Command Palette
Search for a command to run...
تحتوي على ما يقرب من 200000 كتاب، مجموعة بيانات التدريب على مستوى OpenAI متاحة عبر الإنترنت

هل تريد أيضًا تدريب نموذج GPT قوي مثل OpenAI، ولكنك تعاني من عدم وجود مجموعات بيانات تدريبية كافية؟ قام أحد مستخدمي الإنترنت في مجتمع Reddit مؤخرًا برفع مجموعة بيانات نصية عادية تحتوي على ما يقرب من 200 ألف كتاب. إن تدريب نموذج GPT من الدرجة الأولى لم يعد مجرد حلم.
في الآونة الأخيرة، ظهرت مشاركة موارد ساخنة في مجتمع التعلم الآلي "مجموعة بيانات مكونة من 196,640 كتابًا نصيًا عاديًا لتدريب نماذج اللغات الكبيرة مثل GPT"أثار نقاشا حادا.
تحتوي مجموعة البيانات هذه على روابط تنزيل لجميع مجموعات النصوص الكبيرة اعتبارًا من سبتمبر 2020. بالإضافة إلى ذلك، تحتوي على النص العادي لجميع الكتب الموجودة في Bibliotik (مكتبة موارد الكتب عبر الإنترنت)، بالإضافة إلى الكثير من التعليمات البرمجية للتدريب.
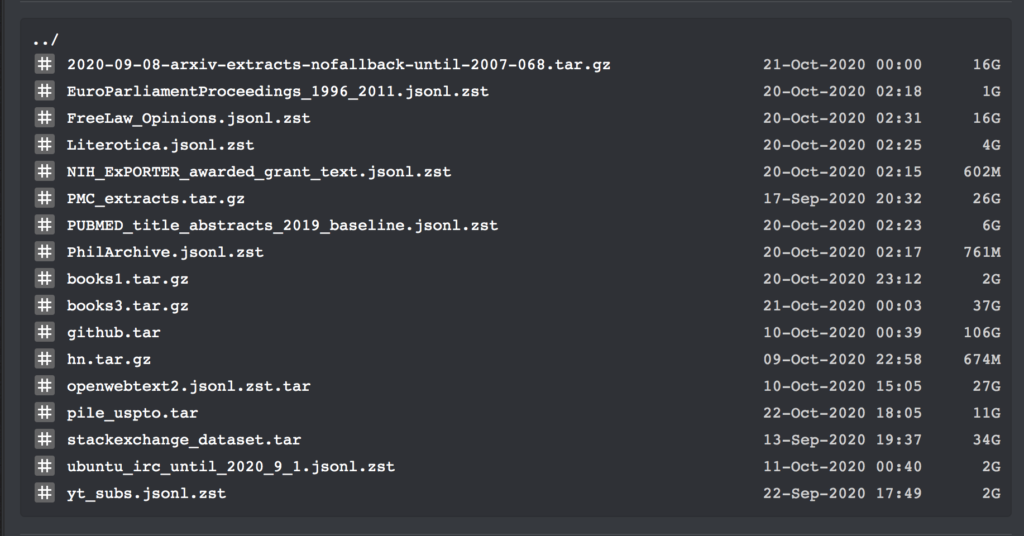
بالأمس فقط، أصدر مستخدم الإنترنت Shawn Presser مجموعة من مجموعات البيانات النصية العادية في مجتمع التعلم الآلي على Reddit، والتي تلقت إشادة بالإجماع.
تحتوي مجموعات البيانات هذه على إجمالي 196,640 مجلدًا من بيانات النص العادي، والتي يمكن استخدامها لتدريب نماذج اللغة الكبيرة مثل GPT.
نظرًا لأن مجموعة البيانات هذه تحتوي على مجموعات بيانات متعددة وأكواد تدريب، فلن ندخل في التفاصيل هنا. سنقوم فقط بإدراج المعلومات المحددة لمجموعات البيانات books1 و books3:
مجموعة بيانات نص عادي للكتاب
تم نشره بواسطة: شون بريسر
الكمية المتضمنة:الكتب1: 1800 كتابًا؛ الكتاب 3: 196640 كتابًا
تنسيق البيانات:تنسيق txt
حجم البيانات:الكتب1: 2.2 جيجابايت؛ الكتب 3: 37 جيجابايت
وقت التحديث:أكتوبر 2020
عنوان التنزيل:https://orion.hyper.ai/datasets/13642
وفقًا لمنظم مجموعة البيانات شون بريسير، فإن جودة هذه المجموعات من البيانات عالية جدًا. استغرق الأمر منه حوالي أسبوع لإصلاح البرنامج النصي epub2txt لمجموعة البيانات books1 وحدها.
وبالإضافة إلى ذلك، فقد ذكر أيضًا،يبدو أن مجموعة البيانات books3 تشبه مجموعة البيانات الغامضة "books2" من ورقة OpenAI.ومع ذلك، نظرًا لأن OpenAI لم تقدم معلومات مفصلة حول هذا الأمر، فمن المستحيل فهم أي اختلافات بين الاثنين.
ومع ذلك، في رأيه، هذه المجموعة من البيانات قريبة للغاية من مجموعة بيانات التدريب الخاصة بـ GPT-3. وباستخدامها، فإن الخطوة التالية هي تدريب نموذج لغة معالجة اللغة الطبيعية (NLP) الذي يمكن مقارنته بـ GPT-3. بالطبع، هناك شرط واحد: يجب عليك أيضًا إعداد عدد كافٍ من وحدات معالجة الرسوميات.

وفقا للمقدمة،تحتوي مجموعة البيانات books1 على 1800 كتاب، كلها من مجموعة النصوص الكبيرة BookCorpus.وتشمل هذه: الشعر، والروايات، وما إلى ذلك.
على سبيل المثال، "ظلال الرمادي: نوار، مدينة يكتنفها الظلام" للكاتبة الأمريكية كريستي لين هيغينز، و"مسرح الحيوان" لبنجامين بروك، و"أمريكا واحد" لتي. آي. وايد.
يتم دعم GPT-3 القوي من خلال مجموعة بيانات التدريب
الأصدقاء المهتمون بمجال معالجة اللغة الطبيعية يعرفون أنه في مايو/أيار من هذا العام، جذب نموذج معالجة اللغة الطبيعية GPT-3، الذي بنته شركة OpenAI بتكلفة ضخمة، اهتمامًا كبيرًا في الصناعة بقدرته المذهلة على توليد النصوص، وظل شائعًا منذ ذلك الحين.
لا يستطيع GPT-3 الإجابة على الأسئلة والترجمة وكتابة المقالات بشكل أفضل فحسب، بل يتمتع أيضًا ببعض قدرات الحساب الرياضي. والسبب وراء امتلاكه لهذه القدرات القوية لا ينفصل عن مجموعة البيانات التدريبية الضخمة التي تقف وراءه.
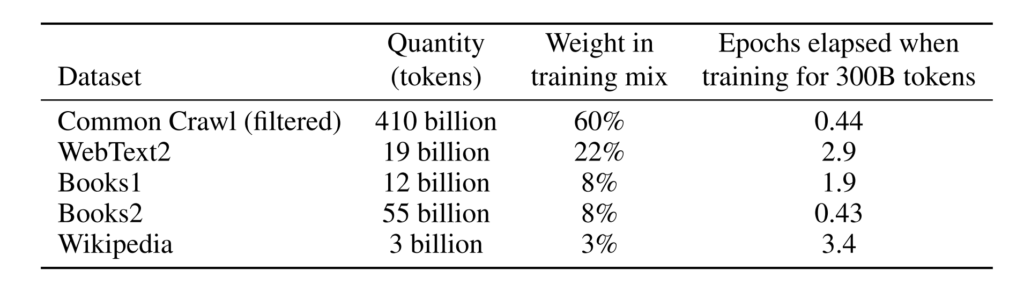
وفقا للمقدمة،مجموعة بيانات التدريب التي يستخدمها GPT-3 كبيرة جدًا. يعتمد على مجموعة بيانات CommonCrawl التي تحتوي على ما يقرب من تريليون كلمة ونص ويب وبيانات وويكيبيديا وبيانات أخرى. أكبر مجموعة بيانات تستخدمها لديها سعة 45 تيرابايت قبل المعالجة.كما وصلت تكاليف تدريبها إلى مبلغ مذهل قدره 12 مليون دولار أميركي.
تجعل مجموعات بيانات التدريب الأكبر ومعلمات النموذج الأكثر شيوعًا GPT-3 متقدمًا كثيرًا في نماذج معالجة اللغة الطبيعية.
ومع ذلك، بالنسبة للمطورين العاديين، إذا أرادوا تدريب نموذج لغة من الدرجة الأولى، ناهيك عن تكلفة التدريب العالية، فسوف يعلقون في خطوة تدريب مجموعة البيانات.
ولذلك فإن مجموعة البيانات التي جلبها شون بريسير حلت هذه المشكلة بلا شك، وقال بعض مستخدمي الإنترنت إنهم وفروا تكاليف ضخمة من خلال هذا العمل.
لقد نقلت شركة Super Neuro الآن مجموعة بيانات الكتب 1 إلى https://orion.hyper.ai،ابحث عن الكلمة الرئيسية "كتاب" أو "نص"، أو انقر فوق النص الأصلي للحصول على مجموعة البيانات.
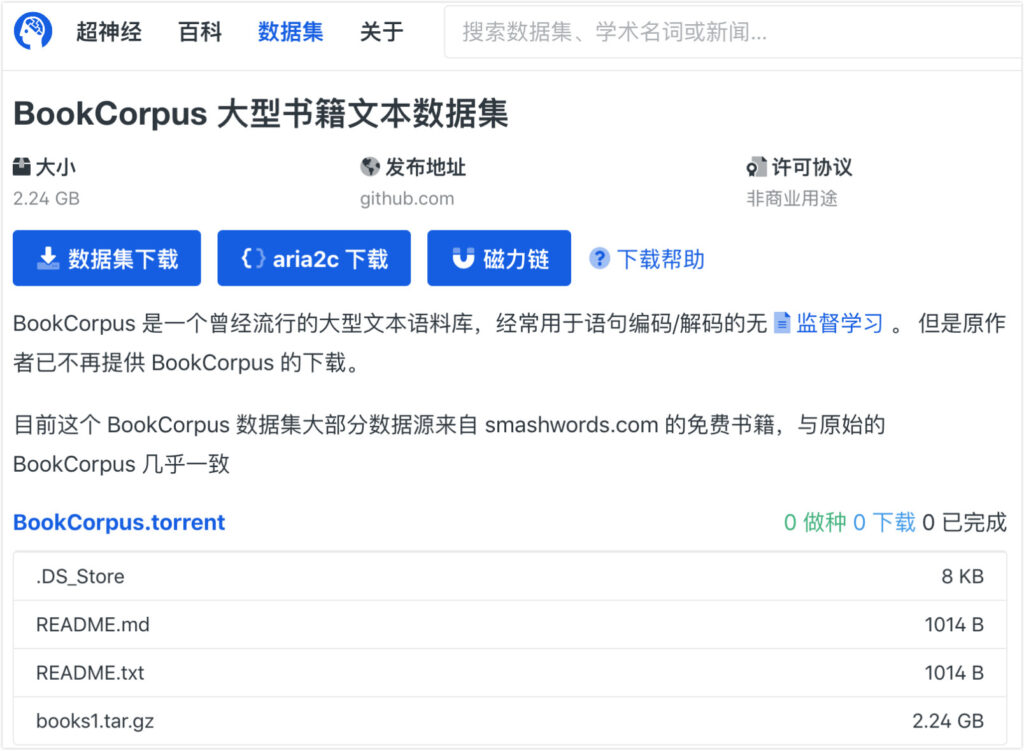
يمكن الحصول على مجموعات البيانات الأخرى من الروابط التالية:
تنزيل عنوان مجموعة بيانات الكتب3:
https://the-eye.eu/public/AI/pile_preliminary_components/books3.tar.gz
عنوان تنزيل كود التدريب:
https://the-eye.eu/public/AI/pile_preliminary_components/github.tar
المنشور الأصلي على Reddit:https://www.reddit.com/r/MachineLearning/comments/ji7y06/p_dataset_of_196640_books_in_plain_text_for/
-- زيادة--








