Command Palette
Search for a command to run...
AAAI 2025에 선정되었습니다! 의료 영상 분할에서 소프트 경계와 동시 발생 문제를 해결하기 위해 중국 지질대학과 다른 연구자들은 ConDSeg라는 영상 분할 모델을 제안했습니다.
의료 영상 분할은 의료 영상 처리 분야에서 중요하고 복잡한 단계입니다. 주로 의료 영상에서 특별한 의미를 가진 부분을 추출하여 임상 진단, 재활 치료, 질병 추적을 지원합니다. 최근 몇 년 동안 컴퓨터와 인공지능의 지원으로 딥러닝 기반 분할 방법이 점차 의료 영상 분할의 주류 방법으로 자리 잡았으며 관련 연구 결과도 눈부시게 발전했습니다.
최고 수준의 국제 인공지능 학회인 제39회 AAAI 인공지능 연례 학회(AAAI 2025)에서 발표된 선정된 결과 중 일부 논문은 자동화된 의료 영상 분할 분야에서 다시 한번 성과 있는 진전을 보여주었습니다.중국 지질과학대학과 바이두의 팀이 공동으로 발표한 연구 결과 중 하나인 "ConDSeg: 대조 기반 특징 향상을 통한 일반 의료 영상 분할 프레임워크"는 폭넓은 주목을 받았습니다.
연구진은 의료 영상 분할 분야에서 '소프트 경계'와 동시 발생 현상이라는 두 가지 주요 과제를 해결하기 위해 대비 기반 의료 영상 분할을 위한 ConDSeg라는 일반 프레임워크를 제안했습니다. 이 프레임워크는 일관성 강화(CR) 학습 전략, 의미 정보 분리(Semantic Information Decoupling, SID) 모듈, 대비 기반 기능 집계(Contrast-Driven Feature Aggregation, CDFA) 모듈, 크기 인식 디코더(Size-Aware Decoder, SA-Decoder) 등을 혁신적으로 도입하여 의료 이미지 분할 모델의 정확도를 더욱 향상시킵니다.
서류 주소:
https://arxiv.org/abs/2412.08345
오픈소스 프로젝트인 "awesome-ai4s"는 200개 이상의 AI4S 논문 해석을 모아 방대한 데이터 세트와 도구를 제공합니다.
https://github.com/hyperai/awesome-ai4s
의료 영상 분할 정확도는 두 가지 주요 과제에 직면합니다.
지난 10년 동안 인공지능의 발전으로 의료 이미지의 자동 분할이 빠르게 발전하여 의사와 연구자들이 지루한 작업에서 해방되었습니다. 그러나 의료 이미지의 복잡성과 전문성을 감안할 때, 완전 자동화된 이미지 분할을 달성하려면 아직 갈 길이 멀고, 정확성은 무시할 수 없는 중요한 과제입니다. 정확성이 떨어지면 자동화는 불가능하기 때문입니다.
현재 관점에서 보면,의료 영상의 "소프트 경계"와 동시 발생 현상은 의료 영상 분할 정확도 향상을 방해하는 주요 문제입니다.
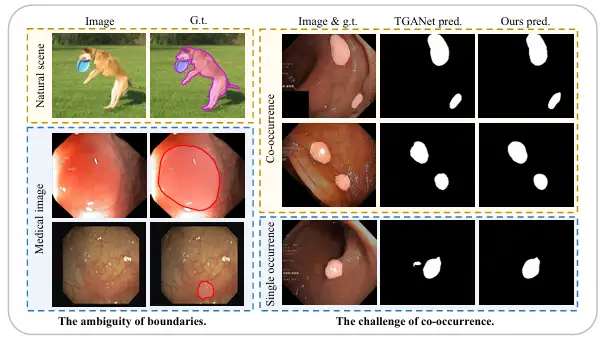
첫째, 전경과 배경 사이에 경계가 뚜렷한 자연 이미지와 비교했을 때, 의료 이미지는 전경(폴립, 샘, 병변 등)과 배경 사이에 흐릿한 "부드러운 경계"가 있는 경우가 많습니다. 그 이유는 병적인 조직과 주변의 정상 조직 사이에 전이 영역이 존재하기 때문에 경계를 정의하기 어렵기 때문입니다. 또한 대부분의 경우 의료 영상에서 나타나는 조명 효과가 좋지 않고 대비가 낮아 병적인 조직과 정상 조직의 경계가 더욱 모호해져 경계를 구분하기가 더욱 어렵습니다.
둘째, 자연 장면에서 무작위로 나타나는 사물과 달리, 의료 이미지 속의 장기와 조직은 고도로 고정적이고 규칙적이기 때문에, 동시에 나타나는 현상도 널리 퍼져 있습니다. 즉, 서로 다른 이미지 특징, 조직 또는 병변이 의료 이미지에 동시에 나타나는 것입니다. 예를 들어, 내시경 용종 이미지에서는 작은 용종이 비슷한 크기의 용종과 함께 나타나는 경우가 많으며, 이를 통해 모델이 용종과 관련이 없는 특정 동시 발생 특징을 매우 쉽게 학습할 수 있습니다. 그러나 병리 조직이 단독으로 나타나는 경우 모델은 종종 정확한 예측을 내릴 수 없습니다.
위의 과제를 해결하기 위해 최근 몇 년 동안 점점 더 많은 연구 방법이 이 분야에 집중되었습니다. 예를 들어, 선전대학교 의학부 생체공학과의 웨 광휘 부교수 팀은 정확한 폴립 분할에 사용할 수 있는 경계 제약 네트워크 BCNet을 출시했습니다. 여기에는 얕은 맥락적 특징, 고수준 위치 특징, 추가적인 폴립 경계 감독을 결합하여 경계를 포착할 수 있는 양측 경계 추출 모듈이 언급되어 있습니다. 이 결과는 "폴립 분할을 위한 교차 계층 기능 통합을 갖춘 경계 제약 네트워크"라는 제목으로 IEEE 생물의학 및 건강 정보학 저널에 게재되었습니다.
서류 주소:
https://ieeexplore.ieee.org/document/9772424
예를 들어, 상하이 기술 대학 생체공학과의 창립 학장인 션딩강 교수의 팀과 다른 연구자들은 폴립 분할에 사용할 수 있는 교차 수준 기능 집계 네트워크인 CFA-Net을 제안했습니다. 경계 인식 기능을 생성하기 위해 경계 예측 네트워크를 설계하고 계층적 전략을 사용하여 이러한 기능을 분할 네트워크에 병합합니다. 이 결과는 "폴립 분할을 위한 교차 수준 특징 집계 네트워크"라는 제목으로 패턴 인식에 게재되었습니다.
서류 주소:
https://www.sciencedirect.com/science/article/abs/pii/S0031320323002558
그러나 이러한 방법들은 모두 경계 관련 감독을 명시적으로 도입하여 모델의 경계에 대한 주의를 개선했지만, 모호한 영역에서 불확실성을 자연스럽게 줄이는 모델의 능력을 근본적으로 향상시키지는 못했습니다. 따라서 가혹한 환경에서는 이러한 방법의 강건성은 여전히 약하고 모델의 성능을 개선하는 데에는 여전히 한계가 있습니다. 동시에 전경과 배경을 정확하게 구분하지 못하고, 이미지 속의 서로 다른 개체를 구분하지 못하는 문제는 대부분 모델이 겪는 문제로 남아 있습니다.
기존 방식과는 다르게,중국 지질대학과 바이두의 연구팀이 수행한 연구에서 연구진은 대비 기반 의료 이미지 분할을 위한 ConDSeg라는 일반 프레임워크를 제안했습니다.구체적인 혁신 내용은 다음과 같습니다.
* 혹독한 환경에서의 견고성 테스트에 대응하여 연구자들은 인코더의 견고성을 향상시키고 고품질 기능을 추출하기 위해 일관성 강화(CR) 사전 학습 전략을 제안했습니다. 동시에, 의미 정보 분리(SID) 모듈은 피쳐 맵을 전경, 배경 및 불확실한 영역으로 분리하고, 특별히 설계된 손실 함수를 통해 학습 중에 불확실성을 줄이는 방법을 학습합니다.
* 제안된 대조 기반 특징 집계(CDFA) 모듈은 SID가 추출한 대조 특징을 통해 다층 특징의 융합과 향상을 안내합니다. 크기 인식 디코더(SA-Decoder)는 이미지에서 서로 다른 개체를 더 잘 구분하고 공통적인 특징의 간섭을 극복하기 위해 서로 다른 크기의 개체에 대해 별도의 예측을 내리는 것을 목표로 합니다.
ConDSeg의 4대 혁신 기술은 의료 영상 분할 정확도를 향상시킵니다.
전반적인,본 연구에서 제안하는 ConDSeg는 2단계 아키텍처를 갖춘 일반적인 의료 영상 분할 프레임워크입니다.다음 그림과 같이:
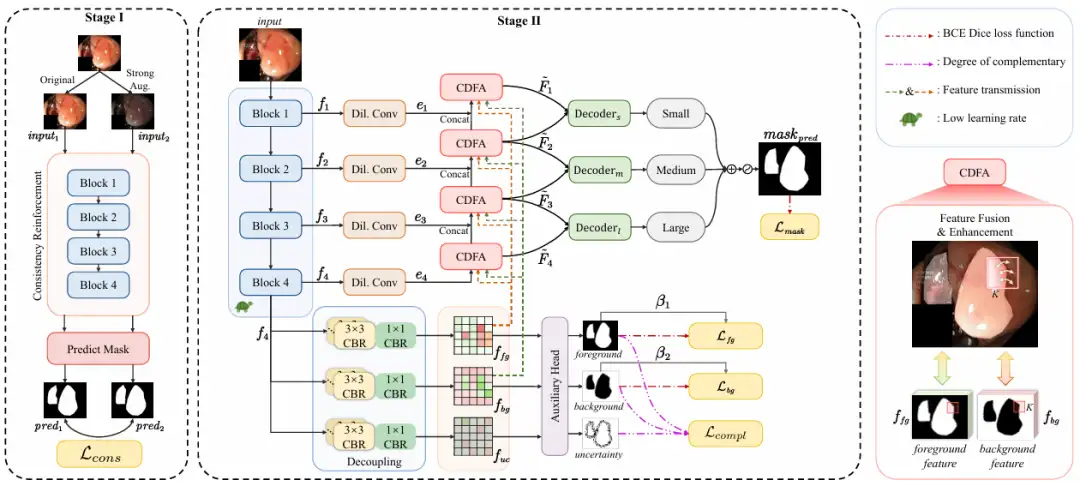
첫 번째 단계에서는,이 연구의 목표는 낮은 조도와 낮은 대비 장면에서 인코더의 특징 추출 기능과 견고성을 극대화하는 것입니다.
연구진은 인코더에 대한 사전 학습을 수행하기 위해 CR 사전 학습 전략을 도입하고, 인코더를 전체 네트워크에서 분리한 후 간단한 예측 헤드(Predict Mask)를 설계했습니다. 원본 이미지(Original)와 향상된 이미지(Strong Aug.)를 인코더에 입력하면 예측된 마스크 간의 일관성이 극대화되고, 다양한 조명 및 대비 조건에서 인코더의 견고성이 향상되며, 혹독한 환경에서도 고품질 기능을 추출하는 능력이 개선됩니다. 향상 방법에는 밝기, 대비, 채도, 색조를 무작위로 변경하는 것과 무작위로 회색조 이미지로 변환하는 것, 가우시안 블러를 추가하는 것이 포함됩니다.
연구팀이 제안한 일관성 손실 Lcons는 픽셀 수준의 분류 정확도를 기반으로 설계되었다는 점도 언급할 가치가 있습니다. 간단한 이진화 연산과 이진 교차 엔트로피(BCE) 손실 계산을 사용하여 예측된 마스크 간의 픽셀 수준 차이를 직접 비교합니다. 이 방법은 계산적으로 더 간단하고 수치적 불안정성을 피할 수 있어 대규모 데이터에 더 적합합니다.
두 번째 단계에서는,네트워크 전체가 미세하게 조정되고, 인코더의 학습률은 낮은 수준으로 설정됩니다. 4단계로 나뉩니다.
* 특징 추출, ResNet-50 인코더는 다양한 레벨의 다양한 의미 정보를 포함하는 특징 맵 f₁에서 f₄까지 추출합니다.
* 의미 정보 분리: 심층적 의미 정보를 담고 있는 피처 맵 f₄가 SID에 입력되고 전경, 배경 및 불확실한 영역 정보를 담고 있는 피처 맵으로 분리됩니다. SID는 세 개의 병렬 분기로 시작하며, 각 분기는 여러 개의 CBR 모듈로 구성됩니다. 특징 맵 f₄가 세 개의 브랜치에 입력된 후, 전경, 배경 및 불확실한 영역 특징이 각각 추가된 서로 다른 의미 정보를 갖는 세 개의 특징 맵이 얻어집니다. 그런 다음 보조 헤드가 3개의 특징 맵을 예측하고 전경, 배경 및 불확실한 영역에 대한 마스크를 생성합니다. 손실 함수의 제약을 통해 SID 학습은 불확실성을 줄이고 전경과 배경 사이의 마스크 정확도를 향상시킵니다. 다음 그림과 같이:
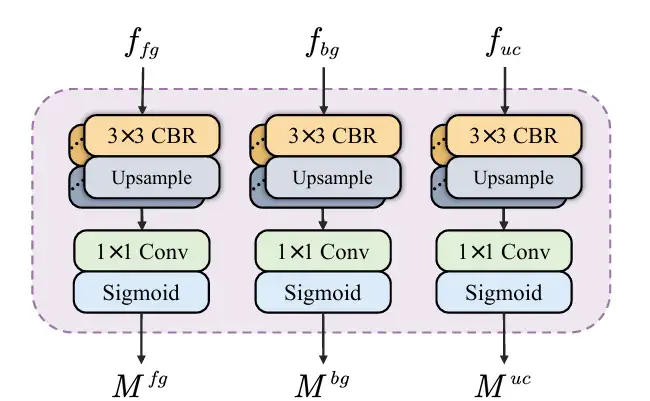
* 특징 집계: 특징 맵 f₁에서 f₄가 CDFA 모듈에 입력되고, 분리된 특징 맵을 기반으로 다중 레벨 특징 맵이 점진적으로 융합되어 전경 및 배경 특징의 표현이 향상됩니다. CDFA는 SID에 의해 분리된 전경과 배경의 대비 특징을 활용하여 다단계 특징 융합을 안내할 뿐만 아니라, 모델이 분할할 엔터티와 복잡한 배경 환경을 더 잘 구별할 수 있도록 도와줍니다. 다음 그림과 같이:
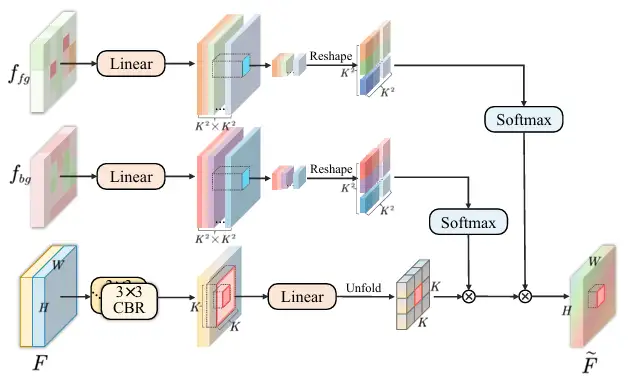
* 다중 스케일 예측을 위해 연구진은 작은 크기, 중간 크기, 큰 크기의 세 가지 디코더를 구축했습니다. 디코더 ₛ, 디코더 ₘ, 디코더 ₗ는 각각 특정 레벨의 CDFA 출력을 수신한 다음 크기에 따라 이미지에서 여러 엔터티를 찾습니다. 각 디코더의 출력은 융합되어 최종 마스크를 생성하므로, 모델은 큰 엔터티를 정확하게 분할하고 작은 엔터티를 정확하게 찾을 수 있으며, 동시 발생 현상이 잘못 학습되는 것을 방지하고 디코더의 규모 특이점 문제를 해결할 수 있습니다. 다음 그림과 같이:
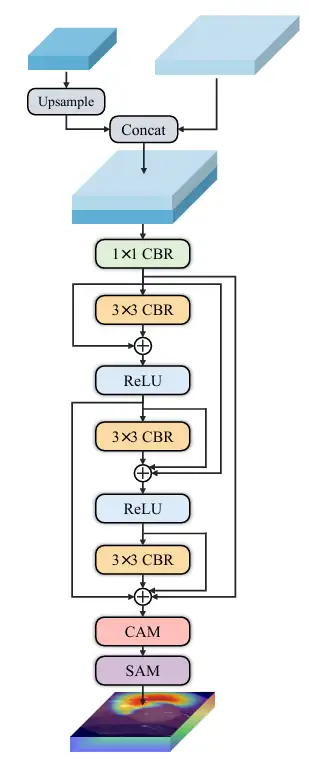
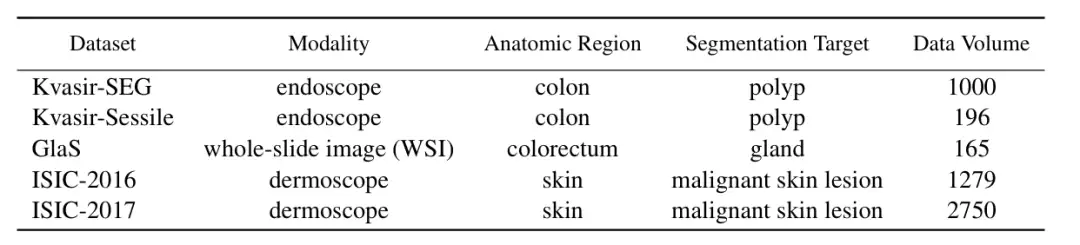
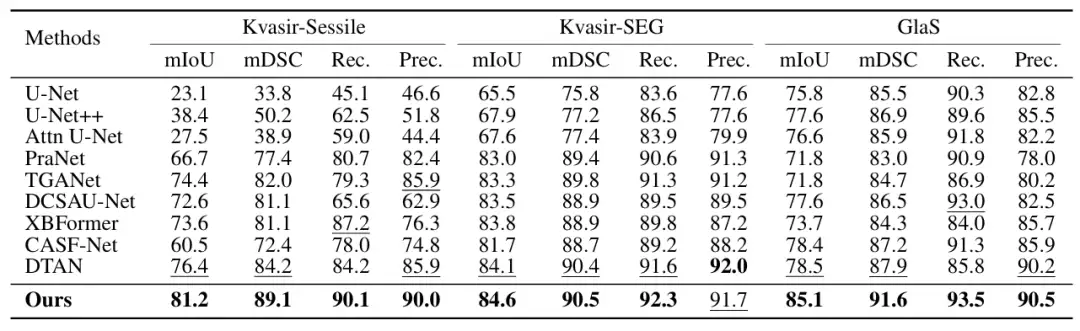
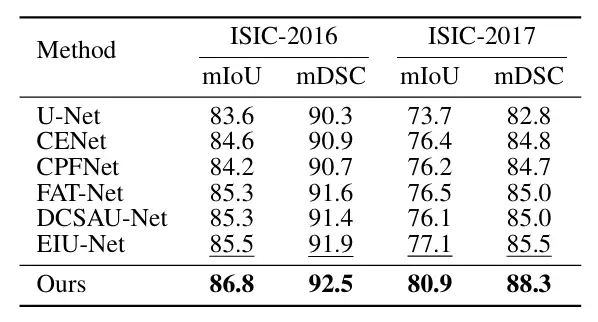
의료영상 분할 분야에서 ConDSeg의 성능을 검증하기 위해,연구진은 세 가지 의료 영상 작업(내시경, 전체 슬라이스 영상, 피부경 검사)을 테스트하기 위해 다섯 개의 공개 데이터 세트(아래 그림에 표시된 대로 Kvasir-SEG, Kvasir-Sessile, GlaS, ISIC-2016, ISIC-2017)를 선택했습니다. 연구원들은 이미지 크기를 256×256픽셀로 조정하고 배치 크기를 4로 설정했습니다. 최적화에는 Adam 옵티마이저를 사용했습니다.
주요 비교 대상에는 U-Net, U-Net++, Attn U-Net, CENet, CPFNet, PraNet, FATNet, TGANet, DCSAUNet, XBoundFormer, CASF-Net, EIU-Net, DTAN과 같은 가장 진보된 방법이 포함됩니다.결과는 제안된 방법이 5개의 모든 데이터 세트에서 가장 좋은 분할 성능을 달성함을 보여줍니다.다음 그림과 같이:
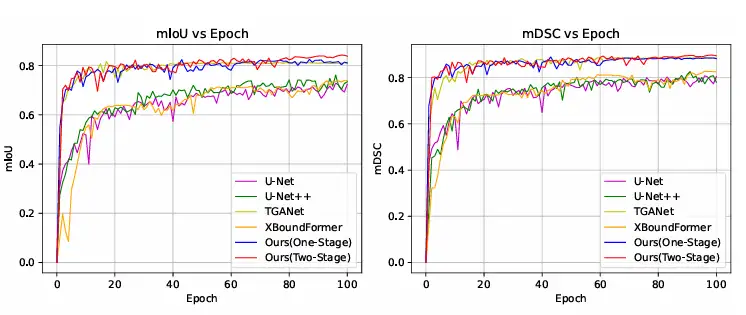
또한 연구진은 Kvasir-SEG 데이터 세트에서 다른 방법과 훈련 수렴 곡선을 비교했습니다. 실험 결과에 따르면 ConDSeg는 단 한 단계의 학습만으로도 고급 수준에 도달할 수 있으며, 전체 ConDSeg 프레임워크를 사용했을 때 이 방법이 가장 빠른 수렴 속도와 최상의 성능을 달성했습니다. 아래 그림과 같습니다.
의료영상 분할은 자본과 기술의 뜨거운 화두가 되고 있다.
의료 영상 분할은 임상 의학과 의학 연구 모두에서 중요한 역할을 합니다. 특별히 훈련된 AI 시스템은 높은 효율성과 지능성으로 기존 의료 영상 분할 방법을 혁신하여 의료진과 과학 연구자에게 없어서는 안 될 보조 도구가 되었습니다. 의료 영상 분할이 이처럼 발전하고 성과를 거둘 수 있었던 이유는 자본과 기술이라는 두 가지 동력 덕분입니다.
자본 측면에서는 최근 몇 년 동안 투자 커뮤니티에서 AI와 바이오의학의 학제간 분야가 화제가 되고 있으며, 올해는 AI 기반 의료 영상이 성공적인 시작을 이루는 데 앞장서고 있습니다. 1월 28일, 스페인 의료 영상 회사 Quibim은 5,000만 달러(약 3억 6,000만 위안) 규모의 시리즈 A 자금 조달을 완료했다고 발표했습니다. Quibim의 핵심 기술은 의료 영상 데이터를 기반으로 한 인공지능 분석이며, QP-Liver는 확산성 간 질환의 MR 진단을 위한 자동 분할 도구입니다.
기술 측면에서 AI와 의료 영상 분할의 결합은 오랫동안 주요 연구소의 연구 초점 중 하나였습니다. 예를 들어, 매사추세츠 공과대학 컴퓨터 과학 및 인공지능 연구소(MIT CSAIL)의 한 팀은 매사추세츠 종합병원과 하버드 의대의 연구자들과 협력하여 대화형 생물의학 이미지 분할을 위한 일반 모델인 ScribblePrompt를 제안했습니다. 이 모델은 그래피티, 클릭, 경계 상자와 같은 다양한 주석 방법을 사용하는 주석 작성자를 지원하여 훈련되지 않은 레이블과 이미지 유형에 대해서도 생물의학 이미지 분할 작업을 유연하게 수행할 수 있도록 합니다.
"ScribblePrompt: 모든 생물의학 이미지를 위한 빠르고 유연한 대화형 분할"이라는 제목의 관련 결과는 최고의 국제 학술 대회인 ECCV 2024에서 수락되었습니다.
서류 주소:
https://arxiv.org/pdf/2312.07381
또한 옥스퍼드 대학 연구팀은 Meta가 발표한 SAM 2를 기반으로 의료 이미지를 비디오로 처리하는 Medical SAM 2(MedSAM-2)라는 의료 이미지 분할 모델을 개발했습니다. 이 제품은 3D 의료 영상 분할 작업에서 우수한 성능을 발휘할 뿐만 아니라, 새로운 단일 프롬프트 분할 기능도 제공합니다. 사용자는 새로운 특정 객체에 대한 힌트만 제공하면 되고, 후속 이미지에서 유사한 객체의 분할은 추가 입력 없이 모델에 의해 자동으로 완료됩니다.
*자세한 보고서를 보려면 여기를 클릭하세요: SAM 2 최신 애플리케이션이 출시되었습니다! 옥스포드 대학 팀, Medical SAM 2 출시, 의료 영상 분할 SOTA 목록 갱신
간단히 말해서, AI는 더 이상 첨단 기술이 아닙니다. 의료 영상의 자동 분할 기술의 개발은 생물의학 분야에서 AI의 잠재력을 확인시켜 주었으며, 그 상업적 타당성 또한 잇따른 자본 스토리를 통해 검증되었습니다. 앞으로 의료영상 분야의 가장 중요한 고리인 의료영상 분할은 AI의 도움을 받아 급속도로 발전할 것으로 기대됩니다. 의료 영상 분할 분야의 성공으로 인해 자본이 보다 광범위한 생물의학 시장에도 유입되어 기술, 자본, 사업의 완벽한 폐쇄 루프가 실현될 것입니다.