Command Palette
Search for a command to run...
مجموعة MMedC الطبية متعددة اللغات واسعة النطاق
التاريخ
الحجم
المؤسسة
عنوان URL للنشر
رابط الورقة البحثية
الترخيص
CC BY-NC-SA 3.0
الوسوم
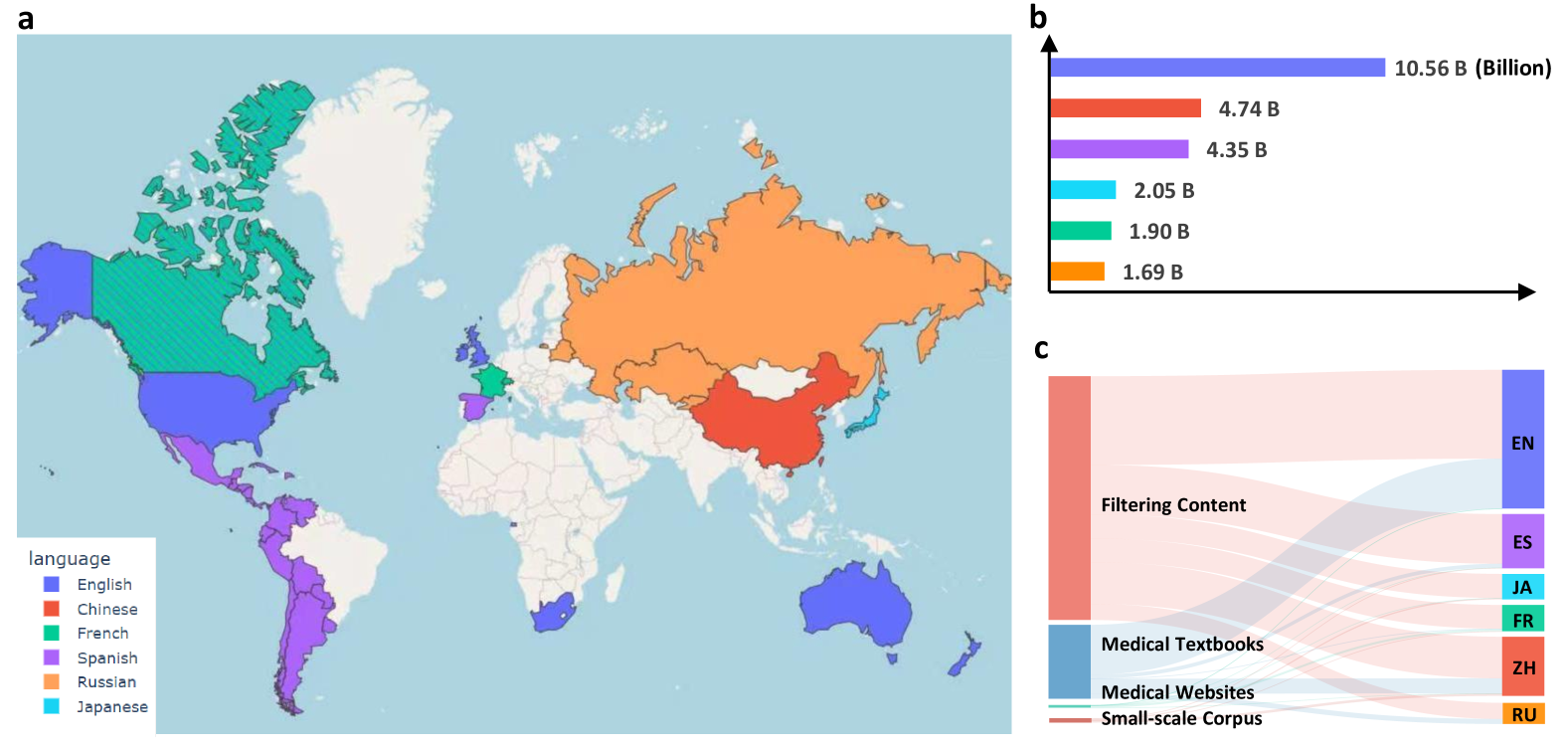
مجموعة البيانات الطبية متعددة اللغات الضخمة (MMedC) هي مجموعة بيانات طبية متعددة اللغات أنشأها فريق الرعاية الصحية الذكية في كلية الذكاء الاصطناعي بجامعة شنغهاي جياو تونغ في عام 2024. وتحتوي على ما يقرب من 25.5 مليار رمز تغطي 6 لغات رئيسية: الإنجليزية والصينية واليابانية والفرنسية والروسية والإسبانية. تم إنشاء مجموعة البيانات هذه لتعزيز تطوير نماذج اللغة الطبية الكبيرة متعددة اللغات، والتي تغطي معظم أنحاء العالم، ولا يزال الدعم لمزيد من اللغات قيد التحديث والتوسع. نتائج الورقة ذات الصلة هينحو بناء نموذج لغوي متعدد اللغات للطب"، نُشرت في مجلة Nature Communications. تتضمن مصادر بيانات MMedC بشكل أساسي أربعة جوانب: أولاً، يتم فحص المحتوى المتعلق بالطب من قواعد بيانات النصوص العامة واسعة النطاق (مثل CommonCrawl) من خلال خوارزميات استدلالية؛ ثانياً، يتم استخراج النص من الكتب الطبية باستخدام تقنية التعرف الضوئي على الحروف (OCR)؛ ثالثًا، يتم جمع البيانات من مواقع طبية مرخصة رسميًا في العديد من البلدان؛ وأخيرًا، تم دمج بعض مجموعات البيانات الطبية الصغيرة الموجودة. بالإضافة إلى ذلك، من أجل تقييم تطوير النماذج متعددة اللغات في المجال الطبي، قام فريق البحث أيضًا بتصميم معيار تقييم جديد للإجابة على الأسئلة متعددة اللغات متعددة الاختيارات يسمى MMedBench. يتم الحصول على جميع الأسئلة في MMedBench بشكل مباشر من بنوك أسئلة الفحص الطبي في مختلف البلدان بدلاً من الحصول عليها ببساطة من خلال الترجمة، وبالتالي تجنب تحيز الفهم التشخيصي الناجم عن الاختلافات في إرشادات الممارسة الطبية في بلدان مختلفة. أثناء عملية التقييم، لا يحتاج النموذج إلى اختيار الإجابة الصحيحة فحسب، بل يجب عليه أيضًا تقديم تفسير معقول، وبالتالي اختبار قدرة النموذج على فهم وتفسير المعلومات الطبية المعقدة وتحقيق تقييم أكثر شمولاً. كما قام فريق البحث أيضًا بفتح المصدر للنموذج الطبي متعدد اللغات MMed-Llama 3، والذي أظهر أداءً استثنائيًا في العديد من المعايير، متفوقًا بشكل كبير على النماذج مفتوحة المصدر الحالية وهو مناسب بشكل خاص للضبط الدقيق المخصص في القطاع الطبي. وقد أصبحت جميع البيانات والرموز مفتوحة المصدر، مما يعزز التعاون وتبادل التكنولوجيا بين مجتمع البحث العالمي. يوفر بناء MMedC والمصدر المفتوح دعمًا للبيانات الغنية وعالي الجودة لتدريب وتقييم نماذج اللغة الطبية متعددة اللغات، ويساعد في حل مشاكل الحواجز اللغوية وعولمة الموارد الطبية، ويظهر إمكانات كبيرة للتطبيق في المجال الطبي.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.