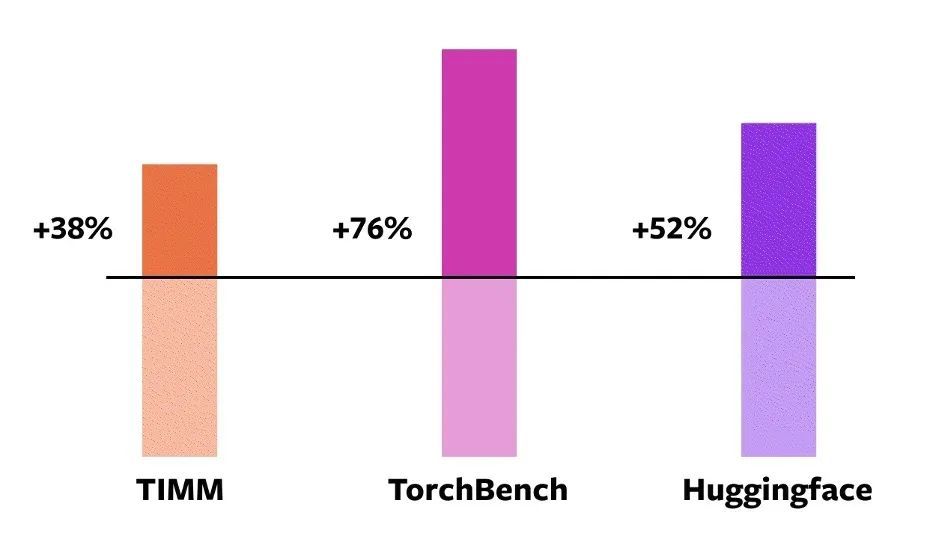 تسريع وضع الحماس لبطاقة معالجة الرسومات NVIDIA A100 لطرازات مختلفة
تسريع وضع الحماس لبطاقة معالجة الرسومات NVIDIA A100 لطرازات مختلفة
جرب torch.compile عبر الإنترنت:يمكن للمطورين تثبيته وتجربته من خلال الملف الثنائي الليلي. من المتوقع إصدار إصدار PyTorch 2.0 Stable في أوائل مارس 2023.
في خارطة طريق PyTorch 2.x، سيتم الاستمرار في إثراء وتحسين أداء وقابلية التوسع في الوضع المترجم في المستقبل.
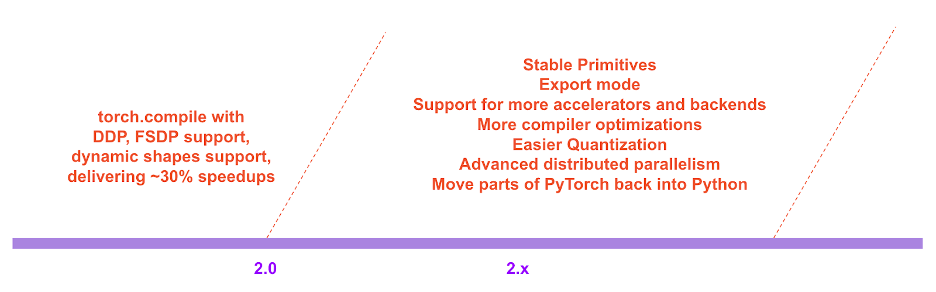 خريطة طريق PyTorch 2.x
خريطة طريق PyTorch 2.x
خلفية التطوير
لقد كانت فلسفة تطوير PyTorch دائمًا هي وضع المرونة والقدرة على الاختراق في المقام الأول، والأداء في المقام الثاني.ملتزم بِ:
1. تنفيذ عالي الأداء
2. قم بتعديل البنية الداخلية بشكل مستمر
3. تجريد جيد للبيانات الموزعة، والتباين التلقائي، وتحميل البيانات، والمعجلات، وما إلى ذلك.
منذ تقديم PyTorch في عام 2017، عملت مسرعات الأجهزة (مثل وحدات معالجة الرسومات) على زيادة سرعة الحوسبة بنحو 15 مرة وسرعة الوصول إلى الذاكرة بنحو مرتين.
من أجل الحفاظ على الأداء العالي والتنفيذ السريع، كان لا بد من نقل معظم المحتوى الداخلي لـ PyTorch إلى C++، مما قلل من قابلية اختراق PyTorch وزاد من الحد الأقصى للمطورين للمشاركة في مساهمات الكود.
منذ اليوم الأول، كان مسؤولو PyTorch على دراية بالقيود المفروضة على الأداء بسبب التنفيذ السريع. في يوليو 2017، بدأ المسؤولون العمل على تطوير مُجمِّع لـ PyTorch. يحتاج المترجم إلى تسريع تشغيل برامج PyTorch دون التضحية بتجربة PyTorch.كان المعيار الرئيسي هو الحفاظ على درجة معينة من المرونة: دعم الأشكال الديناميكية والبرامج الديناميكية، والتي يستخدمها المطورون على نطاق واسع.

التفاصيل الفنية لـ PyTorch
منذ إطلاقه، تم بناء العديد من مشاريع التجميع في PyTorch.يمكن تقسيم هذه المترجمات إلى 3 فئات:
- اكتساب الرسم البياني
- خفض الرسم البياني
- تجميع الرسم البياني
ومن بين هذه التحديات، يواجه اكتساب بنية الرسم البياني أكبر التحديات.
خلال السنوات الخمس الماضية، جربنا torch.jit.trace، وTorchScript، وFX tracing وLazy Tensors، ولكن بعضها مرن ولكن ليس سريعًا بما يكفي، وبعضها سريع بما يكفي ولكن ليس مرنًا، وبعضها ليس سريعًا ولا مرنًا، وبعضها لديه تجربة مستخدم سيئة.
على الرغم من أن TorchScript واعد،لكن هذا يتطلب الكثير من التعديلات في الكود والتبعيات، وهو ليس ممكنًا جدًا.
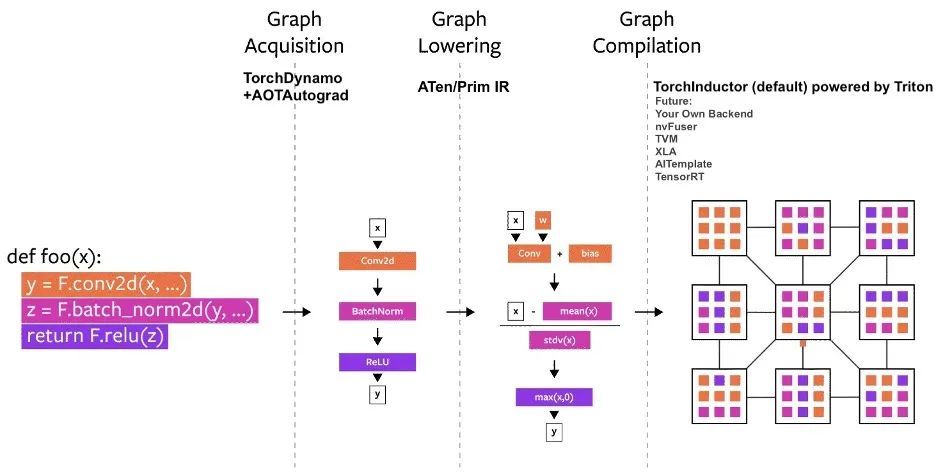 مخطط عملية تجميع PyTorch
مخطط عملية تجميع PyTorch
TorchDynamo: الحصول على بنية الرسم البياني بشكل موثوق وسريع
يستخدم TorchDynamo ميزة CPython المقدمة في PEP-0523 والتي تسمى واجهة برمجة تطبيقات تقييم الإطار. وقد اعتمد المسؤول على نهج قائم على البيانات للتحقق من فعاليته في Graph Capture، باستخدام أكثر من 7000 مشروع على Github مكتوبة في PyTorch كمجموعة للتحقق.
تظهر التجارب أنيمكن لبرنامج TorchDynamo الحصول على بنية الرسم البياني بشكل صحيح وآمن في وقت 99%، كما أن التكلفة غير ذات أهمية.لأنه لا يتطلب أي تعديل على الكود الأصلي.
TorchInductor: مُولِّد كود أسرع مع الأشعة تحت الحمراء المحددة حسب التشغيل
يكتب عدد متزايد من المطورين أنوية مخصصة عالية الأداء.يمكن استخدام لغة تريتون.بالإضافة إلى ذلك، بالنسبة لواجهة المترجم الجديدة لـ PyTorch 2.0، يأمل المسؤول أيضًا في استخدام تجريدات مماثلة لـ PyTorch eager، والحصول على أداء عام كافٍ لدعم مجموعة واسعة من الوظائف في PyTorch.
يستخدم TorchInductor مستوى حلقة التعريف حسب التشغيل في Pythonic IR لتعيين نماذج PyTorch تلقائيًا إلى كود Triton الناتج على وحدة معالجة الرسومات وC++/OpenMP على وحدة المعالجة المركزية.
يحتوي مستوى الحلقة الأساسية IR لـ TorchInductor على حوالي 50 مشغلًا فقط ويتم تنفيذه في Python، مما يجعله قابلاً للاختراق والتوسع بدرجة كبيرة.
AOTAutograd: إعادة استخدام Autograd للرسوم البيانية المسبقة
لتسريع التدريب، لا يلتقط PyTorch 2.0 الكود على مستوى المستخدم فحسب، بل يلتقط أيضًا خوارزمية الانتشار الخلفي. سيكون الأمر أفضل إذا تم استخدام نظام PyTorch autograd المجرب.
يستخدم AOTAutograd آلية تمديد PyTorch torch_dispatch لتتبع محرك Autograd.يتيح للمطورين التقاط التمريرة الخلفية "قبل الوقت المحدد"، مما يسمح للمطورين باستخدام TorchInductor لتسريع التمريرة الأمامية والخلفية.
PrimTorch: مشغلات بدائية مستقرة
كتابة الواجهة الخلفية لـ PyTorch ليس بالأمر السهل. يحتوي Torch على أكثر من 1200 مشغل، وإذا أخذت في الاعتبار الأحمال الزائدة المختلفة لكل مشغل، فإن الرقم يصل إلى 2000+.
 نظرة عامة على تصنيف أكثر من 2000 مشغل PyTorch
نظرة عامة على تصنيف أكثر من 2000 مشغل PyTorch
لذلك، تصبح كتابة الميزات الخلفية أو المتقاطعة مهمة تستغرق وقتًا طويلاً. تسعى PrimTorch إلى تحديد مجموعة أصغر وأكثر استقرارًا من المشغلين. من الممكن خفض برامج PyTorch باستمرار إلى هذه المجموعات من المشغلين. الهدف الرسمي هو تحديد مجموعتين من المشغلين:
* تحتوي Prim ops على حوالي 250 مشغلًا منخفض المستوى نسبيًا. نظرًا لأنها منخفضة المستوى بدرجة كافية، فإن هذه المشغلات أكثر ملاءمة للمترجمين. يحتاج المطورون إلى دمج هذه المشغلات لتحقيق أداء جيد.
* تحتوي ATen ops على حوالي 750 مشغلًا أساسيًا مناسبًا للإخراج المباشر. تعتبر هذه المشغلات مناسبة للبرامج الخلفية التي تم دمجها على مستوى ATen، أو للبرامج الخلفية التي لم يتم تجميعها لاستعادة الأداء من مجموعة المشغلات الأساسية (مثل عمليات Prim).
التعليمات
1. كيفية تثبيت PyTorch 2.0؟ ما هي المتطلبات الإضافية؟
قم بتثبيت أحدث الإصدارات الليلية:
كودا 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117كودا 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116وحدة المعالجة المركزية
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu2. هل كود PyTorch 2.0 متوافق مع الإصدار 1.x؟
نعم، لا يتطلب الإصدار 2.0 تعديل سير عمل PyTorch، فقط سطر واحد من التعليمات البرمجية النموذج = torch.compile(النموذج)يمكنك بعد ذلك تحسين النموذج الخاص بك لاستخدام مجموعة 2.0 وتشغيلها بسلاسة مع كود PyTorch الآخر. هذا الخيار ليس إلزاميًا ويمكن للمطورين الاستمرار في استخدام الإصدارات السابقة.
3. هل تم تمكين PyTorch 2.0 افتراضيًا؟
لا، يجب تمكين الإصدار 2.0 صراحةً في كود PyTorch الخاص بك عن طريق تحسين النموذج باستخدام استدعاء وظيفة واحدة.
4. كيفية ترحيل كود PT1.X إلى PT2.0؟
الكود السابق لا يتطلب أي هجرة. إذا كنت تريد استخدام ميزة الوضع المترجم الجديدة المقدمة في الإصدار 2.0، فيمكنك أولاً تحسين النموذج بسطر واحد من التعليمات البرمجية:النموذج = torch.compile(النموذج).
ينعكس تحسن السرعة بشكل رئيسي في عملية التدريب. إذا كان النموذج يعمل بشكل أسرع من الوضع المتلهف، فهذا يعني أنه يمكن استخدامه للاستدلال.
import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(\*\*input)5. ما هي الميزات التي تم إيقافها في PyTorch 2.0؟
حاليًا، PyTorch 2.0 ليس مستقرًا بعد ولا يزال في إصدار nightlies. لا يزال دعم الأشكال الديناميكية في torch.compile في مراحله المبكرة ولا يُنصح به حتى إصدار 2.0 المستقر في مارس 2023.
وهذا يعني أنه حتى بالنسبة لأحمال العمل ذات الشكل الثابت، فهي لا تزال مدمجة في الوضع المجمّع وقد تحدث بعض الأخطاء. بالنسبة للجزء من الكود الخاص بك الذي يتعطل، يرجى تعطيل الوضع المترجم وتقديم تقرير عن المشكلة.
إرسال المشكلة إلى البوابة:https://github.com/pytorch/pytorch/issues
ما ورد أعلاه هو مقدمة مفصلة لـ PyTorch 2.0. سوف نستكمل مقدمة البدء في PyTorch 2.0 في المستقبل. من فضلك تابعنا!
يمكنك أيضًا البحث عن Hyperai01 على WeChat والانضمام إلى مناقشة مجموعة تطوير تقنية PyTorch مع Neural Star.








