YOLOv12의 원클릭 배포
1. 튜토리얼 소개 📖

YOLOv12는 버팔로 대학과 중국과학원 대학의 연구원들에 의해 2025년에 출시되었습니다.YOLOv12: 주의 중심 실시간 객체 감지기".
YOLOv12의 획기적인 성능
- YOLOv12-N은 T4 GPU에서 1.64밀리초의 추론 지연 시간과 함께 40.6%의 mAP를 달성하는데, 이는 YOLOv10-N/YOLOv11-N보다 2.1%/1.2% 더 높습니다.
- YOLOv12-S는 RT-DETR-R18 / RT-DETRv2-R18보다 성능이 뛰어나며, 연산량은 36%에 불과하고 매개변수도 45%만큼 줄었습니다.
📜 YOLO 개발 역사 및 관련 튜토리얼
YOLO(You Only Look Once)는 2015년 출시 이후 객체 감지 및 이미지 분할 분야를 선도해 왔습니다.YOLO 시리즈와 관련 튜토리얼의 발전 과정은 다음과 같습니다.
- YOLOv2(2016): 배치 정규화, 앵커 박스, 차원 클러스터링을 소개합니다.
- YOLOv3(2018): 보다 효율적인 백본 네트워크, 멀티 앵커, 공간 피라미드 풀링을 사용합니다.
- YOLOv4(2020): Mosaic 데이터 증강, 앵커 없는 감지 헤드 및 새로운 손실 함수를 소개합니다. → 튜토리얼:DeepSOCIAL은 YOLOv4 기반 군중 거리 모니터링 및 다중 타겟 추적을 구현합니다.
- YOLOv5(2020): 하이퍼파라미터 최적화, 실험 추적 및 자동 내보내기 기능이 추가되었습니다. → 튜토리얼:YOLOv5_deepsort 실시간 다중 타겟 추적 모델
- YOLOv6(2022): 메이투안은 오픈소스로, 자율 배송 로봇에 널리 사용됩니다.
- YOLOv7(2022): COCO 키포인트 데이터 세트에 대한 포즈 추정을 지원합니다. → 튜토리얼:사용자 정의 YOLOv7 모델을 훈련하고 사용하는 방법
- YOLOv8(2023):Ultralytics가 출시되어 다양한 시각 AI 작업을 지원합니다. → 튜토리얼:사용자 정의 데이터로 YOLOv8 학습
- YOLOv9(2024): 프로그래밍 가능 그래디언트 정보(PGI)와 일반화된 효율적 계층 집계 네트워크(GELAN) 소개.
- YOLOv10(2024): 청화대학교에서 출시한 이 기술은 엔드투엔드 헤더를 도입하고 비최대 억제(NMS) 요구 사항을 제거합니다. → 튜토리얼:YOLOv10 실시간 엔드투엔드 객체 감지
- YOLOv11(2024): Ultralytics의 최신 모델로, 감지, 분할, 자세 추정, 추적 및 분류를 지원합니다. → 튜토리얼:YOLOv11의 원클릭 배포
- YOLOv12 🚀 신규(2025): 속도와 정확성의 두 가지 정점에 어텐션 메커니즘의 성능적 이점이 결합되었습니다!
이 튜토리얼에서는 컴퓨팅 리소스로 RTX 4090을 사용합니다.
2. 작업 단계🛠️
1. 컨테이너 시작 후 API 주소를 클릭하여 웹 인터페이스로 진입합니다.

객체 감지기의 출력은 이미지 내 객체를 둘러싸는 경계 상자 집합과 각 경계 상자에 대한 클래스 레이블, 그리고 신뢰도 점수입니다. 객체 감지는 장면에서 관심 객체를 식별해야 하지만 정확한 위치나 모양을 알 필요는 없는 경우에 적합한 선택입니다.
이는 다음 두 가지 기능으로 나뉩니다.
- 이미지 감지
- 비디오 감지
2. 이미지 감지
입력은 이미지이고 출력은 레이블이 붙은 이미지입니다.
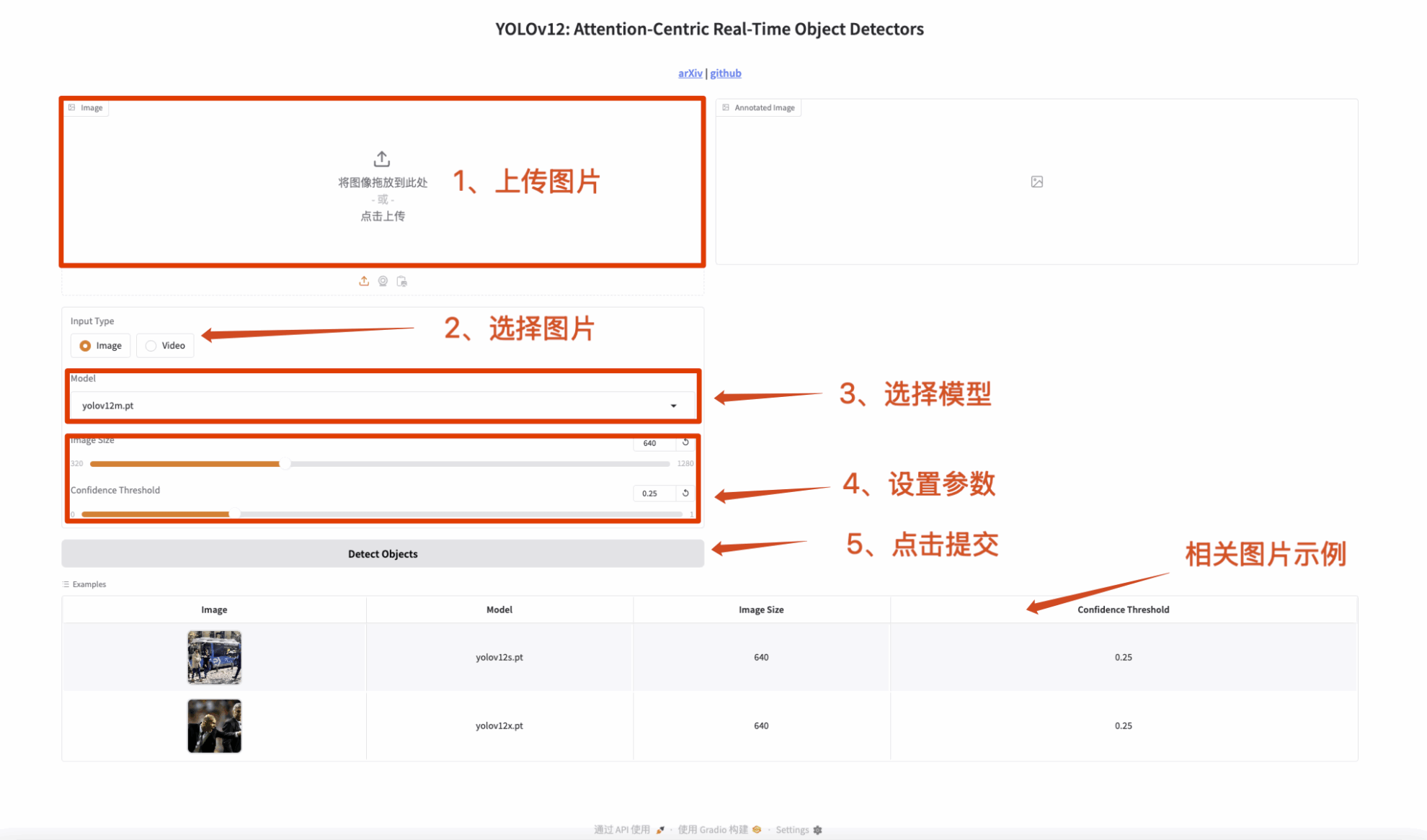

그림 1 이미지 감지
3. 비디오 감지
입력은 비디오이고 출력은 레이블이 있는 비디오입니다.
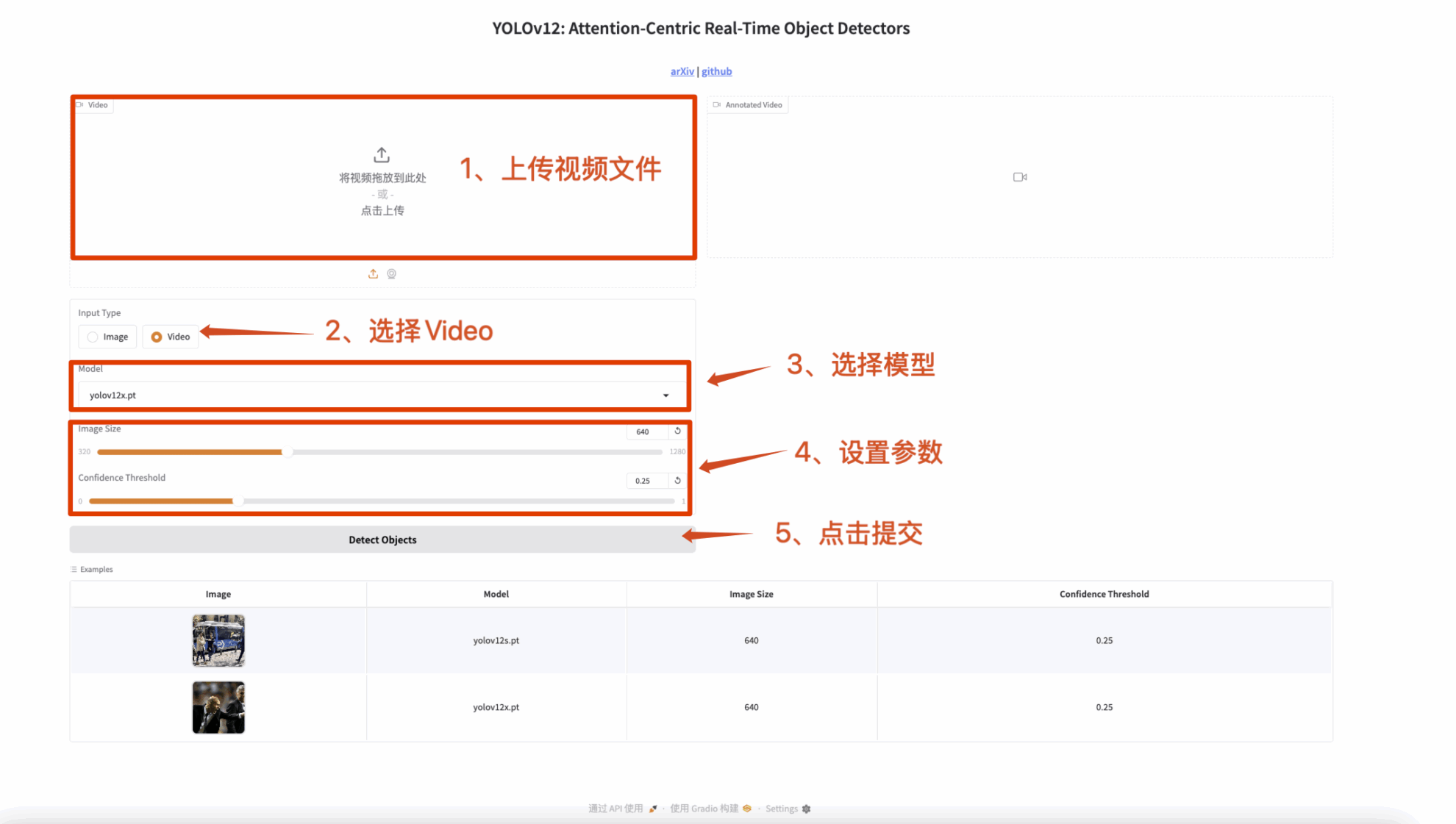
그림 2 비디오 감지
🤝 토론
🖌️ 고품질 프로젝트를 발견하시면, 백그라운드에 메시지를 남겨 추천해주세요! 또한, 튜토리얼 교환 그룹도 만들었습니다. 친구들의 QR코드 스캔과 [SD 튜토리얼] 댓글을 통해 그룹에 가입하여 다양한 기술 이슈에 대해 논의하고 신청 결과를 공유해 주시기 바랍니다.↓

YOLOv12는 기술적 도약일 뿐만 아니라 컴퓨터 비전 분야의 혁명이기도 합니다! 와서 체험해 보세요! 🚀