Command Palette
Search for a command to run...
PipeTransformer: خط أنابيب مرن آلي لتدريب النماذج الموزعة على نطاق واسع

عنوان الورقة:
PipeTransformer: خطوط أنابيب مرنة آلية للتدريب الموزع للنماذج واسعة النطاق
يستخدم Pipeptransformer خطوط أنابيب مرنة آلية لإجراء تدريب موزع فعال لنماذج المحولات. في PipeTransformer، قمنا بتصميم خوارزمية تجميد ديناميكية قابلة للتكيف يمكنها التعرف تدريجيًا على طبقات معينة وتجميدها أثناء التدريب، ونظام خط أنابيب مرن يمكنه تخصيص الموارد بشكل ديناميكي لتدريب الطبقات النشطة المتبقية.
على وجه التحديد، يقوم PipeTransformer تلقائيًا باستبعاد الطبقات المجمدة من خط الأنابيب، ويجمع الطبقات النشطة في عدد أقل من وحدات معالجة الرسوميات، ويتفرع مع المزيد من النسخ المتماثلة لزيادة عرض البيانات الموازي.
تظهر التقييمات على ViT (باستخدام مجموعة بيانات ImageNet) وBERT (باستخدام مجموعات بيانات SQuAD وGLUE) أن PipeTransformer يحقق تسريعًا يصل إلى 2.83x مقارنة بخطوط الأساس الحديثة دون أي فقدان في الدقة.
وتتضمن الورقة أيضًا مجموعة متنوعة من تحليلات الأداء لمساعدة المستخدمين على اكتساب فهم أكثر شمولاً للخوارزمية وتصميم النظام.
بعد ذلك، ستقدم هذه المقالة بالتفصيل الخلفية البحثية، والدافع، وأفكار التصميم، وحلول التصميم للنظام، وكيفية تنفيذ الخوارزمية والنظام باستخدام واجهة برمجة التطبيقات الموزعة PyTorch.
مقدمة

لقد حققت نماذج المحولات الكبيرة اختراقات في الدقة في كل من معالجة اللغة الطبيعية والرؤية الحاسوبية. يحقق GPT-3 أرقامًا قياسية جديدة في الدقة العالية لمعظم مهام معالجة اللغة الطبيعية. في ImageNet، حقق Vision Transformer (ViT باختصار) أيضًا دقة عالية بلغت 89%، متفوقًا على شبكات التلافيفية الأكثر تقدمًا ResNet-152 وEfficientNet.
لتناول مشكلة أحجام النماذج المتزايدة باستمرار، اقترح الباحثون تقنيات تدريب موزعة مختلفة، بما في ذلك خوادم المعلمات، والتوازي في خطوط الأنابيب، والتوازي داخل الطبقة، والتوازي في البيانات بدون تكرار.
ومع ذلك، فإن حلول التدريب الموزعة الحالية هي مجرد سيناريوهات بحثية، ويجب تحسين جميع أوزان النموذج أثناء عملية التدريب (أي يجب أن تظل تكاليف الحساب والاتصال مستقرة نسبيًا أثناء التكرارات المختلفة). تظهر الأبحاث الحديثة حول التدريب التدريجي أنه يمكن تدريب المعلمات في الشبكة العصبية بشكل ديناميكي:
- تحليل الارتباط الكنسي للمتجه المفرد لديناميكيات التعلم العميق والقدرة على التفسير. مؤتمر نيوريبس 2017
- التدريب الفعال لـ BERT من خلال التكديس التدريجي. ICML 2019
- تسريع تدريب نماذج اللغة القائمة على المحول باستخدام إسقاط الطبقة التدريجي. نيوريبس 2020
- حول نمو المحول للتدريب على BERT التدريجي. المؤتمر الوطني لطب الأسنان العام 2021

الشكل 2: التدريب المجمد القابل للتفسير: التقارب من أسفل إلى أعلى في DNN (باستخدام ResNet لاختبار النتائج على CIFAR10) يوضح كل جزء تشابه كل طبقة من خلال SVCCA
على سبيل المثال، في التدريب المجمد، تتقارب الشبكات العصبية عادةً من الأسفل إلى الأعلى (أي ليس من الضروري تدريب جميع الطبقات لتحقيق نتائج معينة).
يوضح الشكل أعلاه مثالاً لكيفية استقرار الأوزان أثناء عملية التدريب باستخدام نهج مماثل. وبناء على هذا،نحن نستفيد من التدريب المجمد لإجراء تدريب موزع لنماذج المحولات، وتسريع التدريب من خلال تخصيص الموارد بشكل ديناميكي للتركيز على مجموعة مختصرة من الطبقات النشطة.
تعتبر استراتيجية تجميد الطبقة هذه مناسبة بشكل خاص لتوازي خطوط الأنابيب، لأن استبعاد الطبقات السفلية المتتالية من خط الأنابيب يمكن أن يقلل من تكاليف الحوسبة والذاكرة والاتصالات.
الشكل 3: تعمل عملية خط الأنابيب الآلية والمرنة في PipeTransformer على تسريع التدريب الموزع لنماذج المحولات
PipeTransformer هو إطار عمل مرن لتسريع تدريب خطوط الأنابيب والذي يتفاعل تلقائيًا مع الطبقات المجمدة عن طريق تحويل نطاق نماذج خطوط الأنابيب وعدد نسخ خطوط الأنابيب بشكل ديناميكي.
على حد علمنا، هذه هي الورقة الأولى التي تدرس تجميد الطبقة في سياق خطوط الأنابيب والتدريب الموازي للبيانات.
يوضح الشكل 3 مزايا هذا المزيج.
أولاً، من خلال استبعاد الطبقات المجمدة من خط الأنابيب، يمكن ضغط نفس النموذج في عدد أقل من وحدات معالجة الرسومات، مما يؤدي إلى تقليل الاتصالات بين وحدات معالجة الرسومات وتقليص فقاعات خط الأنابيب.
ثانيًا، بعد تعبئة النموذج على عدد أقل من وحدات معالجة الرسوميات، يمكن لنفس المجموعة استيعاب المزيد من تكرارات خط الأنابيب، وبالتالي زيادة عرض التوازي في البيانات.
والأمر الأكثر أهمية هو أن الميزتين مضاعفتان وليستا تراكميتين، مما يؤدي إلى تسريع تقدم التدريب.
يواجه تصميم PipeTransformer أربعة تحديات رئيسية.
أولاً، يجب أن تتخذ خوارزمية التجميد قرارات تجميد ديناميكية وتكيفية؛ ومع ذلك، فإن العمل الحالي لا يوفر سوى أداة تحليل لاحقة.
ثانيًا، تتأثر كفاءة إعادة تقسيم خط الأنابيب بالعديد من العوامل، بما في ذلك حبيبات التقسيم، وحجم التنشيط عبر التقسيم، وعدد أجزاء الدفعات الصغيرة، الأمر الذي يتطلب التفكير والبحث في مساحة حل أكبر.
بعد ذلك، لتقديم نسخ إضافية من خطوط الأنابيب بشكل ديناميكي، يجب على PipeTransformer التغلب على الطبيعة الثابتة للاتصالات الجماعية وتجنب بروتوكولات المراسلة المعقدة بين العمليات (لا يمكن التعامل مع خط الأنابيب إلا بواسطة عملية واحدة) عندما تصبح العمليات الجديدة متاحة عبر الإنترنت.
أخيرًا، يمكن أن توفر ذاكرة التخزين المؤقت الوقت للانتشار الأمامي المتكرر للطبقات المجمدة، ولكن يجب مشاركتها بين خطوط الأنابيب الموجودة وخطوط الأنابيب المضافة حديثًا لأن النظام لا يستطيع إنشاء وتسخين ذاكرة تخزين مؤقتة مخصصة لكل نسخة متماثلة.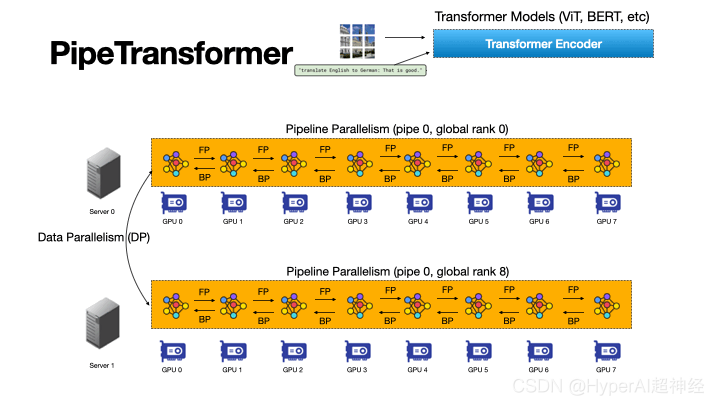
الشكل 4: مخطط تخطيطي لديناميكيات المحول الأنبوبي
كما هو موضح في الشكل 4، من أجل مواجهة التحديات المذكورة أعلاه،يتكون تصميم PipeTransformer من أربعة كتل بناء أساسية.
الأولى هي خوارزمية تكيفية قابلة للضبط تعمل على توليد إشارات تساعد في تحديد الطبقات المجمدة في تكرارات مختلفة (خوارزمية التجميد). بمجرد تشغيل هذه الإشارات، تقوم وحدة خط الأنابيب المرنة (AutoPipe) بتجميع الطبقات النشطة المتبقية في عدد أقل من وحدات معالجة الرسوميات من خلال تقييم التغييرات في أحجام النشاط وأحمال العمل للأقسام غير المتجانسة (الطبقات المجمدة والنشطة).
بعد ذلك، بناءً على نتائج التحليل السابقة لأطوال خطوط الأنابيب المختلفة، يتم تقسيم الدفعة الصغيرة إلى سلسلة من الدفعات الصغيرة الأفضل.
تعمل الوحدة التالية، AutoDP، على إنشاء نسخ إضافية من خطوط الأنابيب لشغل وحدات معالجة الرسومات (GPUs) التي تم إصدارها وتحافظ على مجموعات عملية الاتصال الهرمية لتحقيق العضوية الديناميكية للاتصال الجماعي.
تشارك الوحدة الأخيرة، AutoCache، عمليات التنشيط بكفاءة بين العمليات المتوازية للبيانات الموجودة والمضافة حديثًا وتستبدل ذاكرة التخزين المؤقت القديمة تلقائيًا أثناء التحويلات.
بشكل عام، يجمع PipeTransformer بين خوارزمية التجميد ووحدات AutoPipe وAutoDP وAutoCache لتوفير تسريع تدريبي كبير.
لقد قمنا بتقييم PipeTransformer باستخدام نماذج ViT (باستخدام مجموعة بيانات ImageNet) وBERT (باستخدام مجموعات بيانات SQuAD وGLUE) وأظهرنا أن PipeTransformer يحقق تسريعًا يصل إلى 2.83x مقارنة بخطوط الأساس الحديثة دون أي فقدان في الدقة.
نحن نقدم أيضًا تحليلات أداء مختلفة لمساعدة المستخدمين على اكتساب فهم أكثر شمولاً للتصميمات الخوارزمية والنظامية. أخيرًا، قمنا بتطوير واجهة برمجة تطبيقات مرنة مفتوحة المصدر لـ PipeTransformer توفر فصلًا واضحًا بين خوارزميات التجميد، وتعريف النموذج، وتسريع التدريب، مما يسمح بالانتقال إلى الخوارزميات التي تتطلب استراتيجيات تجميد مماثلة.
التصميم العام
لنفترض أن هدفنا هو تدريب نموذج واسع النطاق في نظام تدريب موزع. يجمع هذا النظام بين التوازي في نموذج خط الأنابيب والتوازي في البيانات ويمكن استخدامه للتعامل مع السيناريوهات التالية:
لا يمكن للنموذج أن يتناسب مع ذاكرة جهاز وحدة معالجة رسومية واحدة، أو أن حجم الدفعة صغير بما يكفي لتجنب نفاد الذاكرة. على وجه التحديد، الإعدادات المحددة هي كما يلي:
- مهام التدريب وتعريفات النموذج. قم بتدريب نماذج المحول (مثل Vision Transformer، وBERT، وما إلى ذلك) على مجموعات بيانات الصور أو النصوص واسعة النطاق. يحتوي نموذج المحول mathcalF على إجمالي L طبقات، حيث تتكون الطبقة i من دالة حساب أمامية fi ومجموعة من المعلمات المقابلة.
- البنية التحتية للتدريب. افترض أن البنية الأساسية للتدريب تتكون من مجموعة وحدة معالجة رسومية تحتوي على N خادم وحدة معالجة رسومية (أي العقد). تحتوي كل عقدة على I وحدة معالجة رسومية. المجموعة متجانسة، مما يعني أن تكوين الأجهزة لكل وحدة معالجة رسومية وخادم متطابق. سعة الذاكرة لكل وحدة معالجة رسومية هي MGPU. يتم ربط الخوادم مع بعضها البعض عبر واجهات الشبكة ذات النطاق الترددي العالي مثل InfiniBand.
- التوازي في خطوط الأنابيب. في كل جهاز، نقوم بتحميل النموذج F في خط أنابيب يحتوي على K قسم (K يمثل أيضًا طول خط الأنابيب). يتكون القسم k من طبقات Pk المتتالية. افترض أن كل قسم تتم معالجته بواسطة جهاز GPU واحد. 1≤K≤I يعني أنه يمكننا بناء خطوط أنابيب متعددة لنسخ متعددة من النماذج على جهاز واحد.
افترض أن جميع أجهزة وحدة معالجة الرسوميات في خط الأنابيب تنتمي إلى نفس الجهاز، وأن خط الأنابيب عبارة عن خط أنابيب متزامن، ولا يتضمن أي تدرجات منتهية الصلاحية، وأن عدد الدفعات الصغيرة هو M. في نظام التشغيل Linux، تتم معالجة كل خط أنابيب بواسطة عملية. لمزيد من التفاصيل، راجع GPipe.
- التوازي في البيانات. DDP عبارة عن مجموعة معالجة متوازية للبيانات موزعة عبر الأجهزة داخل العمال المتوازيين R. كل عامل هو نسخة من خط الأنابيب (عملية واحدة). الفهرس (المعرف) للعامل rth هو الرتبة r.
بالنسبة لأي خطي أنابيب في DDP، يمكن أن ينتميا إلى نفس خادم وحدة معالجة الرسومات (GPU) أو خوادم وحدة معالجة الرسومات (GPU) المختلفة، ويمكنهما أيضًا تبادل التدرجات باستخدام خوارزمية AllReduce.
في هذه الحالات، هدفنا هو تسريع التدريب من خلال الاستفادة من التدريب المجمد، مما يلغي الحاجة إلى تدريب جميع الطبقات أثناء عملية التدريب بأكملها.
بالإضافة إلى ذلك، يساعد هذا في توفير العمليات الحسابية والاتصالات وفقدان الذاكرة، ويتجنب إلى حد ما الإفراط في التجهيز الناجم عن التجميد المستمر للطبقات.
ومع ذلك، للاستفادة من هذه المزايا، يجب التغلب على التحديات الأربعة المذكورة أعلاه، وهي تصميم خوارزمية تجميد متكيفة، وإعادة تقسيم خط الأنابيب الديناميكي، وإعادة تخصيص الموارد بكفاءة، والتخزين المؤقت عبر العمليات.
الشكل 5: نظرة عامة على نظام تدريب PipeTransformer
شاركت PipeTransformer في تصميم خوارزمية تجميد فورية ونظام تدريب خط أنابيب مرن تلقائي يمكنه تحويل نطاق نماذج خط الأنابيب وعدد نسخ خط الأنابيب بشكل ديناميكي. يظهر الهيكل العام للنظام في الشكل 5.
لدعم خط الأنابيب المرن الخاص بـ PipeTransformer، نقوم بالحفاظ على إصدار مخصص من PyTorch Pipeline. بالنسبة لتوازي البيانات، نستخدم PyTorch DDP كخط أساسي. المكتبات الأخرى هي آليات قياسية لنظام التشغيل (مثل المعالجة المتعددة)، والتي تلغي أيضًا الحاجة إلى برامج أو أجهزة مخصصة.
لضمان تنوع الإطار، قمنا بفصل نظام التدريب إلى أربعة مكونات أساسية: خوارزمية التجميد، وAutoPipe، وAutoDP، وAutoCache.
تقوم خوارزمية التجميد (الرمادية) بأخذ عينات من المقاييس من حلقة التدريب وتتخذ قرارات التجميد طبقة تلو الأخرى، والتي يتم مشاركتها مع AutoPipe (الأخضر).
AutoPipe هي وحدة خط أنابيب مرنة تعمل على تسريع التدريب من خلال استبعاد الطبقات المجمدة من خط الأنابيب وتعبئة الطبقات النشطة على عدد أقل من وحدات معالجة الرسومات (اللون الوردي)، وبالتالي تقليل الاتصالات بين وحدات معالجة الرسومات والحفاظ على توقف خط الأنابيب بشكل أصغر.
يقوم AutoPipe بعد ذلك بتمرير معلومات طول خط الأنابيب إلى AutoDP (اللون الأرجواني)، والذي يقوم بعد ذلك بإنشاء المزيد من نسخ خط الأنابيب عندما يكون ذلك ممكنًا لزيادة عرض التوازي في البيانات.
يتضمن الشكل أيضًا مثالًا حيث يقدم AutoDP نسخة متماثلة جديدة (باللون الأرجواني). AutoCache (المخطط البرتقالي) عبارة عن وحدة تخزين مؤقتة عبر خطوط الأنابيب. من أجل سهولة القراءة والعمومية، يظل هيكل الكود المصدر متوافقًا مع الشكل 5.
التنفيذ باستخدام واجهة برمجة تطبيقات PyTorch
كما يمكن رؤيته من الشكل 5، يتكون PipeTransformer من أربعة مكونات: Freeze Algorithm وAutoPipe وAutoDP وAutoCache.
من بينها، يعتمد AutoPipe وAutoDP على PyTorch DDP (torch.nn.parallel.DistributedDataParallel) وpipeline (torch.distributed.pipeline) على التوالي.
في هذه المدونة، نسلط الضوء فقط على تفاصيل التنفيذ الرئيسية لـ AutoPipe و AutoDP. لمزيد من المعلومات حول خوارزمية التجميد وAutoCache، راجع الورقة.
AutoPipe: خط أنابيب مرن
يمكن لـ AutoPipe تسريع التدريب عن طريق استبعاد الطبقات المجمدة من خط الأنابيب وضغط الطبقات النشطة على عدد أقل من وحدات معالجة الرسوميات.يتناول هذا القسم المكونات الرئيسية لـ AutoPipe:
1) خط أنابيب التقسيم الديناميكي؛
2) تقليل عدد معدات خطوط الأنابيب؛
3) تحسين حجم الدفعة الصغيرة وفقًا لذلك
الاستخدام الأساسي لخط أنابيب PyTorch
قبل الخوض في تفاصيل AutoPipe، دعونا أولاً نتعرف على الاستخدام الأساسي لـ PyTorch Pipeline (torch.distributed.pipeline.sync.Pipe):
لفهم تصميم خط الأنابيب أثناء العمل، ضع في اعتبارك المثال البسيط التالي:
# Step 1: build a model including two linear layers
fc1 = nn.Linear(16, 8).cuda(0)
fc2 = nn.Linear(8, 4).cuda(1)
# Step 2: wrap the two layers with nn.Sequential
model = nn.Sequential(fc1, fc2)
# Step 3: build Pipe (torch.distributed.pipeline.sync.Pipe)
model = Pipe(model, chunks=8)
# do training/inference
input = torch.rand(16, 16).cuda(0)
output_rref = model(input)في هذا المثال البسيط، يمكنك أن ترى أنه قبل تهيئة Pipe، تحتاج إلى تقسيم نموذج nn.Sequential إلى أجهزة GPU متعددة وتعيين العدد الأمثل للأجزاء.
يعد تحقيق التوازن في العمليات الحسابية عبر الأقسام أمرًا بالغ الأهمية لسرعة تدريب خط الأنابيب، حيث إن التوزيع غير المتساوي لحمل العمل عبر المراحل يمكن أن يتسبب في حدوث تأخيرات، مما يجبر الأجهزة التي تحتوي على عدد أقل من المهام على الانتظار. يمكن أن يكون لعدد القطع أيضًا تأثيرًا كبيرًا على إنتاجية خط الأنابيب.
موازنة أقسام خطوط الأنابيب
في أنظمة التدريب الديناميكية مثل PipeTransformer، فإن مجرد وجود نفس عدد المعلمات في كل قسم لا يضمن أسرع سرعة تدريب. وتلعب عوامل أخرى أيضًا دورًا رئيسيًا:
الشكل 6: تقع حدود القسم في منتصف اتصال التخطي
1. تكلفة الاتصالات عبر الأقسام. يؤدي وضع حدود القسم في منتصف اتصال التخطي إلى حدوث اتصال إضافي لأن المتجهات الموجودة في اتصال التخطي يجب أن يتم نسخها بعد ذلك إلى وحدات معالجة رسومية مختلفة.
على سبيل المثال، بالنسبة لأقسام BERT في الشكل 6، يجب أن يحصل القسم k على مخرجات وسيطة من القسم k-2 والقسم k-1. على النقيض من ذلك، إذا تم وضع الحدود بعد طبقة الإضافة، تصبح تكلفة الاتصال بين القسم k-1 والقسم k أصغر بشكل كبير.
تظهر القياسات أن الاتصالات بين الأجهزة أكثر تكلفة من الأقسام غير المتوازنة قليلاً، لذا لا نفكر في قطع اتصالات التخطي.
2. تجميد استخدام ذاكرة الطبقة. أثناء التدريب، يجب على AutoPipe إعادة حساب حدود القسم عدة مرات لموازنة نوعين مختلفين من الطبقات: الطبقات المجمدة والطبقات النشطة.
نظرًا لأن الطبقات المجمدة لا تتطلب خرائط تنشيط عكسية وحالات محسِّن وتدرجات، فإن تكلفة ذاكرة الطبقات المجمدة لا تشكل سوى جزء بسيط من تكلفة الطبقات غير النشطة.
بدلاً من تشغيل ملف تعريف تدخلي للحصول على المقاييس الأساسية لتكاليف الذاكرة والحوسبة، نقوم بتعريف عامل تكلفة قابل للضبط lambdafrozen لتقييم استخدام الذاكرة لطبقة مجمدة بالنسبة لنفس الطبقة النشطة. استنادًا إلى القياسات التجريبية على الأجهزة التجريبية، قمنا بضبطها على 1/6.
بناءً على النقطتين المذكورتين أعلاه، يمكن لـ AutoPipe موازنة أقسام خطوط الأنابيب وفقًا لأحجام المعلمات.على وجه التحديد، يستخدم AutoPipe خوارزمية جشعة لتخصيص الطبقات المجمدة والطبقات النشطة بحيث يمكن توزيع الطبقات الفرعية لمنطقة التسجيل بالتساوي على أجهزة وحدة معالجة الرسومات K.
الكود الزائف هو وظيفة load_balance() في الخوارزمية 1. يتم استخراج الطبقات المجمدة من النموذج الأصلي وحفظها في مثيل نموذج منفصل Ffrozen في الجهاز الأول من خط الأنابيب.
لاحظ أن خوارزمية التجزئة المستخدمة في هذه المقالة ليست الخيار الوحيد؛يعد PipeTransformer برنامجًا معياريًا ويمكن تشغيله بالاشتراك مع أي من البدائل.
ضغط الأنابيب
يساعد ضغط خط الأنابيب على تحرير وحدة معالجة الرسومات لاستيعاب المزيد من نسخ خط الأنابيب ويقلل من كمية الاتصالات بين الأجهزة بين الأقسام. لتحديد المدة التي يجب أن يستغرقها الضغط، يمكننا تقدير استهلاك الذاكرة لأكبر قسم بعد الضغط ثم مقارنته باستهلاك الذاكرة لأكبر قسم في خط الأنابيب في خطوة زمنية T=0.
لتجنب إنشاء ملف تعريف ذاكرة مكثف، تستخدم خوارزمية الضغط حجم المعلمة كوكيل لاستخدام ذاكرة التدريب. وبناءً على هذا التبسيط، فإن المبادئ التوجيهية لضغط خطوط الأنابيب هي كما يلي: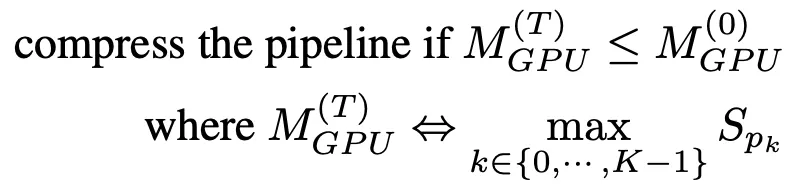
بمجرد استلام إشعار التجميد، سيحاول AutoPipe تقسيم طول الأنبوب K على 2 (على سبيل المثال، من 8 إلى 4، ثم 2). من خلال إدخال K/2، يمكن لخوارزمية الضغط التحقق مما إذا كانت نتيجة الضغط تلبي المعايير المذكورة في الصيغة (1).
يظهر الكود الزائف في الأسطر من 25 إلى 33 من الخوارزمية 1. لاحظ أن هذا الضغط يجعل التسريع ينمو بشكل كبير أثناء التدريب، مما يعني أنه إذا كان خادم وحدة معالجة الرسومات يحتوي على المزيد من وحدات معالجة الرسومات (على سبيل المثال، أكثر من 8)، فإن التسريع سيزداد بشكل أكبر. الشكل 7: فقاعة خط الأنابيب
الشكل 7: فقاعة خط الأنابيب
تمثل Fd وb وUd التحديثات الأمامية والخلفية والمحسنة لـ micro=batch b على الجهاز d، على التوالي.
يبلغ الحجم الإجمالي للفقاعة في كل تكرار K-1 مرات التكاليف الأمامية والخلفية لكل دفعة صغيرة.
بالإضافة إلى ذلك، يمكن لهذه التقنية أيضًا تسريع التدريب عن طريق تقليل حجم فقاعة خط الأنابيب. لتوضيح حجم الفقاعة في خط الأنابيب، يوضح الشكل 7 كيفية مرور 4 دفعات صغيرة عبر 4 خطوط أنابيب للأجهزة مع K=4.
بشكل عام، يبلغ حجم الفقاعة الإجمالي K-1 أضعاف التكلفة الأمامية والخلفية لكل دفعة صغيرة. ومن ثم، فمن الواضح أن خطوط الأنابيب الأقصر لها أحجام فقاعات أصغر.
العدد الديناميكي للدفعات الصغيرة
استخدمت أنظمة خطوط الأنابيب الموازية السابقة عددًا ثابتًا من الدفعات الصغيرة لكل دفعة صغيرة (M). توصي شركة GPipe بأن يكون M ≥ 4 x K، حيث أن K هو عدد الأقسام (طول خط الأنابيب). ومع ذلك، نظرًا لأن PipeTransformer يقوم بتكوين K بشكل ديناميكي، فقد وجدنا أن الحفاظ على M ثابتًا أثناء التدريب لا يعمل بشكل جيد.
بالإضافة إلى ذلك، عند التكامل مع DDP، تؤثر قيمة M أيضًا على كفاءة مزامنة تدرج DDP. نظرًا لأن DDP يجب أن ينتظر الدفعة الدقيقة الأخيرة لإكمال الحساب العكسي للمعلمة قبل مزامنة التدرج، فكلما كانت الدفعة الدقيقة أدق، كان التداخل بين الحساب والاتصال أصغر.
لذلك، بدلاً من استخدام قيمة ثابتة، يبحث PipeTransformer بشكل ديناميكي عن القيمة المثلى لـ M في الهجين لبيئة DDP من خلال تعداد قيم M في نطاق K-6K. بالنسبة لبيئة تدريب محددة، يلزم إكمال عملية إنشاء الملف الشخصي مرة واحدة فقط (انظر السطر 35 من الخوارزمية 1).
للحصول على الكود المصدر الكامل، يرجى الرجوع إلى
AUTODP: إنشاء المزيد من نسخ خطوط الأنابيب
نظرًا لأن AutoPipe يمكنه ضغط نفس خط الأنابيب في عدد أقل من وحدات معالجة الرسوميات، فيمكن لـ AutoDP إنشاء نسخ جديدة من خط الأنابيب تلقائيًا لزيادة عرض التوازي في البيانات.
ورغم بساطة مفهومها، فإن الاعتماد على التواصل والدولة أمر دقيق ويتطلب تصميماً دقيقاً.هناك ثلاثة تحديات رئيسية محتملة:
1. اتصالات DDP: يتطلب الاتصال الجماعي في PyTorch DDP عضوية ثابتة، مما يمنع خطوط الأنابيب الجديدة من الاتصال بالخطوط الموجودة؛
2. مزامنة الحالة: يجب أن تكون العملية التي تم تنشيطها حديثًا متوافقة مع خط الأنابيب الحالي من حيث إجراءات التدريب (مثل عدد العصور ومعدل التعلم) والوزن وحالات المُحسِّن وحدود الطبقة المجمدة ونطاق وحدة معالجة الرسومات في خط الأنابيب؛
3. إعادة توزيع مجموعة البيانات: ينبغي إعادة موازنة مجموعة البيانات لتتناسب مع العدد الديناميكي لخطوط الأنابيب. لا يؤدي هذا إلى تجنب المتأخرين فحسب، بل يضمن أيضًا أن تكون تدرجات جميع عمليات DDP متساوية الوزن.
الشكل 8: AutoDP: التوازي الديناميكي للبيانات مع المعلومات بين مجموعتي عمليات
ملاحظة: العمليات من 0 إلى 7 تنتمي إلى الجهاز 0، والعمليات من 8 إلى 15 تنتمي إلى الجهاز 1
ولمعالجة هذه التحديات، قمنا بإنشاء مجموعات عملية الاتصال المزدوجة لـ DDP. كما هو موضح في الشكل 8، فإن مجموعة عملية المعلومات (الأرجوانية) مسؤولة عن معلومات التحكم الخفيفة وتغطي جميع العمليات، بينما تحتوي مجموعة عملية التدريب النشطة (الصفراء) على العمليات النشطة فقط وتعمل كأداة للتواصل مع الموتر الثقيل أثناء التدريب.
مجموعة المعلومات ثابتة، في حين يتم تقسيم مجموعة التدريب وإعادة بنائها لتتناسب مع عملية النشاط. في T0، تكون العمليات 0 و8 فقط نشطة. أثناء الانتقال إلى T1، تقوم العملية 0 بتنشيط العمليتين 1 و9 (نسخ خط الأنابيب المضافة حديثًا) ومزامنة المعلومات الضرورية المذكورة أعلاه باستخدام مجموعات الرسائل.
وتشكل العمليات الأربع النشطة بعد ذلك مجموعة تدريب جديدة، تعمل على تكييف الاتصال الجماعي الثابت مع العضوية الديناميكية. لإعادة توزيع مجموعة البيانات، قمنا بتنفيذ متغير DistributedSampler الذي يضبط أخذ العينات من البيانات بسلاسة لتتناسب مع عدد النسخ المتماثلة للخطوط الأنابيب النشطة.
يساعد التصميم أعلاه على تقليل فقدان الاتصال في DDP. على وجه التحديد، عند الانتقال من T0 إلى T1، يمكن للعمليتين 0 و1 تدمير مثيل DDP الحالي، وستقوم العملية النشطة ببناء مجموعة تدريب DDP جديدة باستخدام نموذج خط الأنابيب المخزن مؤقتًا (يخزن AutoPipe النموذج المجمد والنموذج المخزن مؤقتًا بشكل منفصل).
لتحقيق العمليات المذكورة أعلاه، استخدمنا واجهات برمجة التطبيقات التالية:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# initialize the process group (this must be called in the initialization of PyTorch DDP)
dist.init_process_group(init_method='tcp://' + str(self.config.master_addr) + ':' +
str(self.config.master_port), backend=Backend.GLOO, rank=self.global_rank, world_size=self.world_size)
...
# create active process group (yellow color)
self.active_process_group = dist.new_group(ranks=self.active_ranks, backend=Backend.NCCL, timeout=timedelta(days=365))
...
# create message process group (yellow color)
self.comm_broadcast_group = dist.new_group(ranks=[i for i in range(self.world_size)], backend=Backend.GLOO, timeout=timedelta(days=365))
...
# create DDP-enabled model when the number of data-parallel workers is changed. Note:
# 1. The process group to be used for distributed data all-reduction.
If None, the default process group, which is created by torch.distributed.init_process_group, will be used.
In our case, we set it as self.active_process_group
# 2. device_ids should be set when the pipeline length = 1 (the model resides on a single CUDA device).
self.pipe_len = gpu_num_per_process
if gpu_num_per_process > 1:
model = DDP(model, process_group=self.active_process_group, find_unused_parameters=True)
else:
model = DDP(model, device_ids=[self.local_rank], process_group=self.active_process_group, find_unused_parameters=True)
# to broadcast message among processes, we use dist.broadcast_object_list
def dist_broadcast(object_list, src, group):
"""Broadcasts a given object to all parties."""
dist.broadcast_object_list(object_list, src, group=group)
return object_listبالنسبة للرمز، يرجى الرجوع إلى
القسم التجريبي
يقوم هذا القسم أولاً بتلخيص الإعداد التجريبي ثم يقوم بتقييم أداء PipeTransformer في مهام الرؤية الحاسوبية ومعالجة اللغة الطبيعية.
الأجهزة. تم إجراء التجارب على جهازين متطابقين متصلين بواسطة InfiniBand CX353A (جيجابايت/ثانية)، كل منهما مزود بـ 8 بطاقات رسومية NVIDIA Quadro RTX 5000 (ذاكرة معالجة رسومية 16 جيجابايت). يبلغ عرض النطاق الترددي من وحدة معالجة الرسومات إلى وحدة معالجة الرسومات داخل الجهاز (PCI 3.0، 16 مسارًا) 15.754 جيجابايت/ثانية.
ينجز. نحن نستخدم PyTorch Pipe ككتلة بناء. التعريف والتكوين والمرمزات المرتبطة بنموذج BERT كلها من HuggingFace 3.5.0. لقد قمنا بتنفيذ Vision Transformer باستخدام TensorFlow في PyTorch.
النماذج ومجموعات البيانات. استخدمت التجربة نموذجين تمثيليين للمحول في مجالات السيرة الذاتية ومعالجة اللغة الطبيعية: محول الرؤية (ViT) و BERT. يتم تطبيق ViT على مهمة تصنيف الصور، ويتم تهيئتها باستخدام الأوزان المدربة مسبقًا على ImageNet21K، وضبطها بدقة على ImageNet وCIFAR-100. يعمل BERT على مهمتين: تصنيف النص على مجموعة بيانات SST-2 من معيار تقييم فهم اللغة العامة (GLUE)، والإجابة الذكية على الأسئلة على مجموعة بيانات SQuAD v1.1 (Stanford Question Answering). تتكون مجموعة بيانات SQuAD v1.1 من 100000 زوج من الأسئلة والأجوبة التي تم جمعها جماعيًا.
خطة التدريب. تتطلب النماذج الكبيرة عادةً آلاف الأيام من وحدة معالجة الرسوميات (GPU) {\emph{eg}, GPT-3) إذا تم تدريبها من الصفر، لذا فإن ضبط المهام اللاحقة باستخدام النماذج المدربة مسبقًا أصبح اتجاهًا في مجالات CV وNLP. بالإضافة إلى ذلك، يعد PipeTransformer نظام تدريب معقدًا يتضمن مكونات أساسية متعددة. لذلك، بالنسبة لتطوير النظام وأبحاث الخوارزمية للإصدار الأول من PipeTransformer، فإنه ليس من المجدي من حيث التكلفة تطويره وتقييمه من الصفر باستخدام التدريب المسبق على نطاق واسع. لذلك، تركز التجارب المقدمة في هذا القسم على النماذج المدربة مسبقًا. لاحظ أنه نظرًا لأن بنية النموذج في التدريب المسبق والضبط الدقيق هي نفسها، فإن PipeTransformer يمكنه تلبية كلا المتطلبين. سنناقش نتائج التدريب المسبق في الملحق.
خط الأساس. تقوم التجارب في هذا القسم بمقارنة PipeTransformer مع أطر العمل الحديثة PyTorch Pipeline (تنفيذ PyTorch GPipe) و PyTorch DDP. نظرًا لأن هذه هي الورقة الأولى التي تدرس تجميد الطبقات لتسريع التدريب الموزع، فلا يوجد حل متوافق تمامًا حتى الآن.
المعلمات الفائقة. بالنسبة لمجموعات بيانات ImageNet وCIFAR-100، تم استخدام ViT-B/16 (12 طبقة محولة وحجم رقعة إدخال 16 × 16) في التجارب. بالنسبة لـ SQuAD 1.1، تم استخدام BERT-large-uncased (24 طبقة) في التجارب. يستخدم SST-2 قاعدة BERT غير المغلفة (12 طبقة). باستخدام تدريب PipeTransformer وViT وBERT، يمكن ضبط حجم الدفعة لكل خط أنابيب إلى حوالي 400 و64 على التوالي. بالنسبة للمعلمات الفائقة الأخرى (مثل العصر ومعدل التعلم وما إلى ذلك)، راجع الملحق.
تدريب التسارع الشامل
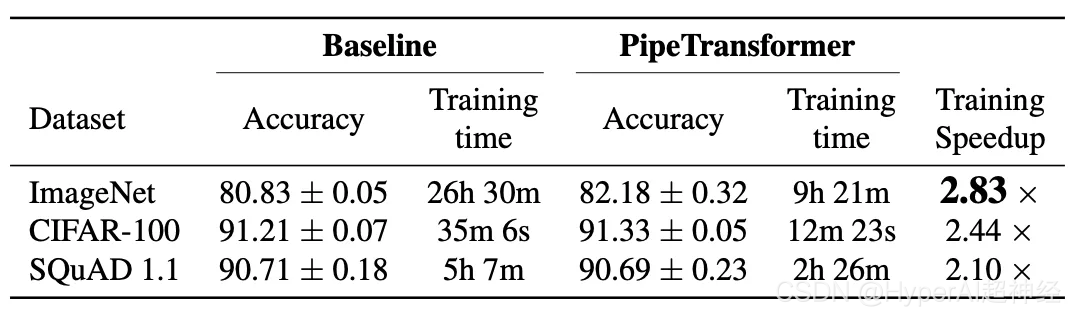
يوضح الجدول أعلاه ملخص النتائج التجريبية الإجمالية. لاحظ أن التسريع هنا يعتمد على قيمة محافظة(1/3)، يمكن لهذه القيمة تحقيق دقة مماثلة أو حتى أعلى. إذا كانت القيمة أ(2/5،1/2) يمكن تحقيق تسريع أعلى، ولكن مع خسارة طفيفة في الدقة. بالإضافة إلى ذلك، فإن BERT (24 طبقة) أكبر من ViT-B/16 (12 طبقة)، وبالتالي يتطلب المزيد من وقت الاتصال.
تحليل الأداء
انهيار التسريع
يعرض هذا القسم نتائج التقييم ويحلل أداء المكونات المختلفة في /AutoPipe.
لفهم فعالية هذه المكونات الأربعة وتأثيرها على سرعة التدريب، أجرينا تجارب بمجموعات مختلفة واستخدمنا معدل إنتاج عينات التدريب (العينات/الثانية) والتسريع كمقياس. وتظهر النتائج في الشكل 9.تتضمن النقاط الرئيسية المستفادة من النتائج التجريبية ما يلي:
1. التسريع الرئيسي هو نتيجة خط الأنابيب المرن الذي تم تنفيذه بواسطة AutoPipe و AutoDP؛
2. يتم تضخيم تأثير AutoCache بواسطة AutoDP؛
3. يتم إجراء تدريب التجميد بشكل مستقل دون أي تعديلات على النظام أو تباطؤ في التدريب.
ضبط أ في خوارزمية التجميد

الشكل 10: ضبط أ في خوارزمية التجميد
لقد أجرينا بعض التجارب لتوضيح كيفية تأثير تجميد الخوارزمية على سرعة التدريب. تظهر النتائج أنه كلما كان التجميد المفرط أكبر، كلما زادت سرعة التسارع، ولكن سيكون هناك انخفاض طفيف في الأداء. في المثال الموضح في الشكل 10، عندما تكون a=1/5، يكون أداء التدريب المجمد أفضل من التدريب العادي، مع نسبة تسريع تبلغ 2.04.
العدد الأمثل للقطع في خط الأنابيب المرن

الشكل 11: العدد الأمثل للقطع في خط الأنابيب المرن
نقوم بتحليل رقم الدفعة الدقيقة الأمثل M لأطوال مختلفة من الأنابيب K. تظهر النتائج في الشكل 11. كما نرى، يتغير الرقم الأمثل M وفقًا لذلك مع قيم مختلفة من K. عندما يكون M مختلفًا، تصبح فجوة الإنتاجية أكبر (كما هو موضح في الشكل عندما K = 8)، مما يؤكد أيضًا ضرورة استخدام ملف تعريف أمامي في خطوط الأنابيب المرنة.
فهم توقيت ذاكرة التخزين المؤقت

الشكل 12: توقيت ذاكرة التخزين المؤقت
لتقييم AutoCache، قمنا بمقارنة معدل إنتاج العينة لوظائف التدريب بدءًا من العصر 0 مع AutoCache (الخط الأزرق) وبدون AutoCache (الخط الأحمر).
يوضح الشكل 12 أن تمكين التخزين المؤقت في وقت مبكر جدًا قد يؤدي إلى إبطاء التدريب لأنه أكثر تكلفة من الانتشار الأمامي عبر عدد أقل من الطبقات المجمدة. بعد تجميد المزيد من الطبقات، أصبح أداء التنشيطات المخزنة مؤقتًا أفضل بشكل ملحوظ من التمريرة الأمامية المقابلة. لذلك، يستخدم AutoCache Profiler لتحديد الوقت المناسب لتمكين التخزين المؤقت.
في نظامنا، بالنسبة لـ ViT (12 طبقة)، يبدأ التخزين المؤقت من الطبقة المجمدة الثالثة؛ بالنسبة لـ BERT (24 طبقة)، يبدأ التخزين المؤقت من الطبقة المجمدة الخامسة.
تلخيص
تقدم هذه الورقة PipeTransformer، وهو حل شامل يجمع بين التوازي المرن لخطوط الأنابيب والتوازي مع البيانات للتدريب الموزع باستخدام واجهة برمجة التطبيقات الموزعة PyTorch.
على وجه التحديد، يمكن لـ PipeTransformer تجميد الطبقات في خط الأنابيب تدريجيًا، وحزم الطبقات النشطة المتبقية في عدد أقل من وحدات معالجة الرسوميات، وتفرع المزيد من نسخ خط الأنابيب لزيادة عرض البيانات الموازي. يُظهر التقييم على نماذج ViT وBERT أن PipeTransformer يحقق تسريعًا بمقدار 2.83x مقارنةً بخط الأساس المتطور دون أي فقدان في الدقة.








