Command Palette
Search for a command to run...
勾配の累積勾配の累積
日付
勾配累積は、ニューラル ネットワークのトレーニングに使用されるサンプルのバッチを、順番に実行されるいくつかの小さなバッチ サンプルに分割するメカニズムです。
勾配の累積についてさらに議論する前に、ニューラル ネットワークのバックプロパゲーション プロセスを確認することが最善です。
ニューラルネットワークの逆伝播
深層学習モデルは相互接続された多くの層で構成されており、サンプルは各ステップで順伝播によって伝播されます。すべての層を伝播した後、ネットワークはサンプルの予測を生成し、各サンプルの損失値を計算します。これは、「そのサンプルに対してネットワークがどの程度間違っていたか」を示します。次に、ニューラル ネットワークは、モデル パラメーターに対するこれらの損失値の勾配を計算します。これらの勾配は、個々の変数の更新を計算するために使用されます。
モデルを構築するとき、損失を最小限に抑えるために使用されるアルゴリズムを担当するオプティマイザーが選択されます。オプティマイザーは、フレームワーク (SGD、Adam など) にすでに実装されている一般的なオプティマイザーの 1 つであることも、必要なアルゴリズムを実装するカスタム オプティマイザーであることもできます。オプティマイザーは、勾配に加えて、学習率、現在のステップ インデックス (適応学習率用)、運動量など、更新を計算するためのより多くのパラメーターを管理および使用する場合があります。
技術的な勾配の蓄積
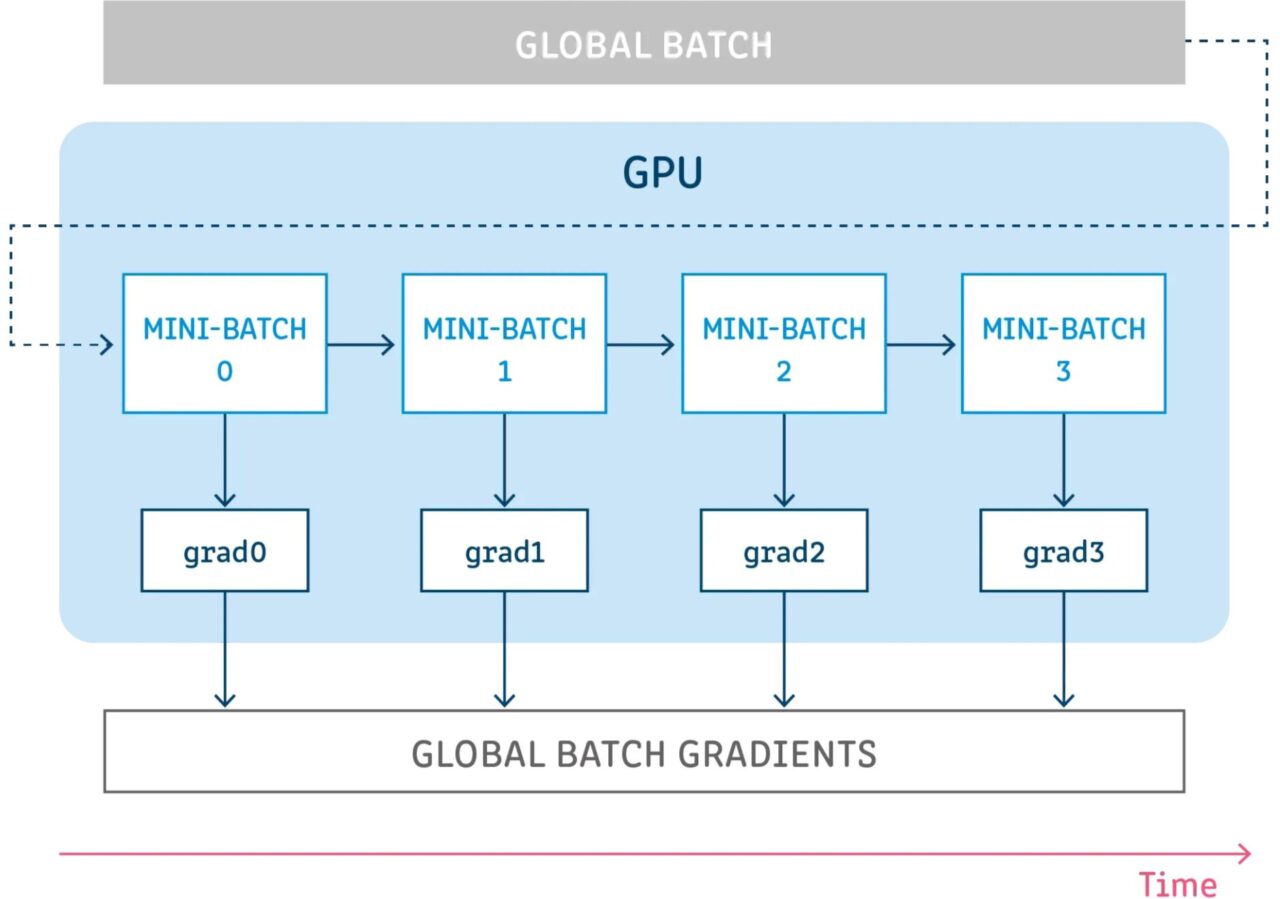
勾配の累積とは、モデル変数を更新せずに構成された数のステップを実行しながら、それらのステップの勾配を累積し、累積された勾配を使用して変数の更新を計算することを意味します。
モデル変数を更新せずにいくつかのステップを実行することは、サンプルのバッチをいくつかの小さなバッチに分割する論理的な方法です。各ステップで使用されるサンプルのバッチは実際にはミニバッチであり、これらすべてのステップのサンプルを組み合わせたものが実際にはグローバル バッチです。
これらすべてのステップで変数を更新しないことにより、すべてのミニバッチは同じモデル変数を使用して勾配を計算します。これは、グローバル バッチ サイズを使用しているかのように同じ勾配と更新が計算されるようにするための必須の動作です。
これらすべてのステップで勾配を累積すると、同じ勾配の合計が得られます。
参考文献
【1】https://towardsdatascience.com/what-is-gradient-accumulation-in-deep-learning-ec034122cfa