HyperAI
Command Palette
Search for a command to run...
HuMo-17B: 三峰性協創
1. チュートリアルの概要

HuMoは、清華大学とByteDanceのインテリジェントクリエーションラボが2025年9月に発表した、人間中心の動画生成に重点を置いたマルチモーダル動画生成フレームワークです。テキスト、画像、音声など、複数のモーダル入力から、高品質で精細、かつ制御可能な人間のような動画を生成できます。HuMoは、強力なテキストキュー追従機能、一貫した被写体保持機能、音声駆動によるモーション同期機能を備えています。テキスト-画像(Text-ImageからVideoGen)、テキスト-音声(Text-AudioからVideoGen)、テキスト-画像-音声(Text-Image-AudioからVideoGen)からの動画生成をサポートしています。関連研究論文も公開されています。 HuMo: 協調的マルチモーダルコンディショニングによる人間中心のビデオ生成 。
HuMoプロジェクトは、1.7Bと17Bの2つの仕様でモデルデプロイメントを提供しています。このチュートリアルでは、17Bモデルと1枚のRTX Pro 6000カードをリソースとして使用します。
→ クリックして体験へジャンプHuMo 1.7B: マルチモーダルビデオ生成のためのフレームワーク”。
2. プロジェクト例
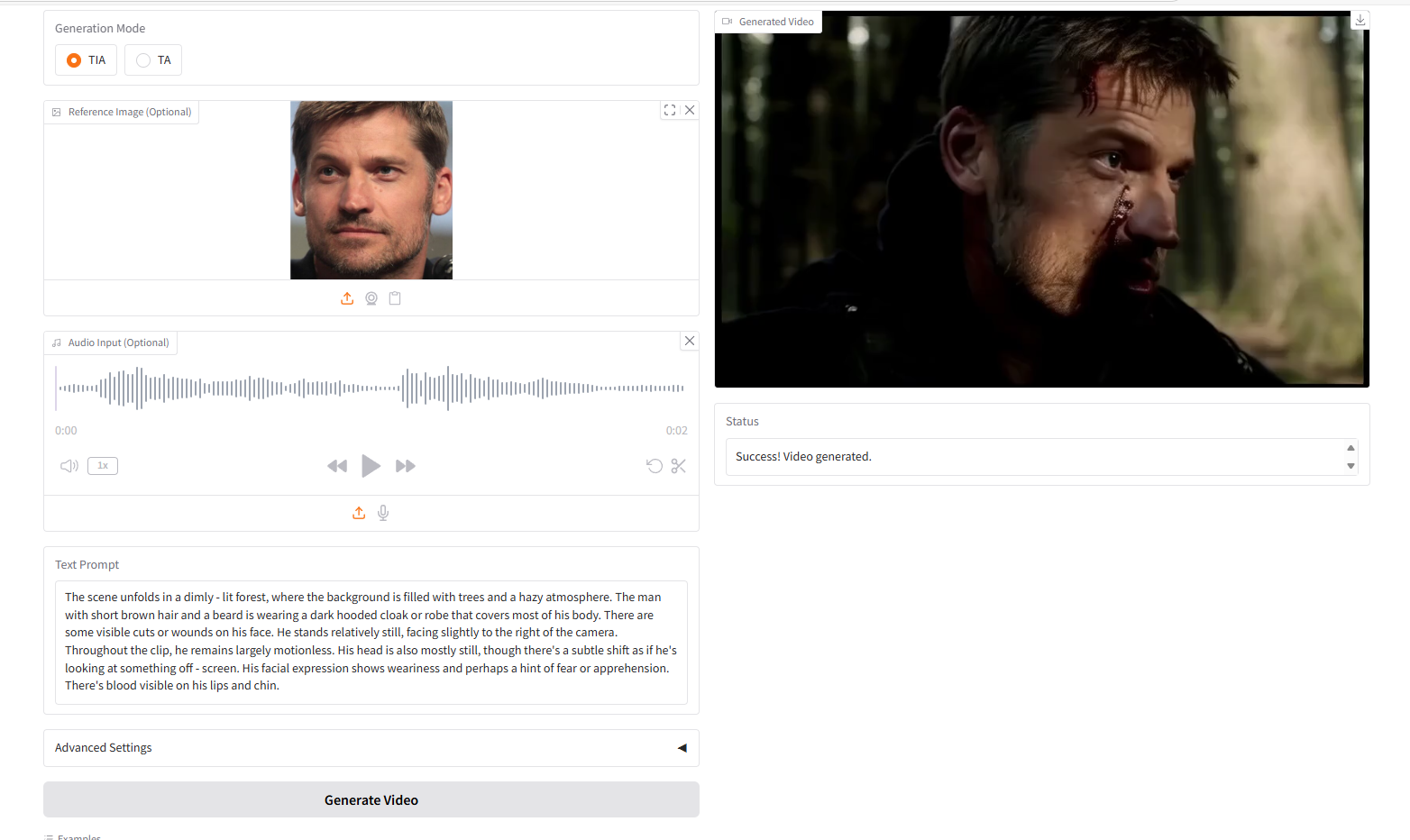
テキスト・画像・音声、TIAからのVideoGen
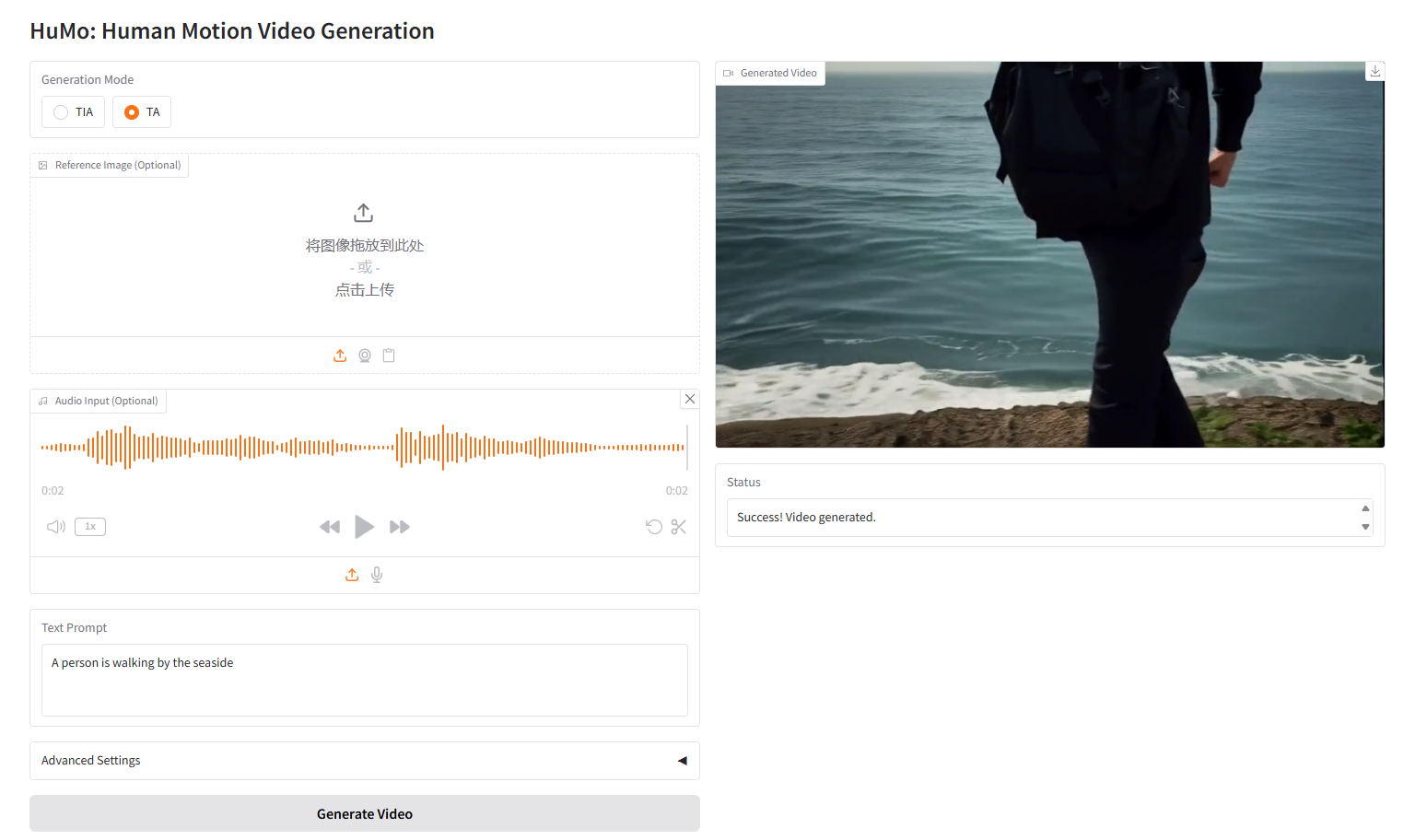
Text-Audio、TA の VideoGen
3. 操作手順
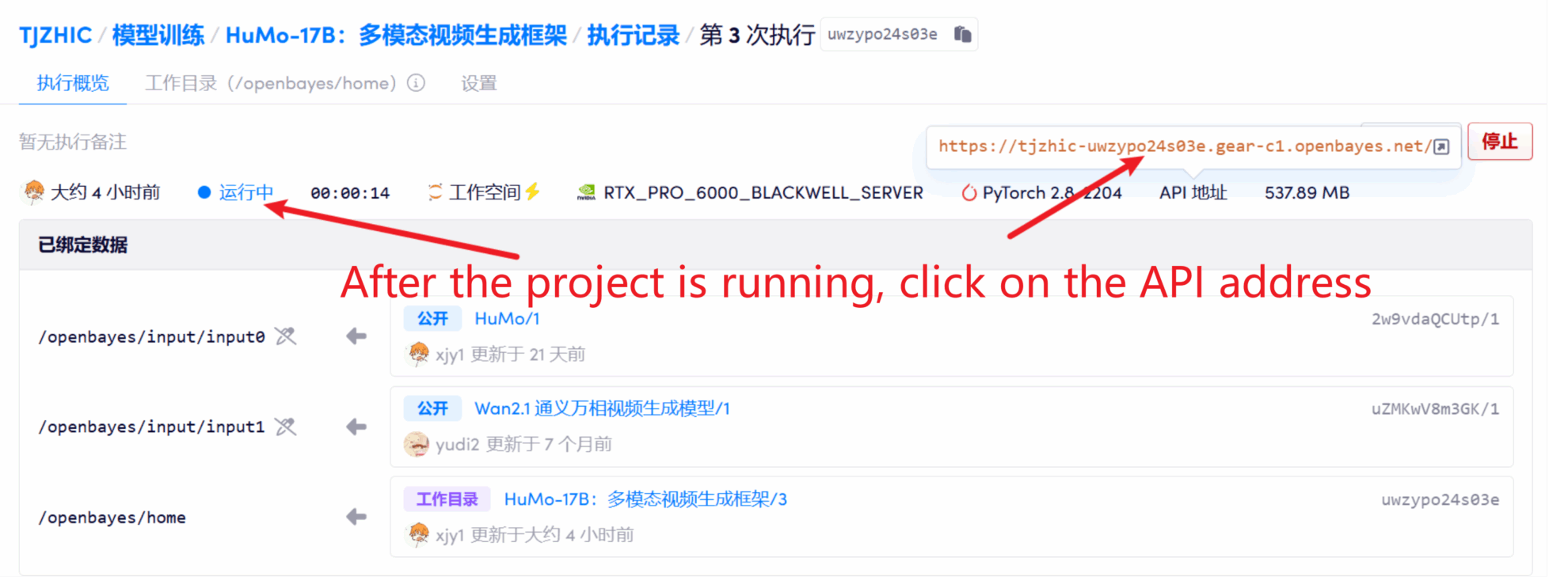
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。 注: サンプリング ステップを 10 に設定すると、結果の生成に約 3 ~ 5 分かかります。
TIA
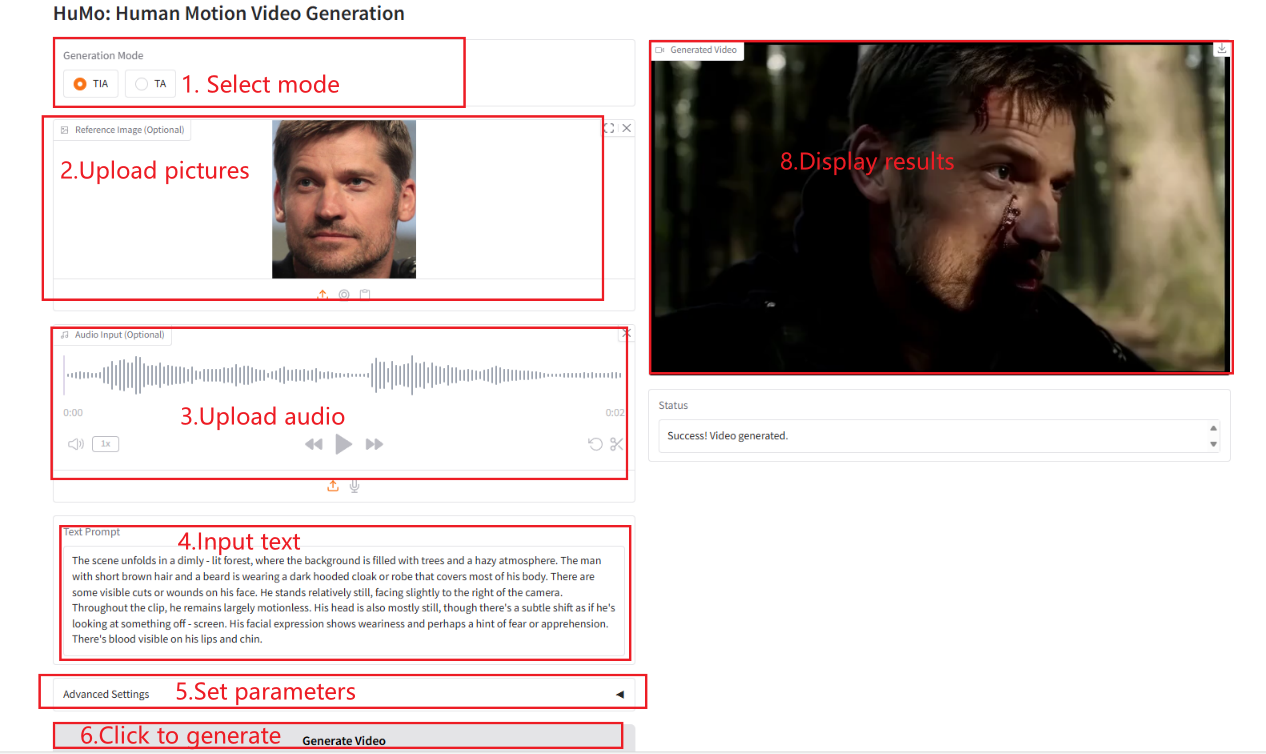
TA
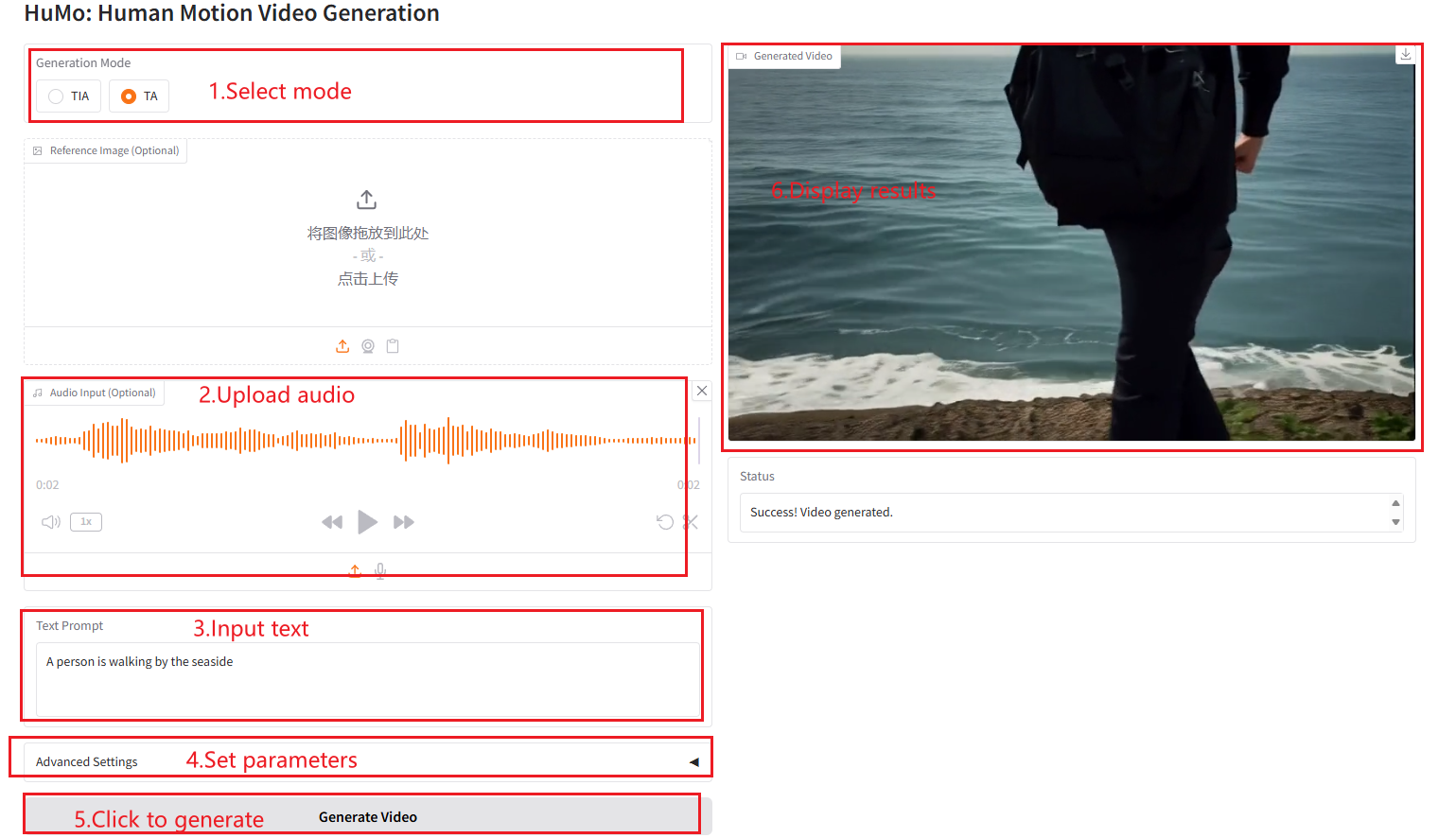
パラメータの説明
- 高さ: ビデオの高さを設定します。
- 幅: ビデオの幅を設定します。
- フレーム: ビデオ フレームの数を設定します。
- テキスト ガイダンス スケール: テキスト ガイダンスのスケーリング。ビデオ生成時のテキスト プロンプトの影響を制御するために使用されます。
- 画像ガイダンス スケール: 画像ガイダンスのスケーリング。ビデオ生成における画像キューの影響を制御するために使用されます。
- オーディオ ガイダンス スケール: オーディオ キューがビデオ生成に与える影響を制御するために使用されるオーディオ ガイダンス スケーリング。
- サンプリング ステップ: 生成されたビデオの品質と詳細を制御するために使用されるサンプリング ステップの数。
- ランダム シード: ビデオ生成のランダム性を制御するために使用されるランダム シード。
引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{chen2025humo,
title={HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning},
author={Liyang Chen and Tianxiang Ma and Jiawei Liu and Bingchuan Li and Zhuowei Chen and Lijie Liu and Xu He and Gen Li and Qian He and Zhiyong Wu},
year={2025},
eprint={2509.08519},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.08519},
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。