Command Palette
Search for a command to run...
USO: 統一されたスタイルと主題に基づく画像生成モデル
1. チュートリアルの概要

2025年8月にByteDanceのUXOチームによってリリースされたUSOは、コンテンツとスタイルの分離と再結合のための統合フレームワークです。あらゆるシーンのあらゆるテーマとスタイルを自由に組み合わせ、高い被写体一貫性、強力なスタイル忠実度、そして自然で不自然ではない感覚を持つ画像を生成します。USOは大規模なトリプレットデータセットを構築し、スタイル特徴の整合とコンテンツとスタイルの分離を同時に行うデカップリング学習スキームを採用し、さらにスタイル報酬学習(SRL)を導入することでモデル性能を向上させています。USOは、スタイルの類似性と被写体忠実度を総合的に評価するためのベンチマークテスト「USO-Bench」を公開しました。実験では、USOが被写体一貫性とスタイル類似性の両方において、オープンソースモデルの中で最先端の性能を達成していることが示されています。関連研究論文も公開されています。 USO: 分離学習と報酬学習による統一スタイルと主題主導型生成 。
このチュートリアルで使用されるコンピューティング リソースは、単一の RTX 4090 カードです。
2. エフェクト表示
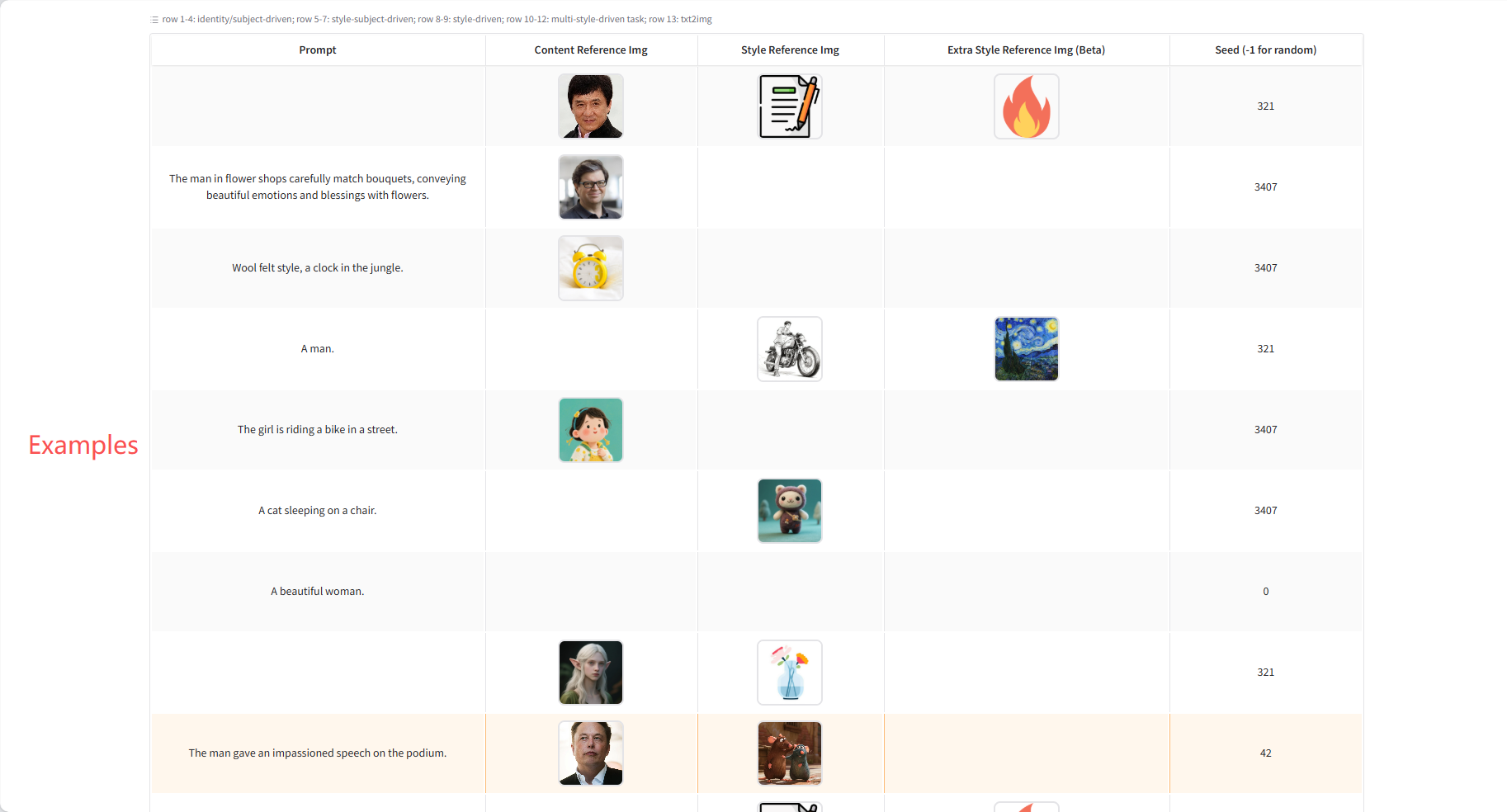
テーマ/アイデンティティ主導の世代
被写体を新しいシーンに配置する場合は、「犬/男性/女性が…している」といった自然な表現を使用してください。レイアウトを維持したままスタイルのみを変換したい場合は、「スタイルを…のスタイルに転送する」といったガイドキューを使用してください。ポートレート生成において、USOは肌のディテールが鮮明な画像の生成に優れています。実践ガイド:半身のキューには半身のクローズアップを使用し、ポーズや構図が大きく変わる場合は全身画像を使用してください。

スタイル主導の世代
あなたのスタイルに合った画像を1枚か2枚アップロードし、自然な言葉で希望の画像を作成してください。USOはあなたの指示に従って、アップロードしたスタイルに合った画像を生成します。

スタイルテーマ主導の生成
USOは、1つまたは2つのスタイル参照を使用して、単一のコンテンツ参照にスタイルを設定できます。レイアウトを保持するビルドの場合は、ヒントを空に設定するだけです。
レイアウトを保持するビルド

レイアウトオフセット生成

3. 操作手順
1. コンテナを起動します
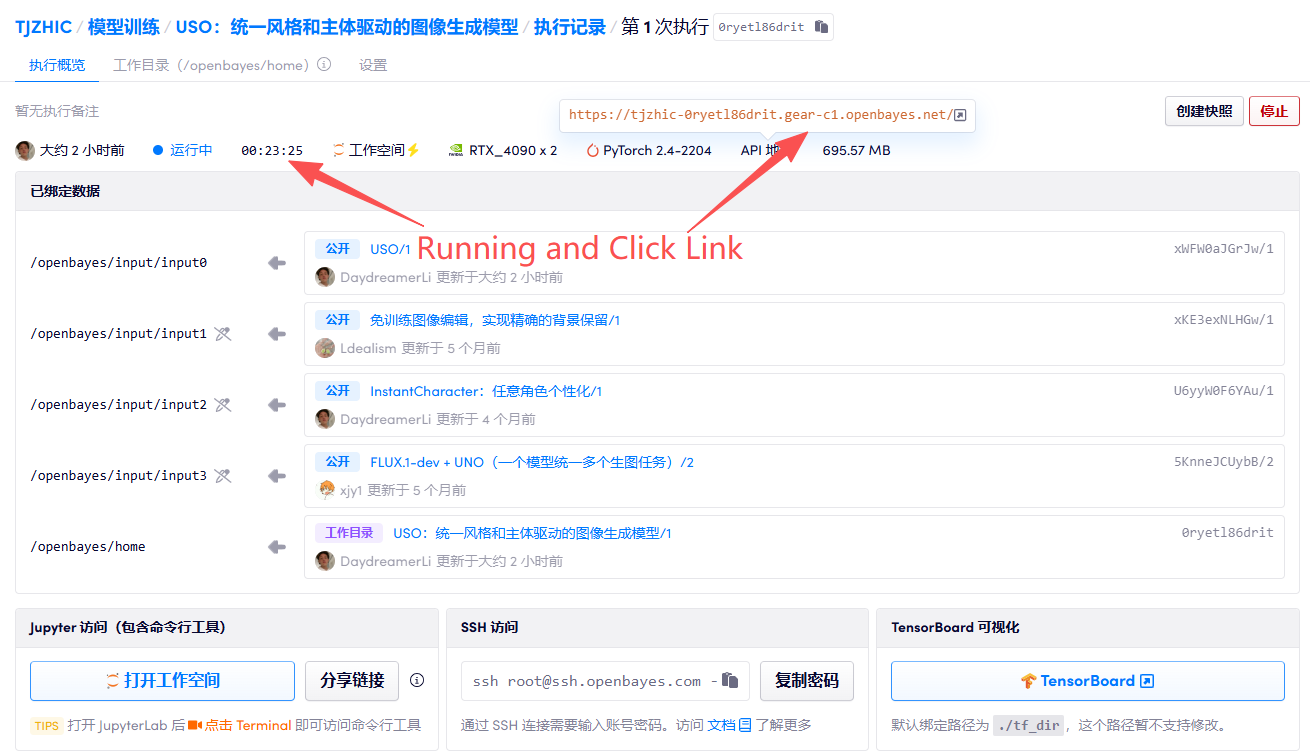
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
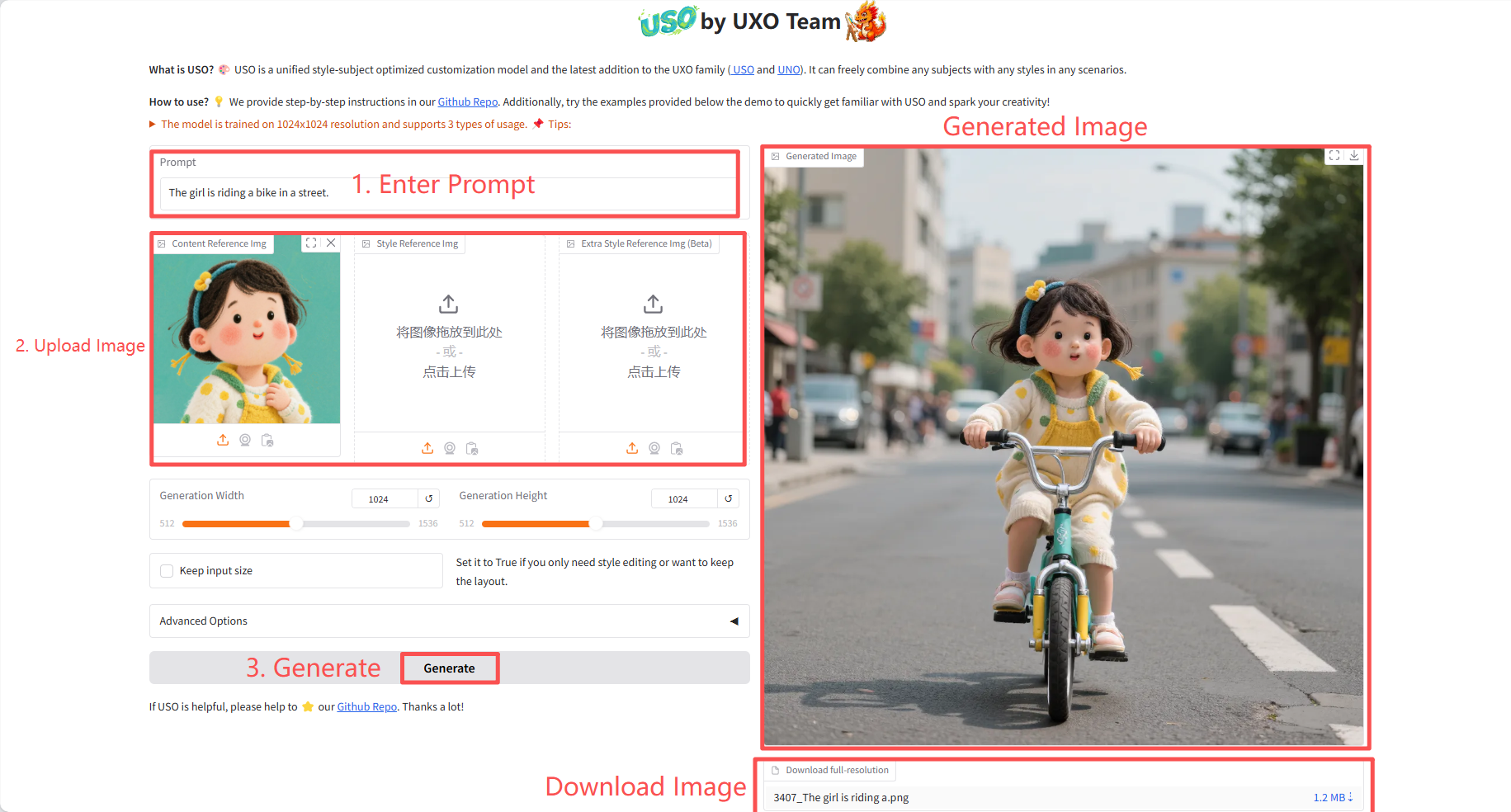
具体的なパラメータ:
- 生成幅: 画像の幅を生成します。
- 生成高さ: 生成される画像の高さ。
- 入力サイズを維持: スタイルの編集のみが必要な場合、またはレイアウトを保持する場合は、これを True に設定します。
- 詳細オプション:
- ステップ数:拡散モデル生成プロセスにおける反復回数を制御します。ステップ数が多いほど理論的には画像品質は向上しますが、生成時間も長くなります。
- ガイダンス: 生成された画像がプロンプトの単語と参照画像にどの程度従うかを制御します。
- コンテンツ参照サイズ: コンテンツ参照画像を処理する際、特徴抽出の前に、指定された最長辺の長さ (アスペクト比を維持) に拡大縮小される場合があります。
- シード (ランダムの場合は -1): 乱数ジェネレーターの初期状態を制御します。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
Githubユーザーに感謝 スーパーヤン このチュートリアルの展開。このプロジェクトの引用情報は次のとおりです。
@article{wu2025uso,
title={USO: Unified Style and Subject-Driven Generation via Disentangled and Reward Learning},
author={Shaojin Wu and Mengqi Huang and Yufeng Cheng and Wenxu Wu and Jiahe Tian and Yiming Luo and Fei Ding and Qian He},
year={2025},
eprint={2508.18966},
archivePrefix={arXiv},
primaryClass={cs.CV},
}