Command Palette
Search for a command to run...
Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition
Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition
Abstract
Recent advances in diffusion-based and controllable video generation have enabled high-quality and temporally coherent video synthesis, laying the groundwork for immersive interactive gaming experiences. However, current methods face limitations in dynamics, generality, long-term consistency, and efficiency, which limit the ability to create various gameplay videos. To address these gaps, we introduce Hunyuan-GameCraft, a novel framework for high-dynamic interactive video generation in game environments. To achieve fine-grained action control, we unify standard keyboard and mouse inputs into a shared camera representation space, facilitating smooth interpolation between various camera and movement operations. Then we propose a hybrid history-conditioned training strategy that extends video sequences autoregressively while preserving game scene information. Additionally, to enhance inference efficiency and playability, we achieve model distillation to reduce computational overhead while maintaining consistency across long temporal sequences, making it suitable for real-time deployment in complex interactive environments. The model is trained on a large-scale dataset comprising over one million gameplay recordings across over 100 AAA games, ensuring broad coverage and diversity, then fine-tuned on a carefully annotated synthetic dataset to enhance precision and control. The curated game scene data significantly improves the visual fidelity, realism and action controllability. Extensive experiments demonstrate that Hunyuan-GameCraft significantly outperforms existing models, advancing the realism and playability of interactive game video generation.
One-sentence Summary
The authors from Tencent Hunyuan and Huazhong University of Science and Technology propose Hunyuan-GameCraft, a diffusion-based framework that unifies keyboard/mouse inputs into a shared camera space for fine-grained action control, employs hybrid history-conditioned training for long-term temporal and 3D consistency, and leverages model distillation for efficient real-time deployment, enabling high-dynamic, realistic interactive game video generation from single images and prompts across diverse AAA game environments.
Key Contributions
- Hunyuan-GameCraft addresses the challenge of generating high-dynamic, temporally coherent, and action-controllable gameplay videos by unifying discrete keyboard and mouse inputs into a shared continuous camera representation space, enabling fine-grained interpolation and physically plausible movement and camera control.
- The framework introduces a hybrid history-conditioned training strategy that autoregressively extends video sequences while preserving scene consistency, using historical context integration and a mask indicator to mitigate error accumulation in long-term generation.
- Trained on over one million gameplay recordings across 100+ AAA games and fine-tuned on a synthetic annotated dataset, Hunyuan-GameCraft achieves superior visual fidelity and action controllability, with model distillation enabling efficient real-time inference suitable for interactive gaming environments.
Introduction
The authors leverage recent advances in diffusion-based video generation to address the growing demand for high-dynamic, interactive game content, where real-time responsiveness, long-term consistency, and physical plausibility are critical for immersive experiences. Prior work struggles with maintaining temporal coherence over extended sequences, suffers from quality degradation due to error accumulation in autoregressive generation, and often lacks efficient integration of diverse user inputs. To overcome these challenges, the authors introduce Hunyuan-GameCraft, a novel framework that unifies discrete keyboard and mouse actions into a continuous action space for fine-grained, physically plausible control. They propose a hybrid history-conditioned training strategy that combines multiple historical context types—single frames, previous clips, and longer segments—within a denoising framework, enabling stable, long-form video generation with strong spatiotemporal consistency. Additionally, they employ model distillation to accelerate inference, making the system suitable for real-time interactive deployment. The approach achieves state-of-the-art performance in both action controllability and long-term video fidelity.
Dataset
- The dataset is built from over 100 AAA video games, including titles like Assassin's Creed, Red Dead Redemption, and Cyberpunk 2077, ensuring high visual fidelity and complex in-game interactions.
- Gameplay recordings, each lasting 2–3 hours, are processed into 6-second coherent video clips at 1080p resolution, resulting in over 1 million clips.
- A two-tier partitioning strategy is used: scene-level segmentation via PySceneDetect and action-level boundaries detected using RAFT-derived optical flow gradients to identify rapid actions like aiming.
- Data filtering removes low-quality content through multiple methods: quality assessment, OpenCV-based luminance filtering to exclude dark scenes, and VLM-driven gradient analysis for robust, multi-perspective filtering.
- Interaction annotation reconstructs 6-DoF camera trajectories using Monst3R, capturing detailed translational and rotational motion for each frame, enabling precise viewpoint control in video generation.
- Structured captioning employs game-specific vision-language models to generate two types of descriptions per clip: short summaries (≤30 characters) and detailed descriptions (>100 characters), both of which are randomly sampled during training.
- The dataset is used in training with a mixture of video clips and captions, where the processed clips and their corresponding annotations are combined to support end-to-end camera-controlled video generation.
Method
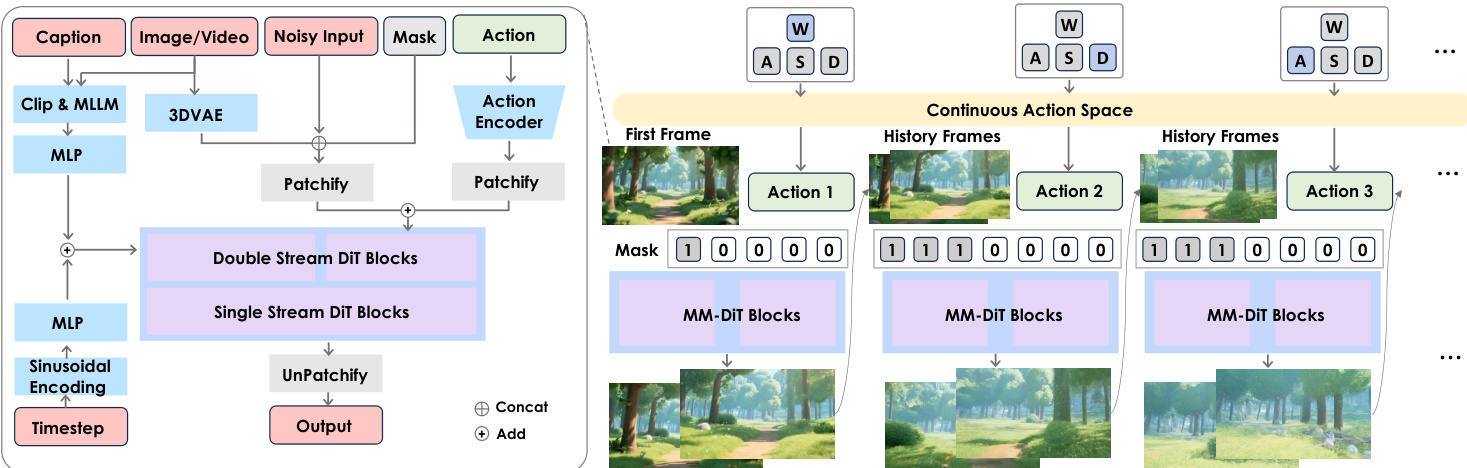
The authors leverage the HunyuanVideo framework, an open-sourced MM-DiT-based text-to-video model, as the foundation for Hunyuan-GameCraft, a system designed for high-dynamic interactive video generation in game environments. The overall architecture integrates multiple components to enable fine-grained control, long-term temporal coherence, and efficient inference. The framework begins with raw gameplay video data, which undergoes scene and action partitioning to extract relevant visual and control signals. These are processed through a quality filter to remove low-quality clips and annotated with structured captions and interaction information. The processed data is then used to train a model that combines image, video, and action inputs.
Refer to the framework diagram to understand the overall data flow and module interactions. The core of the model is built upon a dual-stream DiT architecture, which processes image/video and action inputs separately before fusing them. The image and video data are first encoded using a 3DVAE, while the action signals, derived from keyboard and mouse inputs, are processed by a lightweight action encoder. Both encoded streams are then patchified and combined with a learnable scaling coefficient to ensure stable feature fusion. The fused features are fed into the Double Stream DiT Blocks and Single Stream DiT Blocks, which perform the denoising process. The model also incorporates a sinusoidal encoding for the timestep and a Multi-Layer Perceptron (MLP) to process the caption and clip information. The final output is generated through an UnPatchify layer.

To achieve fine-grained action control, the authors unify standard keyboard and mouse inputs into a shared continuous camera representation space. This space, denoted as A, is defined as a subset of camera parameters C⊆Rn and is designed to be intuitive and continuous. The action space is parameterized by a translation direction dtrans∈S2, a rotation direction drot∈S2, a translation speed α∈[0,vmax], and a rotation speed β∈[0,ωmax]. This representation allows for precise control over camera movement and orientation, aligning with common gaming conventions. The action encoder, a lightweight network composed of convolutional and pooling layers, converts the discrete keyboard/mouse signals into this continuous space. The resulting camera pose information is then injected into the model using a token addition strategy, where dual lightweight learnable tokenizers facilitate efficient fusion between video and action tokens.
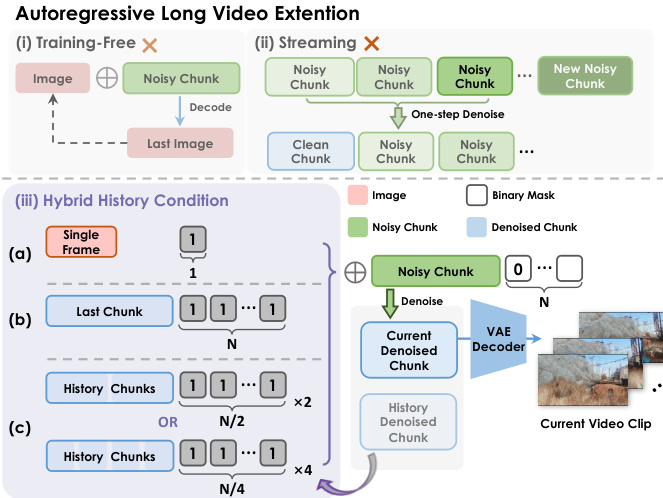
For long video generation, the model employs a hybrid history-conditioned training strategy. This approach extends video sequences autoregressively by denoising new noisy latent chunks conditioned on previously denoised historical chunks. The method uses a variable mask indicator, where 1s represent history frames and 0s represent predicted frames, to guide the denoising process. This hybrid condition ensures that the model preserves historical scene information while generating new content, maintaining temporal coherence and action controllability. The authors compare this approach to training-free inference and streaming generation, demonstrating that the hybrid history condition effectively prevents quality collapse and control degradation.
To enhance inference efficiency and playability, the authors implement model distillation based on the Phased Consistency Model (PCM). This technique distills the original diffusion process and classifier-free guidance into a compact eight-step consistency model, achieving a 10–20× acceleration in inference speed. The distillation process is further optimized using Classifier-Free Guidance Distillation, which trains a student model to directly produce guided outputs without relying on external guidance mechanisms. The objective function for this distillation is designed to minimize the difference between the student and teacher model outputs, enabling real-time rendering rates of 6.6 frames per second. This acceleration is crucial for enabling interactive gameplay experiences with low latency.
Experiment
- Hunyuan-GameCraft validates its effectiveness in image-to-video generation and long video extension through full-parameter training on 192 H20 GPUs, using a two-phase strategy with hybrid history conditioning (0.7 single clip, 0.05 multiple clips, 0.25 single frame) and data augmentation to balance action distributions.
- On a diverse test set of 150 images and 12 action signals, Hunyuan-GameCraft achieves state-of-the-art performance across multiple metrics: significantly outperforms Matrix-Game in dynamic performance (Dynamic Average), reduces interaction errors by 55% in cross-domain tests, and improves temporal consistency and visual quality.
- Quantitative results (Tab. 2) show Hunyuan-GameCraft surpasses baselines including CameraCtrl, MotionCtrl, WanX-Cam, and Matrix-Game in FVD, RPE trans/rot, Image Quality, Aesthetic Score, and Temporal Consistency.
- User studies (Tab. 3) confirm superior user preference, with Hunyuan-GameCraft receiving the highest average ranking scores (5/5) across both visual quality and interaction accuracy.
- Ablation studies (Tab. 4) demonstrate that hybrid history conditioning balances interaction accuracy and long-term consistency, token addition for control injection achieves optimal performance with low overhead, and balanced training on game and synthetic data ensures robust dynamic and interactive capabilities.
- The model generalizes to real-world scenarios, generating high-fidelity, high-dynamic videos with accurate camera control from real images, as shown in Fig. 10, and supports minute-long video extensions with consistent quality (Fig. 8).
Results show that Hunyuan-GameCraft achieves the best performance in dynamic capability and temporal consistency, with a Dynamic Average score of 67.2 and a Temporal Consistency score of 0.95, while also reducing Fréchet Video Distance to 1554.2. The method outperforms all baselines in interactive control accuracy and visual quality, and when combined with PCM, it further improves inference speed to 6.6 FPS.

The authors compare Hunyuan-GameCraft with several baselines across multiple dimensions, including game sources, resolution, action space, and scene generalization. Results show that Hunyuan-GameCraft achieves the best performance in scene generalizability, scene dynamic, and scene memory, while supporting a continuous action space and operating at 720p resolution.

Results show that Hunyuan-GameCraft outperforms all baselines across multiple metrics, achieving the highest scores in video quality, temporal consistency, motion smoothness, action accuracy, and dynamic capability. The authors use a hybrid history conditioning approach and optimized training strategy to enhance interactive control and long-term video generation, resulting in superior performance compared to existing methods.

The authors conduct an ablation study to evaluate the impact of different data distributions and conditioning strategies on model performance. Results show that training exclusively on synthetic data achieves high aesthetic quality and interaction accuracy but significantly degrades dynamic capability, while using only live gameplay data improves dynamic performance at the cost of interaction accuracy. The proposed hybrid approach, combining both data types and using a combination of image and clip conditioning, achieves the best overall balance, yielding the highest aesthetic score and competitive performance across all metrics.
