Command Palette
Search for a command to run...
أطلقوا سراح الفنان الأصلي! يستخدم Wav2Lip الذكاء الاصطناعي للاستماع إلى الموسيقى ومزامنة حركات شفاه الشخصيات

"نظرا لصدقه"لقد أصبح هذا غير فعال في مواجهة تكنولوجيا الذكاء الاصطناعي. تظهر تقنيات تغيير الوجه ومزامنة الشفاه بشكل لا نهاية له، كما أصبحت التأثيرات أكثر واقعية. اليوم سوف نقدم واف تو ليب يحتاج النموذج فقط إلى مقطع فيديو أصلي وصوت مستهدف لدمجهما في واحد.
وفي السنوات الأخيرة، حصدت أفلام الرسوم المتحركة في هوليوود مراراً وتكراراً أكثر من مليار دولار في شباك التذاكر، مثل "زوتوبيا" و"فروزن"، وكلها ذات جودة ممتازة.إذا أخذنا حركات الشفاه كمثال فقط، فهي دقيقة للغاية، وحركات الشفاه للشخصيات المتحركة متطابقة تقريبًا مع حركات الشفاه للأشخاص الحقيقيين.
ولتحقيق مثل هذا التأثير، هناك حاجة إلى عملية معقدة للغاية، والتي تتطلب قدرًا هائلاً من القوى البشرية والموارد المادية. لذلك، من أجل توفير التكاليف، يستخدم العديد من منتجي الرسوم المتحركة حركات شفاه بسيطة نسبيًا فقط.
والآن، تعمل الذكاء الاصطناعي على تسهيل عمل الفنانين المفاهيميين. نشر فريق من جامعة حيدر أباد في الهند وجامعة باث في المملكة المتحدة ورقة بحثية في ACM MM2020 هذا العام"خبير مزامنة الشفاه هو كل ما تحتاجه لتوليد الكلام إلى الشفاه في البرية"،تم اقتراح نموذج الذكاء الاصطناعي المسمى Wav2Lip، والذي يحتاج فقط إلى مقطع فيديو لشخص وصوت مستهدف لدمج الاثنين في واحد، مما يجعل الاثنين يعملان معًا بسلاسة.
تقنية مزامنة الشفاه Wav2Lip، التأثير رائع للغاية
هناك في الواقع العديد من التقنيات لمزامنة الشفاه. حتى قبل ظهور تقنية التعلم العميق، كانت هناك بعض التقنيات التي تطابق شكل شفاه الشخصية مع إشارة الصوت الفعلية.
ولكن Wav2Lip يظهر مزايا مطلقة بين جميع الطرق. تعتمد الطرق الأخرى الموجودة بشكل أساسي على الصور الثابتة لإخراج مقاطع فيديو متزامنة مع الشفاه تتوافق مع الصوت المستهدف، ولكن مزامنة الشفاه غالبًا لا تعمل بشكل جيد مع الشخصيات الديناميكية المتحدثة.
يمكن لبرنامج Wav2Lip إجراء تحويل الشفاه مباشرة على مقاطع الفيديو الديناميكية وإخراج نتائج الفيديو التي تتوافق مع الصوت المستهدف.
بالإضافة إلى ذلك، لا تتوفر مقاطع الفيديو فحسب، بل تتوفر أيضًا مزامنة الشفاه مع الصور المتحركة، لذا سيتم إثراء حزم الرموز التعبيرية الخاصة بك من الآن فصاعدًا!

أظهر التقييم اليدويبالمقارنة مع الطرق الحالية، فإن مقاطع الفيديو التي تم إنشاؤها بواسطة Wav2Lip تتفوق على الطرق الحالية بنسبة تزيد عن 90% من الوقت.
ما مدى فعالية النموذج؟ أجرى سوبر نيرو بعض الاختبارات. يُظهر الفيديو التالي تأثير تشغيل العرض التوضيحي الرسمي. المواد المدخلة هي مواد الاختبار المقدمة من قبل المسؤول، بالإضافة إلى مواد الاختبار باللغتين الصينية والإنجليزية التي اختارتها Super Neural Network.
الشخصيات في مدخل الفيديو الأصلي لا تتحدث
من خلال تشغيل نموذج الذكاء الاصطناعي، يتم مزامنة شكل شفاه الشخصية مع الصوت المدخل
يمكننا أن نرى أن التأثير مثالي في فيديو الرسوم المتحركة للعرض التوضيحي الرسمي. في اختبار الشخص الحقيقي الفائق العصبي، وبصرف النظر عن التشوه الطفيف واهتزاز الشفاه، فإن تأثير مزامنة الشفاه بشكل عام لا يزال دقيقًا نسبيًا.
تم إصدار البرنامج التعليمي، تعلم في ثلاث دقائق
بعد رؤية هذا، هل أنت أيضًا حريص على تجربته؟ إذا كانت لديك بالفعل فكرة جريئة، فلماذا لا تبدأ الآن؟
حاليًا، تم فتح المشروع على GitHub، ويقدم المؤلف عروضًا تفاعلية، ودفاتر Colab، ورمز تدريب كامل، ورمز استنتاج، ونماذج مدربة مسبقًا، ودروس تعليمية.
تفاصيل المشروع هي كما يلي:
اسم المشروع:Wav2Lip
عنوان GitHub:
https://github.com/Rudrabha/Wav2Lip
بيئة تشغيل المشروع:
- اللغة: بايثون 3.6+
- برنامج معالجة الفيديو: ffmpeg
تنزيل نموذج اكتشاف الوجه المدرب مسبقًا:
https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth
بالإضافة إلى إعداد البيئة المذكورة أعلاه، تحتاج أيضًا إلى تنزيل وتثبيت حزم البرامج التالية:
- ليبروسا==0.7.0
- numpy==1.17.1
- opencv-contrib-python>=4.2.0.34
- opencv-python==4.1.0.25
- tensorflow==1.12.0
- شعلة==1.1.0
- تورش فيجن==0.3.0
- tqdm==4.45.0
- رقم ==0.48
ومع ذلك، ليس عليك الاستعداد لهذه الإجراءات المرهقة.كل ما عليك فعله هو إعداد صورة/فيديو لشخص (شخص CGI مناسب أيضًا) + صوت (الصوت الاصطناعي مناسب أيضًا).يمكنك تشغيله بنقرة واحدة فقط على منصة خدمة الحاويات الخاصة بقوة الحوسبة للتعلم الآلي المحلية.
منفذ:https://openbayes.com/console/openbayes/containers/EiBlCZyh7k7
توفر المنصة حاليًا أيضًا وقتًا مجانيًا لاستخدام vGPU كل أسبوع، حتى يتمكن الجميع من إكمال البرنامج التعليمي بسهولة.
يحتوي النموذج على ثلاثة أوزان: Wav2Lip، وWav2Lip+GAN، وExpert Discriminator. ومن بين هذه الطرق، فإن تأثيرات الطريقتين الأخيرتين أفضل بكثير من استخدام نموذج Wav2Lip وحده. الأوزان المستخدمة في هذا البرنامج التعليمي هي Wav2Lip+GAN.
ويؤكد مؤلفو النموذج أنيجب استخدام جميع نتائج الكود مفتوح المصدر فقط لأغراض البحث/الأكاديمية/الشخصية،تم تدريب النموذج على أساس مجموعة البيانات LRS2 (جمل قراءة الشفاه 2)، لذا فإن أي شكل من أشكال الاستخدام التجاري محظور تمامًا.
لتجنب إساءة استخدام التكنولوجيا، يوصي الباحثون بشدة أيضًا بوضع علامة على أي محتوى تم إنشاؤه باستخدام كود Wav2Lip ونماذجه على أنه مصطنع.
التكنولوجيا الرئيسية وراء ذلك: تمييز مزامنة الشفاه
كيف يستمع Wav2Lip إلى الصوت ويقوم بمزامنة الشفاه بدقة؟
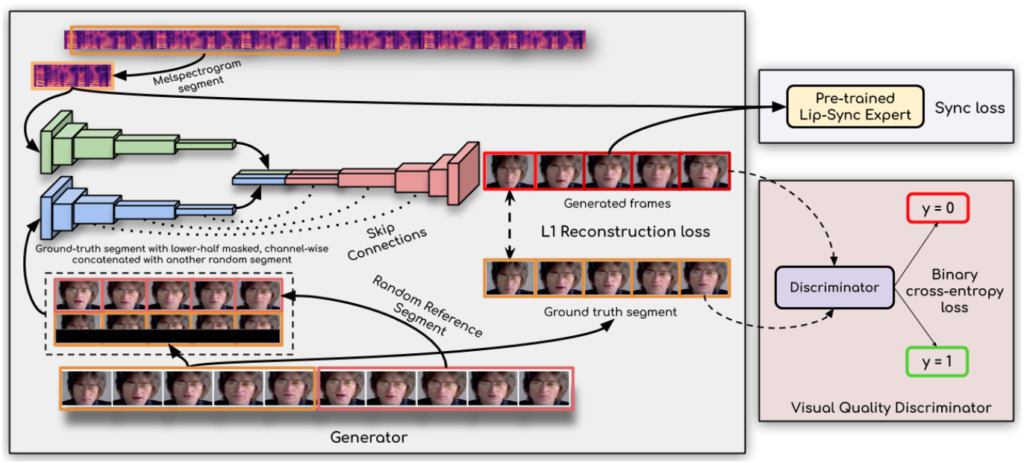
ويقال أن مفتاح تحقيق الاختراق هو:استخدم الباحثون جهاز تمييز مزامنة الشفاه،يؤدي هذا إلى إجبار المولد على إنتاج حركات شفاه دقيقة وواقعية بشكل مستمر.
بالإضافة إلى ذلك، تعمل هذه الدراسة على تحسين الجودة البصرية من خلال استخدام إطارات متعددة متتالية بدلاً من إطار واحد في المميز واستخدام فقدان الجودة البصرية (بدلاً من مجرد فقدان التباين) لتفسير الارتباطات الزمنية.
وقال الباحثون:يعد نموذج Wav2Lip الخاص بهم عالميًا تقريبًا، ويمكن تطبيقه على أي وجه، وأي صوت، وأي لغة، ويمكنه تحقيق دقة عالية لأي مقطع فيديو.يمكن دمجه بسلاسة مع الفيديو الأصلي، ويمكن استخدامه أيضًا لتحويل الوجوه المتحركة، كما يمكن استيراد الكلام المركب أيضًا.
من المحتمل أن هذه القطعة الأثرية قد تخلق موجة أخرى من مقاطع الفيديو للأشباح...
عنوان الورقة:
عنوان العرض التوضيحي:
https://bhaasha.iiit.ac.in/lipsync/
-- زيادة--








