Command Palette
Search for a command to run...
تصحيح الأخطاء المطبعية | نشر نموذج واحد لتصحيح الأخطاء الإملائية للنصوص الصينية
نظرة عامة على المحتوى: أحد أنواع أخطاء النصوص الصينية هي الأخطاء الإملائية. تُعد هذه المقالة بمثابة برنامج تعليمي لنشر نموذج لتطبيق تصحيح أخطاء النص الصيني باستخدام طريقة التدريب المسبق BART.
الكلمات الرئيسية: BART، تصحيح الإملاء الصيني، معالجة اللغة الطبيعية
تم نشر هذه المقالة لأول مرة على الحساب الرسمي لـ WeChat: HyperAI
ثلاث عقبات رئيسية أمام أخطاء النصوص الصينية: الإملاء والقواعد والدلالات
يعد تصحيح أخطاء النصوص الصينية فرعًا مهمًا في مجال معالجة اللغة الطبيعية الحالي، والذي يهدف إلى اكتشاف أخطاء النصوص الصينية وتصحيحها.تتضمن الأخطاء النصية الصينية الشائعة أخطاء إملائية وأخطاء نحوية وأخطاء دلالية.
1. الأخطاء الإملائية:
يشير إلى الاستخدام غير الصحيح للكلمات أو العبارات بسبب طرق الإدخال وبرامج تحويل الكلام إلى نص وما إلى ذلك، ويتجلى ذلك بشكل أساسي في الاستخدام غير الصحيح للكلمات المتجانسة والحروف المتشابهة والأصوات المختلطة وما إلى ذلك، مثل "天气晴郎 – 天气晴" و"时侯 – 当时".
2. خطأ في بناء الجملة:
يشير إلى الكلمات المفقودة أو المكررة أو غير المنظمة أو غير المناسبة بسبب طرق الإدخال أو الكتابة اليدوية غير الدقيقة أو التعرف الضوئي على الحروف غير المنظم وما إلى ذلك، مثل "التواضع يجعل الناس يتقدمون - التواضع يجعل الناس يتقدمون".
3. خطأ دلالي:
الأخطاء المعرفية والمنطقية الناتجة عن عدم فهم بعض المعارف أو عدم القدرة على تنظيم اللغة مثل "هناك 3 أرباع في السنة - هناك 4 أرباع في السنة".
في هذه المقالة، سنستخدم الأخطاء الإملائية الأكثر شيوعًا كأمثلة.توضيح كيفية نشر نموذج تصحيح أخطاء النص الصيني باستخدام نموذج BART.
لتشغيل البرنامج التعليمي مباشرة، يرجى زيارة:
BART: نموذج SOTA الذي يعتمد على نقاط القوة في العديد من
BART تعني المحولات ثنائية الاتجاه والتراجعية التلقائية.إنه عبارة عن مشفر ذاتي لإزالة الضوضاء مصمم للتدريب المسبق لنماذج seq2seq. مناسب لمهام توليد اللغة الطبيعية والترجمة والفهم، اقترحته شركة Meta (المعروفة سابقًا باسم Facebook) في عام 2019.
لمزيد من التفاصيل، يرجى زيارة:
https://arxiv.org/pdf/1910.13461.pdf
يعتمد نموذج BART على مزايا BERT وGPT ويستخدم بنية المحول القياسية كأساس له:
- مرجع وحدة فك التشفير GPT: استبدال وظيفة تنشيط ReLU بوظيفة تنشيط GeLU
- تختلف وحدة التشفير عن BERT: تم التخلي عن وحدة الشبكة العصبية التغذية الأمامية وتم تبسيط معلمات النموذج.
- يشير جزء اتصال الترميز إلى المحول: يجب على كل طبقة من فك التشفير أن تقوم بحسابات الانتباه المتبادل على معلومات الإخراج للطبقة الأخيرة من المشفر (أي آلية انتباه المشفر-فك التشفير)

في هذا البرنامج التعليمي،نحن نستخدم نموذج nlp_bart_text-error-correction_chinese لنشر النموذج.
لمزيد من المعلومات، قم بزيارة:
تفاصيل البرنامج التعليمي: إنشاء عرض توضيحي لتصحيح النص عبر الإنترنت
إعداد البيئة
قم بتشغيل الأمر التالي في محطة Jupyter لتثبيت التبعيات:
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install fairseqتنزيل النموذج
قم بتنفيذ الأمر التالي في المحطة الطرفية لتنزيل النموذج:
git clone http://www.modelscope.cn/damo/nlp_bart_text-error-correction_chinese.gitيستغرق تنزيل النموذج وقتًا طويلاً. تم تنزيل النموذج في هذه الحاوية ويمكن استخدامه مباشرة. nlp_bart_text-error-correction_chinese دليل.
الاستخدام السريع
نشر النموذج
كتابة الخدمة الخدمية
يكتب predictor.py وثيقة:
- استيراد المكتبات التابعة: بالإضافة إلى المكتبات المستخدمة في العمل، تحتاج أيضًا إلى الاعتماد على openbayes-serving.
import openbayes_serving as serv
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks- فئة التنبؤ: ليست هناك حاجة إلى وراثة فئات أخرى، على الأقل توفير البداية وتوقع الواجهات.
- يخرج
__init__حدد مسار النموذج في نموذج التحميل - يخرج
predictإجراء الاستدلال وإرجاع النتيجة
class Predictor:
def __init__(self):
self.model_path = './nlp_bart_text-error-correction_chinese'
self.corrector = pipeline(Tasks.text_error_correction, model=self.model_path)
def predict(self, json):
text = json["input"].lower()
result = self.corrector(text)
return result- تشغيل: بدء الخدمة
if __name__ == '__main__':
serv.run(Predictor)امتحان
تنفيذ في المحطة الطرفية python predictor.pyبعد بدء الخدمة بنجاح، قم بتنفيذ الكود التالي في هذا المفكرة للاختبار.
ملاحظة: عند الاختبار في حاوية، إذا كان إصدار القارورة أكبر من 2.1، فقد تحدث أخطاء تسجيل مكررة. يمكنك تشغيله عن طريق خفض الإصدار.
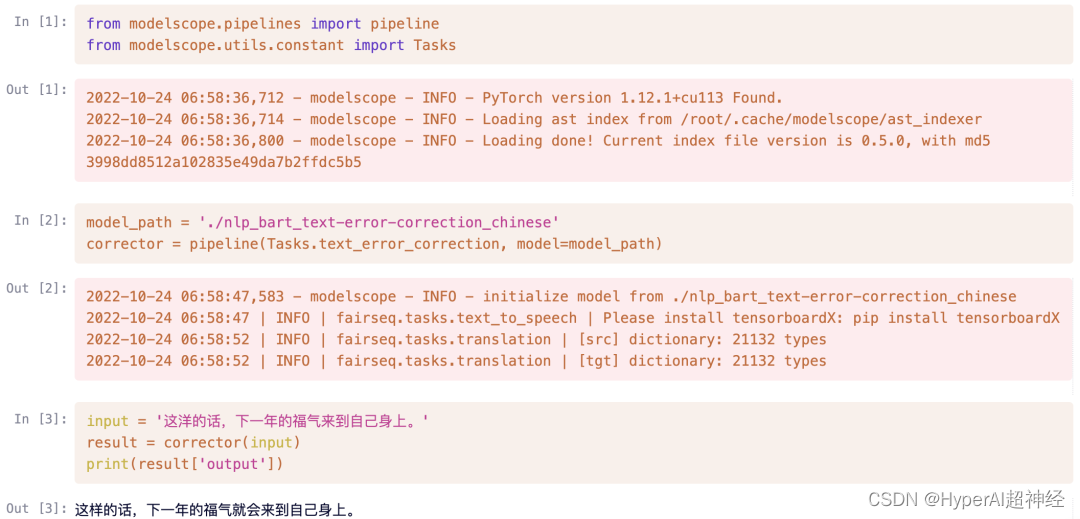
import requests
text = {"input": "这洋的话,下一年的福气来到自己身上。"}
result = requests.post('http://localhost:8080', json=text)
result.json()
{'output': '这样的话,下一年的福气就会来到自己身上。'}بالإضافة إلى الوصول إلى العنوان محليًا http://localhost:8080،يمكنك أيضًا اختباره عبر عنوان URL الذي يمكن الوصول إليه خارجيًا والموضح في المحطة الطرفية.

ملاحظة: بالنسبة لحاويات قوة الحوسبة المختلفة الخاصة بـ OpenBayes، يكون عنوان URL الذي يمكن الوصول إليه خارجيًا مختلفًا. إن استخدام الرابط المباشر في هذا البرنامج التعليمي غير صالح. يجب عليك استبداله بالرابط المطلوب في المحطة الطرفية..
result = requests.post('https://openbayes.com/jobs-auxiliary/open-tutorials/t23g93jjm95d', json=text)
result.json()نشر
بعد نجاح الاختبار، أوقف حاوية الحوسبة وانتظر حتى تكتمل عملية مزامنة البيانات.
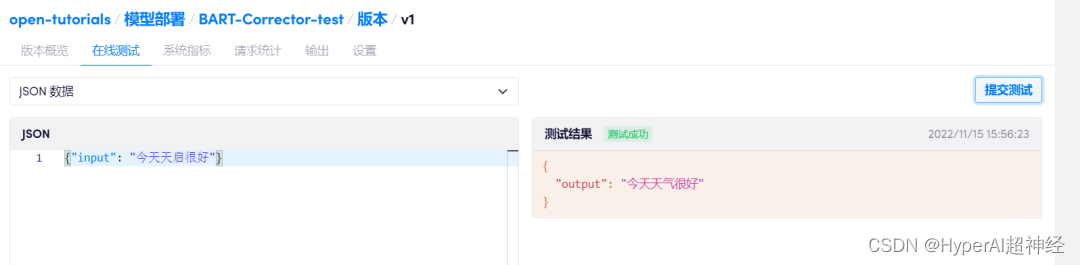
في "حاوية الحوسبة - نشر النموذج"، انقر فوق "إنشاء نشر جديد"، وحدد نفس الصورة المستخدمة في التطوير، وقم بربط حاوية الحوسبة هذه، ثم انقر فوق "نشر".يمكنك إجراء الاختبار عبر الإنترنت.
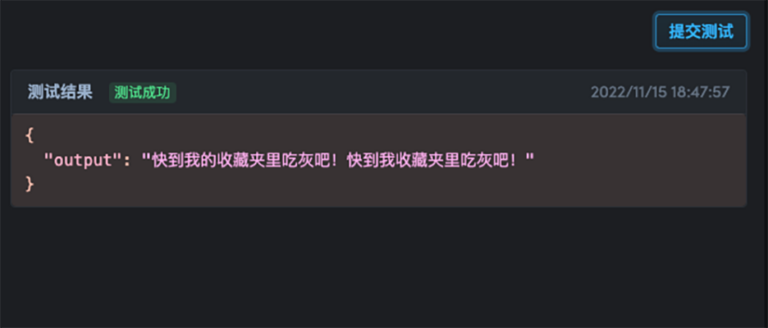
لمزيد من المعلومات حول نشر النموذج، يرجى الرجوع إلى:
في هذه المرحلة، تم تدريب ونشر نموذج تصحيح أخطاء النص الصيني الذي يدعم الاختبار عبر الإنترنت!
لمشاهدة وتشغيل البرنامج التعليمي الكامل، قم بزيارة الرابط التالي:
تعال وجرب نموذج تصحيح الخطأ الصيني الخاص بك!
-- زيادة--
روابط مرجعية:
[1] https://www.51cto.com/article/715865.html
[2] https://arxiv.org/pdf/1910.1346








