Command Palette
Search for a command to run...
Step1X-Edit: A Practical Framework for General Image Editing
Step1X-Edit: A Practical Framework for General Image Editing
Abstract
In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
One-sentence Summary
The Step1X-Image Team at StepFun proposes Step1X-Edit, a novel open-source image editing model that leverages a multimodal LLM to process user instructions and reference images, fusing latent embeddings with a diffusion decoder to generate high-fidelity edits; trained on a diverse 11-task dataset and evaluated via the new GEdit-Bench, it achieves performance close to proprietary models like GPT-4o and Gemini2 Flash, advancing accessible, high-quality image manipulation.
Key Contributions
-
Step1X-Edit addresses the performance gap between open-source and proprietary image editing models by leveraging a multimodal large language model (MLLM) to interpret user instructions and reference images, extracting a latent embedding that guides a diffusion image decoder to generate high-fidelity edited outputs with strong alignment to both the input and edit intent.
-
The model is trained on a large-scale, high-quality dataset generated via a scalable pipeline covering 11 diverse editing task categories, including object manipulation, attribute modification, and stylization, ensuring comprehensive coverage of real-world editing scenarios and enabling robust generalization.
-
Evaluation on the newly introduced GEdit-Bench, a benchmark built from real-world user instructions, demonstrates that Step1X-Edit significantly outperforms existing open-source models and approaches the performance of leading proprietary systems like GPT-4o, validating its effectiveness in practical image editing tasks.
Introduction
The authors leverage multimodal large language models (MLLMs) and diffusion architectures to address the growing demand for intuitive, natural language-driven image editing in applications ranging from creative design to content generation. While recent proprietary models like GPT-4o and Gemini2 Flash achieve high-fidelity, context-aware edits, open-source alternatives lag due to limited training data quality, narrow task coverage, and weak alignment between instructions and visual outputs. To bridge this gap, the authors introduce Step1X-Edit, a unified framework that integrates MLLM-based semantic reasoning with a DiT-style diffusion decoder, enabling precise, general-purpose editing while preserving image fidelity. Their key contributions include a scalable data generation pipeline producing over 1 million high-quality image-editing pairs across 11 diverse task categories, a new benchmark—GEdit-Bench—curated from real-world user instructions to enable more authentic evaluation, and an open-source model that significantly closes the performance gap with proprietary systems.
Dataset
- The dataset, named Step1X-Edit, is a large-scale, high-quality collection of over 20 million instruction-image triplets (source image, editing instruction, target image), assembled through web crawling and systematic categorization into 11 distinct image editing tasks.
- After rigorous filtering using multimodal LLMs (e.g., Step-1o) and human annotators, more than 1 million high-quality triplets are retained, forming the Step1X-Edit-HQ subset, which surpasses existing datasets in scale and maintains strong absolute magnitude post-filtering.
- The 11 categories include: Subject Addition & Removal, Subject Replacement & Background Change, Color Alteration & Material Modification, Text Modification, Motion Change, Portrait Editing and Beautification, Style Transfer, and Tone Transformation.
- For Subject Addition/Removal and Replacement/Background Change, the pipeline uses Florence-2 for semantic annotation, SAM-2 for segmentation, ObjectRemovalAlpha or Flux-Fill for inpainting, and Step-1o/GPT-4o for instruction generation, followed by human validation.
- Color and material edits use Zeodepth for depth estimation and ControlNet with diffusion models to preserve object identity while modifying appearance.
- Text modification leverages PPOCR for character recognition and Step-1o to identify valid/invalid regions, with final outputs refined via manual retouching.
- Motion change is derived from frame pairs in Koala-36M videos, processed with BiRefNet and RAFT for foreground-background separation and optical flow estimation, with GPT-4o generating motion-related instructions.
- Portrait editing combines public beautification pairs and human-led edits, with all data manually validated for consistency.
- Style Transfer is bidirectional: stylized inputs are converted to photorealistic outputs using edge-guided diffusion models, while realistic inputs are transformed into stylized outputs using the same pipeline.
- Tone Transformation applies algorithmic filters to simulate global adjustments like dehazing, deraining, and seasonal changes.
- A redundancy-enhanced annotation strategy is used, where multiple rounds of model and human refinement improve instruction quality and reduce hallucinations.
- Stylized annotation is guided by contextual examples to ensure consistent tone, structure, and granularity across the dataset.
- All annotations are bilingual (Chinese-English), enhancing accessibility and supporting multilingual model training.
- The dataset is used to train models with a mixture of task-specific ratios, leveraging the diverse subtasks to improve generalization across editing domains.
- A cropping strategy is applied during data processing to focus on relevant image regions, particularly for tasks involving object-level edits.
- Metadata includes task category, editing type, object labels, and transformation details, constructed through automated and manual pipelines.
- The GEdit-Bench benchmark, derived from over 1,000 real-world user editing instances collected from Reddit, is used to evaluate model performance on authentic, practical editing tasks.
- To ensure privacy, a de-identification protocol is applied: original images are replaced with visually and semantically similar public alternatives via reverse image search, or modified with minimal, intent-preserving changes when no match is found.
Method
The authors leverage a unified framework for general image editing that integrates a Multimedia Large Language Model (MLLM), a connector module, and a Diffusion in Transformer (DiT) architecture. The overall process begins with an editing instruction and a reference image being jointly processed by the MLLM, such as Qwen-VL, through a single forward pass. This enables the model to capture semantic relationships between the textual instruction and the visual content. To focus on the editing-relevant information, the token embeddings corresponding to the system prefix are discarded, retaining only those aligned with the edit instruction. The resulting embeddings are then passed to a lightweight connector module, such as the token refiner, which restructures them into a compact multimodal feature representation suitable for the DiT network. Additionally, the mean of the valid embeddings from the MLLM is projected via a linear layer to generate a global guidance vector, allowing the DiT to benefit from the MLLM's enhanced semantic understanding.
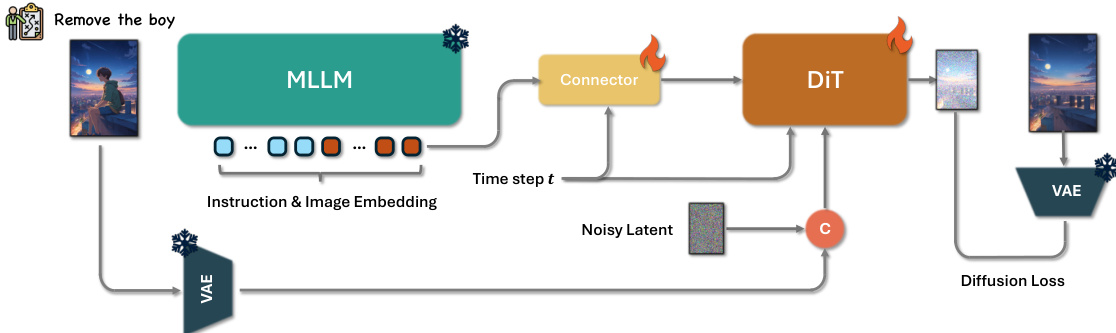
The DiT module, as detailed in the accompanying diagram, operates on latent representations. During training, the reference image is encoded by a Variational Autoencoder (VAE) encoder, and its latent features are linearly projected into image tokens. As shown in the figure below, these image tokens are concatenated with noise image tokens along the token length dimension to form the final visual input for the DiT. The DiT processes this input through multiple blocks, with the connector module providing additional conditioning information derived from the MLLM embeddings. The model is trained using a diffusion loss based on the rectified flow formulation, jointly optimizing the connector and the DiT. This training strategy ensures stability without relying on mask loss tricks, and a fixed learning rate of 1e−5 is used to balance convergence speed and training stability.

To facilitate effective cross-modal conditioning, the authors design a feature aggregation strategy that uses token concatenation, following the approach of OminiControl. This method balances responsiveness to editing instructions with the preservation of fine-grained image details, contrasting with other methods that employ channel concatenation or additional causal self-attention mechanisms. The connector module plays a crucial role in this process by transforming the MLLM's output into a form that can be effectively integrated with the DiT's latent space, enabling the model to perform high-fidelity, semantically aligned edits across a diverse range of user instructions.
Experiment
- Evaluated on GEdit-Bench-EN and GEdit-Bench-CN using SQ, PQ, and O metrics; Step1X-Edit outperforms open-source models like OmniGen and achieves comparable results to closed-source models such as Gemini2 Flash and Doubao, surpassing them in style change and color alteration on GEdit-Bench-EN and excelling in Chinese instruction handling on GEdit-Bench-CN.
- On GEdit-Bench-EN, Step1X-Edit achieves the highest overall score in the Intersection subset, with strong performance across 11 evaluation axes, demonstrating robustness and consistency without requiring masks.
- In user studies with 55 participants, Step1X-Edit achieves high subjective preference scores, ranking competitively against Gemini2 Flash, GPT-4o, and Doubao, with results indicating strong user preference, particularly in identity preservation and visual quality.
The authors use GEdit-Bench-CN to evaluate image editing models, reporting results on both the Intersection subset and Full set. Results show that Step1X-Edit-v1.1 achieves the highest scores across all metrics in the Intersection subset, outperforming Gemini [15], Doubao [50], and GPT-4o [37], and maintains strong performance in the Full set, demonstrating its effectiveness in handling diverse editing tasks.

The authors use a user study to evaluate the subjective quality of image editing results, comparing Step1X-Edit with Gemini2 Flash, Doubao, and GPT-4o on the GEdit-Bench. Results show that Step1X-Edit achieves comparable user preference scores to state-of-the-art models, with its performance being particularly strong in the Intersection subset, while Gemini2 Flash receives a notably high score due to its strong identity-preserving capabilities.

Results show that Step1X-Edit achieves a user preference score of 6.544 on the Intersection subset and 6.939 on the Full set, outperforming Gemini [15] and Doubao [50] in both metrics. The authors use these scores to demonstrate that Step1X-Edit produces editing results with subjective quality comparable to state-of-the-art models, particularly excelling in the Full set where it surpasses Gemini and Doubao.

The authors use GEdit-Bench to evaluate image editing models, with results showing Step1X-Edit outperforming open-source models and achieving competitive results against closed-source models like Gemini2 Flash and GPT-4o in both the Intersection and Full sets. Results show Step1X-Edit achieves the highest scores across most metrics in the GEdit-Bench-EN evaluation, particularly in semantic consistency and overall quality, indicating strong performance in aligning with editing instructions.
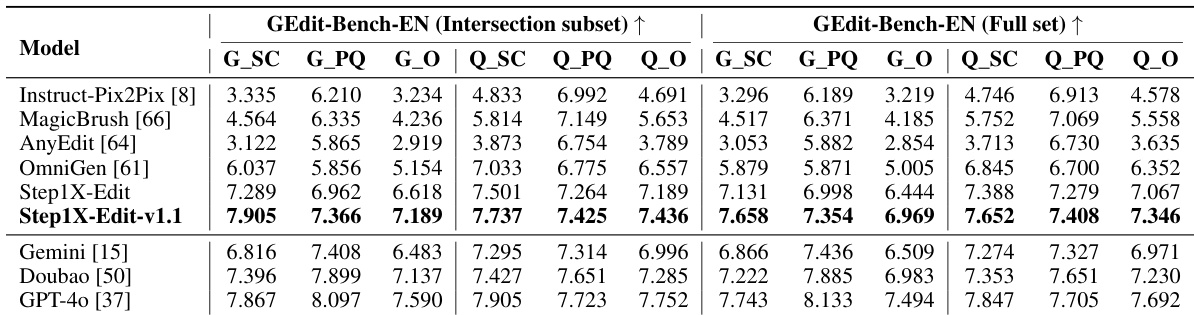
The authors use GEdit-Bench to evaluate image editing models, comparing their performance against state-of-the-art open-source and proprietary systems. Results show that Step1X-Edit outperforms existing open-source models and achieves competitive results with closed-source models like Gemini2 Flash and GPT-4o across both English and Chinese instructions.
