Command Palette
Search for a command to run...
استرجاع المعلومات، تخطيط المسار، التجارة الإلكترونية، ما هي ساحات المعارك في KDD؟

تنطلق فعاليات مؤتمر KDD 2020، المؤتمر الدولي الأبرز في مجال استخراج البيانات، الأسبوع المقبل. من بين 2035 ورقة بحثية تم تقديمها هذا العام، تم قبول 338 ورقة. ومن بين هذه الشركات، حققت شركات التكنولوجيا المحلية العملاقة مثل BAT، وDidi، وHuawei أداءً جيدًا.
المؤتمر الدولي السنوي لاستخراج البيانات واكتشاف المعرفة ACM SIGKDD 2020 (مؤتمر اكتشاف المعرفة واستخراج البيانات، المشار إليه باسم KDD)،ستقام عبر الإنترنت من 23 إلى 27 أغسطس.

مع تطور تكنولوجيا قواعد البيانات والتراكم المستمر للبيانات، تلقى مجال استخراج البيانات المزيد والمزيد من الاهتمام.
كما شهد عدد الطلبات المقدمة إلى KDD في السنوات الأخيرة نموًا بمعدل ملحوظ، من 1115 في عام 2016 إلى 2035 هذا العام. وفي هذه الأوراق، أصبحت مساهمات الشعب الصيني أكبر بشكل متزايد وكانت النتائج مثيرة للإعجاب للغاية.
KDD في عامه السادس والعشرين، وتتزايد قوة البحث العلمي للشعب الصيني عامًا بعد عام
بدأت KDD في عام 1995 وتقام سنويًا من قبل اللجنة الخاصة التابعة لـ ACM لتعدين البيانات واكتشاف المعرفة (SIGKDD).تم التوصية به من قبل CCF (اتحاد الكمبيوتر الصيني) باعتباره مؤتمرًا دوليًا من الفئة A.ويُعرف باسم "كأس العالم" في مجال استخراج البيانات.
باعتبارها المؤتمر الدولي الأعلى مستوى في مجال استخراج البيانات في العالم، تشتهر KDD بمعدل قبول الأوراق الصارم، حيث لا يتجاوز معدل القبول السنوي 20%، وهذا العام ليس استثناءً.
في 25 مايو، أعلن مؤتمر KDD 2020 رسميًا عن الأوراق المقبولة.وفي هذا العام، تم تقديم ما مجموعه 1279 ورقة بحثية إلى مسار البحث (أوراق أكاديمية لمجتمع البحث)، وتم قبول 216 ورقة، وبالتالي بلغ معدل القبول 16.8%.
تم تقديم 756 ورقة بحثية لمسار علوم البيانات التطبيقية (المسار العملي للصناعة).تم قبول 121 ورقة بحثية، بمعدل قبول 16%.
هذا العام هو العام السادس والعشرون لـ KDD. وفقًا للإحصائيات المتعلقة بعدد الأوراق المنشورة والجوائز التي فازوا بها، زادت مشاركة الصينيين في KDD عامًا بعد عام في السنوات الأخيرة، وأصبح أداؤهم أقوى وأقوى، وتم اختيار المزيد والمزيد من الأوراق، وفازوا بالعديد من الجوائز.
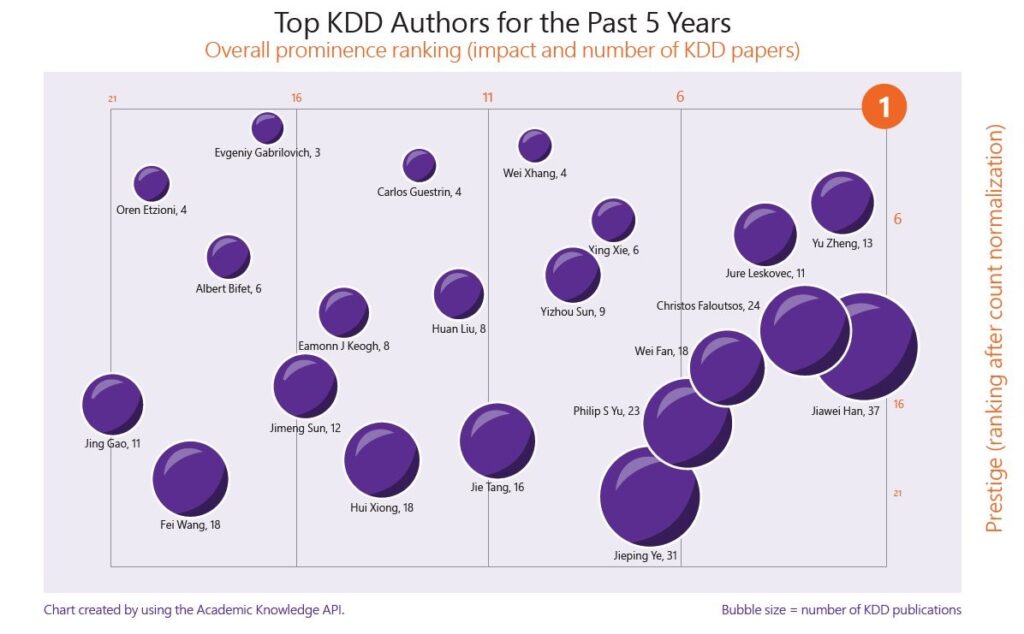
في السنوات الأخيرة، أصبحت إنجازات شركات التكنولوجيا المحلية الكبرى في KDD مثيرة للإعجاب بشكل متزايد.
وفقًا للإحصاءات، نشرت شركات BAT الرئيسية الثلاث ما مجموعه 12 مقالاً في عام 2018. هذا العام، نشرت Alibaba وحدها 25 ورقة بحثية، ونشرت Tencent 10 أوراق بحثية، ونشرت Baidu 9 أوراق بحثية، ونشرت Didi وHuawei وJD.com 6 أوراق بحثية لكل منها.
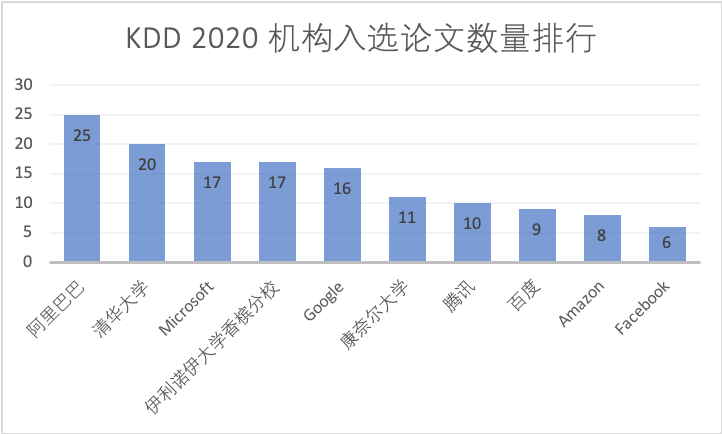
KDD 2020: أين ساحة المعركة للشركات الكبرى؟
لقد قمنا بفرز الأوراق المقبولة من الشركات المحلية الكبرى حسب سيناريوهات التطبيق حتى يتمكن الجميع من التعلم والرجوع إليها. وقد تم نشر بعض هذه الأوراق على arXiv، لذا يمكنك إلقاء نظرة سريعة عليها.
استرجاع المعلومات 《استخراج الميزات المميزة لتوصيات تاوباو》

الوحدة: علي بابا
ملخص:تلعب الميزات دورًا مهمًا في مهام التنبؤ بالتجارة الإلكترونية. لضمان التناسق بين التدريب غير المتصل بالإنترنت والخدمة عبر الإنترنت، فإننا عادةً ما نستخدم نفس الميزات لكليهما. ومع ذلك، فإن هذا الاتساق يتجاهل بعض السمات المميزة. على سبيل المثال، توفر ميزات مثل وقت البقاء على صفحة تفاصيل المنتج معلومات عند تقدير معدل التحويل (CVR)، وهو احتمالية قيام المستخدم بشراء المنتج بعد النقر فوقه. ومع ذلك، ينبغي إجراء تنبؤات CVR عبر الإنترنت قبل حدوث النقر.نقوم بتعريف الميزات التمييزية ولكن لا يمكن استخدامها في التدريب إلا كميزات مميزة. استنادًا إلى تقنية التقطير لسد الفجوة بين التدريب والاستدلال، يقترح هذا البحث خوارزمية تجزئة الميزة (PFD).أجرينا تجارب على مهمتين أساسيتين للتنبؤ بتوصيات تاوباو، وهما معدل النقر للتصنيف الخشن ومعدل التحويل للتصنيف الدقيق. من خلال استخراج الميزات التفاعلية المحظورة أثناء تقديم CTR والميزات اللاحقة لـ CVR، نحقق تحسينات كبيرة على خطوط الأساس القوية الخاصة بهم. أثناء اختبار A/B عبر الإنترنت، تحسنت Click Metrics بمقدار +5.0% في مهمة CTR. في مهمة CVR، تم تحسين مقياس التحويل بمقدار 2.3%. علاوة على ذلك، من خلال معالجة العديد من القضايا المتعلقة بتدريب PFD، نحصل على سرعة تدريب مماثلة كأساس دون أي تقطير.
عنوان الورقة:
https://arxiv.org/abs/1907.05171
استرجاع المعلومات 《إطار عمل التوصية متعدد المصالح القابل للتحكم》

الوحدة: علي بابا
ملخص:في السنوات الأخيرة، مع التطور السريع لتكنولوجيا التعلم العميق، تم استخدام الشبكات العصبية على نطاق واسع في أنظمة توصية التجارة الإلكترونية. لقد قمنا بصياغة مشكلة توصية نظام التوصية كمشكلة توصية متسلسلة، بهدف التنبؤ بالعنصر التالي الذي من المحتمل أن يتفاعل معه المستخدم. عادةً ما تقدم الأعمال الحديثة تضمينًا شاملاً لتسلسل سلوك المستخدم. ومع ذلك، لا يمكن للتضمين الموحد للمستخدم أن يعكس الاهتمامات المتعددة للمستخدم على مدار فترة زمنية. في هذه الورقة، نقترح إطار عمل جديد قابل للتحكم متعدد المصالح للتوصية المتسلسلة يسمى ComiRec. تلتقط وحدة الاهتمامات المتعددة لدينا اهتمامات متعددة من تسلسلات سلوك المستخدم ويمكن استخدامها لاسترداد العناصر المرشحة من مجموعة عناصر واسعة النطاق. يتم بعد ذلك إدخال هذه العناصر في وحدة التجميع للحصول على معلومات التوصية الشاملة. تستخدم وحدة التجميع عوامل قابلة للتحكم لتحقيق التوازن بين دقة وتنوع التوصيات. نحن نجري تجارب التوصية المتسلسلة على مجموعتين من البيانات في العالم الحقيقي: أمازون وتاوباو.تظهر النتائج التجريبية أن إطار عملنا يحقق تحسينات كبيرة مقارنة بالنماذج الحديثة. لقد تم أيضًا نشر إطار عملنا بنجاح على منصة السحابة الموزعة غير المتصلة بالإنترنت التابعة لشركة Alibaba.
عنوان الورقة:
https://arxiv.org/abs/2005.09347
استرجاع المعلومات "إطار عمل توصية دقيق ومتنوع يعتمد على الشبكة العصبية التلافيفية ذات الرسم البياني البايزي"

الشركة: هواوي
ملخص:في أنظمة التوصية، يعد التعلم الدقيق لتمثيل المستخدمين والعناصر موضوعًا مهمًا للغاية. مع البحث المكثف وتطبيق الشبكات التلافيفية البيانية، أصبح تطبيق الشبكات التلافيفية البيانية على أنظمة التوصية يجذب المزيد والمزيد من الاهتمام. تعتبر جميع نماذج التوصية القائمة على الرسم البياني الرسم البياني للتفاعل الملحوظ بين المستخدم والعنصر بمثابة الحقيقة الأساسية بين المستخدمين والعناصر. ومع ذلك، في سياق أنظمة التوصية، لا يكون هذا الإعداد معقولاً دائماً. على سبيل المثال، سيعامل هذا الإعداد التفاعلات التي لا تحتوي على حواف في الرسم البياني للتفاعل باعتبارها أمثلة سلبية، وقد تكون مثل هذه التفاعلات غير الملحوظة تفاعلات محتملة في المستقبل؛ من ناحية أخرى، قد تكون بعض الحواف التي نلاحظها غير حقيقية أو ناجمة عن الضوضاء. لحل هذه المشكلة،في هذا العمل، نستخدم شبكة الرسم البياني التلافيفية البايزية (BGCN) لنمذجة عدم اليقين في الرسوم البيانية للتفاعل بين المستخدم والعنصر.
نقترح دالة خسارة BPR مفصلة لعملية التدريب ونناقش أيضًا بالتفصيل كيفية إجراء التنبؤات بموجب نموذجنا. لقد قمنا بالتحقق من صحة نموذجنا على أربع مجموعات بيانات عامة ووجدنا أن نموذج BGCN الخاص بنا تفوق على نماذج التوصية القائمة على الرسم البياني الموجودة في جميع مقاييس التقييم. لقد تحققنا أيضًا من ذلك في مجموعات بيانات المنتج ووجدنا أن دقة نموذج BGCN قد تحسنت أيضًا.بالإضافة إلى ذلك، وجدنا أيضًا أن نتائج التوصيات الخاصة بنموذج BGCN الخاص بنا تأخذ في الاعتبار كل من الدقة والتنوع، وكان تأثير التوصية على مستخدمي "البداية الباردة" أكثر أهمية.
روابط ذات صلة:
https://zhuanlan.zhihu.com/p/142812078
تخطيط المسار "بوليستار: محرك مسارات النقل العام الذكي والفعال على مستوى البلاد"

الوحدة: بايدو
ملخص:تلعب وسائل النقل العام دورًا مهمًا في حياة الناس اليومية. لقد ثبت أن وسائل النقل العام أكثر خضرة وأكثر كفاءة وأكثر اقتصادا من أي شكل آخر من أشكال النقل. ومع ذلك، مع تزايد حجم شبكات النقل وتعقيد ظروف السفر، أصبح من الصعب على الأشخاص العثور على أفضل طريق من مكان إلى آخر عبر أنظمة النقل العام. ولتحقيق هذه الغاية، نقترح في هذه الورقة البحثية محرك Polestar، وهو محرك قائم على البيانات لتوجيه وسائل النقل العام الذكية والفعالة. على وجه التحديد، نقترح أولاً نموذجًا جديدًا لبيانات النقل العام (PTG) لأنظمة النقل العام ذات تكاليف السفر المختلفة، مثل الوقت أو المسافة. ثم قدمنا عامًاخوارزميات البحث عن المسار وطريقة ربط الموقع الفعالة لتوليد مسارات مرشحة بكفاءة. وبناءً على ذلك، نقترح نموذج تصنيف المرشحين ثنائي المسار لالتقاط تفضيلات المستخدم في مواقف السفر الديناميكية. وأخيرا، أظهرت التجارب التي أجريت على مجموعتين من البيانات الواقعية مزايا نورث ستار من حيث الكفاءة والفعالية.في الواقع، في أوائل عام 2019، تم بالفعل نشر نظام Polestar على خرائط Baidu، إحدى أكبر خدمات رسم الخرائط في العالم. حتى الآن، قدمت شركة بولاريس خدماتها لأكثر من 330 مدينة، وأجابت على أكثر من 100 مليون استفسار يوميًا، وحققت زيادة كبيرة في معدلات النقر لدى المستخدمين.
عنوان الورقة:
https://arxiv.org/abs/2007.07195
تخطيط المسار باستخدام شبكات الرسم البياني المكاني الزمني الهجينة المتلافية: تحسين التنبؤ بحركة المرور باستخدام بيانات الملاحة

الوحدة: علي بابا
ملخص:حظيت توقعات حركة المرور باهتمام متزايد في الآونة الأخيرة بسبب شعبية خدمات الملاحة عبر الإنترنت ومشاركة الرحلات ومشاريع المدن الذكية. ونظراً للطبيعة غير الثابتة لحركة المرور على الطرق، فإن الافتقار إلى المعلومات السياقية سيحد بشكل أساسي من دقة التنبؤ. ولمعالجة هذه المشكلة، نقترح شبكة تلافيفية هجينة ذات رسم بياني مكاني زمني (H-STGCN)، والتي تتمكن من "استنتاج" أوقات السفر المستقبلية من خلال الاستفادة من بيانات حجم حركة المرور القادمة. على وجه التحديد، نقترح خوارزمية للحصول على حركة المرور القادمة من محرك الملاحة عبر الإنترنت. باستخدام علاقة التدفق والكثافة الخطية المتقطعة، يقوم هيكل المحول الجديد بتحويل الحجم الوارد إلى وقت سفر مكافئ. نقوم بدمج هذه الإشارة مع إشارة وقت السفر المستخدمة بشكل شائع ثم نطبق التفاف الرسم البياني لالتقاط التبعيات المكانية.وعلى وجه الخصوص، نقوم ببناء مصفوفة مجاورة مركبة تعكس قرب النقل الفطري. نحن نجري تجارب واسعة النطاق على مجموعات البيانات في العالم الحقيقي. تظهر النتائج أن H-STGCN يتفوق بشكل كبير على الطرق الحديثة في مختلف المقاييس، وخاصة في التنبؤ بالازدحام غير المتكرر.
عنوان الورقة:
https://arxiv.org/abs/2006.12715
تخطيط المسار 《التنبؤ بتأثيرات المعالجة الفردية في المسابقات الجماعية واسعة النطاق في ظل اقتصاد الدراجات المشتركة》

الوحدة: ديدي
ملخص:ولتحقيق أقصى قدر من التفاعل التراكمي للمستخدمين (على سبيل المثال، النقرات التراكمية) في التوصيات المتسلسلة، يتعين علينا عادةً موازنة هدفين متعارضين محتملين، وهما السعي إلى تحقيق تفاعل فوري أعلى للمستخدمين (على سبيل المثال، معدل النقر إلى الظهور) وتشجيع المستخدمين على التصفح (أي المزيد من العناصر).غالبًا ما تدرس الأعمال الموجودة هاتين المهمتين بشكل منفصل، مما يؤدي في كثير من الأحيان إلى نتائج دون المستوى الأمثل.في هذه الورقة، قمنا بدراسة هذه المشكلة من منظور تحسين الإنترنت واقتراح إطار عمل مرن وعملي للموازنة بشكل صريح بين وقت تصفح المستخدم الأطول ومشاركة المستخدم المباشرة الأعلى. على وجه التحديد، من خلال النظر إلى العناصر كأفعال، وطلبات المستخدمين كحالات، ومغادرات المستخدمين كحالات استيعاب، نقوم بصياغة سلوك كل مستخدم كعملية اتخاذ قرار ماركوف مخصصة (MDP)، وبالتالي تقليل مشكلة تعظيم مشاركة المستخدم التراكمية إلى مشكلة أقصر مسار عشوائي (SSP). وفي الوقت نفسه، من خلال التقدير الفوري لمشاركة المستخدم واحتمالات الخروج، فقد تبين أن مشكلة SSP يمكن حلها بشكل فعال من خلال البرمجة الديناميكية.وتظهر التجارب على مجموعات البيانات في العالم الحقيقي فعالية هذه الطريقة. بالإضافة إلى ذلك، تم نشر هذه الطريقة على منصة كبيرة للتجارة الإلكترونية، مما أدى إلى زيادة العدد التراكمي للنقرات بنسبة تزيد عن 7%.
عنوان الورقة:
خدمات المستهلك: تعظيم التفاعل التراكمي للمستخدمين من خلال التوصيات المستمرة: منظور التحسين عبر الإنترنت

الوحدة: علي بابا
ملخص:من أجل تعظيم التفاعل التراكمي للمستخدم (على سبيل المثال، النقرات التراكمية) في التوصيات المتسلسلة، من الضروري عادةً تحقيق التوازن بين هدفين متعارضين محتملين، وهما السعي إلى تحقيق تفاعل فوري أعلى للمستخدم (على سبيل المثال، معدل النقر إلى الظهور) وتشجيع تصفح المستخدم (أي المزيد من التعرض للعناصر). غالبًا ما تدرس الدراسات الموجودة هاتين المهمتين بشكل منفصل، مما يؤدي غالبًا إلى نتائج دون المستوى الأمثل.
في هذه الورقة، قمنا بدراسة هذه المشكلة من منظور تحسين الإنترنت واقتراح إطار عمل مرن وعملي للموازنة بشكل صريح بين وقت تصفح المستخدم الأطول ومشاركة المستخدم المباشرة الأعلى. على وجه التحديد، من خلال النظر إلى العناصر كأفعال، وطلبات المستخدمين كحالات، ومغادرات المستخدمين كحالات استيعاب، نقوم بصياغة سلوك كل مستخدم كعملية قرار ماركوف مخصصة (MDP) ونبسط مشكلة تعظيم المشاركة التراكمية للمستخدم إلى مشكلة أقصر مسار عشوائي (SSP). وفي الوقت نفسه، من خلال تقدير مشاركة المستخدم اللحظية واحتمالات الخروج، ثبت أن البرمجة الديناميكية يمكنها حل مشكلة SSP بشكل فعال.وتثبت تجاربنا على مجموعات البيانات الحقيقية فعالية نهجنا. بالإضافة إلى ذلك، تم نشر هذه الطريقة على منصة كبيرة للتجارة الإلكترونية، مما أدى إلى زيادة العدد التراكمي للنقرات بنسبة تزيد عن 7%.
عنوان الورقة:
خدمات المستهلك "بناء روبوتات دردشة ذكية لخدمة العملاء: تعلم كيفية الاستجابة في الوقت المناسب"

الوحدة: ديدي
ملخص:
في السنوات الأخيرة، تم استخدام برامج المحادثة الذكية على نطاق واسع في مجال خدمة العملاء. أحد التحديات الرئيسية التي تواجه روبوتات المحادثة في الحفاظ على محادثة سلسة مع العملاء هو الرد في الوقت المناسب. ومع ذلك، تتبع معظم برامج المحادثة الروبوتية المتقدمة نهج التفاعل المتبادل.تستجيب مثل هذه الروبوتات الدردشة بعد كل كلمة من العميل، وهو ما قد يؤدي في بعض الحالات إلى ردود غير مناسبة وتضليل عملية المحادثة.
في هذه الورقة، نقترح نموذج الزناد الاستجابة متعدد الجولات (MRTM) لمعالجة هذه المشكلة. يتعلم MRTM من المحادثات واسعة النطاق بين الإنسان والآلة بين العملاء والوكلاء من خلال مخطط التعلم الذاتي.ويستخدم علاقة المطابقة الدلالية بين السياق والاستجابة لتدريب نموذج المطابقة الدلالية، ويحصل على وزن العبارات المتزامنة في السياق من خلال آلية الاهتمام الذاتي غير المتماثلة. ويتم بعد ذلك استخدام الأوزان لتحديد ما إذا كان ينبغي الاستجابة لسياق معين.
لقد أجرينا تجارب مكثفة على مجموعتين من بيانات المحادثة تم جمعها من أنظمة خدمة العملاء عبر الإنترنت في العالم الحقيقي. وتظهر النتائج أن MRTM يتفوق بشكل كبير على خط الأساس. بالإضافة إلى ذلك، قمنا بدمج MRTM في برنامج الدردشة الآلي لخدمة العملاء الخاص بشركة Didi. بناءً على القدرة على تحديد وقت الاستجابة المناسب، يمكن لبرنامج المحادثة الآلي تجميع المعلومات بشكل تدريجي عبر جولات متعددة من المحادثة وتقديم استجابات أكثر ذكاءً في الوقت المناسب.
عنوان الورقة:
https://dl.acm.org/doi/10.1145/3394486.3403390
التجارة الإلكترونية "شبكات الانتباه البياني غير المتجانسة المزدوجة لتحسين أداء البحث طويل المدى في المتاجر في التجارة الإلكترونية"

الوحدة: علي بابا
ملخص:
شبكات الانتباه البياني غير المتجانسة المزدوجة لتحسين أداء البحث طويل المدى في المتاجر عبر التجارة الإلكترونية
مع النمو الهائل لمستخدمي Taobao والمتاجر، يواجه البحث عن المتجر العديد من التحديات الفريدة:
1) لا تستطيع العديد من أسماء المتاجر التعبير بشكل كامل عن المنتجات التي تبيعها، أي الفجوة الدلالية بين استعلامات المستخدم وأسماء المتاجر؛
2) بسبب نقص تفاعل المستخدم، من الصعب توفير نتائج بحث جيدة للاستعلامات الطويلة، ومن الصعب استرداد المتاجر الطويلة ذات الصلة الكبيرة بالاستعلام. ولمعالجة هذين التحديين الرئيسيين، نلجأ إلى الشبكات العصبية الرسومية (GNNs). خاصة،باستخدام بيانات تفاعل المستخدم من البحث في المتجر والبحث عن المنتج، نقترح شبكة انتباه بياني غير متجانسة مزدوجة (DHGAT) متكاملة مع بنية ذات برجين.أولاً، نقوم بإنشاء رسم بياني غير متجانس في سياق البحث في المتجر من خلال الاستفادة من القرب من الدرجة الأولى والثانية من سلوك بحث المستخدم، وسلوك نقر المستخدم، وسجلات شراء المستخدم. ومن ثم، تم تصميم DHGAT للتركيز على اعتماد الجيران غير المتجانسين والمتجانسين للاستعلامات والمتاجر لتعزيز تمثيلها الخاص، مما يساعد على التخفيف من ظاهرة الذيل الطويل.علاوة على ذلك، يخفف DHGAT الفجوة الدلالية من خلال الجمع بين عناوين العناصر ذات الصلة، وبالتالي إثراء دلالات نص الاستعلام وأسماء المتاجر.
عنوان الورقة:
https://dl.acm.org/doi/10.1145/3394486.3403393
التجارة الإلكترونية: خطة إعلانية مع ضمان التسليم على مستوى الطلب: التنبؤ والتخصيص》
الشركة: تينسنت
ملخص:عادةً ما تقوم الأبحاث الحالية حول تقديم الإعلانات عبر الإنترنت بنمذجة الخدمة باعتبارها مشكلة تخصيص العرض على مستوى المجموعة أو مستوى المستخدم وتفترض أن نتائج البحث متاحة وأن العقود موقعة، وبالتالي التركيز على البحث عن أفضل تخصيص للخدمة عبر الإنترنت. ومع ذلك، فإن هذه التقنيات ليست كافية لتلبية احتياجات اتجاهات الصناعة اليوم:
1) يسعى المعلنون إلى استهداف أكثر دقة، الأمر الذي لا يتطلب سمات على مستوى المستخدم فحسب، بل يتطلب أيضًا سمات على مستوى الطلب؛
2) يفضل المستخدمون خدمات الإعلان الأكثر ودية، مما سيؤدي إلى المزيد من القيود على الإعلان؛
3) إن العائق أمام نمو إيرادات الناشرين لا يكمن في خدمات الإعلان فحسب، بل أيضاً في دقة التنبؤ واستراتيجيات المبيعات.
نظرًا لأن مقياس نماذج مستوى الطلب أكبر بعدة أوامر من حيث الحجم من مقياس نماذج مستوى السكان أو مستوى المستخدم، فإن حل هذه المشكلات ليس بالأمر السهل.
وفي مواجهة هذا التحدي، اقترحنا نظامًا شاملًا لجدولة الإعلانات على مستوى الطلب مع ضمان التسليم، وقمنا بتحسين ثلاثة عناصر رئيسية بعناية بما في ذلك التنبؤ بالانطباعات والمبيعات والخدمة.لقد تم نشر نظامنا في نظام الإعلان المضمون عبر الإنترنت الخاص بشركة Tencent وقد خدم مليارات المستخدمين لمدة عام تقريبًا. تُظهر التقييمات التي أجريت على بيانات واقعية واسعة النطاق وأداء الأنظمة المنشورة أن تصميمنا قادر على تحسين دقة وسرعة تسليم التنبؤ بالانطباعات على مستوى الطلب بشكل كبير.
عنوان الورقة: لم ينشر بعد
INPREM: نموذج تنبؤ بالرعاية الصحية قابل للتفسير وجدير بالثقة

الشركة: تينسنت
ملخص:
أصبح بناء نماذج تنبؤية للطب الشخصي استنادًا إلى السجلات الصحية الإلكترونية التاريخية مجالًا نشطًا للبحث. بفضل قدراتها القوية على استخراج الميزات، حققت أساليب التعلم العميق نتائج جيدة في العديد من مهام التنبؤ السريري. ومع ذلك، فإن الافتقار إلى القدرة على التفسير والمصداقية يجعل من الصعب تطبيقه في حالات اتخاذ القرارات السريرية الفعلية.
ولمعالجة هذه المشكلة، نقترح في هذه الورقة نموذجًا تنبؤيًا قابلًا للتفسير وجديرًا بالثقة (INPREM) للرعاية الصحية. أولاً، تم تصميم INPREM كنموذج خطي قابل للتفسير لتحقيق القدرة على التفسير. وفي الوقت نفسه، يتم ترميز العلاقات غير الخطية في الأوزان المكتسبة لنمذجة التبعيات بين كل زيارة وداخلها.وهذا يسمح لنا بالحصول على مصفوفة مساهمة متغيرات الإدخال،وكدليل على النتائج المتوقعة، فإنها تساعد الأطباء على فهم سبب قيام النموذج بمثل هذا التنبؤ، مما يجعل النموذج أكثر قابلية للتفسير.ثانيًا، من أجل الموثوقية، نضع بوابة عشوائية (وفقًا لتوزيع برنولي للتشغيل أو الإيقاف) على كل وزن للنموذج، بالإضافة إلى فرع إضافي لتقدير ضوضاء البيانات. يستخدم النموذج أخذ العينات بطريقة مونت كارلو ووظيفة موضوعية تأخذ ضوضاء البيانات في الاعتبار لالتقاط عدم اليقين في كل تنبؤ. في المقابل، يبلغ عدم اليقين الملتقط الطبيب بمستوى ثقة النموذج، مما يجعل النموذج أكثر جدارة بالثقة. لقد أثبتنا تجريبياً أن INPREM المقترح يتمتع بمزايا كبيرة مقارنة بالطرق الحالية.
عنوان الورقة:
https://dl.acm.org/doi/abs/10.1145/3394486.3403087
التسجيل مفتوح لمؤتمر KDD 2020 عبر الإنترنت
مؤتمر KDD 2020 قيد التنفيذ، والتسجيل للمؤتمر مفتوح الآن:
https://www.kdd.org/kdd2020/#!
وقد تم الإعلان عن جدول الأعمال الكامل. يمكن للطلبة المهتمين حضور اللقاء عن بعد عبر تطبيق زووم. تبلغ قيمة تذاكر الطلاب 50 دولارًا أمريكيًا. ومن المقرر أن تقام واحدة من الجلسات الأكثر ترقبا، حفل الافتتاح وحفل توزيع الجوائز، من الساعة الثامنة إلى العاشرة صباحا بالتوقيت المحلي في 25 أغسطس/آب. يرجى البقاء على اتصال.
للاطلاع على الجدول الكامل، يرجى الاطلاع على:
https://www.kdd.org/kdd2020/schedule
مصادر:
https://www.kdd.org/kdd2020/accepted-papers#ads-papers
https://www.aminer.cn/conf/kdd2020/papers
-- زيادة--








