Command Palette
Search for a command to run...
vLLM + Open WebUI で NVIDIA-Nemotron-Nano-9B-v2 をデプロイする
1. チュートリアルの概要
NVIDIA-Nemotron-Nano-9B-v2は、NVIDIAチームが2025年8月19日にリリースした軽量大規模言語モデルです。Nemotronシリーズのハイブリッドアーキテクチャ最適化版であるこのモデルは、Mambaの効率的な長文処理能力とTransformerの強力なセマンティックモデリング能力を革新的に統合しています。わずか90億(9B)のパラメータで128Kの超長コンテキストサポートを実現します。推論効率とエッジコンピューティングデバイス(RTX 4090レベルのGPUなど)におけるタスクパフォーマンスは、同様のパラメータサイズを持つ最先端モデルに匹敵し、大規模言語モデルの軽量展開と長文理解における大きな進歩を示しています。関連研究論文も入手可能です。 NVIDIA Nemotron Nano 2: 正確で効率的なハイブリッド Mamba-Transformer 推論モデル 。
このチュートリアルでは、リソースとして単一の RTX A6000 カードを使用します。
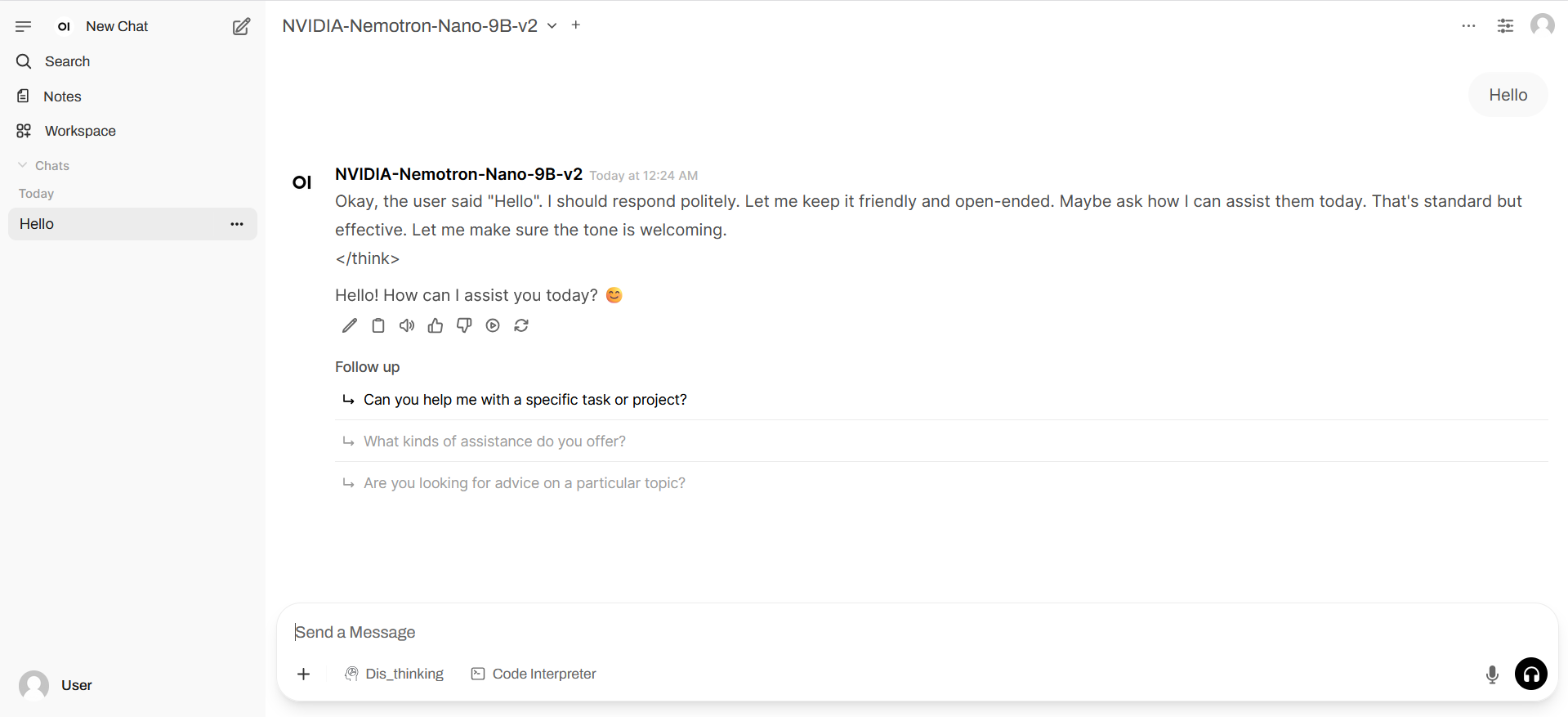
2. プロジェクト例
3. 操作手順
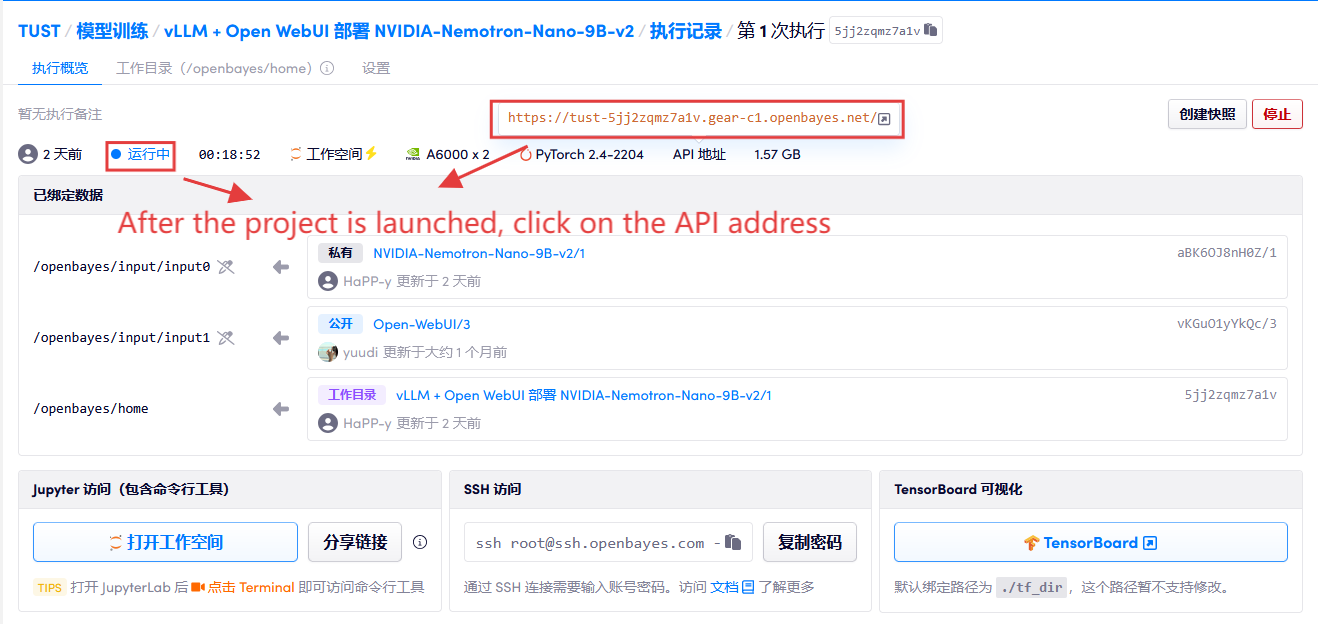
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
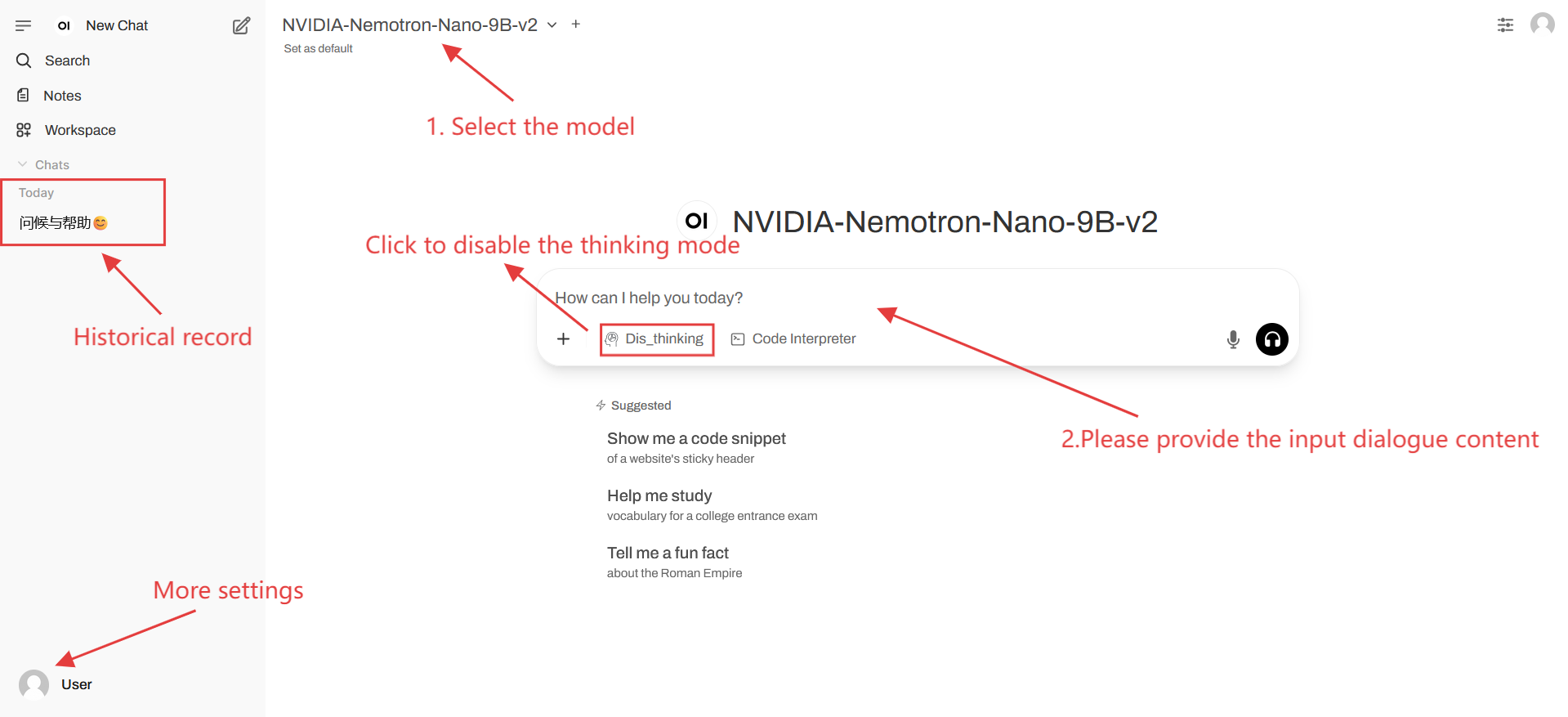
2. Web ページに入ると、モデルと会話を開始できます。
「モデル」が表示されない場合は、モデルが初期化中です。モデルのサイズが大きいため、2~3分ほどお待ちいただき、ページを更新してください。
利用手順
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{nvidia2025nvidianemotronnano2,
title={NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model},
author={NVIDIA},
year={2025},
eprint={2508.14444},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.14444},
}