HyperAI
Command Palette
Search for a command to run...
Yolov13のワンクリック展開
1. チュートリアルの概要

YOLOv13は、清華大学、太原理工大学、西安交通大学などの共同研究チームによって2025年6月に提案された物体検出モデルです。YOLOシリーズのリアルタイム検出の利点を基盤に、ハイパーグラフ拡張、高次セマンティックモデリング、軽量構造再構築といった一連の新メカニズムを導入しています。MS COCOやPascal VOCなどの主流データセットにおいて包括的なリーダーシップを獲得し、より強力な汎化能力と実用的な展開を実証しています。関連論文も公開されています。 YOLOv13: ハイパーグラフ強化適応視覚認識によるリアルタイム物体検出 。
このチュートリアルでは、リソースとして単一の RTX 5090 カードを使用します。
2. プロジェクト例
画像
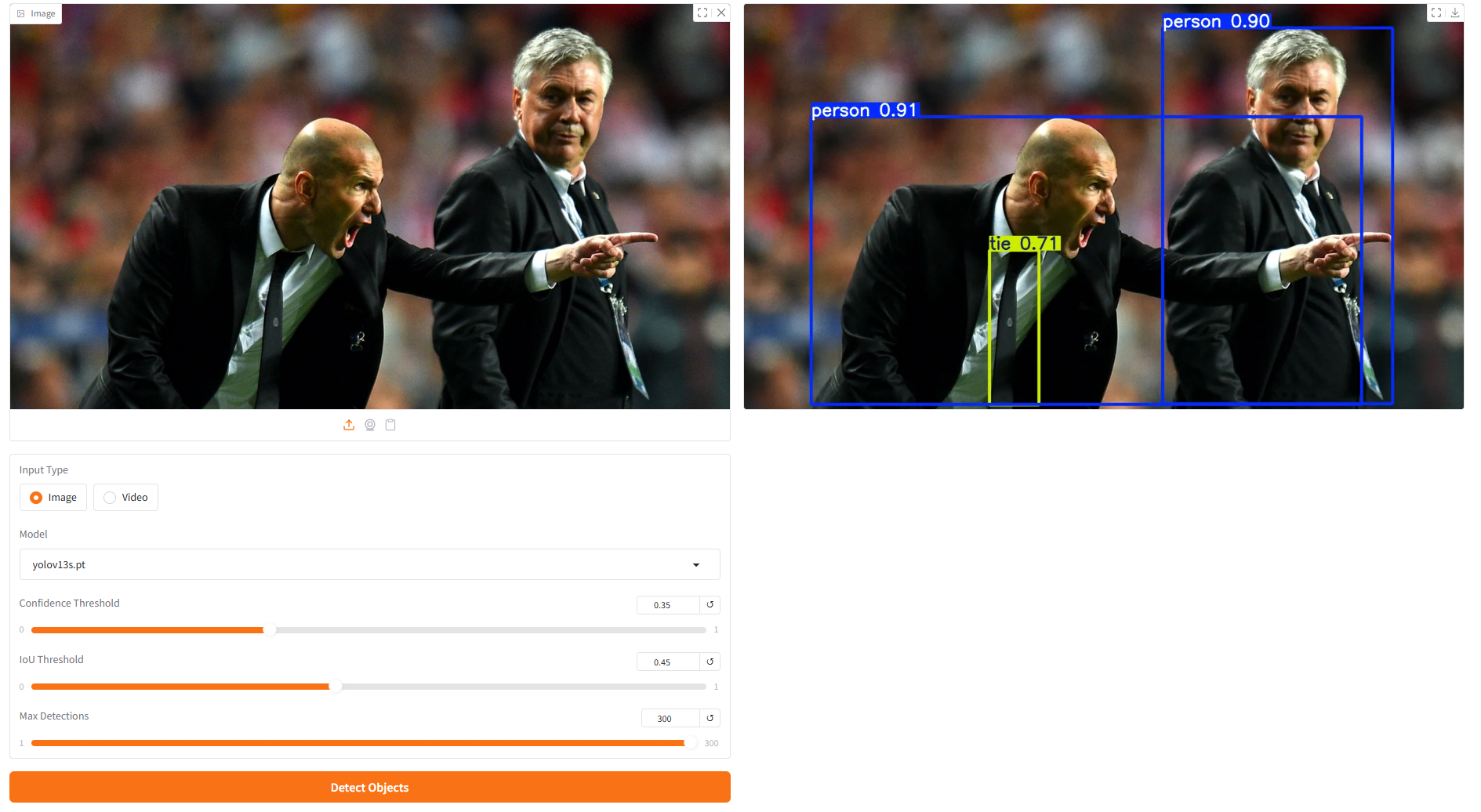
ビデオ

3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
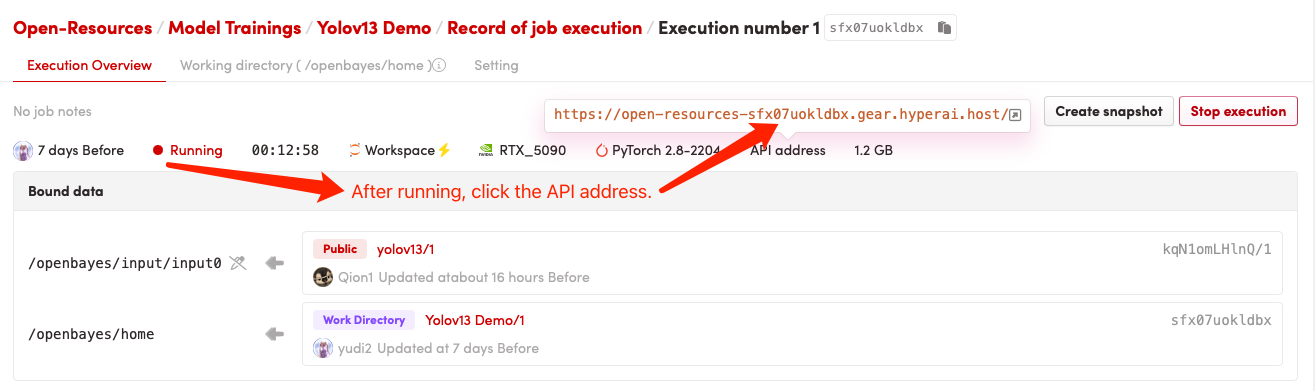
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
画像
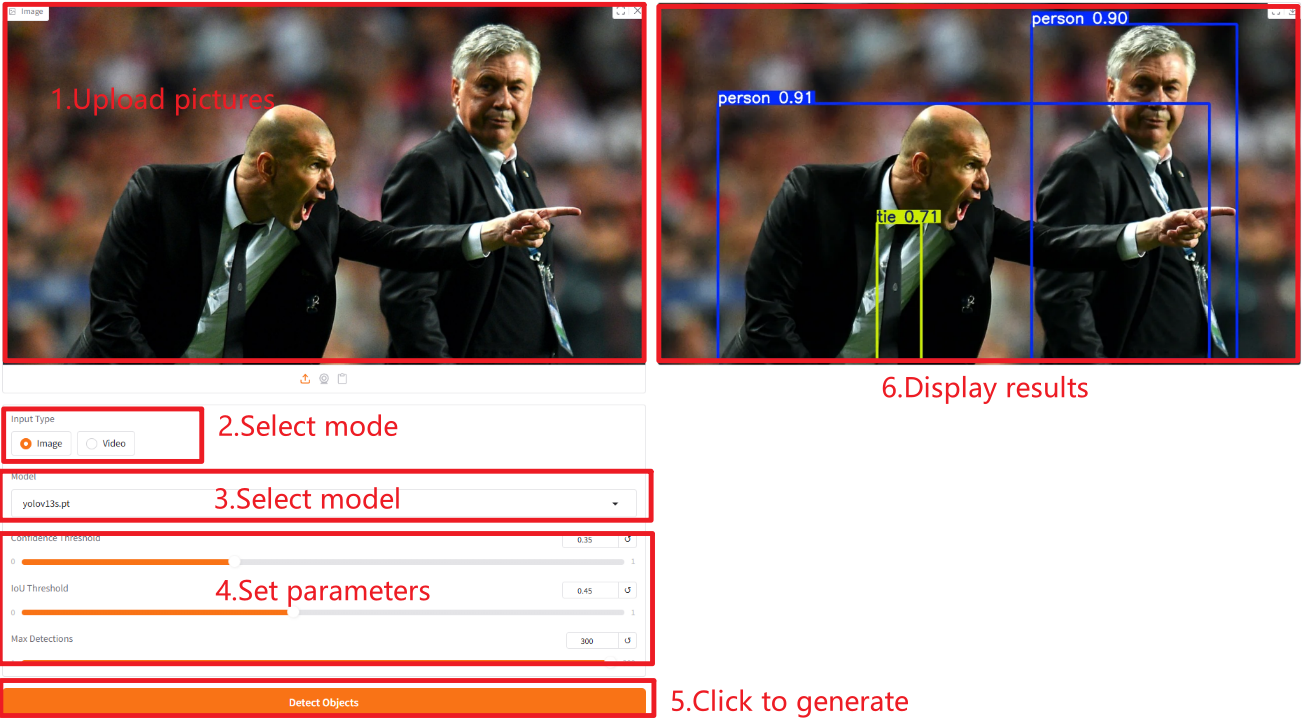
ビデオ
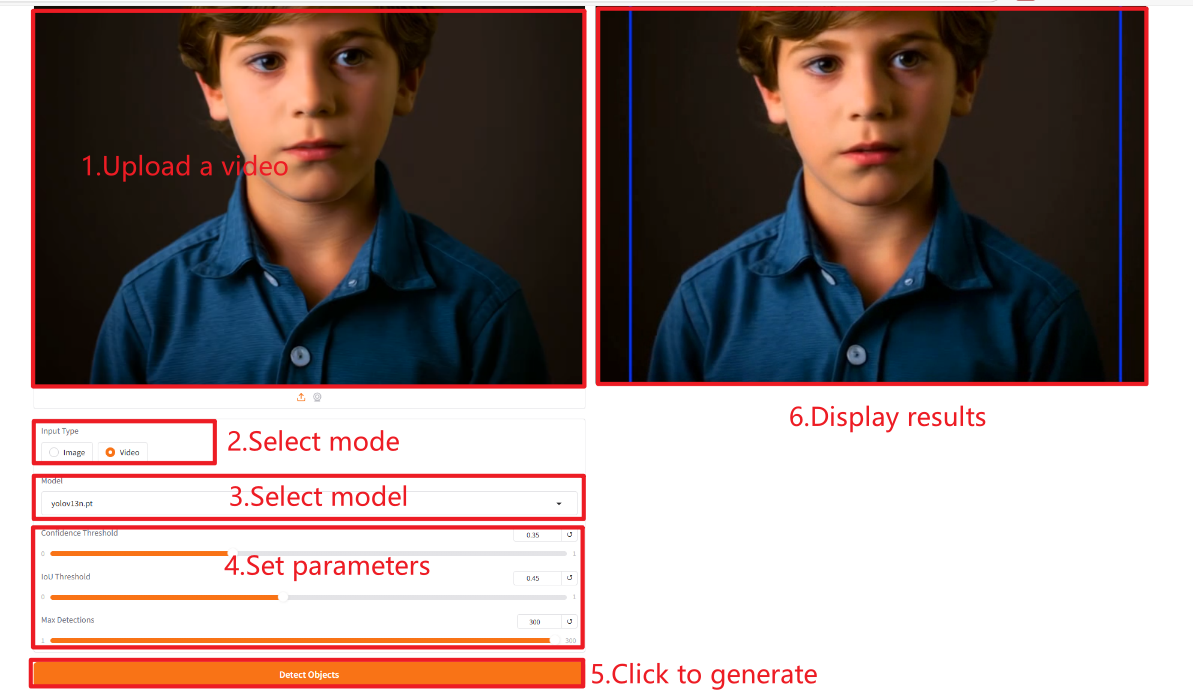
パラメータの説明
- モデル: yolov13n.pt (ナノ)、yolov13s.pt (小)、yolov13l.pt (大)、yolov13x.pt (特大)。一般的に、モデルが大きいほど精度 (mAP) は高くなりますが、パラメータ数、計算コスト (FLOP)、推論時間も長くなります。
- 信頼度しきい値: 信頼度しきい値。
- IoU しきい値: NMS で使用される、IoU (Intersection over Union) しきい値。
- 画像あたりの最大検出数: 画像あたりの検出ボックスの最大数。
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。
引用情報
このプロジェクトの引用情報は次のとおりです。
@article{yolov13,
title={YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception},
author={Lei, Mengqi and Li, Siqi and Wu, Yihong and et al.},
journal={arXiv preprint arXiv:2506.17733},
year={2025}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。