Command Palette
Search for a command to run...
DiffVox: サウンド差別化モデル
1. チュートリアルの概要

DiffVoxプロジェクトは、ソニーAI、ソニー株式会社、ロンドン大学クイーン・メアリー校の研究チームによって2025年5月に共同で開始されました。このモデルの核となる機能は、高度な推論時間最適化手法と、革新的なガウス事前制約の導入にあります。これにより、人間の生の音声録音を、ターゲットリファレンスに聴感上近似し、パラメータに関してはプロフェッショナルミキシング基準に準拠した高品質なオーディオへとインテリジェントに変換することができます。これは、人間の声のスタイル変換に焦点を当てた高度なモデルであり、関連する研究論文には以下が含まれます… DiffVox: 音声効果分布の捕捉と分析のための微分可能モデル(DAFx25で受信)および ガウス分布を用いたボーカルエフェクトスタイル転送の推論時間最適化の改善(WASPAA 2025 に採択)。
このチュートリアルでは、デフォルトのリソースとして単一の RTX 5090 グラフィック カードを使用しますが、プログラムの起動には、最小で単一の RTX 4090 グラフィック カードも使用できます。
2. プロジェクト例
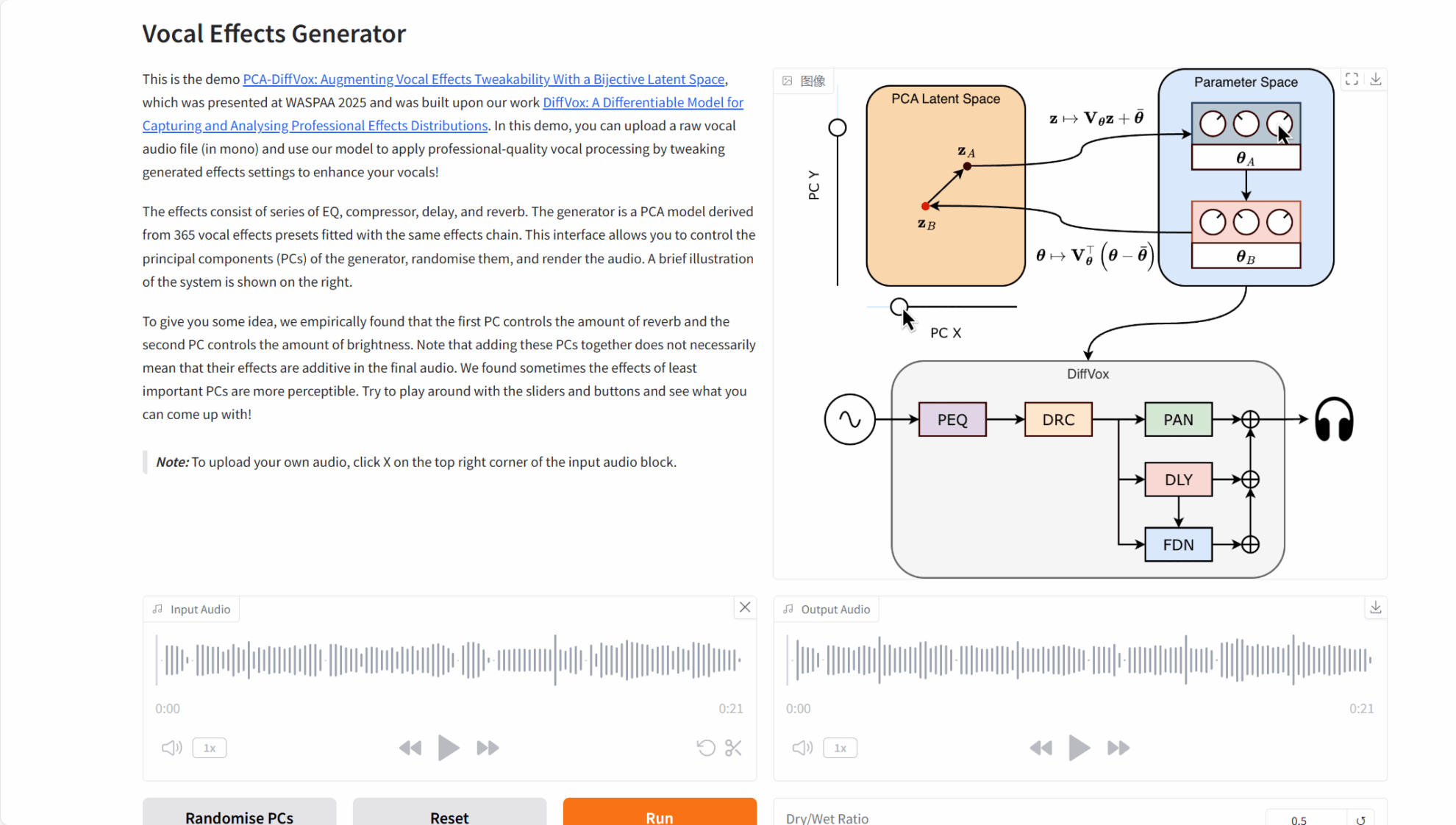
3. 操作手順
1. コンテナを起動します
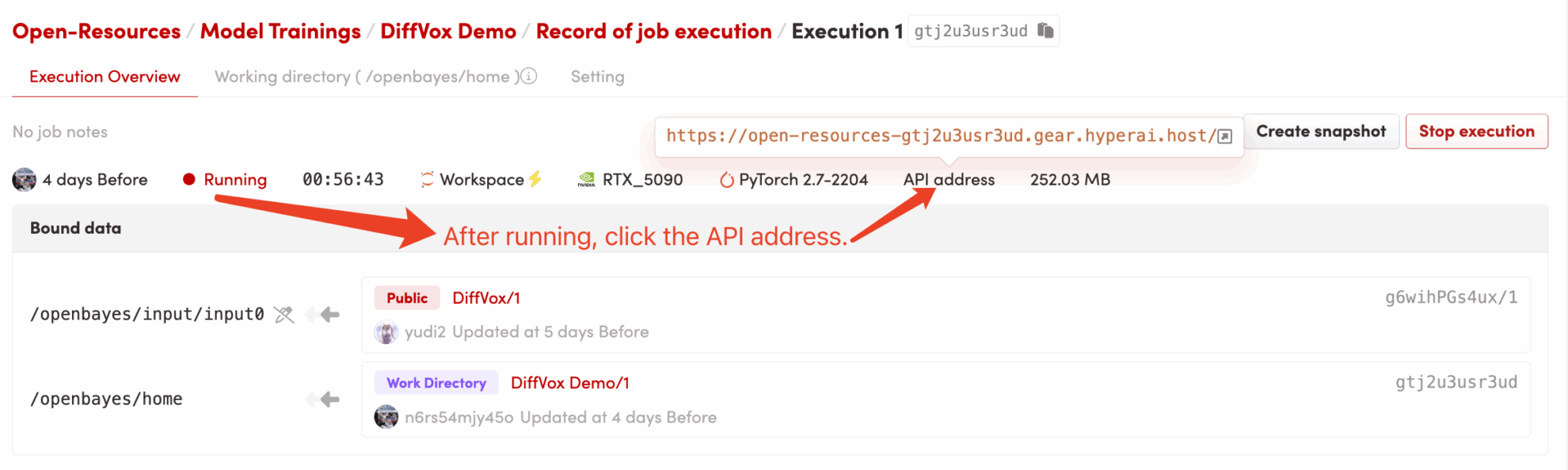
2. ウェブページに入ったら、モデルを使用することができます
「Bad Gateway」と表示される場合は、モデルが初期化中です。2~3分ほどお待ちいただき、ページを更新してください。Safariをご利用の場合、音声が直接再生されない場合がありますので、事前にダウンロードしてください。
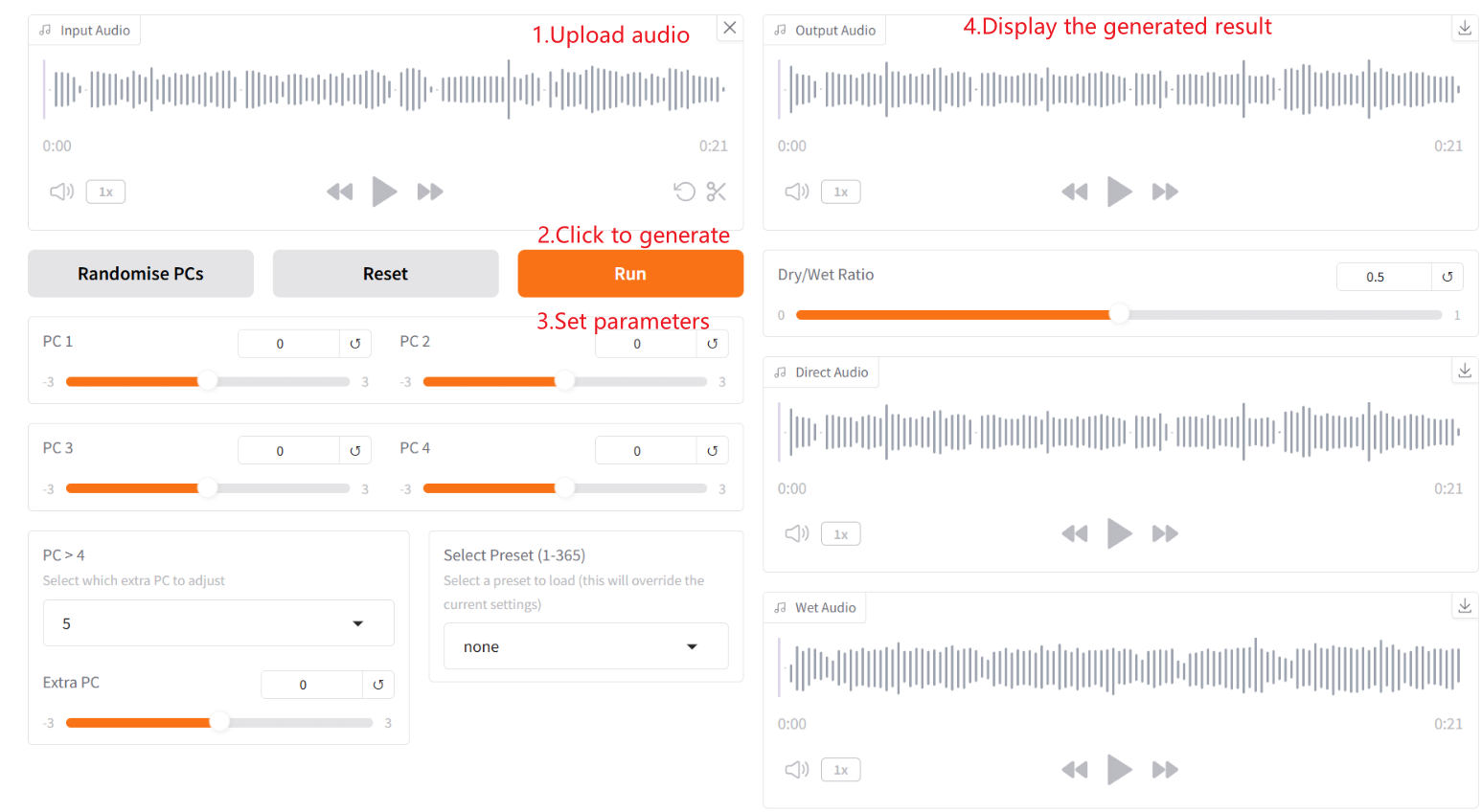
関連パラメータの説明
メインコントローラーとプリセット
ラピッドオーディオ
- 効果メイン コントロール パネルには、コア オーディオ処理機能とプリセット選択が含まれています。
- 説明するこれはエフェクト処理チェーン全体のエントリ ポイントであり、すべてのエフェクト モジュールの作業を調整する役割を担います。
乾燥/湿潤比
- 効果ドライサウンド(原音)とウェットサウンド(加工音)の混合比をコントロール
- 説明する:
- 0%: 完全にドライなオーディオ。元の音だけを出力します。
- 50%: ドライサウンドとウェットサウンドのバランスミキシング
- 100%: 完全にウェットなサウンドで、処理されたサウンドのみを出力します。
- 応用エフェクト処理の強度を制御し、過剰な処理を回避するために使用されます。
出力オーディオ
- 効果最終ミックス出力オーディオ
- 説明するすべてのエフェクト処理とウェット/ドライ ミキシング後の完全な結果。
ドライオーディオ
- 効果エフェクトなしの未加工の未処理オーディオ。
- 説明する録音のオリジナルの特性が保存されるため、比較や後処理に適しています。
ウェットオーディオ
- 効果すべてのエフェクト処理後のウェットサウンド
- 説明するイコライゼーション、コンプレッション、ディレイ、リバーブなどのすべてのエフェクトを含むサウンド。
プリセットを選択(1〜365)
- 効果プリセットエフェクトライブラリの選択
- 説明する:
- 365種類のプロが調整したエフェクトプリセットが含まれています
- 幅広い音楽スタイルとサウンド特性をカバー
- パーソナライズされた調整の出発点として役立ちます。
パラメトリックイコライザー
パラメトリックEQ
- 効果正確なトーン調整ツール
- 説明する複数のフィルターを使用して特定の周波数帯域を増強または減衰させることにより、音のスペクトル特性を形成することができます。
ハイパスフィルタ
- 効果指定された周波数以下の低周波成分を削除します。
- 応用:
- 呼吸音や風の音などの低周波ノイズを除去します。
- 曇りを減らして透明度を高める
- 標準設定: 80~120 Hz
ローシェルフ(低域シェルフ型イコライザー)
- 効果: 全ての低周波数帯域の全体的なブーストまたは減衰
- 応用:
- 音の厚みと暖かさを増します。
- 低周波のこもり音を低減
- 標準周波数: 100~250 Hz
ピークフィルター
- 効果特定の周波数ポイントの正確な調整
- 応用:
- 共鳴ピークの除去
- ボーカルの存在感を高める
- 特定の周波数帯域における音色の問題を修正
ハイシェルフ(高域シェルフ型イコライザー)
- 効果すべての高周波数の全体的なブーストまたは減衰
- 応用:
- 開放感と明るさを増す
- 耳障りな高周波を減らす
- 標準周波数: 8~12 kHz
頻度
- 効果処理する中心周波数を選択します。
- 説明する: フィルタが動作する周波数ポイントを決定します
得
- 効果: 周波数の増幅または減衰の度合いを制御する
- 範囲-12 dB ~ +12 dB
- 今すぐ: この周波数を高める
- 負の値この周波数を減衰させる
Q
- 効果: 影響を受ける周波数範囲の幅を制御する
- 説明する:
- 高いQ値影響範囲は狭く、対象は限定的
- 低いQ値広範囲に影響、スムーズな効果
- 応用狭い Q は精密な補正に使用され、広い Q は全体的な調整に使用されます。
コンプレッサーとエキスパンダー
コンプレッサーとエクスパンダー
- 効果ダイナミックレンジプロセッサ
- 関数コンプレッサーはダイナミック レンジを縮小し、エクステンダーはダイナミック レンジを拡大します。
しきい値
- 効果圧縮/拡張が開始されるしきい値レベルを設定します。
- 説明する:
- このレベルを超える信号は圧縮されます。
- このレベル以下の信号は増幅されます。
- 範囲-60 dB~0 dB
圧縮比(コンプレッションレシオ)
- 効果圧縮の強度を制御する
- 説明する:
- 2:1軽度の圧迫
- 4:1中程度の圧縮
- 10:1強力な圧縮
- ∞:1リミッター効果
補填(補償を得る)
- 効果圧縮後のレベル損失の補償
- 応用: 圧縮後の音量を圧縮前の音量と同等にします。
攻撃時間
- 効果: コンプレッサーが作動を開始する速度を制御します
- 説明する:
- クイックスタート影響度を高めるために、過渡状態を維持します。
- スロースタートトランジェントを和らげ、よりスムーズなサウンドを実現します。
- 範囲0.1~100ミリ秒
リリース時間
- 効果: コンプレッサーの動作を停止する速度を制御する
- 説明する:
- すぐにリリース急速な回復により吸引効果が得られる可能性があります。
- ゆっくりと放出ダイナミックリカバリが遅くなり、より自然な効果が得られます。
- 範囲50~1000ミリ秒
エクスペクティブ比率
- 効果: 拡張の強度を制御する
- 説明する:
- 1:2信号レベルはしきい値を下回ると半分になります。
- 1:10強力な拡張機能により、ノイズを効果的に低減します。
- 範囲: 0-1(実際には膨張率の逆数)
Exp.しきい値
- 効果: エクステンダーが動作を開始する電圧レベルを設定します
- 説明するこのしきい値を下回る信号はさらに減衰されます。
RMS平均係数
- 効果: 信号応答に対するコンプレッサーの感度を制御する
- 説明する:
- 高価値平均音量に敏感、スムーズな応答
- 低い価値瞬間的なピーク値に敏感で、応答時間が速いです。
- 応用音楽のスタイルやニーズに応じて応答特性を調整します
卓球の遅延
ピンポンディレイ
- 効果ステレオディレイエフェクト
- 特徴エコーは左チャンネルと右チャンネルの間で交互に発生します。
遅延時間
- 効果: エコーの時間間隔を制御する
- 範囲100~1000ミリ秒
- 応用:
- 短い遅延:空間と奥行きの感覚が増す
- ロングディレイ:目立つエコー効果を生み出す
フィードバック
- 効果エコーの繰り返し回数を制御する
- 説明する:
- フィードバックが低い少量のエコー
- 高いフィードバック繰り返し行うことで自己興奮を引き起こす可能性があります。
- 範囲: 0-1
得
- 効果: ディレイ効果の音量をコントロールします
- 範囲-80 dB~0 dB
奇数/偶数ディレイパン
- 効果: 奇数エコーと偶数エコーの音像位置をそれぞれ制御します
- 説明する:
- -100: ちょうど左チャンネル
- 0中央揃え
- 100右チャンネル全体
- 応用3次元の空間移動効果を作成する
ローパス周波数
- 効果遅延エコーの低周波フィルタリング
- 応用:
- 自然減衰をシミュレートする高周波損失
- 暖かく、耳障りではないエコーを作成します。
リバーブセンド
- 効果: 残響に送られる遅延信号の量
- 応用遅延エコーに空間感覚を加えることで、より自然な効果が生まれます。
FDNリバーブ
FDNリバーブ
- 効果高品質のデジタルリバーブエフェクト
- 特徴フィードバック遅延ネットワークに基づいて、自然な空間シミュレーションを提供します。
トーン補正(PEQ)
- 効果リバーブエフェクト内のイコライザー。
- 関数:
- 残響音の周波数応答を調整する
- リバーブの明るさや暖かさを制御します。
- メインサウンドとのリバーブの衝突を避ける
減衰時間
- 効果残響の減衰時間を制御する
- 説明する:
- 短い減衰小部屋効果
- 長い減衰ホール効果または教会効果
- 範囲0~9秒
- 応用空間のサイズと要件に応じて残響時間を調整します。
引用情報
このプロジェクトの引用情報は次のとおりです。
@inproceedings{ycy2025diffvox,
title={DiffVox: A Differentiable Model for Capturing and Analysing Vocal Effects Distributions},
author={Chin-Yun Yu and Marco A. Martínez-Ramírez and Junghyun Koo and Ben Hayes and Wei-Hsiang Liao and György Fazekas and Yuki Mitsufuji},
year={2025},
booktitle={Proc. DAFx},
}
@inproceedings{ycy2025ito,
title={Improving Inference-Time Optimisation for Vocal Effects Style Transfer with a Gaussian Prior},
author={Chin-Yun Yu and Marco A. Martínez-Ramírez and Junghyun Koo and Wei-Hsiang Liao and Yuki Mitsufuji and György Fazekas},
year={2025},
booktitle={Proc. WASPAA},
}