Command Palette
Search for a command to run...
مجموعة بيانات متعددة الوسائط لأزواج النصوص والصور MINT-1T
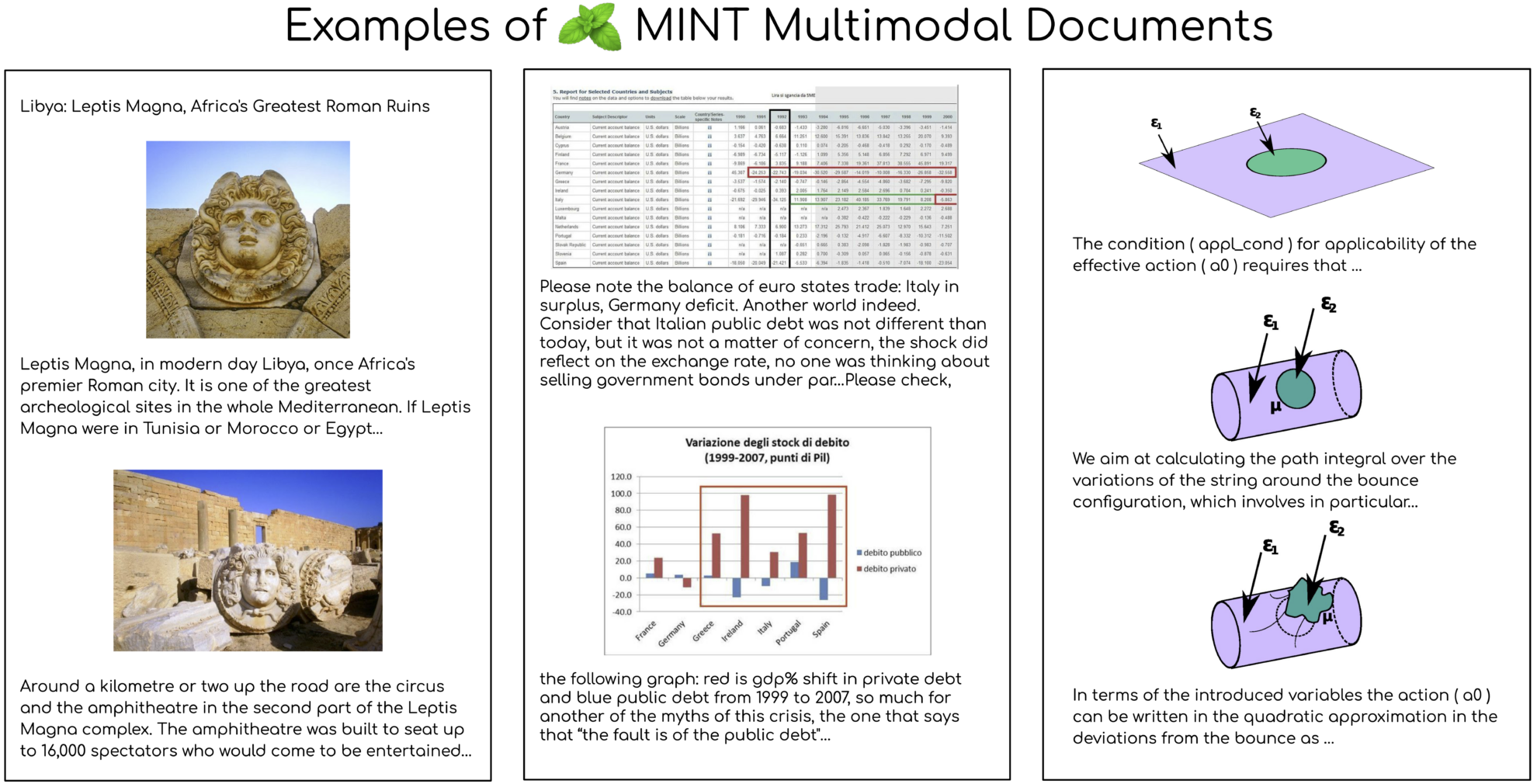
مجموعة بيانات MINT-1T هي مجموعة بيانات متعددة الوسائط مفتوحة المصدر بشكل مشترك بين Salesforce AI ومؤسسات متعددة في عام 2024. وقد حققت توسعًا كبيرًا في الحجم، حيث وصلت إلى تريليون علامة نصية و3.4 مليار صورة، وهو ما يزيد بمقدار 10 أضعاف عن حجم أكبر مجموعة بيانات مفتوحة المصدر سابقًا. "نتائج الورقة ذات الصلة هي"MINT-1T: توسيع نطاق البيانات متعددة الوسائط مفتوحة المصدر بمقدار 10 أضعاف: مجموعة بيانات متعددة الوسائط تحتوي على تريليون رمز مميزيتبع بناء هذه المجموعة من البيانات المبادئ الأساسية للحجم والتنوع. فهي لا تشمل مستندات HTML فحسب، بل تشمل أيضًا مستندات PDF وأوراق ArXiv. يُحسّن هذا التنوع تغطية المستندات العلمية بشكل كبير. مصادر بيانات MINT-1T متنوعة، بما في ذلك على سبيل المثال لا الحصر، صفحات الويب والأوراق الأكاديمية والمستندات، والتي لم تُستغل بالكامل في مجموعات البيانات متعددة الوسائط من قبل.
من حيث تجارب النموذج، أظهر نموذج XGen-MM المتعدد الوسائط المدرب مسبقًا على MINT-1T أداءً جيدًا في معايير وصف الصور والإجابة على الأسئلة المرئية، متجاوزًا مجموعة البيانات الرائدة السابقة OBELICS. ومن خلال التحليل، نجح MINT-1T في تحقيق تحسينات كبيرة في الحجم وتنوع مصادر البيانات والجودة، وخاصة في مستندات PDF وArXiv، التي تتمتع بطول متوسط أطول بشكل ملحوظ وكثافة صورة أعلى. بالإضافة إلى ذلك، تظهر نتائج نمذجة موضوع المستندات من خلال نموذج LDA أن مجموعة HTML الفرعية من MINT-1T تظهر نطاقًا أوسع من تغطية المجال، في حين تركز مجموعة PDF الفرعية بشكل أساسي في مجالات العلوم والتكنولوجيا.
يظهر MINT-1T أداءً ممتازًا في مهام متعددة، وخاصة في مجال العلوم والتكنولوجيا، وذلك بفضل شعبية هذه المجالات في مستندات ArXiv وPDF. يتم تقييم أداء التعلم السياقي للنماذج عند استخدام أعداد مختلفة من الأمثلة. تتفوق النماذج المدربة على MINT-1T على نموذج OBELICS الأساسي في جميع أعداد الأمثلة. لا يوفر إصدار MINT-1T للباحثين والمطورين مجموعة كبيرة من البيانات متعددة الوسائط فحسب، بل يوفر أيضًا تحديات وفرصًا جديدة لتدريب وتقييم النماذج متعددة الوسائط.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.