Command Palette
Search for a command to run...
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Abstract
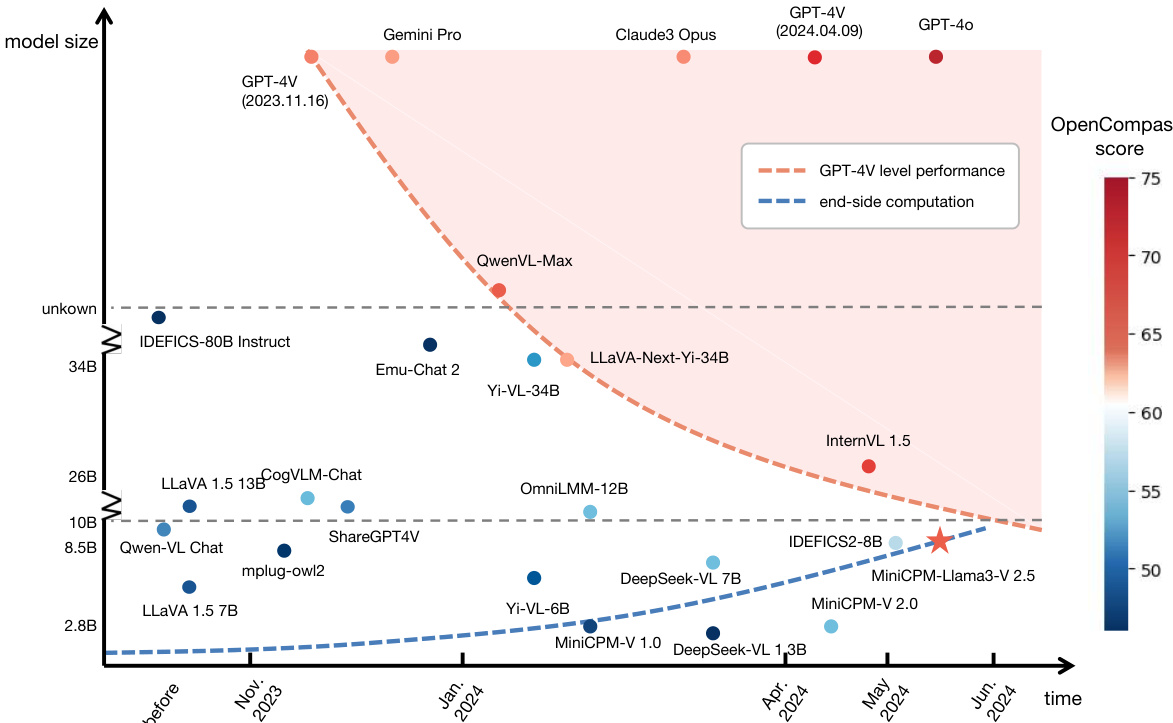
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
One-sentence Summary
The authors, from MiniCPM-V Team and OpenBMB, propose MiniCPM-V, a series of efficient multimodal large language models that achieve GPT-4V-level performance with significantly reduced size, enabling high-resolution image understanding, low-hallucination behavior, multilingual support, and mobile deployment—representing a key trend toward on-device AI and expanding real-world applications in privacy-sensitive and resource-constrained environments.
Key Contributions
- MiniCPM-V addresses the critical challenge of deploying high-performance Multimodal Large Language Models (MLLMs) on resource-constrained end-side devices, enabling practical applications in mobile, offline, and privacy-sensitive scenarios where cloud-based inference is infeasible.
- The latest MiniCPM-Llama3-V 2.5 achieves state-of-the-art performance on OpenCompass across 11 benchmarks, surpassing GPT-4V-1106, Gemini Pro, and Claude 3, through optimized architecture, training recipes, and high-resolution image perception up to 1.8M pixels at any aspect ratio.
- It demonstrates trustworthy behavior with reduced hallucination rates, strong OCR capabilities including table-to-markdown conversion, and support for 30+ languages, enabling efficient and reliable deployment on mobile devices while aligning with a broader trend of shrinking model sizes and increasing end-device compute capacity.
Introduction
The authors leverage recent advances in multimodal large language models (MLLMs) to address the critical challenge of deploying high-performance models on end-side devices like smartphones, where computational resources are constrained by memory, power, and processing speed. Prior work has largely relied on massive cloud-based MLLMs, which limit real-world applicability in privacy-sensitive, offline, or energy-constrained environments. Despite progress in lightweight models, achieving GPT-4V-level performance on such devices remained elusive due to trade-offs between model size, inference efficiency, and capability. The authors’ main contribution is MiniCPM-V, a series of efficient MLLMs that achieve state-of-the-art performance—surpassing GPT-4V, Gemini Pro, and Claude 3 on OpenCompass—while being deployable on mobile phones. Key innovations include adaptive high-resolution image encoding (supporting up to 1.8M pixels), RLAIF-V-based alignment for reduced hallucination, multilingual generalization via instruction tuning, and comprehensive end-side optimizations including quantization and NPU acceleration. The work also identifies a promising trend akin to Moore’s Law in MLLMs: decreasing model size for equivalent performance, driven by both model efficiency and rising end-device compute capacity, signaling a shift toward powerful, on-device multimodal AI.
Dataset
- The dataset comprises diverse image-text pairs sourced from multiple origins, including real-world scenes, product images, and synthetic or augmented data, designed to support multimodal understanding across languages and visual complexities.
- Key subsets include:
- A Korean food-focused subset featuring traditional dishes like bibimbap, with images showing preparation stages, ingredients (e.g., gochujang, vegetables, seaweed), and serving vessels, sourced from curated culinary photography.
- A transportation and infrastructure subset capturing gas stations and truck parking areas, with detailed visual descriptions of vehicles, shelters, fuel pumps, signage, and environmental context, drawn from real-world urban and industrial imagery.
- A multilingual evaluation subset containing image-text pairs in multiple languages, used to assess cross-lingual performance, including English, Korean, and others, with annotations reflecting linguistic diversity.
- The authors use the data for training with a mixture of ratios favoring high-quality, diverse, and linguistically rich samples; the training split is constructed to balance domain coverage and avoid overfitting to specific visual or linguistic patterns.
- Images undergo preprocessing including aspect ratio normalization, resolution scaling, and cropping to focus on salient regions, particularly in cases involving extreme aspect ratios or cluttered scenes.
- Metadata is constructed to include language tags, object annotations, and scene descriptions, with hallucinated or incorrect outputs explicitly marked in red in qualitative evaluations to highlight model limitations.
- The dataset supports both fine-grained detail captioning and scene-text understanding tasks, with emphasis on accurate visual grounding and cross-lingual consistency.
Method
The authors leverage a modular architecture for MiniCPM-V, designed to balance performance and efficiency for real-world deployment. The overall framework consists of three primary components: a visual encoder, a compression layer, and a large language model (LLM). The input image is first processed by the visual encoder, which extracts visual features. These features are then passed through a compression layer to reduce the number of visual tokens, and finally, the compressed visual tokens are combined with the text input and fed into the LLM for conditional text generation. This modular design allows for efficient handling of high-resolution images while maintaining strong multimodal capabilities.
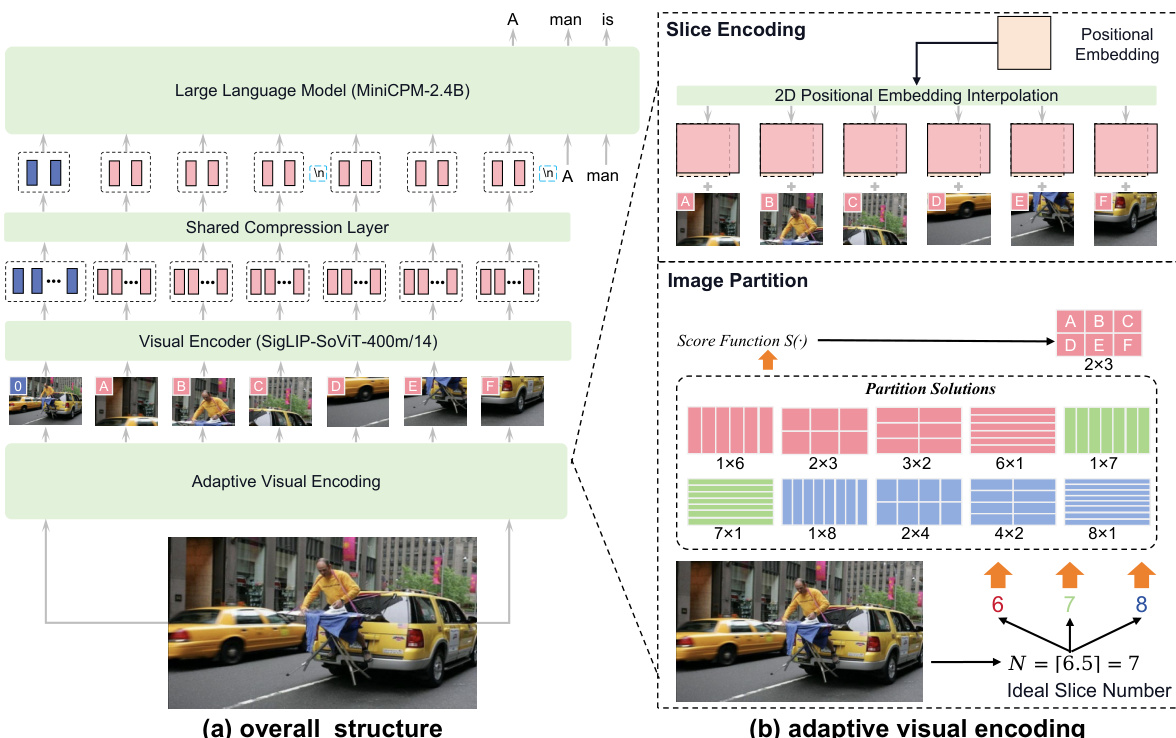
The visual encoding process is a key innovation, designed to handle high-resolution images with arbitrary aspect ratios effectively. The method begins with image partitioning, where the input image is divided into a grid of slices. The number of slices is determined by the ratio of the input image area to the pre-training area of the visual encoder, calculated as N=⌈Wv×HvWI×HI⌉. To find the optimal partition, a score function evaluates potential combinations of rows and columns, S(m,n), which measures the deviation of the slice aspect ratio from the pre-training aspect ratio. The partition with the highest score is selected. This process ensures that each slice is well-suited for the visual encoder's pre-training setting. Following partitioning, each slice undergoes encoding. The slices are resized proportionally to match the pre-training area, and the visual encoder's position embeddings are interpolated to adapt to the new slice dimensions. This step is crucial for maintaining the integrity of the visual features. The authors also include the original image as an additional slice to provide holistic context.
After visual encoding, the model employs a token compression module to manage the high number of visual tokens generated by the encoder. This module uses a single-layer cross-attention mechanism with a fixed number of queries to compress the visual tokens. For MiniCPM-V 1.0 and 2.0, the visual tokens are compressed into 64 queries, while MiniCPM-Llama3-V 2.5 uses 96 tokens. This compression significantly reduces the computational load and memory footprint, enabling the model to be more efficient and suitable for deployment on end-side devices. To preserve spatial information, a spatial schema is introduced, where each slice's tokens are wrapped with special tokens <slice> and </slice>, and slices from different rows are separated by a newline token \n.
The training process for MiniCPM-V is structured in three phases to ensure robust and efficient learning. The first phase is pre-training, which is divided into three stages. Stage-1 focuses on warming up the compression layer by training it while keeping the visual encoder and LLM frozen. Stage-2 extends the input resolution of the visual encoder from 224×224 to 448×448, training the entire visual encoder. Stage-3 further trains the visual encoder and compression layer using the adaptive visual encoding strategy to handle high-resolution inputs with any aspect ratio. This phase also introduces OCR data to enhance the model's OCR capabilities. To improve data quality, a caption rewriting model is used to correct low-quality captions. Data packing is employed to manage the variance in sample lengths, improving memory efficiency and computational speed.
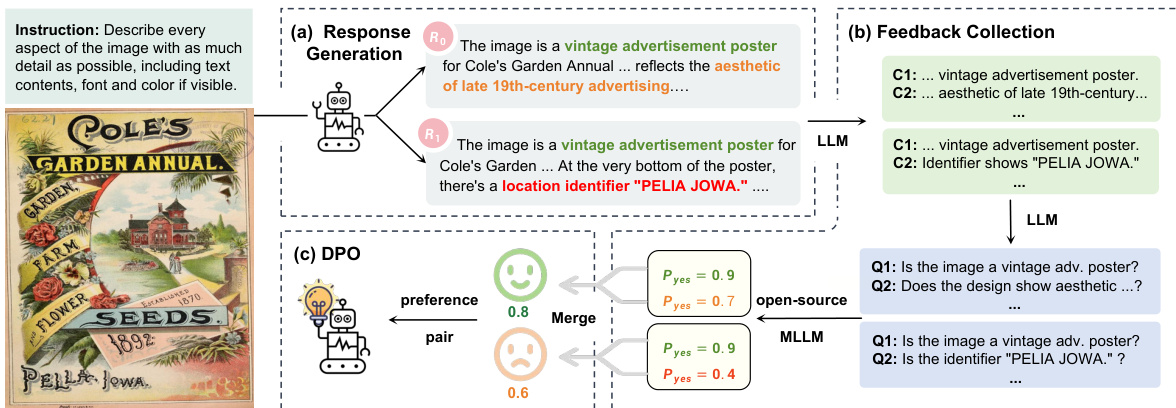
The second phase is supervised fine-tuning (SFT), where the model is trained on high-quality, human-annotated datasets to learn interaction capabilities. The SFT data is split into two parts: Part-1 focuses on basic recognition, while Part-2 enhances the model's ability to generate detailed responses and follow instructions. The final phase is RLAIF-V, which uses a divide-and-conquer approach to reduce hallucinations. This involves generating multiple responses, collecting feedback on their correctness, and using DPO (Direct Preference Optimization) to optimize the model based on the preference dataset. This multi-phase training strategy ensures that the model is both powerful and reliable.
Experiment
- End-side deployment experiments validate the feasibility of running MiniCPM-Llama3-V 2.5 on mobile and edge devices through quantization and framework optimization.
- Basic practice using Q4_K_M 4-bit quantization in the GGML framework reduces memory usage from 16–17G to ~5G, enabling deployment on mobile devices.
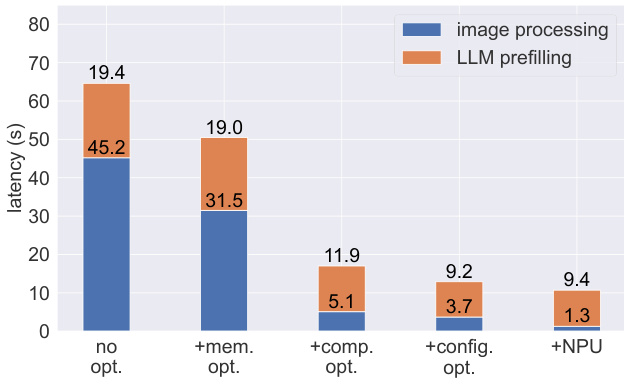
- Advanced practices including memory usage optimization, compilation optimization, configuration optimization, and NPU acceleration significantly improve performance: encoding latency drops from 64.2s to 17.0s, and decoding throughput increases from 1.3 to 8.2 tokens/s on Xiaomi 14 Pro.
- NPU acceleration reduces visual encoding time from 3.7s to 1.3s, achieving performance comparable to Mac M1 on Xiaomi 14 Pro.
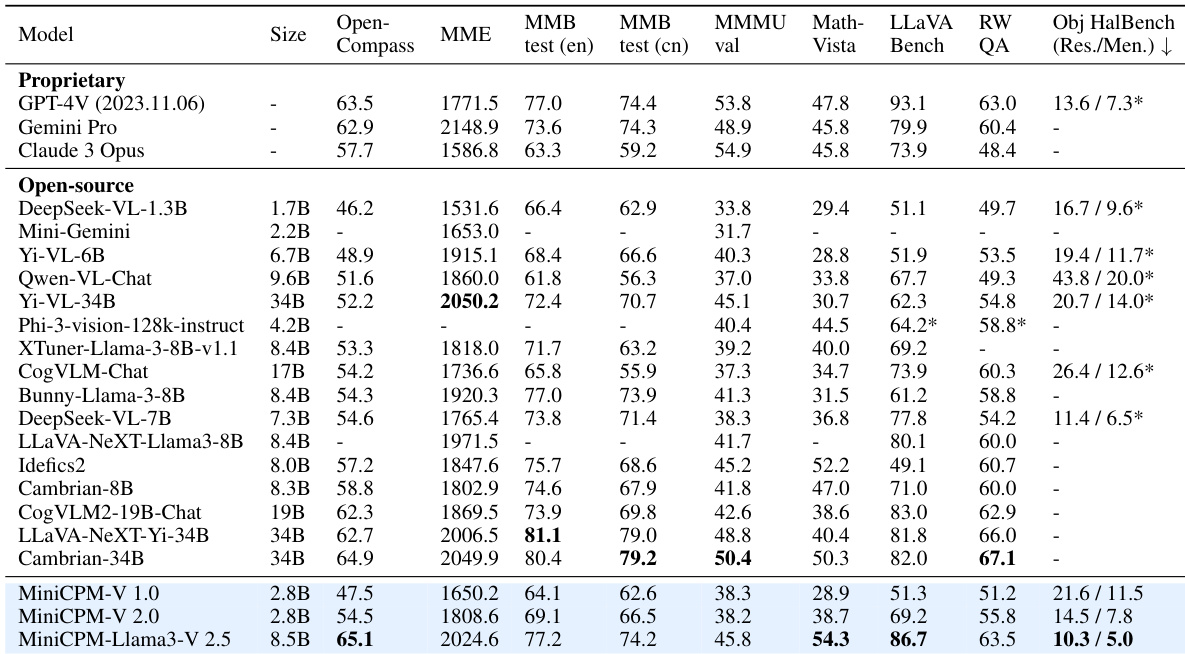
- On the OpenCompass benchmark, MiniCPM-Llama3-V 2.5 surpasses strong open-source models like Idefics2-8B by 7.9 points and outperforms larger models such as Cambrian-34B and LLaVA-NeXT-Yi-34B, while achieving better results than proprietary models GPT-4V-1106 and Gemini Pro with significantly fewer parameters.
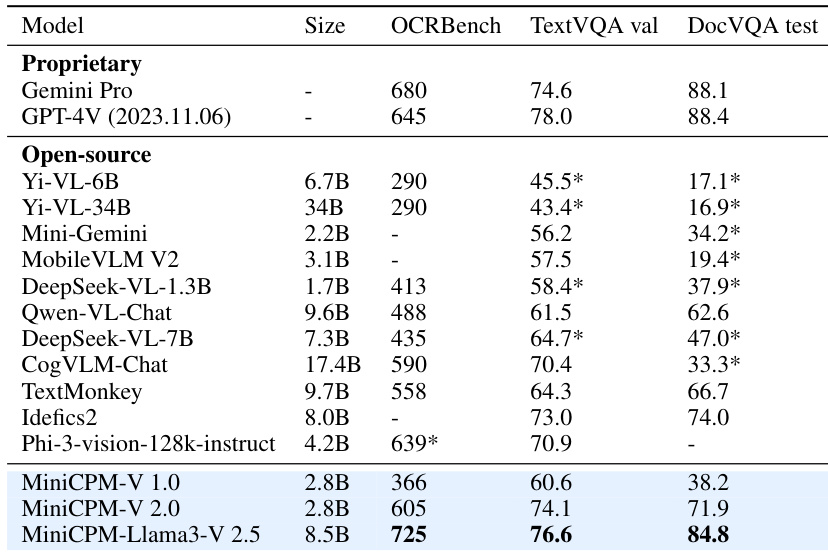
- On OCR benchmarks (OCR-Bench, TextVQA, DocVQA), MiniCPM-Llama3-V 2.5 outperforms open-source models (1.7B–34B) and matches proprietary models like GPT-4V-1106 and Gemini Pro.
- The model achieves multilingual multimodal capability across over 30 languages, outperforming Yi-VL-34B and Phi-3-Vision-128k-instruct on multilingual LLaVA Bench.
- Ablation studies confirm that RLAIF-V reduces hallucination rates without sacrificing performance, improving OpenCompass scores by 0.6 points on average.
- Multilingual generalization with less than 0.5% SFT data yields over 25-point gains in multilingual performance, demonstrating high data efficiency.
- Case studies demonstrate strong OCR, high-resolution extreme aspect ratio input handling, and trustworthy behavior with fewer hallucinations than GPT-4V.
The authors use MiniCPM-V 2.5 to achieve strong performance on multimodal benchmarks while maintaining efficiency, outperforming larger open-source models and approaching proprietary models like GPT-4V and Gemini Pro in both general capabilities and OCR tasks. The model's effectiveness is enhanced by techniques such as RLAIF-V for reducing hallucinations and multilingual generalization, enabling robust performance across diverse languages and real-world applications.

The authors compare MiniCPM-V 2.5 with other open-source and proprietary models on OCR and text understanding benchmarks, showing that MiniCPM-Llama3-V 2.5 achieves the highest scores on OCRBench, TextVQA, and DocVQA, outperforming models like Yi-VL-34B and GPT-4V in these tasks. Results indicate that MiniCPM-V 2.5 delivers strong OCR and multimodal understanding capabilities despite its smaller size, demonstrating competitive performance across multiple benchmarks.
The authors use MiniCPM-Llama3-V 2.5 to achieve state-of-the-art performance on general multimodal benchmarks, outperforming strong open-source models and approaching or exceeding proprietary models like GPT-4V and Gemini Pro despite having significantly fewer parameters. Results show that MiniCPM-V 2.5 achieves a good balance between performance and efficiency, with strong OCR capabilities, multilingual support, and reduced hallucination rates, making it suitable for real-world applications.
The authors use an ablation study to evaluate the impact of RLAIF-V on MiniCPM-Llama3-V 2.5, showing that incorporating RLAIF-V improves performance across multiple benchmarks while reducing hallucination rates. Results indicate that the model with RLAIF-V achieves higher scores on OpenCompass, MME, MMB dev, MMMU, Math-Vista, LLaVA Bench, and Object HalBench compared to the version without RLAIF-V.

The authors use a series of optimization techniques to reduce the latency of MiniCPM-Llama3-V 2.5 on end-side devices, with results showing that memory usage optimization reduces image processing time from 45.2s to 31.5s, and further optimizations including compilation, configuration, and NPU acceleration progressively lower the total latency to 1.3s. Results show that the combination of these techniques enables the model to achieve efficient inference on mobile devices, with the final NPU-accelerated configuration achieving a decoding throughput of 8.2 tokens/s, surpassing typical human reading speed.