Command Palette
Search for a command to run...
回転位置エンコーディング RoPE (回転位置エンベディング)
日付
回転位置エンコーディング RoPE (Rotary Position Embedding) は論文です。Roformer: ロートレイ位置埋め込みを備えた強化されたトランスフォーマー」は、相対位置情報をセルフアテンションに統合し、トランスフォーマーアーキテクチャのパフォーマンスを向上させることができる位置エンコード方式です。これは、Llama、Baichuan、ChatGLM、Qwen などを含むがこれらに限定されない大規模モデルで広く使用されている位置エンコーディングです。コンピューティング リソースの制限により、最新の大規模モデルは推論中に短いコンテキスト長でトレーニングされ、事前トレーニングされた長さを超えると、モデルのパフォーマンスが大幅に低下します。その結果、大規模なモデルがトレーニング前の長さを超えてより良い結果を達成できるようにすることを目的として、RoPE に基づく長さの外挿に関する多くの研究が行われてきました。したがって、RoPE ベース モデルの長さの外挿については、RoPE の基礎となる原理を理解することが重要です。
RoPEの基本原則
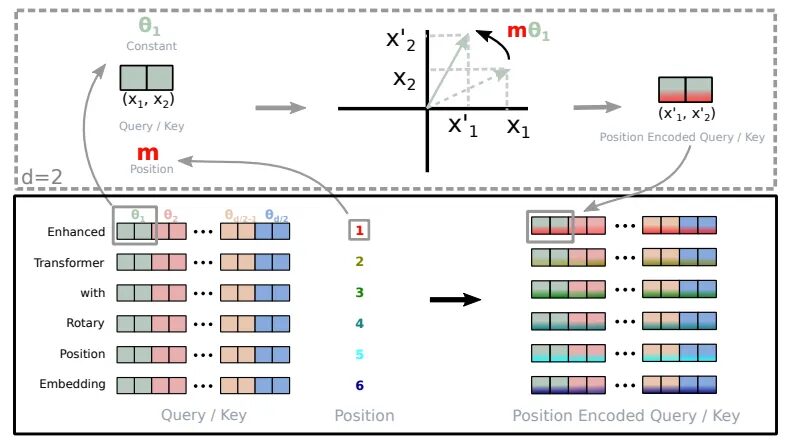
RoPE の基本原理は、各位置を、長さと方向が位置情報に関連する回転ベクトルとしてエンコードすることです。具体的には、長さ n のシーケンスの場合、RoPE は各位置 i を回転ベクトル pe_i としてエンコードします。回転ベクトル pe_i は次のように定義されます。
pe_i = (sin(iオメガ)、cos(iオメガ))
このうち、omega は回転ベクトルの周波数を制御するハイパーパラメータです。
RoPEのメリット
RoPE の特徴は、明示的な相対位置の依存関係をモデルのセルフ アテンション メカニズムにシームレスに統合できることです。この動的なアプローチには、次の 3 つの利点があります。
- シーケンス長の柔軟性: 従来の位置埋め込みでは通常、シーケンスの最大長を定義する必要があり、適応性が制限されます。一方、RoPE は非常に柔軟です。任意の長さのシーケンスに対して、その場で位置埋め込みを生成できます。
- トークン間の依存関係を減らす: RoPE は、トークン間の関係をモデル化する点で非常に賢明です。シーケンス内でトークンが互いに離れるにつれて、RoPE はそれらの間のトークンの依存関係を自然に減らします。この段階的な減衰は、人間が言語を理解する方法とより一致しています。
- 自己注意力の強化: RoPE は、従来の絶対位置エンコーディングには存在しない機能である相対位置エンコーディングを備えた線形セルフアテンション メカニズムを備えています。この機能強化により、トークン埋め込みをより正確に利用できるようになります。
回転エンコーディングの実装 (から引用) ロフォーマー)
従来の絶対位置エンコードは、コンテキストに関係なく、単語が位置 3、5、または 7 に出現するかどうかを指定することに似ています。対照的に、RoPE を使用すると、モデルは単語が互いにどのように関係しているかを理解できます。単語 A は単語 B の後、単語 C の前に頻繁に出現することが認識されます。この動的な理解により、モデルのパフォーマンスが向上します。
RoPEの導入
Rotary Position Encoding (RoPE) コードを分解して、その実装方法を理解します。
precompute_theta_pos_frequenciesRoPEの特別な値を計算する関数です。まず、というファイルを定義します。theta制御するハイパーパラメータ回転の振幅。値が小さいほど、回転が小さくなります。次に、次の値を計算します。グループ回転角度theta。この関数は、シーケンス内の位置のリストも作成し、位置のリストと回転角度の外積を取得して計算します。各位置をどのくらい回転させる必要があるか。最後に、これらの値を固定サイズの極形式の複素数に変換します。これは、位置と回転を表す暗号のようなものです。apply_rotary_embeddingsこの関数は数値を受け取り、回転情報で数値を強化します。まず入力値を受け取ります最後の次元は次のように分割されます。実数部と虚数部のペアを表します。これらのペアは、単一の複素数に結合されます。次に機能ですが、事前に計算された複素数と入力を乗算します。、これにより効果的に回転が適用されます。最後に、結果を実数に変換してデータを再整形し、さらに処理できるようにします。
参考文献
【1】https://www.bolzjb.com/archives/PiBBdbZ7.html