Command Palette
Search for a command to run...
تعليمات استخدام TorchMultimodal الجديدة لمكتبة PyTorch: توسيع النموذج العام متعدد الوسائط FLAVA إلى 10 مليارات معلمة

في المقالة السابقة، قدمنا TorchMultimodal. اليوم، سنبدأ بحالة محددة لإظهار كيفية توسيع النموذج الأساسي متعدد الوسائط في مكتبة TorchMultimodal بدعم من تقنية Torch Distributed.
في السنوات الأخيرة، أصبحت النماذج الكبيرة مجالًا بحثيًا يجذب الكثير من الاهتمام. إذا أخذنا معالجة اللغة الطبيعية كمثال، فقد تطورت نماذج اللغة من مئات الملايين من المعلمات (BERT) إلى مئات المليارات من المعلمات (GPT-3)، مما لعب دورًا مهمًا في تحسين أداء المهام اللاحقة.
لقد تم إجراء أبحاث واسعة النطاق في الصناعة حول كيفية توسيع نطاق نماذج اللغة واسعة النطاق. يمكن ملاحظة اتجاه مماثل في مجال الرؤية، مع تحول المزيد والمزيد من المطورين إلى النماذج القائمة على المحولات (مثل Vision Transformer وMasked Auto Encoders).
من الواضح أنه بفضل تطوير النماذج واسعة النطاق، تم تحسين البحث على نموذج واحد (مثل النص والصورة والفيديو) بشكل مستمر، كما تم تكييف الأطر بسرعة مع النماذج الأكبر.
وفي الوقت نفسه، ومع التطبيقات الواقعية لمهام مثل استرجاع الصور والنصوص، والإجابة على الأسئلة البصرية، والحوار البصري، وتوليد النص إلى صورة، حظيت التعددية الوسائطية باهتمام متزايد.
والخطوة التالية هي تدريب نماذج متعددة الوسائط واسعة النطاق. وكانت هناك أيضًا بعض الجهود في هذا المجال، مثل CLIP من OpenAI، وParti من Google، وCM3 من Meta.
ستوضح هذه المقالة كيفية توسيع نطاق FLAVA إلى 10 مليارات معلمة باستخدام تقنية PyTorch Distributed من خلال دراسة حالة.
قراءة إضافية:HyperAI: نظرة على أدوات FX المستخدمة بواسطة Meta: تحسين نماذج PyTorch باستخدام تحويل الرسم البياني
يحرر
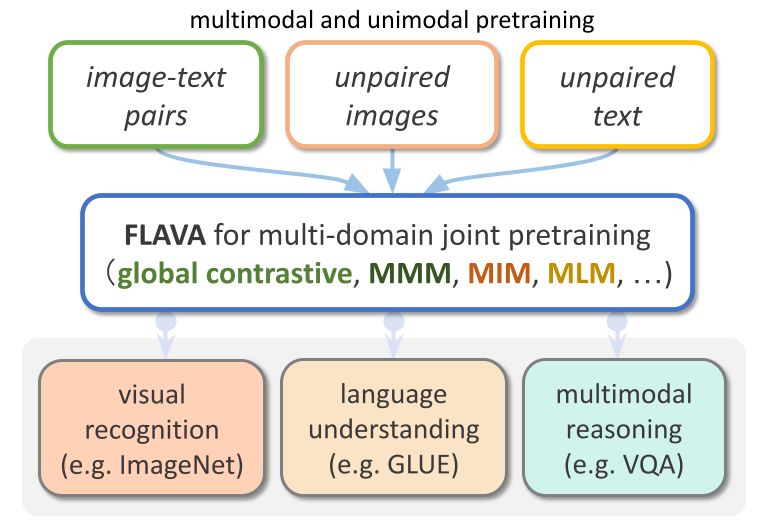
FLAVA هو نموذج قائم على الرؤية واللغة متاح في TorchMultimodal
لقد أظهرت FLAVA مزايا أداء متميزة في كل من معايير النموذج الفردي والنموذج المتعدد. ستوضح هذه المقالة كيفية توسيع FLAVA باستخدام أمثلة التعليمات البرمجية ذات الصلة.
انظر الكود للحصول على التفاصيل:
multimodal/examples/flava/native at main · facebookresearch/multimodal · GitHub
نظرة عامة على توسيع نطاق FLAVA
FLAVA هو نموذج متعدد الوسائط أساسي يتكون من مشفرات الصور والنصوص المستندة إلى المحول ووحدة اندماج متعددة الوسائط المستندة إلى المحول.
تم تدريب FLAVA مسبقًا على البيانات أحادية الوسائط ومتعددة الوسائط مع خسائر مختلفة، بما في ذلك خسائر اللغة المقنعة والصورة والنموذج متعدد الوسائط التي تتطلب من النموذج إعادة بناء المدخلات الأصلية من سياقها (التعلم الذاتي الإشراف).
بالإضافة إلى ذلك، فإنه يستخدم فقدان مطابقة نص الصورة، بما في ذلك الأمثلة الإيجابية والسلبية لأزواج النص والصورة المتوافقة، وخسارة التباين على غرار CLIP.
بالإضافة إلى المهام المتعددة الوسائط (مثل استرجاع الصور والنصوص)، يظهر FLAVA أيضًا أداءً ممتازًا في معايير أحادية الوسائط (مثل مهام GLUE في معالجة اللغة الطبيعية وتصنيف الصور المرئية).
يحرر
كان نموذج FLAVA الأصلي يحتوي على حوالي 350 مليون معلمة واستخدم تكوين ViT-B16 لكل من أجهزة ترميز الصور والنصوص.
مرجع:https://arxiv.org/pdf/2010.11929.pdf
يستخدم محول الاندماج المتعدد الوسائط نفس المشفر أحادي النمط، ولكن عدد الطبقات هو نصف العدد السابق فقط. كان فريق تطوير PyTorch يستكشف زيادة حجم المبرمج لاستيعاب متغيرات ViT الأكبر حجمًا.
هناك جانب آخر لتوسيع نطاق FLAVA وهو زيادة حجم الدفعة. يستغل FLAVA بذكاء الخسارة التباينية السلبية داخل الدفعة، والتي عادةً ما تكون متاحة فقط في عدد كبير من الأحجام.
مرجع:https://openreview.net/pdfid=U2exBrf_SJh
بشكل عام، يتم تحقيق أقصى قدر من كفاءة التدريب أو معدل الإنتاج عند التشغيل بالقرب من أكبر حجم دفعة ممكن، والذي يتم تحديده من خلال مقدار ذاكرة وحدة معالجة الرسومات المتوفرة (راجع قسم التجارب).
يوضح الجدول التالي مخرجات تكوينات النماذج المختلفة، حيث حددنا تجريبياً الحد الأقصى لحجم الدفعة الذي يمكن أن يتناسب مع الذاكرة لكل تكوين.

يحرر
نظرة عامة على التحسين
يوفر PyTorch العديد من التقنيات الأصلية لتوسيع نطاق النماذج بكفاءة. تتناول الأقسام التالية الطرق الثلاثة بالتفصيل وتوضح كيفية تطبيق هذه التقنيات لتوسيع نطاق نموذج FLAVA إلى 10 مليارات معلمة.
التوازي في البيانات الموزعة
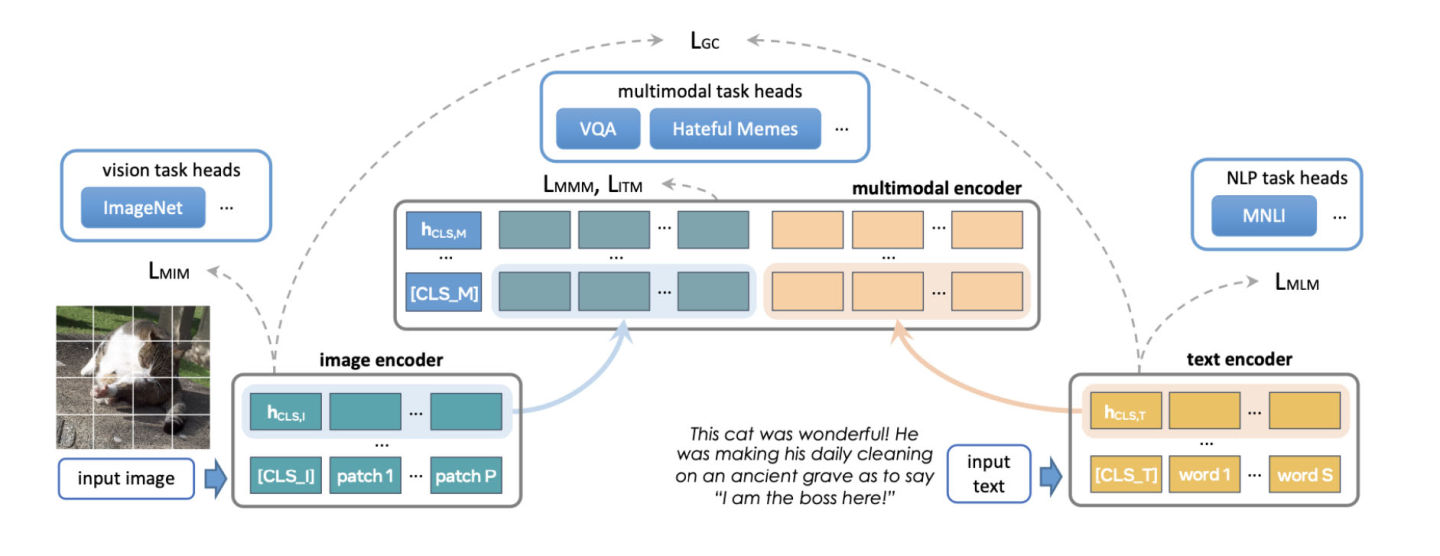
نقطة البداية الشائعة للتدريب الموزع هي التوازي في البيانات. تقوم عملية التوازي في البيانات بتكرار النموذج بين وحدات معالجة الرسوميات وتقسيم مجموعة البيانات. تعمل وحدات معالجة الرسومات المختلفة على معالجة أقسام بيانات مختلفة بالتوازي ومزامنة تدرجاتها (عبر كل التخفيضات) قبل تحديث أوزان النموذج.
يوضح الشكل التالي عملية معالجة البيانات بالتوازي (التكرار الأمامي، والتكرار الخلفي، وخطوة تحديث الوزن):

يحرر
لتحقيق التوازي في البيانات، توفر PyTorch واجهة برمجة تطبيقات أصلية، DistributedDataParallel (DDP)، والتي يمكن استخدامها كغلاف للوحدات النمطية كما هو موضح أدناه:
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])التوازي الكامل للبيانات المجزأة
يمكن تقسيم استخدام ذاكرة وحدة معالجة الرسوميات لتطبيق التدريب تقريبًا إلى إدخال النموذج، وتخزين التنشيط الوسيط (اللازم لحسابات التدرج)، ومعلمات النموذج، والتدرجات، وحالة المُحسِّن.
عند توسيع نموذج، عادةً ما تتم إضافة هذه العناصر معًا. عندما تنفد ذاكرة وحدة معالجة الرسوميات (GPU) واحدة، فإن توسيع النموذج باستخدام DDP قد يؤدي إلى نفاد الذاكرة لأنه يكرر المعلمات والتدرجات وحالات المحسن عبر جميع وحدات معالجة الرسوميات.
لتقليل هذا النسخ وتوفير ذاكرة وحدة معالجة الرسومات، يمكن تجزئة معلمات النموذج والتدرجات وحالة المحسن إلى جميع وحدات معالجة الرسومات، مع قيام كل وحدة معالجة رسومات بإدارة جزء واحد فقط. تشير هذه الطريقة إلى ZeRO-3 المقترحة من قبل Microsoft.
يتوفر تنفيذ أصلي لـ PyTorch لهذا النهج كواجهة برمجة تطبيقات FullyShardedDataParallel (FSDP)، والتي تم إصدارها كميزة تجريبية في PyTorch 1.12.
أثناء التكرارات الأمامية والخلفية للوحدة، يقوم FSDP بدمج معلمات النموذج (باستخدام التجميع الكامل) وفقًا للاحتياجات الحسابية وإعادة تقسيمها بعد الحساب. إنه يستخدم مجموعة التشتت والاختزال لمزامنة التدرجات لضمان الحصول على متوسط تدرجات الشظايا عالميًا. عمليات التكرار الأمامي والعكسي للنموذج في FSDP هي كما يلي:

يحرر
عند استخدام FSDP، تحتاج إلى تغليف الوحدات الفرعية للنموذج باستخدام واجهة برمجة التطبيقات للتحكم في وقت تجزئة وحدة فرعية معينة أم لا. يوفر FSDP واجهة برمجة تطبيقات جاهزة للتغليف التلقائي، والعديد من سياسات التغليف، والقدرة على كتابة السياسات.
يوضح المثال التالي كيفية تغليف نموذج FLAVA باستخدام FSDP. حدد سياسة التغليف التلقائي: transformer_auto_wrap_policy . سيؤدي هذا إلى تغليف طبقة محول واحدة (TransformerEncoderLayer)، ومحول صورة (ImageTransformer)، ومشفر نص (BERTTextEncoder)، ومشفر متعدد الوسائط (FLAVATransformerWithoutEmbeddings) في وحدة FSDP واحدة.
يستخدم هذا نهج التغليف المتكرر لإدارة الذاكرة بكفاءة. على سبيل المثال، بعد اكتمال التكرار الأمامي أو الخلفي لطبقة المحول الواحدة، يتم حذف المعلمات، مما يؤدي إلى تحرير الذاكرة وتقليل استخدام الذاكرة القصوى.
يوفر FSDP أيضًا بعض الخيارات القابلة للتكوين لضبط أداء التطبيق، مثل استخدام limit_all_gathers في هذا المثال. إنه يمنع التجميع المبكر لجميع معلمات النموذج ويقلل من ضغط الذاكرة على التطبيق.
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)نقطة تفتيش التنشيط
كما ذكر أعلاه، تؤثر مساحة تخزين التنشيط الوسيطة ومعلمات النموذج والتدرجات وحالة المُحسِّن على استخدام ذاكرة وحدة معالجة الرسومات. يمكن لـ FSDP تقليل استهلاك الذاكرة الناتج عن الثلاثة الأخيرة، لكنه لا يستطيع تقليل الذاكرة المستهلكة عن طريق التنشيط. تزداد الذاكرة المستخدمة بواسطة عمليات التنشيط مع حجم الدفعة أو عدد الطبقات المخفية.
تعمل نقطة تفتيش التنشيط على تقليل استخدام الذاكرة عن طريق إعادة حساب عمليات التنشيط أثناء التكرارات العكسية بدلاً من الاحتفاظ بها في الذاكرة في وحدة نقطة التفتيش المحددة.
على سبيل المثال، من خلال تطبيق نقاط تفتيش التنشيط على نموذج 2.7 مليار معلمة، تم تقليل ذروة الذاكرة النشطة بعد التكرار الأمامي بعامل 4.
يوفر PyTorch واجهة برمجة تطبيقات نقطة تفتيش التنشيط المستندة إلى الغلاف. ويتيح لك checkpoint_wrapper للمستخدمين تغليف وحدة واحدة باستخدام check، ويتيح لك apply_activation_checkpointing للمستخدمين تحديد استراتيجية لتغليف الوحدة باستخدام نقاط التفتيش في الوحدة بأكملها.
يمكن تطبيق هاتين الواجهتين البرمجيتين على معظم النماذج لأنهما لا تتطلبان أي تغييرات في كود تعريف النموذج.
ومع ذلك، إذا كنت بحاجة إلى تحكم أكثر دقة في أجزاء نقاط التفتيش، مثل نقاط تفتيش وظيفة محددة داخل وحدة نمطية، فيمكنك استخدام واجهة برمجة التطبيقات torch.utils.checkpoint، والتي تتطلب تعديل كود النموذج.
يظهر أدناه تطبيق غلاف نقطة تفتيش التنشيط على طبقة محول FLAVA واحدة (المشار إليها بواسطة TransformerEncoderLayer):
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
كما هو موضح أعلاه، فإن تغليف طبقة محول FLAVA باستخدام نقطة تفتيش التنشيط والنموذج الشامل باستخدام FSDP يسمح بتوسيع نطاق FLAVA إلى 10 مليارات معلمة.
تجربة
بالنسبة لطرق التحسين المختلفة المذكورة أعلاه، سنقوم بإجراء المزيد من التجارب لمعرفة تأثيرها على أداء النظام.
خلفية:
- استخدام عقدة واحدة مع 8 وحدات معالجة رسومية A100 سعة 40 جيجابايت
- قم بتشغيل 1000 تكرار تدريب مسبق
- تدريب الدقة المختلطة في PyTorch باستخدام نوع البيانات bfloat16 (دقة مختلطة تلقائية)
- تمكين تنسيق TensorFloat32 لتحسين أداء matmul على A100
- تعريف الإنتاجية على أنها متوسط عدد العناصر التي تتم معالجتها في الثانية (تجاهل أول 100 تكرار عند قياس الإنتاجية)
- إن تقارب التدريب وتأثيره على مؤشرات المهام اللاحقة سيكون بمثابة اتجاه جديد للأبحاث المستقبلية
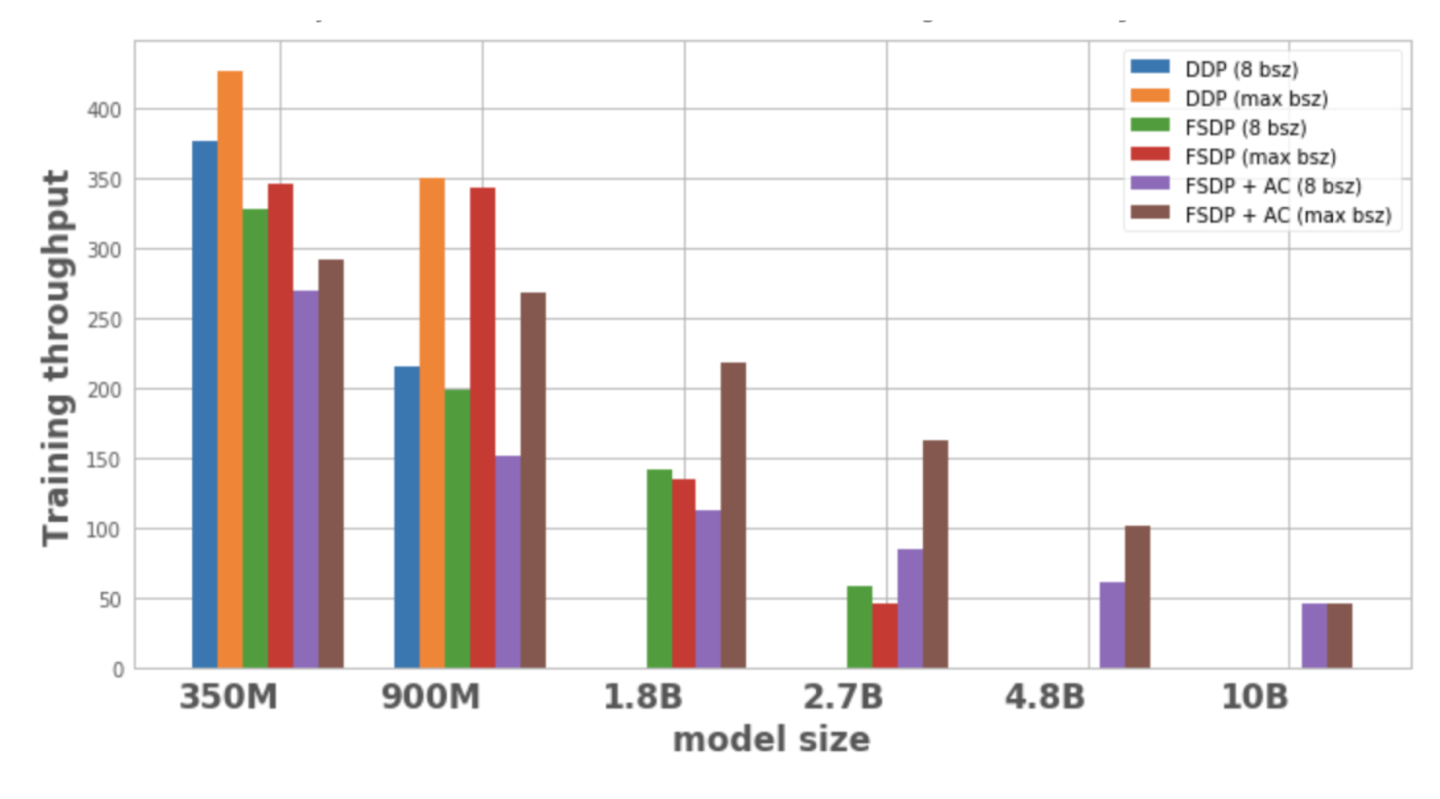
يوضح الشكل 1 معدل الإنتاج لكل تكوين نموذجي وتحسينه، مع حجم دفعة محلي يبلغ 8، وهو الحد الأقصى لحجم الدفعة الممكن على عقدة واحدة. لا يحتوي متغير النموذج المحسن على نقاط بيانات، مما يشير إلى أنه لا يمكن تدريب النموذج على عقدة واحدة.
يحرر
الشكل 1: معدل إنتاج التدريب في ظل تكوينات مختلفة
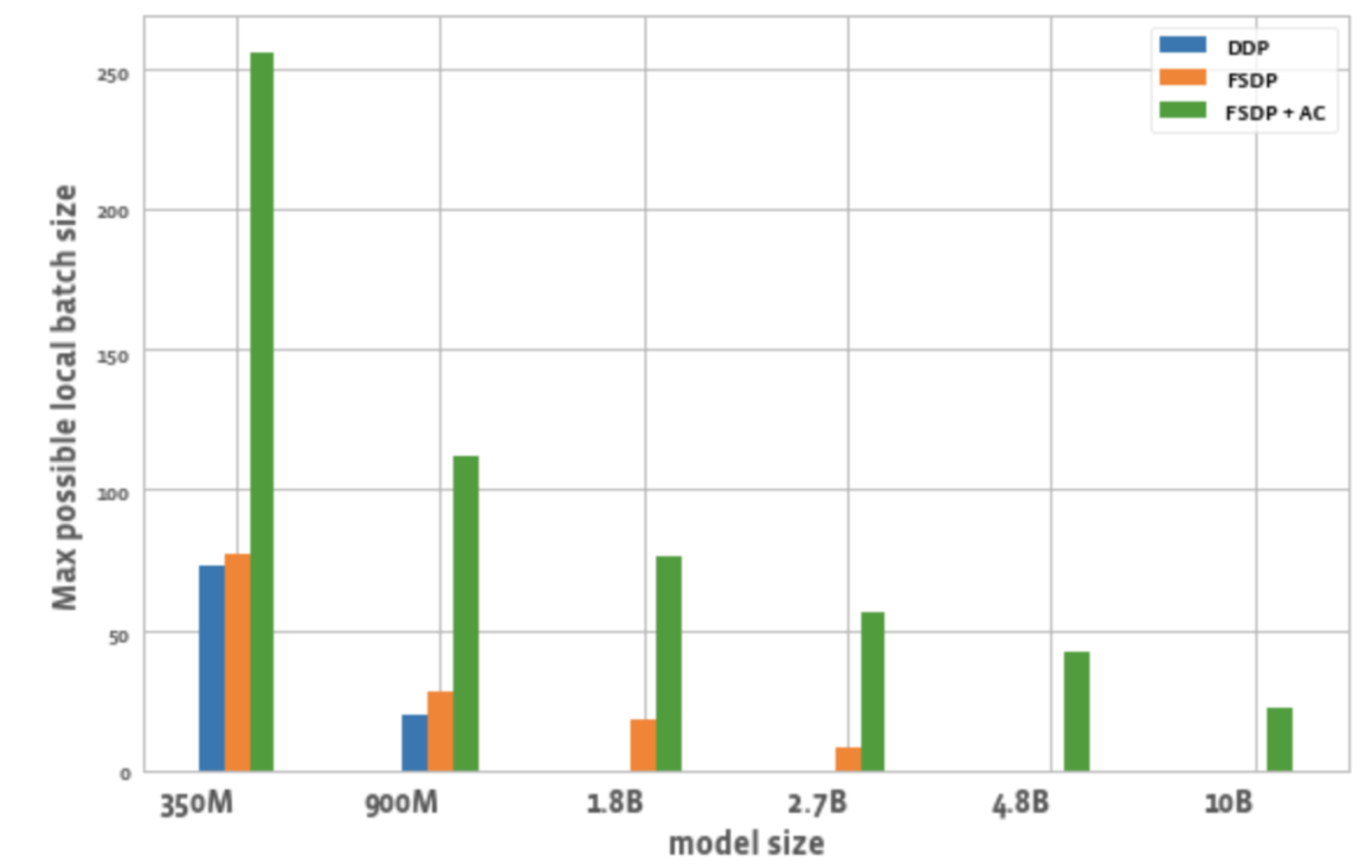
يوضح الشكل 2 الحد الأقصى لحجم الدفعة الممكن لجميع وحدات معالجة الرسوميات في كل عملية تحسين.
يحرر
الشكل 2: الحد الأقصى لحجم الدفعة المحلية الممكنة في ظل تكوينات مختلفة
ومن هنا يمكننا أن نلاحظ:
1. توسيع حجم النموذج:
يمكن لـ DDP استيعاب نماذج 350M و900M فقط على عقدة واحدة. يؤدي استخدام FSDP إلى توفير الذاكرة، لذا من الممكن تدريب نماذج أكبر بثلاث مرات من DDP (أي 1.8B و2.7B المتغيرات). يتيح الجمع بين نقطة تفتيش التنشيط (AC) مع FSDP تدريب نماذج أكبر، أكبر بحوالي 10 مرات من DDP (مثل المتغيرات 4.8B و10B).
2. الإنتاجية:
- بالنسبة للنماذج الأصغر، عندما يكون حجم الدفعة 8، يكون معدل إنتاج DDP أعلى قليلاً من أو يساوي معدل إنتاج FSDP، والذي يمكن تفسيره من خلال الاتصالات الإضافية المطلوبة بواسطة FSDP. إن الجمع بين FSDP و AC له أدنى معدل إنتاجية. يرجع السبب في ذلك إلى أن AC يعيد تشغيل قناة التكرار الأمامي التي تم فحصها أثناء عملية التكرار العكسي، مما يؤدي إلى التضحية بالحسابات الإضافية لتوفير الذاكرة. ومع ذلك، بالنسبة لنموذج 2.7B، فإن FSDP + AC يتمتع في الواقع بإنتاجية أعلى مقارنة بـ FSDP وحده. يرجع السبب في ذلك إلى أن نموذج 2.7B مع FSDP قريب من حد الذاكرة حتى عند حجم دفعة يبلغ 8، مما يؤدي إلى إعادة محاولة malloc CUDA، مما يؤدي إلى إبطاء التدريب. يساعد التيار المتردد على تقليل ضغط الذاكرة الذي لا يسبب إعادة المحاولة.
- بالنسبة لـ DDP و FSDP + AC، يزداد إنتاج النموذج مع زيادة حجم الدفعة. والشيء نفسه ينطبق على الإصدارات الأصغر من FSDP. ومع ذلك، بالنسبة لنماذج المعلمات 1.8B و2.7B، ينخفض الإنتاج عند زيادة حجم الدفعة. أحد الأسباب المحتملة هو أنه عند حدود الذاكرة، قد يتعين على إدارة ذاكرة CUDA الخاصة بـ PyTorch إعادة محاولة استدعاءات cudaMalloc أو تشغيل إلغاء التجزئة المكلف للعثور على كتل ذاكرة مجانية للتعامل مع احتياجات ذاكرة عبء العمل، مما قد يؤدي إلى تدريب أبطأ.
- بالنسبة للنماذج الكبيرة (1.8B، 2.7B، 4.8B) التي لا يمكن تدريبها إلا باستخدام FSDP، فإن أعلى إعداد للإنتاجية هو التوسع إلى أكبر حجم دفعة باستخدام FSDP+AC. بالنسبة لـ 10B، يمكن ملاحظة أن الإنتاجية لأحجام الدفعات الصغيرة والقصوى متساوية تقريبًا. يرجع السبب في ذلك إلى أن AC يؤدي إلى زيادة الجهد الحسابي، وقد يؤدي حجم الدفعة الأقصى إلى عمليات إلغاء تجزئة باهظة الثمن بسبب التشغيل ضمن حدود ذاكرة CUDA. ومع ذلك، بالنسبة لهذه النماذج الكبيرة، فإن الزيادة في حجم الدفعة تعوض هذه النفقات العامة.
3. حجم الدفعة:
بالمقارنة مع DDP، فإن FSDP بمفرده يمكنه تحقيق أحجام دفعات أعلى قليلاً. بالنسبة لنموذج المعلمات 350M، يمكن استخدام FSDP+AC لتحقيق حجم دفعة أعلى بثلاث مرات من DDP، وبالنسبة لنموذج المعلمات 900M، يمكن تحقيق حجم دفعة أعلى بـ 5.5 مرات. حتى مع 10B، فإن الحد الأقصى لحجم الدفعة هو حوالي 20، وهو أمر جيد جدًا. يمكن لـ FSDP+AC تحقيق حجم دفعة عالمي أكبر باستخدام عدد أقل من وحدات معالجة الرسوميات، وهو أمر فعال بشكل خاص لمهام التعلم التبايني.
ختاماً
مع تطور نماذج القاعدة متعددة الوسائط، أصبحت معلمات النموذج القابلة للتطوير والتدريب الفعال مجالًا رئيسيًا. يهدف نظام PyTorch البيئي إلى تسريع تدريب وتوسيع نطاق النماذج متعددة الوسائط من خلال توفير أدوات مختلفة.
في المستقبل، سيضيف PyTorch الدعم لأنواع أخرى من النماذج، مثل النماذج التوليدية متعددة الوسائط، وتحسين أتمتة التقنيات ذات الصلة. نرحب بالجميع لمواصلة متابعة الحساب الرسمي لمجتمع مطوري PyTorch. يمكنك أيضًا مسح رمز الاستجابة السريعة وملاحظة "PyTorch" للانضمام إلى مجتمع PyTorch.

مدونة PyTorch الرسمية، الدروس التعليمية
أحدث التطورات وأفضل الممارسات
امسح رمز الاستجابة السريعة للانضمام إلى مجموعة المناقشة








