Command Palette
Search for a command to run...
ينشر فريق جامعة تشجيانغ طريقة جديدة لتوليف العرض ثلاثي الأبعاد، وهي أفضل بكثير من NeRF وNV
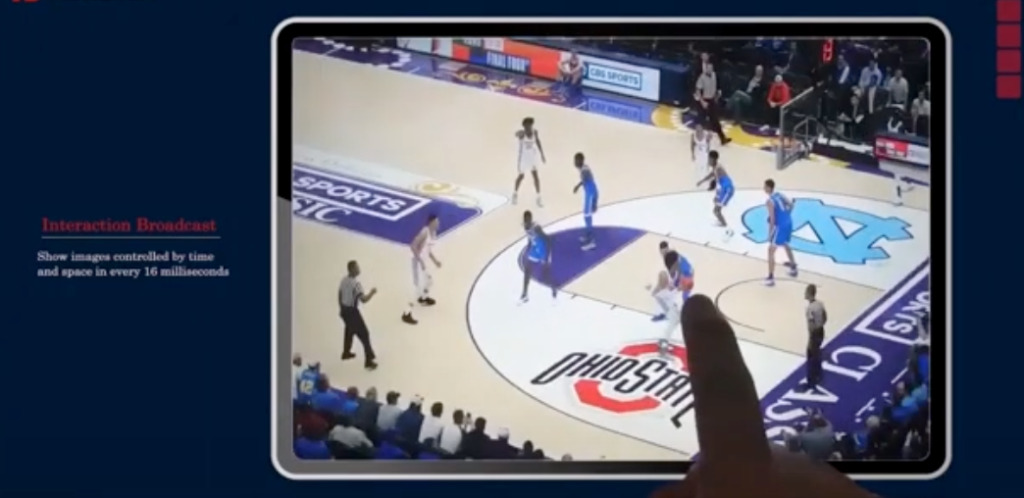
من خلال عدد قليل من مقاطع الفيديو من وجهات نظر مختلفة، يمكن إنشاء صورة كاملة للجسم البشري بزاوية 360 درجة دون أي نقاط عمياء. لا بد من القول أن قدرة الذكاء الاصطناعي على التخيل أصبحت أقوى بشكل متزايد. وقد تؤدي مثل هذه الأدوات إلى تحقيق اختراقات جديدة في صناعة السينما والتلفزيون، وتقديم البرامج الرياضية، وما إلى ذلك في المستقبل.
في المستقبل، قد تتغير الطريقة التي نشاهد بها الأفلام ومباريات كرة القدم والحفلات الموسيقية وما إلى ذلك بشكل كامل بفضل "فيديو وجهة النظر الحرة".
ربما لا تعرف ما هو "فيديو وجهة النظر المجانية"، ولكن يجب أن تكون قد جربت مقاطع فيديو الواقع الافتراضي أو الواقع المعزز أو لعبت ألعابًا ثلاثية الأبعاد. تندرج كل هذه ضمن فئة مقاطع الفيديو ذات وجهة النظر المجانية، وخصائصها هي:يمكن مشاهدته من أي زاوية، مما يوفر تجربة غامرة بالكامل.

كيف يمكن تصوير مثل هذا الفيديو؟ بشكل عام، تتطلب الطريقة التقليدية استخدام كاميرات متعددة للتصوير من زوايا مختلفة، ثم دمج مقاطع الفيديو من جميع الزوايا معًا.

ومع ذلك، تعتمد هذه الطريقة على كاميرات متعددة، وهي ليست مكلفة فحسب، بل إنها محدودة أيضًا بسبب بيئة موقع التصوير.
هناك طريقة أخرى للتخلص من هذه القيود.من خلال إدخال عدد قليل من اللقطات لجسم الإنسان الملتقطة من زوايا مختلفة، يمكن إنشاء رؤية ثلاثية الأبعاد جديدة بزاوية 360 درجة لجسم الإنسان.وهذه هي أحدث نتيجة نشرها مؤخرا باحثون من جامعة تشجيانغ.
في نهاية شهر ديسمبر، نشر الفريق ورقة بحثية جديدة على arxiv"الجسم العصبي: تمثيلات عصبية ضمنية مع رموز كامنة منظمة لتوليف رؤية جديدة للبشر الديناميكيين"، اقترح تمثيلًا جديدًا لجسم الإنسان Neural Body، باستخدام مقاطع فيديو متعددة المشاهد لتجميع وجهات نظر جديدة لأجسام بشرية ديناميكية ثلاثية الأبعاد. وقد أظهرت الاختبارات التجريبية أن هذه الطريقة متفوقة على الطرق السابقة الأخرى.
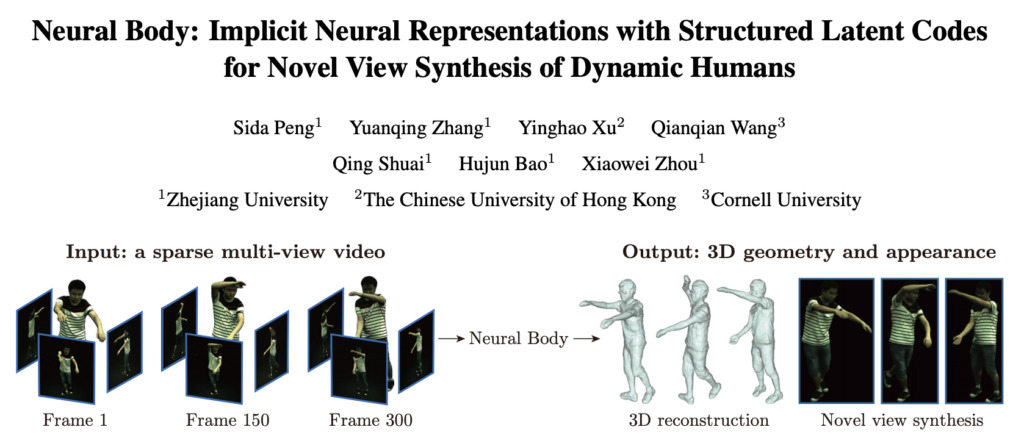
عنوان الورقة: https://arxiv.org/pdf/2012.15838.pdf
ومن الجدير بالذكر أن المؤلفين السبعة وراء هذه الورقة البحثية درسوا أو تخرجوا جميعًا من جامعة تشجيانغ، وهم من مختبر الدولة الرئيسي للتصميم بمساعدة الكمبيوتر والرسومات بجامعة تشجيانغ.ومن بينهم هوجون باو وشياووي تشو، وهما أستاذان في المختبر. بعد تخرجهما من الدراسات الجامعية، حصل كل من ينغهاو شو وتشيان تشيان وانغ على درجة الدكتوراه في الجامعة الصينية في هونج كونج وجامعة كورنيل على التوالي.
حتى مع كمية صغيرة من المواد، لا يزال بإمكانك إنشاء مناظر ثلاثية الأبعاد عالية الجودة
في الوقت الحاضر، سواء كان فيلمًا أو برنامجًا تلفزيونيًا أو حدثًا رياضيًا، فإن ما نراه هي صور تم التقاطها بكاميرا واحدة. إذا تمكنت من الحصول على "فيديو منظور مجاني" ورؤية ما تريد، فستكون بالتأكيد تجربة مثل الحصول على منظور الله.
في الواقع، كانت الذكاء الاصطناعي تدرس هذه المشكلة أيضًا في السنوات الأخيرة، وأنتجت حلولًا لتوليف العرض مثل NeRF وNeural Volumes (NV باختصار).
ومع ذلك، أظهرت الدراسات الحالية أن تعلم التمثيلات العصبية الضمنية للمشاهد ثلاثية الأبعاد يمكن أن يحقق جودة جيدة لتوليف العرض في ظل ظروف عرض الإدخال الكثيفة. ومع ذلك، إذا كانت وجهات النظر متناثرة للغاية، فإن التعلم التمثيلي سيكون في وضع سيئ.

ولذلك، من أجل حل هذه المشكلة الصعبة، اقترح فريق بحثي من جامعة تشجيانغ وجامعة هونج كونج الصينية وجامعة كورنيل الفكرة الرئيسية المتمثلة في دمج نتائج المراقبة في إطارات الفيديو.
واقترحت أحدث نتائج البحث التي توصل إليها الفريق ما يسمى بالجسم العصبي.هذا تمثيل جديد لجسم الإنسان يفترض أن التمثيلات العصبية التي تم تعلمها عبر إطارات مختلفة تشترك في نفس مجموعة الرموز الكامنة المثبتة على شبكة قابلة للتشوه بحيث يمكن دمج الملاحظات عبر الإطارات بشكل طبيعي.توفر الشبكة القابلة للتشوه أيضًا إرشادات هندسية للشبكة لتعلم التمثيلات ثلاثية الأبعاد بشكل أكثر فعالية.

أجرى الباحثون تجارب على مجموعة بيانات متعددة المشاهد تم جمعها حديثًا وأظهروا أن طريقتهم تتمتع بميزة كبيرة على الطرق السابقة من حيث جودة تجميع المشاهد.
وفي عرض توضيحي، أظهر الفريق قدرة طريقتهم على إعادة بناء الشخصيات المتحركة من مقاطع فيديو أحادية العين لأشخاص يقومون بأفعال مختلفة.

تقلل هذه الطريقة بشكل كبير من تكلفة تركيب الفيديو من وجهة نظر حرة، على الأقل من خلال توفير تكلفة الكاميرا، وبالتالي يكون لها تطبيق أوسع.
احصل على جسم عصبي في 5 خطوات
1. الكود الكامن المنظم
ومن أجل التحكم في الموضع المكاني والوضع البشري للرموز الكامنة، قام الفريق بربط هذه الرموز الكامنة بنموذج بشري قابل للتشوه (SMPL). SMPL هو نموذج قائم على قمة الجلد، والذي يتم تعريفه على أنه معلمات الشكل، ومعلمات الوضع، ووظائف تحويل الجسم الصلب بالنسبة لنظام إحداثيات SMPL.
يتم استخدام الكود الكامن مع الشبكة العصبية لتمثيل الهندسة المحلية ومظهر الشخص. إن تثبيت هذه الرموز على نموذج قابل للتشوه قادر على تمثيل شخص ديناميكي. باستخدام التمثيل الديناميكي للشخص، قام الفريق ببناء نموذج متغير كامن يقوم برسم نفس مجموعة الرموز الكامنة في مجالات ضمنية من الكثافة واللون عبر الإطارات، مما يؤدي إلى دمج الملاحظات بشكل طبيعي.
2. انتشار الكود
نظرًا لأن الرموز الكامنة المنظمة متناثرة في الفضاء ثلاثي الأبعاد، فإن الاستيفاء المباشر للرموز الكامنة سيؤدي إلى متجهات صفرية لمعظم النقاط ثلاثية الأبعاد. ولمعالجة هذه المشكلة، قام الفريق بنشر الكود الكامن المحدد على السطح في الفضاء الثلاثي الأبعاد القريب.
نظرًا لأن انتشار الكود لا ينبغي أن يتأثر بموقع واتجاه الشخص في نظام إحداثيات العالم، فإنهم يقومون بتحويل موضع الكود إلى نظام إحداثيات SMPL.
كما يعمل نشر التعليمات البرمجية على تجميع المعلومات العالمية والمحلية للرموز الكامنة المنظمة، مما يساعد على تعلم المجال الضمني.
3. انحدار الكثافة واللون
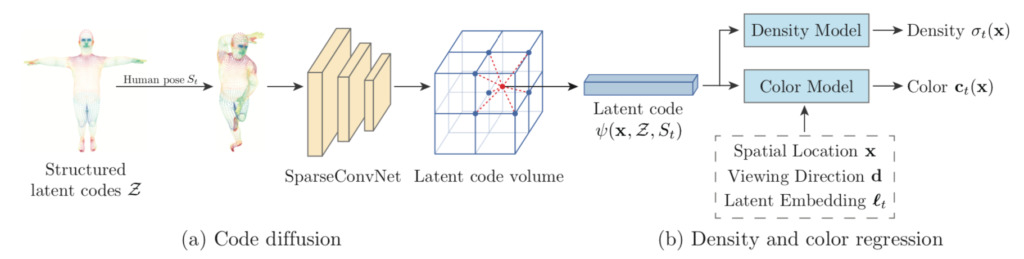
توصل فريق البحث إلى أن العوامل المتغيرة مع الزمن تؤثر على مظهر جسم الإنسان، مثل الإضاءة الثانوية والتظليل الذاتي. وباستخدام جهاز فك التشفير التلقائي، قام الفريق بتعيين إطار تضمين كامن t لكل إطار فيديو لتشفير عوامل التباين الزمني.
4. عرض الحجم
من خلال وجهة نظر معينة، استخدم الفريق تقنية عرض الحجم الكلاسيكية (المعروفة أيضًا باسم العرض المجسم) لتقديم الجسم العصبي إلى صورة ثنائية الأبعاد.
يتم بعد ذلك تقدير حدود المشهد استنادًا إلى نموذج SMPL، ثم يتنبأ Neural Body بكثافة الحجم ولون هذه النقاط.
بناءً على عرض الحجم، يتم تحسين النموذج عن طريق مقارنة الصورة المقدمة بالصورة المرصودة.
5. التدريب
بالمقارنة مع طرق إعادة البناء المعتمدة على الإطار، تستخدم هذه الطريقة جميع الصور في الفيديو لتحسين النموذج وتحتوي على مزيد من المعلومات لاستعادة الهيكل ثلاثي الأبعاد.
بالإضافة إلى ذلك، استخدم الفريق مُحسِّن Adam لتدريب Neural Body. تم إجراء التدريب على أربع وحدات معالجة رسومية 2080 Ti. بالنسبة لمقطع فيديو مكون من أربعة مشاهد بإجمالي 300 إطار، يستغرق التدريب عادةً حوالي 14 ساعة.
بعد الخطوات الخمس المذكورة أعلاه، يصبح Neural Body قادرًا على تحقيق تركيب فيديو مجاني يعتمد على عدد قليل من المشاهدات، وبالمقارنة مع الطرق الأخرى، فإن التأثير أفضل بشكل ملحوظ من الطريقة السابقة.
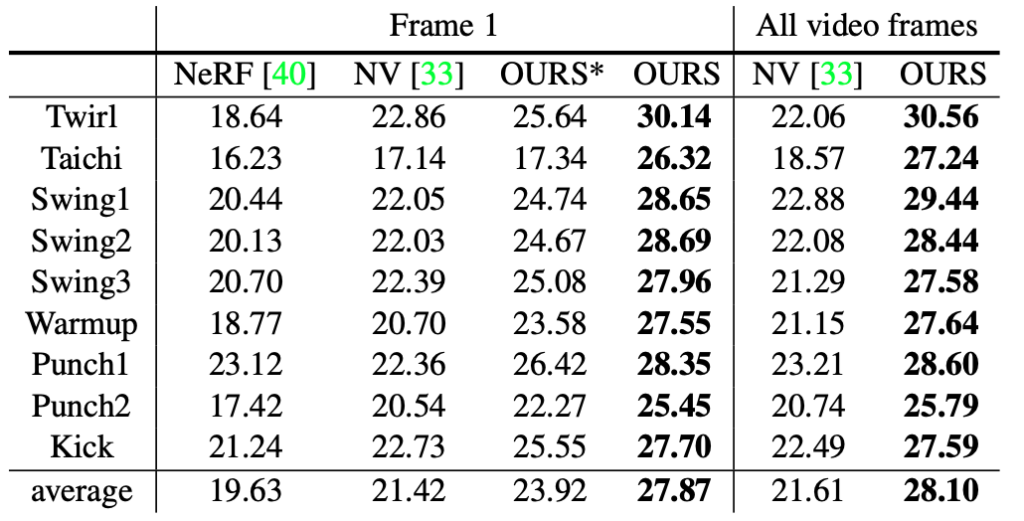
ملاحظة: "OURS*" و"OURS" تمثل نتائج التدريب على إطار فيديو واحد فقط وعلى أربعة إطارات فيديو على التوالي)
وتجعل تقنية الذكاء الاصطناعي التي تملأ الدماغ من السهل تحقيق تأثيرات ثلاثية الأبعاد، ولا تقتصر تطبيقاتها على صناعة السينما والتلفزيون والأحداث الرياضية الحية. بالنسبة لمطوري الألعاب ومدربي اللياقة البدنية ومقدمي الإعلانات ثلاثية الأبعاد وما إلى ذلك، فهي أداة يمكنها تحسين كفاءة العمل وفعاليته بشكل كبير.

الصفحة الرئيسية للمشروع:








