Command Palette
Search for a command to run...
Astronomaly: Identifying Anomalies in 4 Million Galaxy Images Using CNNs and Active Learning

Anomalies in galaxies are key to our understanding of the universe. However, with the development of astronomical observation technology, astronomical data is growing exponentially, exceeding the analytical capabilities of astronomers.
Although volunteers can participate in the processing of astronomical data online, they can only perform some simple classifications and may miss some key data.
To this end, researchers developed the Astronomaly algorithm based on convolutional neural networks and unsupervised learning. Recently, researchers from the University of the Western Cape used Astronomaly for large-scale data analysis for the first time, trying to find anomalies in the universe from 4 million galaxy photos.
Author | Xuecai
Editor | Three Sheep, Iron Tower
This article was first published on HyperAI WeChat public platform~
Anomalies in galaxies are key to our understanding of the universe.By analyzing images recorded by Survey Telescopes, researchers can identify anomalies in galaxies and make inferences about the origin and evolution of the universe.
However, this process is facing severe challenges.Because the amount of astronomical observation data is growing exponentially.Take the Vera Rubin Observatory, which is about to be put into use, for example. This observatory has the world's largest digital camera and is expected to record 20 TB of data every night, 60 PB of data in ten years, and make 32 trillion observations of about 20 billion galaxies.Far beyond the limits of what researchers can analyze humanly.

Figure 1: The Vera Rubin Observatory under construction
In July 2007, some researchers launched the Galaxy Zoo project.Advancing astronomical observation image classification by recruiting volunteers onlineThe project attracted about 150,000 volunteers to make more than 40 million classifications of 1 million galaxy images recorded by the Sloan Digital Sky Survey (SDSS).
Figure 2: Galaxy Zoo project homepage
But the volunteers could only do basic work and could easily miss details in the images.Machine learning excels in image analysis and data classification, and has great potential in astronomical analysis.Supervised learning has been widely used in astronomical data analysis,However, these algorithms require a lot of training data and pre-definition, and perform poorly in finding anomalies.
To this end, in 2021, researchers developed an unsupervised machine learning algorithm called Astronomaly based on a convolutional neural network (CNN), which has excellent performance in different tasks. Recently, researchers from the University of the Western Cape used Astronomaly to analyze about 4 million galaxy images.This algorithm was applied for the first time to large-scale data analysis and discovered anomalies that had previously been overlooked.This result has been published as a preprint on arXiv.
This result has been published on arXiv
Paper link:
https://arxiv.org/abs/2309.08660
Experimental procedures
Dataset: Dark Energy Survey Camera
The data sets of this study are mainly images recorded in the g, r, and z bands in the eighth batch of public data (DR8) of the Dark Energy Camera for Surveys (DECaLS).
The images in the dataset were then screened to remove images obscured by artifacts and stars, and to exclude images that did not conform to the standard galaxy model.That leaves 3,884,404 galaxy images.
Feature extraction:CNN + PCA
In order to improve the computational efficiency of Astronomaly, it is necessary to extract features from high-dimensional images and transform them into low-dimensional vectors.
This study uses pre-trained CNN to extract features from images. Each layer of CNN transforms the input image differently and generates a vector that can represent the image features.
The CNN ultimately output a vector of 1,280 image features. The researchers then used principal component analysis (PCA) to further reduce the data dimensionality. PCA is a common statistical method that can transform a set of correlated variables into uncorrelated principal components based on the variance of the data.Through PCA, the dimension of the image is further reduced to 26, which improves the processing efficiency of Astronomaly.
Abnormal monitoring:iForest + Active Learning
Astronomaly combines the isolation forest (iForest) and local outlier factor (LOF) algorithms for anomaly monitoring.In data testing, the LOF algorithm is difficult to apply to large-scale data, while the iForest algorithm can quickly find anomalies in images through decision trees. Therefore, the iForest algorithm was used in subsequent analysis.
Subsequently, Astronomaly performs active learning through the K-nearest neighbor algorithm (NS) and direct regression algorithm (DR) to continuously update the anomaly scores of the images in the dataset.
The NS algorithm can predict the user's ratings for all images based on a small amount of manually annotated ratings through the random forest regression algorithm, while the DR algorithm directly tries to "simulate" the user's ratings for the images.
Finally, the scoring results of the two algorithms will be compared with the results of manually annotated data for evaluation.

Figure 3: Some of the annotated images
The results of Label 0 are artifacts, masks, and low signal-to-noise ratio from left to right. The results of Label 5 are galaxy mergers, gravitational lenses, and unclassified from left to right.
Gravitational lensing refers to the effect in which a strong gravitational body causes nearby light to no longer propagate in a straight line, similar to the refraction of light by a lens.
Comparative Verification:Recall curve + UMAP
The researchers used iForest, NS and DR algorithms to predict the data in the validation set. The evaluation set contains 184 anomalies. The iForest algorithm found only 15 anomalies in the 500 images with the highest anomaly scores, while the DR and NS algorithms found 84 anomalies each.
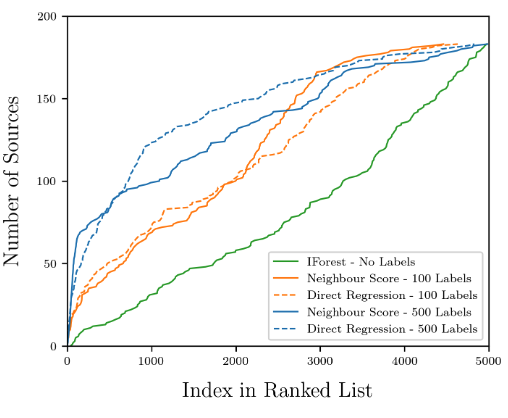
Figure 4: Prediction results of different algorithms
Furthermore, the researchers classified the prediction results of the iForest and NS algorithms according to artifacts, gravitational lenses, and galaxy mergers, and discovered the reasons why the iForest algorithm performed poorly.
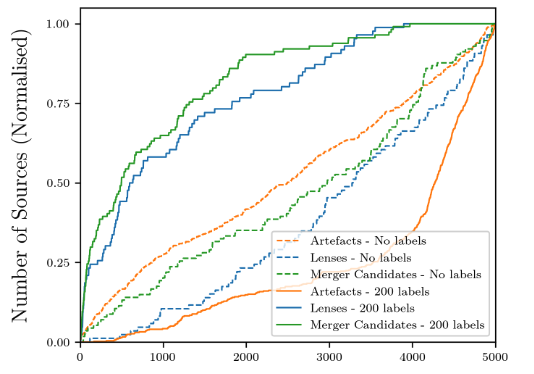
Figure 5: Classification of results of iForest (dashed line) and NS (solid line) algorithms
As shown in the figure, most of the anomalies found by the iForest algorithm are artifacts.Although these technical anomalies are also abnormal, they have no scientific value.NS and DR algorithms can help Astronomaly quickly eliminate the interference of artifacts and find abnormal phenomena in the universe.
At the same time, the researchers used the Uniform Manifold Approximation and Projection (UMAP) method to classify the images in the validation set.
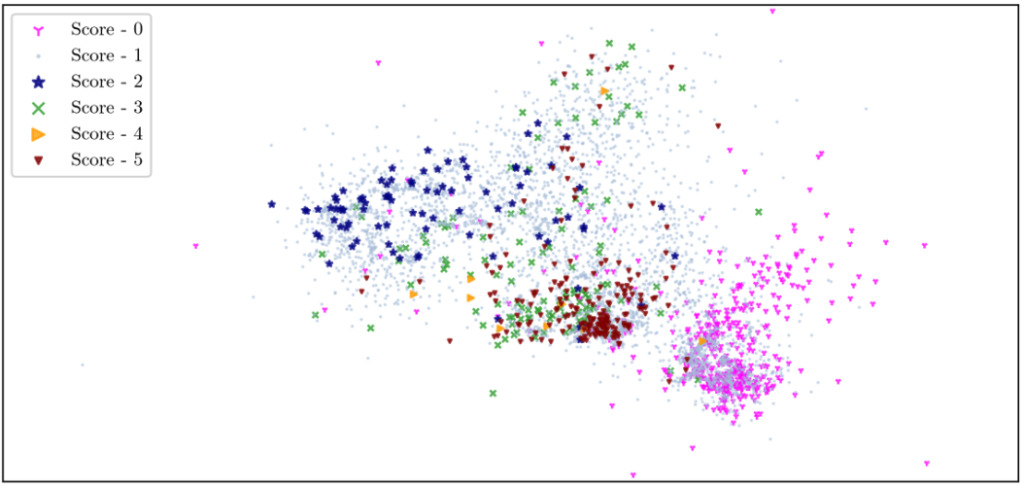
Figure 6: UMAP results of the evaluation set
UMAP classifies images based on their anomaly scores. Images with a score of 1 are ordinary galaxy images, that is, galaxies without any special circumstances. There are a large number of ordinary images with a score of 1 around each type of image, which provides obstacles for the prediction of the iForest algorithm.
It can be seen that the artifacts with a score of 0 and the anomalies with a score of 5 are divided into tight clusters in the figure, indicating that both types of images have very obvious characteristics. However, at the same time, the distribution of the two types of images is very close, which can easily cause the iForest algorithm to make misjudgments.
Large-scale application:Annotate and explore
After evaluating the performance of different algorithms, the researchers applied the NS algorithm to the entire dataset.
As can be seen in the figure, when no data is labeled, that is, when the iForest algorithm has no active learning, there is almost no curve in the results, because the iForest algorithm only finds one anomaly among the 2,000 data with the highest anomaly scores.
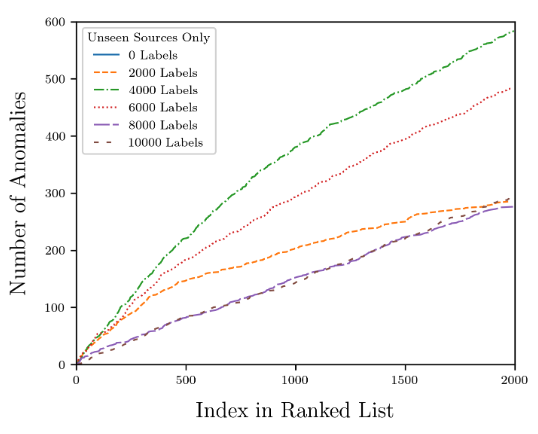
Figure 7: Prediction results of the NS algorithm with different numbers of annotations
However, after annotating 2,000 data points in the dataset, Astronomaly was able to quickly find anomalies in the images through active learning.When the number of annotations is 4,000, Astronomaly has the most newly discovered anomalies., and then begins to decrease, indicating that no additional annotation is needed at this time and the data set can be increased.
Follow-up investigation:1635/2000
After analyzing all the images in the dataset, Astronomaly found 1,635 anomalies in the 2,000 images with the highest anomaly scores, including 8 gravitational lenses, 18 unclassified phenomena, and 1,609 galaxy mergers.

Figure 8: Gravitational lens discovered by Astronomaly

Figure 9: Unclassified anomalies found by Astronomaly

Figure 10: Galaxy merger discovered by Astronomaly
AI heading into space
As the amount of astronomical observation data continues to increase, the status of AI, which is good at data analysis, in astronomy is gradually improving.As early as 2020, researchers at the University of Warwick in the UK used AI to find 50 new planets from NASA's old data.
At the same time, the Five-hundred-meter Aperture Spherical Radio Telescope (FAST), known as the "China Sky Eye," is also facing the problem of too much data.AI provides them with a solutionIn 2021, FAST cooperated with Tencent Youtu Lab to analyze FAST data and quickly found 5 pulsars.
AI is also playing its part in other areas. In 2019, the Event Horizon Telescope (ETH) team released the world’s first photo of a black hole. Four years later,Researchers in the United States used AI to process the photo and obtained a higher-resolution photo of the black hole, "beautifying" the black hole.

Figure 11:The original black hole photo (left) and the processed black hole photo (right)
Perhaps like humans, AI also has the ambition to explore the stars and the sea. Now it has stepped into the universe, looking for clues to the evolution of the universe in the vast amount of data. From new planets to new pulsars to new cosmic anomalies, AI is opening up a new future for astronomy.
Reference Links:
[1]https://zoo4.galaxyzoo.org/?lang=zh_cn#/classify
[2]https://www.cas.cn/kj/202009/t20200901_4757754.shtml
[3]https://www.thepaper.cn/newsDetail_forward_22699012
This article was first published on HyperAI WeChat public platform~








