Command Palette
Search for a command to run...
لقد اتخذت هذه المجموعة من المهندسين خطوة كبيرة إلى الأمام في مجال البرمجة اللغوية العصبية الصينية في أوقات فراغهم

قال أحدهم أنه إذا كنت قد درست معالجة اللغة الطبيعية (NLP)، فسوف تعرف مدى صعوبة معالجة اللغة الطبيعية باللغة الصينية.
على الرغم من أن كليهما ينتمي إلى البرمجة اللغوية العصبية، إلا أن هناك اختلافات كبيرة في التحليل والمعالجة بين اللغتين الإنجليزية والصينية بسبب العادات اللغوية المختلفة، كما أن الصعوبات والتحديات مختلفة أيضًا.

علاوة على ذلك، فإن بعض النماذج الشائعة حاليًا تم تطويرها في الغالب للغة الإنجليزية. بالإضافة إلى عادات الاستخدام الفريدة للغة الصينية، فإن العديد من المهام (مثل تقسيم الكلمات) صعبة للغاية، مما يؤدي إلى تقدم بطيء للغاية في مجال معالجة اللغة الطبيعية الصينية.
ولكن هذا النوع من المشاكل قد يتغير قريبا، لأنه منذ العام الماضي، ظهرت العديد من المشاريع مفتوحة المصدر الممتازة، والتي عززت بشكل كبير تطوير مجال معالجة اللغة الطبيعية في الصين.
النموذج: ALBERT صيني مدرب مسبقًا
في عام 2018، أطلقت Google نموذج اللغة BERT، وهو تمثيلات ترميز ثنائية الاتجاه من المحولات. بفضل أدائها القوي للغاية، اكتسحت مخططات العديد من معايير معالجة اللغة الطبيعية (NLP) بمجرد إصدارها وتم الإشادة بها على الفور باعتبارها تحفة فنية.
ولكن أحد عيوب BERT هو أنه كبير جدًا. يحتوي BERT-large على 300 مليون معلمة، مما يجعل تدريبه صعبًا للغاية. في عام 2019، أطلقت Google AI نموذج ALBERT خفيف الوزن (A Little BERT)، والذي يحتوي على معلمات أصغر بمقدار 18 مرة من نموذج BERT، ولكن أداءه أفضل.
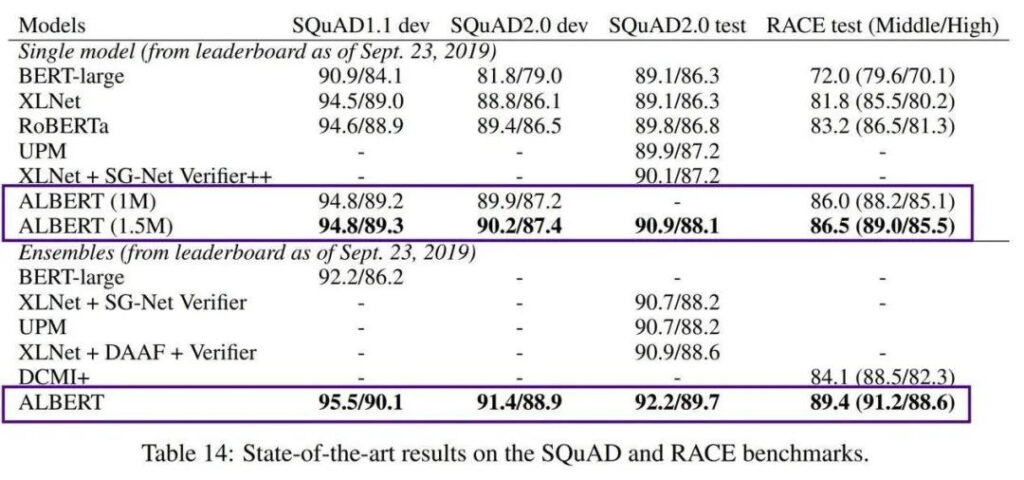
على الرغم من أن AlBERT يحل مشكلة تكلفة التدريب العالية والعدد الهائل من معلمات النماذج المدربة مسبقًا، إلا أنه لا يزال يستهدف السياقات الإنجليزية فقط، مما يجعل المهندسين الذين يركزون على التطوير الصيني يشعرون بالعجز قليلاً.
من أجل جعل هذا النموذج قابلاً للاستخدام في السياق الصيني وإفادة المزيد من المطورين، فتح فريق مهندس البيانات Xu Liang أول نموذج ALBERT صيني مدرب مسبقًا في أكتوبر 2019.
معرض المشاريع
https://github.com/brightmart/albert_zh
تم تدريب نموذج ALBERT الصيني المدرب مسبقًا (المشار إليه باسم albert_zh) على مجموعة بيانات صينية ضخمة. يأتي محتوى التدريب من موسوعات متعددة، وأخبار، ومجتمعات تفاعلية، بما في ذلك 30 جيجابايت من النصوص الصينية وأكثر من 100 مليار حرف صيني.
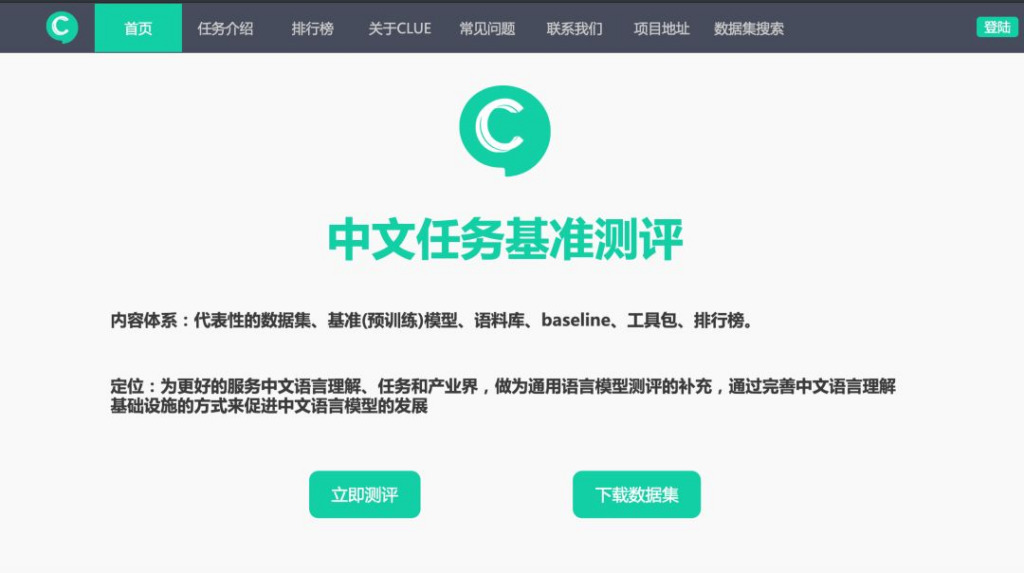
من مقارنة البيانات، تم تعيين طول تسلسل ما قبل التدريب الخاص بـ albert_zh إلى 512، وحجم الدفعة هو 4096، ويولد التدريب 350 مليون بيانات تدريب. نموذج تدريب مسبق قوي آخر، roberta_zh، يولد 250 مليون بيانات تدريب بطول تسلسل يبلغ 256.
يؤدي التدريب المسبق لـ albert_zh إلى إنشاء المزيد من بيانات التدريب واستخدام تسلسلات أطول. ومن المتوقع أن يكون أداء albert_zh أفضل من roberta_zh وأن يتمكن من التعامل مع النصوص الأطول بشكل أفضل.
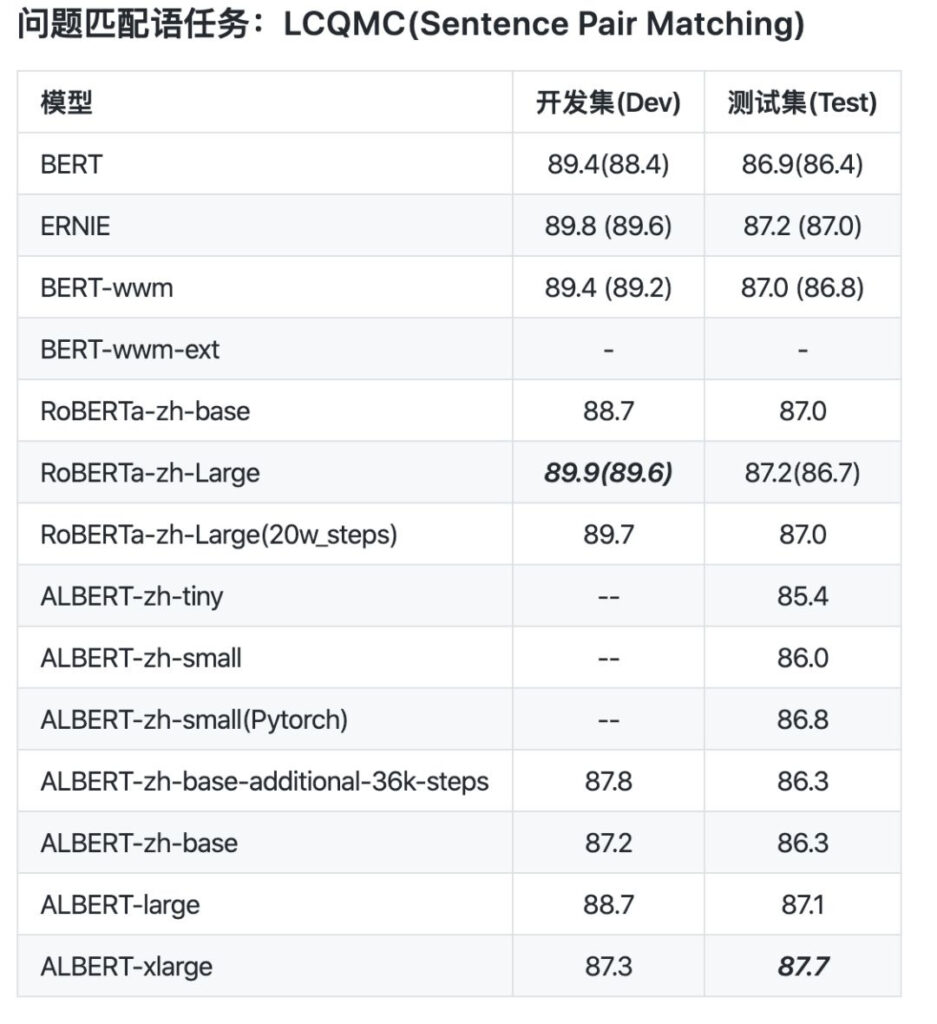
بالإضافة إلى ذلك، قام albert_zh بتدريب سلسلة من نماذج ALBERT بأحجام معلمات مختلفة، من tiny إلى xlarge، مما عزز بشكل كبير شعبية ALBERT في مجال معالجة اللغة الطبيعية الصينية.
ومن الجدير بالذكر أنه في يناير 2020، أصدرت Google AI برنامج ALBERT V2، ثم أطلقت ببطء النسخة الصينية من ALBERT من Google.
المعيار: ChineseGLUE للغراء الصيني
بمجرد أن نحصل على النماذج، كيف نحكم ما إذا كانت جيدة أم سيئة؟ يتطلب هذا معيار اختبار جيد بدرجة كافية. وفي العام الماضي أيضًا، أصبح معيار ChineseGLUE لمعالجة اللغة الطبيعية الصينية مفتوح المصدر.
يعتمد برنامج ChineseGLUE على معيار الاختبار الشهير في الصناعة GLUE، وهو عبارة عن مجموعة من تسع مهام لفهم اللغة الإنجليزية. ويهدف إلى تعزيز البحث في أنظمة فهم اللغة الطبيعية العامة والقوية.
في السابق، لم يكن هناك إصدار صيني يتوافق مع GLUE، ولم يكن من الممكن الحكم على بعض النماذج المدربة مسبقًا في الاختبارات العامة على مهام مختلفة، مما أدى إلى عدم التوافق في تطوير وتطبيق معالجة اللغة الطبيعية في المجال الصيني، وحتى التأخير في التطبيق التكنولوجي.
وفي مواجهة هذا الوضع، أطلق الدكتور Zhenzhong Lan، المؤلف الأول لـ AlBERT، وXu Liang، مطور ablbert_zh، وأكثر من 20 مهندسًا آخرين معيارًا مشتركًا لمعالجة اللغة الطبيعية الصينية: ChineseGLUE.
معرض المشاريع
https://github.com/chineseGLUE/chineseGLUE
سمح ظهور ChineseGLUE بإدراج اللغة الصينية كمؤشر لتقييم النماذج الجديدة، وتشكيل نظام تقييم كامل لاختبار النماذج الصينية المدربة مسبقًا.
يتضمن معيار الاختبار القوي هذا الجوانب التالية:
1) معيار مهمة اللغة الصينية يتكون من عدة جمل أو أزواج جمل، تغطي مهام لغوية متعددة على مستويات مختلفة.
2) توفير قائمة تصنيف لتقييم الأداء، والتي سيتم تحديثها بانتظام لتوفير أساس لاختيار النموذج.
3) مجموعة من نماذج المعايير، بما في ذلك الكود المبدئي، والنماذج المدربة مسبقًا، ومعايير المهام ChineseGLUE، والتي تتوفر في أطر عمل مثل TensorFlow وPyTorch وKeras.
4) أن يكون لديك مجموعة ضخمة من النصوص الأصلية للبحث في مجال التدريب المسبق أو نمذجة اللغة، والتي تبلغ حوالي 10 جيجابايت (2019)، ومن المخطط توسيعها إلى مجموعة كافية من النصوص الأصلية (مثل 100 جيجابايت) بحلول نهاية عام 2020.
ومن المتوقع أن يشهد إطلاق ChineseGLUE وتحسينه المستمر ولادة نماذج معالجة اللغة الطبيعية الصينية أكثر قوة، تمامًا كما شهد GLUE ظهور BERT.
في نهاية ديسمبر 2019، تم نقل المشروع إلى مشروع أكثر شمولاً وأكثر دعمًا من الناحية الفنية: CLUEbenchmark/CLUE.
معرض المشاريع
https://github.com/CLUEbenchmark/CLUE
البيانات: مجموعة البيانات الأكثر اكتمالاً وأكبر مجموعة بيانات في التاريخ
مع النماذج المدربة مسبقًا ومعايير الاختبار، هناك رابط مهم آخر وهو موارد البيانات مثل مجموعات البيانات والمجموعات.
وقد أدى هذا إلى ظهور منظمة أكثر شمولاً، وهي CLUE، وهي اختصار لكلمة GLUE الصينية. وهي منظمة مفتوحة المصدر تقدم معايير تقييم لفهم اللغة الصينية. تشمل مجالات تركيزهم: المهام ومجموعات البيانات، والمعايير، والنماذج الصينية المدربة مسبقًا، والمجموعات والإصدارات التصنيفية.
قبل فترة من الوقت، أصدرت CLUE أكبر وأشمل مجموعة بيانات معالجة اللغة الطبيعية الصينية، والتي تغطي 142 مجموعة بيانات في 10 فئات، CLUEDatasetSearch.

معرض المشاريع
https://github.com/CLUEbenchmark/CLUEDatasetSearch
يتضمن محتواه جميع الاتجاهات الرئيسية للبحث الحالي مثل NER، وضمان الجودة، وتحليل المشاعر، وتصنيف النصوص، وتعيين النص، وتلخيص النص، والترجمة الآلية، والرسوم البيانية المعرفية، والمجموعات، وفهم القراءة.
كل ما عليك فعله هو كتابة الكلمات الرئيسية، أو المعلومات مثل الحقول ذات الصلة على صفحة موقع الويب، ويمكنك البحث عن الموارد المقابلة. توفر كل مجموعة بيانات معلومات مثل الاسم ووقت التحديث والمزود والوصف والكلمات الرئيسية والفئة وعنوان الورقة.
في الآونة الأخيرة، فتحت منظمة CLUE 100 جيجابايت من البيانات الصينية ومجموعة من النماذج الصينية عالية الجودة المدربة مسبقًا، وقدمت ورقة بحثية إلى arViv.

من حيث مجموعة النصوص، قامت CLUE بفتح مصدر CLUECorpus2020: مجموعة نصوص ما قبل التدريب واسعة النطاق للصينيين 100G من مجموعة النصوص ما قبل التدريب الصينية.
تم الحصول على هذه المحتويات بعد تنظيف مجموعة البيانات الخاصة بالجزء الصيني من مجموعة بيانات الزحف المشتركة.
يمكن استخدامها بشكل مباشر للتدريب المسبق أو نموذج اللغة أو مهام توليد اللغة، أو نشر مفردات صغيرة خصيصًا لمهام معالجة اللغة الطبيعية الصينية.
معرض المشاريع
https://github.com/CLUEbenchmark/CLUECorpus2020
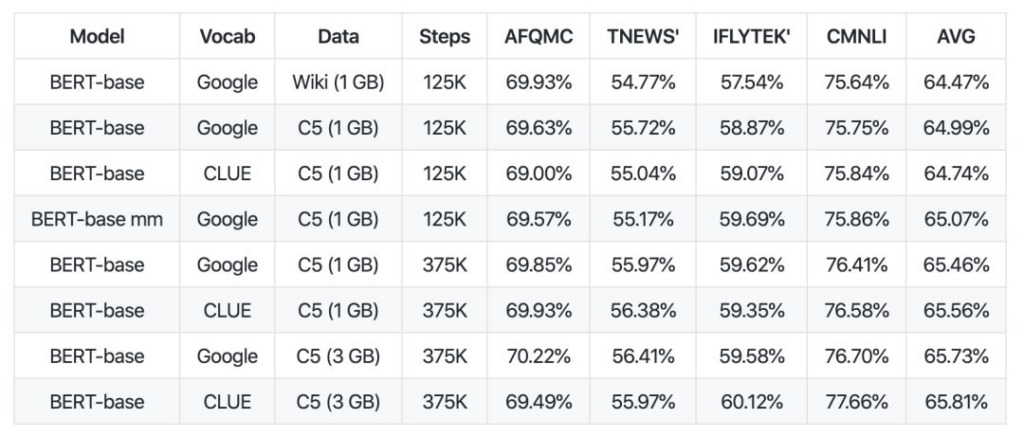
فيما يتعلق بجمع النماذج، تم إصدار CLUEPretrainedModels: مجموعة من النماذج الصينية المدربة مسبقًا عالية الجودة - النماذج الكبيرة الأكثر تقدمًا، والنماذج الصغيرة الأسرع، والنماذج الخاصة بالتشابه.
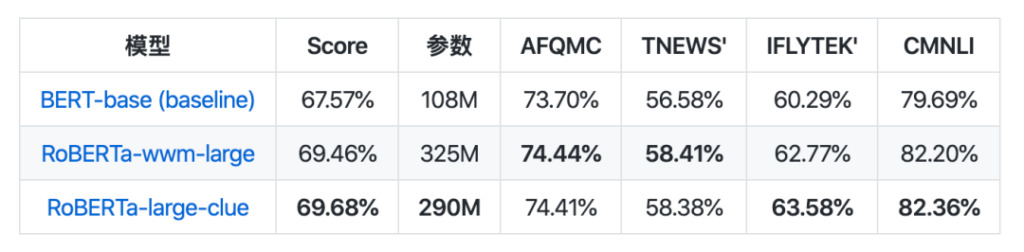
يحقق النموذج الكبير نفس النتائج التي يحققها أفضل نموذج معالجة اللغة الطبيعية الصيني الحالي، بل ويتفوق حتى على بعض المهام. النموذج الصغير أسرع بحوالي 8 مرات من النموذج القائم على Bert. يتم استخدام نموذج التشابه الدلالي لمعالجة مشاكل التشابه الدلالي أو أزواج الجمل، ومن المرجح أن يكون أفضل من استخدام نموذج مدرب مسبقًا بشكل مباشر.
معرض المشاريع
https://github.com/CLUEbenchmark/CLUEPretrainedModels
إن إطلاق هذه الموارد، إلى حد ما، يشبه الوقود الذي يحرك عملية التنمية، وقد تفتح الموارد الكافية الطريق أمام التطور السريع لصناعة معالجة اللغة الطبيعية في الصين.
إنهم يجعلون البرمجة اللغوية العصبية الصينية سهلة
من الناحية اللغوية، تعد اللغتان الصينية والإنجليزية اللغتين الأكثر عدداً من المستخدمين والأعظم تأثيراً في العالم. ومع ذلك، بسبب خصائص لغتهم المختلفة، فإنهم يواجهون أيضًا مشاكل مختلفة في مجال البحث في مجال معالجة اللغة الطبيعية.
على الرغم من أن تطوير معالجة اللغة الطبيعية الصينية أكثر صعوبة ويتأخر عن البحث في اللغة الإنجليزية، والتي يمكن للآلات فهمها بشكل أفضل، إلا أن المهندسين المذكورين في المقالة على استعداد لتعزيز تطوير معالجة اللغة الطبيعية الصينية ومواصلة استكشاف نتائجهم ومشاركتها حتى يمكن تكرار هذه التقنيات بشكل أفضل.
بفضل جهودهم ومساهماتهم في العديد من المشاريع عالية الجودة! وفي الوقت نفسه، نأمل أن يتمكن المزيد من الأشخاص من المشاركة وتعزيز تطوير البرمجة اللغوية العصبية الصينية بشكل مشترك.
-- زيادة--








