مراجعة الحلقة السابقة
-
ستون عامًا من التطور البطيء للترجمة الآلية
-
الترجمة الآلية القائمة على القواعد (RBMT)
-
الترجمة الآلية القائمة على الأمثلة (EBMT)
")
انقر على الصورة لقراءة الجزء الأول من هذا المقال
الترجمة الآلية الإحصائية (SMT)
في أوائل عام 1990، تم في مركز أبحاث IBM عرض نظام ترجمة آلية لأول مرة، وهو نظام لا يعرف شيئًا عن القواعد واللغويات. يقوم بتحليل النص الموجود في الصورة أدناه باللغتين ويحاول فهم الأنماط.
")
الفكرة بسيطة وجميلة. في كلتا اللغتين، يتم تقسيم الجملة نفسها إلى عدة كلمات ثم إعادة تجميعها. تم تكرار هذه العملية حوالي 500 مليون مرة، على سبيل المثال، تمت ترجمة كلمة "Das Haus" إلى "منزل" مقابل "مبنى" مقابل "بناء" وهكذا.
إذا تمت ترجمة الكلمة المصدر (على سبيل المثال، "Das Haus") إلى "منزل" في معظم الأحيان، فستفترض الآلة هذا المعنى. لاحظ أننا لم نضع أي قواعد ولم نستخدم أي قواميس - تم التوصل إلى جميع الاستنتاجات بواسطة الآلات، مسترشدين بالبيانات والمنطق. عند الترجمة، يبدو أن الآلة تقول: "إذا ترجمها الناس بهذه الطريقة، فسأفعلها بهذه الطريقة أيضًا". وهكذا ولدت الترجمة الآلية الإحصائية.
")
ومن مميزاتها أنها أكثر كفاءة، وأكثر دقة، ولا تحتاج إلى لغوي. كلما زاد النص الذي نستخدمه، كلما حصلنا على ترجمات أفضل.
")
(ترجمة إحصائية من جوجل: فهي لا تُظهر احتمالية استخدام هذا المعنى فحسب، بل توفر أيضًا إحصائيات حول معاني أخرى)
سؤال آخر:
كيف تقوم الآلة بربط كلمتي "Das Haus" و"building" - وكيف نعرف أن هذه الترجمات صحيحة؟
الجواب هو أننا لا نعرف.
في البداية، تفترض الآلة أن كلمة "Das Haus" لها نفس الارتباط مع أي كلمة في الجملة المترجمة. ثم، عندما تظهر كلمة "Das Haus" في جمل أخرى، يزداد الارتباط بكلمة "house". هذه هي "خوارزمية محاذاة الكلمات"، وهي مهمة نموذجية للتعلم الآلي على مستوى المدرسة.
تحتاج الآلة إلى ملايين الجمل بلغتين لجمع المعلومات الإحصائية ذات الصلة بكل كلمة. كيف يمكن الحصول على هذه المعلومات اللغوية؟ قررنا استخدام ملخصات اجتماعات البرلمان الأوروبي ومجلس الأمن التابع للأمم المتحدة - يتم تقديم هذه الملخصات باللغات كافة الدول الأعضاء، مما يمكن أن يوفر الكثير من الوقت لجمع المواد.
-
SMT القائم على الكلمات
في البداية، قامت أنظمة الترجمة الإحصائية الأولى بتقسيم الجمل إلى كلمات. وبما أن هذا النهج كان واضحاً ومنطقياً، فقد أطلق على أول نموذج للترجمة الإحصائية من إنتاج شركة IBM اسم "النموذج 1".
النموذج 1: سلة الكلمات
")
استخدم النموذج 1 النهج الكلاسيكي المتمثل في تقسيم الكلمات وحساب الإحصائيات، لكنه لم يأخذ في الاعتبار ترتيب الكلمات، وكانت الحيلة الوحيدة هي ترجمة كلمة واحدة إلى كلمات متعددة. على سبيل المثال، يمكن أن تصبح "Der Staubsauger" "المكنسة الكهربائية"، ولكن هذا لا يعني أنها ستصبح "المكنسة الكهربائية".
النموذج 2: مراعاة ترتيب الكلمات في الجملة
")
إن عدم وجود ترتيب للكلمات هو القيد الرئيسي للنموذج 1، وهو أمر مهم للغاية في عملية الترجمة. النموذج 2 يحل هذه المشكلة عن طريق حفظ المواضع المشتركة للكلمات في الجملة الناتجة وإعادة ترتيبها في الخطوات الوسيطة لجعل الترجمة أكثر طبيعية.
فهل أصبح الأمر أفضل؟ لا.
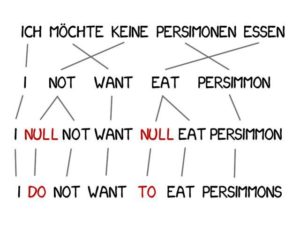
النموذج 3: إضافة كلمات جديدة
")
في الترجمة، غالبًا ما يكون من الضروري إضافة كلمات جديدة لتحسين الدلالات، مثل استخدام "do" في اللغة الألمانية عندما يكون النفي مطلوبًا في اللغة الإنجليزية.العبارة الألمانية "Ich will keine Persimonen" تُترجم إلى الإنجليزية على أنها "أنا لا أريد الكاكي".
لحل هذه المشكلة، يضيف النموذج 3 خطوتين إضافيتين بناءً على الخطوات السابقة:
-
إذا اعتبرت الآلة أنه يجب إضافة كلمة جديدة، يتم إدراج الرمز NULL؛
-
اختر القواعد النحوية الصحيحة أو زوج الكلمات لكل محاذاة للكلمات.
النموذج 4: محاذاة الكلمات
يأخذ النموذج 2 محاذاة الكلمات في الاعتبار ولكنه لا يعرف شيئًا عن إعادة الترتيب. على سبيل المثال، غالبًا ما تتبادل الصفات الأماكن مع الأسماء، وبغض النظر عن كيفية تذكر الترتيب، فمن الصعب الحصول على ترجمة دقيقة دون إضافة عوامل نحوية. لذلك، يأخذ النموذج 4 هذا "الترتيب النسبي" في الاعتبار - إذا كانت كلمتان تتبادلان الأماكن دائمًا، فسوف يعرف النموذج ذلك.
النموذج 5: إصلاح الأخطاء
النموذج 5 يحصل على المزيد من معلمات التعلم ويحل مشكلة تعارض موضع الكلمة. على الرغم من مدى ثوريتها، فإن الأنظمة المستندة إلى النصوص لا تزال غير قادرة على التعامل مع الكلمات المتجانسة، حيث تتم ترجمة كل كلمة بطريقة واحدة.
ومع ذلك، لم تعد هذه الأنظمة مستخدمة حيث تم استبدالها بترجمات أكثر تقدمًا تعتمد على العبارات.
-
SMT القائم على العبارة
تعتمد الطريقة على جميع مبادئ الترجمة المعتمدة على الكلمات: الإحصاء، وإعادة الترتيب، والتقنيات المعجمية. فهو يقسم النص ليس فقط إلى كلمات ولكن أيضًا إلى عبارات، وهي عبارة عن تسلسلات متواصلة من كلمات متعددة على وجه التحديد.
ونتيجة لذلك، تعلمت الآلة ترجمة مجموعات الكلمات المستقرة، وهو ما أدى إلى تحسين الدقة بشكل كبير.
")
والنقطة هي أن هذه العبارات ليست دائمًا هياكل نحوية بسيطة، وإذا كنا على دراية بالتدخل اللغوي وبنية الجملة، فإن جودة الترجمة سوف تنخفض بشكل كبير. لقد قال فريدريك جيلينك، أحد رواد اللغويات الحاسوبية، مازحا ذات مرة: "في كل مرة أهاجم فيها عالم لغوي، يتحسن أداء برنامج التعرف على الكلام".
بالإضافة إلى زيادة الدقة، توفر الترجمة القائمة على العبارات المزيد من الخيارات للنصوص ثنائية اللغة. بالنسبة للترجمة النصية، يعد التطابق الدقيق للمصدر أمرًا بالغ الأهمية، لذا من الصعب المساهمة في القيمة في الترجمة الأدبية أو المجانية.
لا تعاني الترجمة المعتمدة على العبارات من هذه المشكلة، ومن أجل تحسين مستوى الترجمة الآلية، بدأ الباحثون في تحليل مواقع الأخبار بلغات مختلفة.
")
منذ عام 2006، أصبح الجميع تقريبًا يستخدمون هذه الطريقة. كانت Google Translate و Yandex و Bing وأنظمة الترجمة عبر الإنترنت المعروفة الأخرى تعتمد جميعها على العبارات قبل عام 2016. وبالتالي، فإن نتائج أنظمة الترجمة هذه إما أن تكون مثالية أو لا معنى لها، ونعم، هذه هي سمة ترجمة العبارات.
هذه الطريقة القديمة المبنية على القواعد تؤدي دائمًا إلى نتائج متحيزة. لقد ترجم جوجل "ثلاثمائة" إلى "300" دون تردد، ولكن في الواقع "ثلاثمائة" تعني أيضًا "300 عام". وهذا أحد القيود الشائعة لآلات الترجمة الإحصائية.
قبل عام 2016، اعتبرت جميع الدراسات تقريبًا أن الترجمة القائمة على العبارات هي الأكثر تقدمًا، بل وساوت حتى بين "الترجمة الآلية الإحصائية" و"الترجمة القائمة على العبارات". ومع ذلك، أدرك الناس أن جوجل سوف يحدث ثورة في مجال الترجمة الآلية بالكامل.
-
SMT القائم على بناء الجملة
وينبغي أيضًا ذكر هذه الطريقة بشكل مختصر. قبل سنوات عديدة من ظهور الشبكات العصبية، كانت الترجمة القائمة على القواعد النحوية تعتبر "المستقبل"، لكن الفكرة لم تنجح.
ويرى أنصار هذا النهج أنه من الممكن دمجه مع النهج المبني على القواعد. من الممكن إجراء تحليل نحوي دقيق للجمل - تحديد الموضوع، والمسند، وأجزاء أخرى من الجملة، ثم بناء شجرة الجملة. وباستخدامه، تتعلم الآلات تحويل الوحدات النحوية بين اللغات وترجمتها حسب الكلمة أو العبارة. سيؤدي هذا إلى حل مشكلة "خطأ الترجمة" تمامًا.
")
الفكرة جميلة ولكن الواقع قاتم جداً يعمل التحليل النحوي بشكل سيء للغاية، على الرغم من أن مشكلة مكتبة القواعد النحوية الخاصة به قد تم حلها من قبل (لأن لدينا بالفعل العديد من مكتبات اللغات الجاهزة).
الترجمة الآلية العصبية (NMT)
في عام 2014، ظهرت ورقة بحثية مثيرة للاهتمام حول الترجمة الآلية للشبكات العصبية، لكنها لم تجذب الكثير من الاهتمام، وبدأت شركة جوجل فقط في التعمق في هذا المجال. وبعد مرور عامين، في نوفمبر/تشرين الثاني 2016، أعلنت جوجل عن إعلان بارز: لقد قمنا رسميًا بتغيير قواعد اللعبة الخاصة بالترجمة الآلية.
الفكرة مشابهة لميزة Prisma التي تتيح لك محاكاة أسلوب أعمال الفنانين المشهورين. في Prisma، يتم تعليم الشبكات العصبية كيفية التعرف على أسلوب عمل الفنان، ويمكن للصور المصممة الناتجة، على سبيل المثال، أن تجعل الصورة تبدو وكأنها لوحة لفان جوخ. رغم أن هذا مجرد وهم من الإنترنت، إلا أننا نعتقد أنه جميل.
")
ماذا لو تمكنا من نقل أسلوب ما إلى صورة فوتوغرافية، ماذا لو حاولنا فرض لغة أخرى على النص المصدر؟ سيكون النص هو "أسلوب الفنان" الدقيق وسنحاول نقله مع الحفاظ على جوهر الصورة (بعبارة أخرى، جوهر النص).
تخيل ماذا سيحدث إذا تم تطبيق هذا النوع من الشبكات العصبية على نظام الترجمة؟
الآن، بافتراض أن النص المصدر هو مجموعة من الميزات المحددة، فهذا يعني أنك بحاجة إلى ترميزه ثم جعل شبكة عصبية أخرى تفك تشفيره مرة أخرى إلى نص بلغة يعرفها فك التشفير فقط. لا يُعرف أصل هذه الخصائص، ولكن من الممكن التعبير عنها باللغة الإسبانية.
سيكون من المثير للاهتمام أن نرى شبكة عصبية واحدة تقوم فقط بتشفير الجمل إلى مجموعة محددة من الميزات، في حين أن الشبكة الأخرى لا تستطيع إلا فك تشفيرها مرة أخرى إلى نص. ولم يكن أي منهما يعرف من هو الآخر. وكان كل واحد منهم يعرف لغته الخاصة فقط. لقد كانوا غرباء عن بعضهم البعض ولكن لا يزال بإمكانهم التنسيق مع بعضهم البعض.
")
ولكن هناك مشكلة هنا أيضًا، وهي كيفية العثور على هذه الخصائص وتحديدها. عندما نتحدث عن الكلاب فإن خصائصها واضحة، ولكن ماذا عن النص؟ كما تعلمون، منذ 30 عامًا، حاول العلماء إنشاء شفرة لغة عالمية، لكنهم فشلوا في النهاية.
لكن لدينا الآن التعلم العميق، الذي يمكنه حل هذه المشكلة بشكل جيد للغاية لأنه موجود لهذا الغرض. الفرق الرئيسي بين التعلم العميق والشبكات العصبية الكلاسيكية هو قدرتها على البحث الدقيق عن هذه الميزات المحددة، بغض النظر عن طبيعتها. إذا كانت الشبكة العصبية كبيرة بما يكفي، وتحتوي على آلاف بطاقات الفيديو تحت تصرفها، فيمكنها استخراج هذه الميزات من النص.
من الناحية النظرية، يمكننا أن ننقل الميزات التي تم الحصول عليها من الشبكات العصبية إلى اللغويين، حتى يتمكنوا من فتح آفاق جديدة تمامًا لأنفسهم.
السؤال هو، ما نوع الشبكة العصبية التي يمكن تطبيقها على ترميز وفك تشفير النصوص؟
نحن نعلم أن الشبكات العصبية التلافيفية (CNNs) تعمل حاليًا فقط على الصور استنادًا إلى كتل بكسل مستقلة، ولكن لا توجد كتل مستقلة في النص، وتعتمد كل كلمة على البيئة المحيطة بها، تمامًا مثل اللغة والموسيقى. ستوفر الشبكات العصبية المتكررة (RNNs) خيارًا مثاليًا لأنها تتذكر جميع النتائج السابقة - في حالتنا، الكلمات السابقة.
ويتم بالفعل استخدام الشبكات العصبية المتكررة اليوم، مثل نظام التعرف على الصوت RNN-Siri في هواتف iPhone (يقوم بتحليل ترتيب الأصوات، حيث يعتمد التالي على السابق)، ومطالبات لوحة المفاتيح (تذكر السابق، وخمن التالي)، وتوليد الموسيقى، وحتى برامج الدردشة.
")
في غضون عامين، تجاوزت الشبكات العصبية أعمال الترجمة التي تمت خلال العشرين عامًا الماضية بشكل كامل. لقد تم تقليل أخطاء ترتيب الكلمات بنسبة 50%، وأخطاء المفردات بنسبة 17%، والأخطاء النحوية بنسبة 19%. حتى أن الشبكة العصبية تعلمت كيفية التعامل مع مشاكل مثل الكلمات المتجانسة في اللغات المختلفة.
ومن المثير للدهشة أن الشبكات العصبية قادرة على تحقيق ترجمة مباشرة حقيقية، مما يلغي الحاجة إلى القواميس تمامًا. عند الترجمة بين لغتين غير الإنجليزية، ليست هناك حاجة لاستخدام اللغة الإنجليزية كلغة وسيطة. في السابق، إذا كنت تريد ترجمة اللغة الروسية إلى اللغة الألمانية، كان عليك أولاً ترجمة اللغة الروسية إلى اللغة الإنجليزية ثم ترجمة اللغة الإنجليزية إلى اللغة الألمانية. سيؤدي هذا إلى زيادة معدل الخطأ في الترجمة المتكررة.
")
ترجمة جوجل (منذ عام 2016)
في عام 2016، قاموا بتطوير نظام يسمى Google Neural Machine Translation (GNMT) للترجمة إلى تسع لغات. ويحتوي على 8 أجهزة تشفير و8 أجهزة فك تشفير، بالإضافة إلى اتصال بالشبكة يمكن استخدامه للترجمة عبر الإنترنت.
")
لا يقومون بفصل الجمل فحسب، بل يقومون أيضًا بفصل الكلمات، وهذه هي الطريقة التي يتعاملون بها مع الكلمة النادرة. عندما لا تكون الكلمة موجودة في القاموس، لا يوجد مرجع لـ NMT. على سبيل المثال، فكر في ترجمة مجموعة الحروف "Vas3k". في هذه الحالة، يحاول GMNT تقسيم الكلمة إلى أجزاء واستعادة ترجمتها.
نصيحة: لا يزال تطبيق Google Translate لترجمة مواقع الويب في المتصفح يستخدم خوارزمية العبارة القديمة. لسبب ما، لم يقم Google بتحديثه، والاختلافات ملحوظة مقارنة بالإصدار عبر الإنترنت.
ومع ذلك، فإن خدمة Google Translate المستخدمة حاليًا في المتصفح لترجمة مواقع الويب لا تزال تستخدم خوارزمية تعتمد على العبارة. بطريقة ما، لم تقم Google بتحديثه في هذا الصدد، ولكن هذا يسمح لنا أيضًا برؤية الفرق عن وضع الترجمة التقليدي.
تستخدم جوجل آلية التعهيد الجماعي عبر الإنترنت حيث يمكن للأشخاص اختيار الإصدار الذي يعتقدون أنه الأكثر صحة، وإذا أعجب به الكثير من المستخدمين، فستستمر جوجل في ترجمة العبارة بهذه الطريقة ووضع علامة خاصة عليها. وهذا مفيد جدًا للجمل القصيرة اليومية مثل "دعنا نذهب إلى السينما" أو "أنا في انتظارك".
ترجمة ياندكس (منذ عام 2017)
أطلقت ياندكس نظام الترجمة العصبية في عام 2017، والذي يستخدم خوارزمية CatBoost التي تجمع بين الشبكات العصبية والأساليب الإحصائية.
يمكن أن تعوض هذه الطريقة بشكل فعال عن أوجه القصور في ترجمة الشبكة العصبية - حيث من المرجح أن يحدث تشوه في الترجمة للعبارات التي لا تظهر بشكل متكرر. في هذه الحالة، يمكن لترجمة إحصائية بسيطة العثور على الكلمة الصحيحة بسرعة وسهولة.
")
مستقبل الترجمة الآلية؟
لا يزال الناس متحمسين لمفهوم "سمكة بابل" - الترجمة الصوتية الفورية. لقد اتخذت شركة Google خطوة نحو هذا الهدف من خلال سماعات Pixel Buds، ولكن الحقيقة هي أنها ليست مثالية بالتأكيد لأنك تحتاج إلى إخبارها متى تبدأ الترجمة ومتى تصمت وتستمع. ولكن حتى سيري لا تستطيع فعل هذا.
هناك صعوبة واحدة تحتاج إلى استكشاف: كل التعلم يقتصر على مجموعة التعلم الآلي. حتى لو تمكنا من تصميم شبكات عصبية أكثر تعقيدًا، فإنها تقتصر حاليًا على التعلم من النص المقدم. يمكن للمترجمين البشريين استكمال النصوص ذات الصلة من خلال قراءة الكتب أو المقالات لضمان الحصول على نتائج ترجمة أكثر دقة. وهذا هو المكان الذي تتخلف فيه الترجمة الآلية كثيرًا عن الترجمة البشرية.
ولكن بما أن المترجمين البشريين قادرون على القيام بذلك، فمن الناحية النظرية، يمكن للشبكات العصبية أن تقوم بذلك أيضًا. ويبدو أن بعض الأشخاص قد حاولوا بالفعل تحقيق هذه الوظيفة باستخدام الشبكات العصبية. وهذا يعني أنه يستخدم اللغة التي يعرفها للقراءة بلغة أخرى لاكتساب الخبرة، ثم يعيدها إلى نظام الترجمة الخاص به لاستخدامها في المستقبل. دعونا ننتظر ونرى.
قراءة إضافية
")
الترجمة الآلية الإحصائية
بقلم فيليب كوين
اتبع الحساب العام ورد على "الترجمة الآلية الإحصائية" لتحميل نسخة PDF
")
")








