HyperAI
Command Palette
Search for a command to run...
Ovis-U1-3B: マルチモーダル理解・生成モデル
1. チュートリアルの概要

Ovis-U1-3Bは、アリババグループのOvisチームが2025年6月29日にリリースしたマルチモーダル統合モデルです。このモデルは、マルチモーダル理解、テキスト画像生成、画像編集という3つのコア機能を統合しています。高度なアーキテクチャと協調型統合学習法に基づき、高忠実度画像合成と効率的なテキストビジュアルインタラクションを実現します。マルチモーダル理解、生成、編集を含む複数の学術ベンチマークテストにおいて、Ovis-U1は優れた結果を達成し、強力な一般化能力と優れた性能を示しました。関連研究論文も公開されています。 Ovis-U1 技術レポート 。
このチュートリアルでは、RTX 4090 グラフィックカードを1枚使用します。テスト例として、「画像 + テキスト → 画像」、「テキスト → 画像」、「画像 → テキスト」の3つの例を示します。
2. プロジェクト例

3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
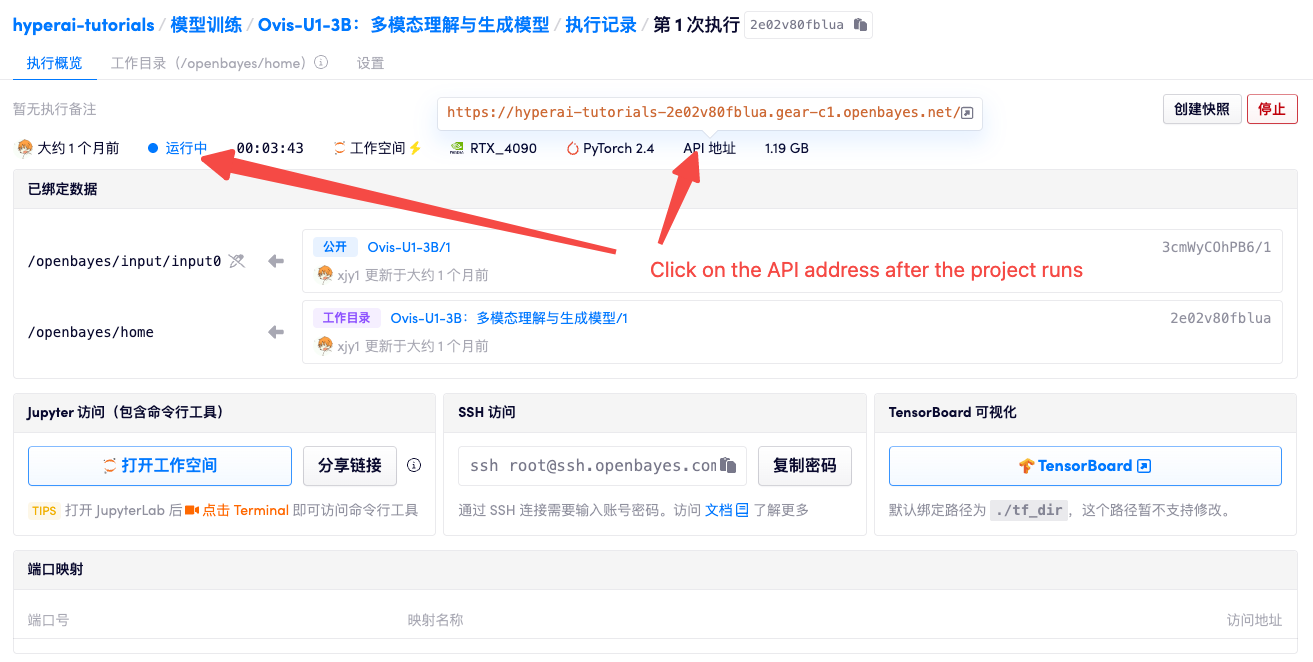
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
2.1 画像 + テキスト → 画像
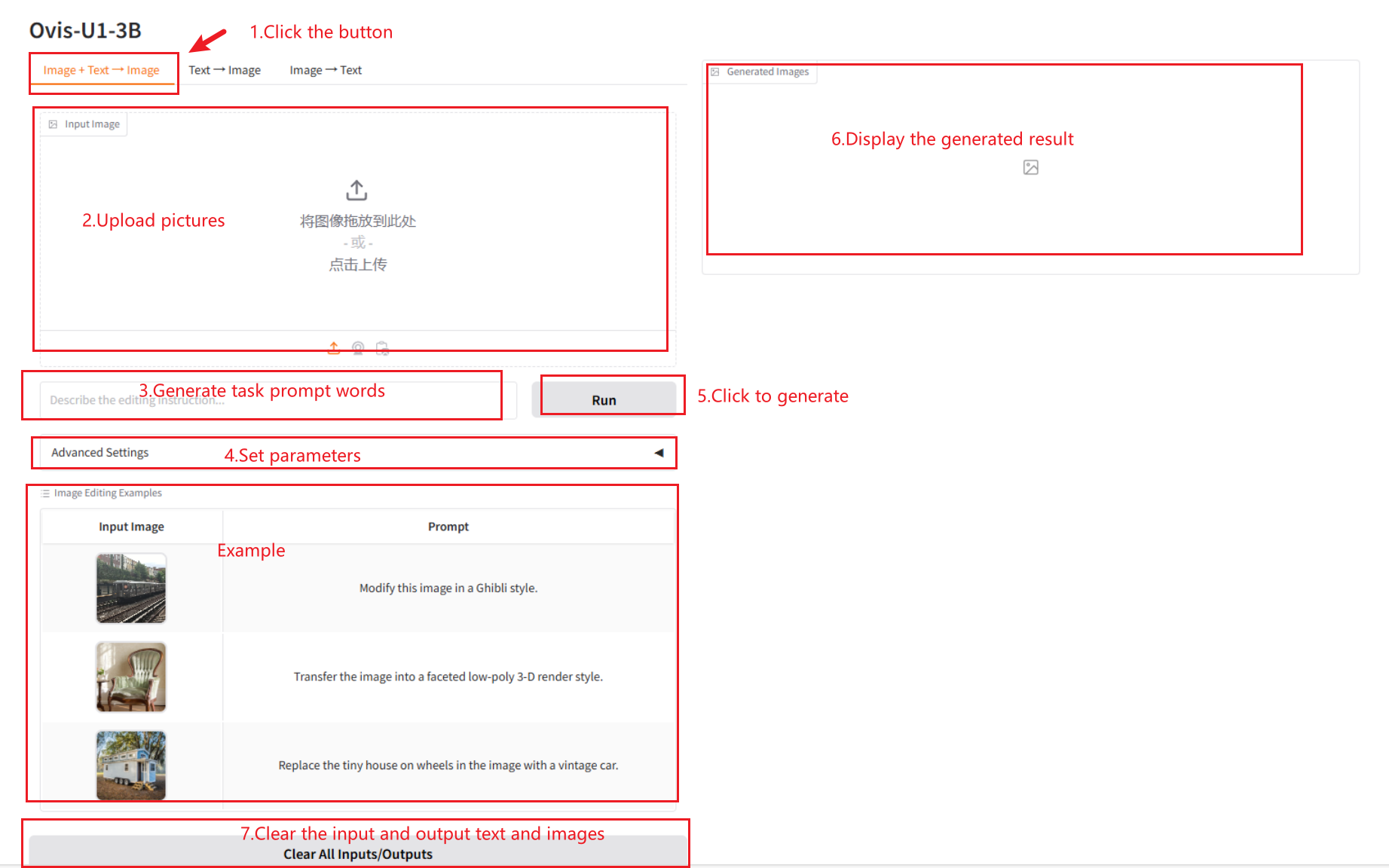
パラメータの説明
- 詳細設定
- 画像ガイダンススケール: 生成された画像に対するテキストキューの影響の強さを制御します。
- テキストガイダンススケール: 生成された画像に対する入力画像の影響を制御します。
- ステップ: 画像生成の反復回数。
- シード: 画像生成プロセスの繰り返しのためのランダム シード。
- シードをランダム化: シードをランダム化します。画像が生成されるたびに、新しいシードがランダムに生成されます。
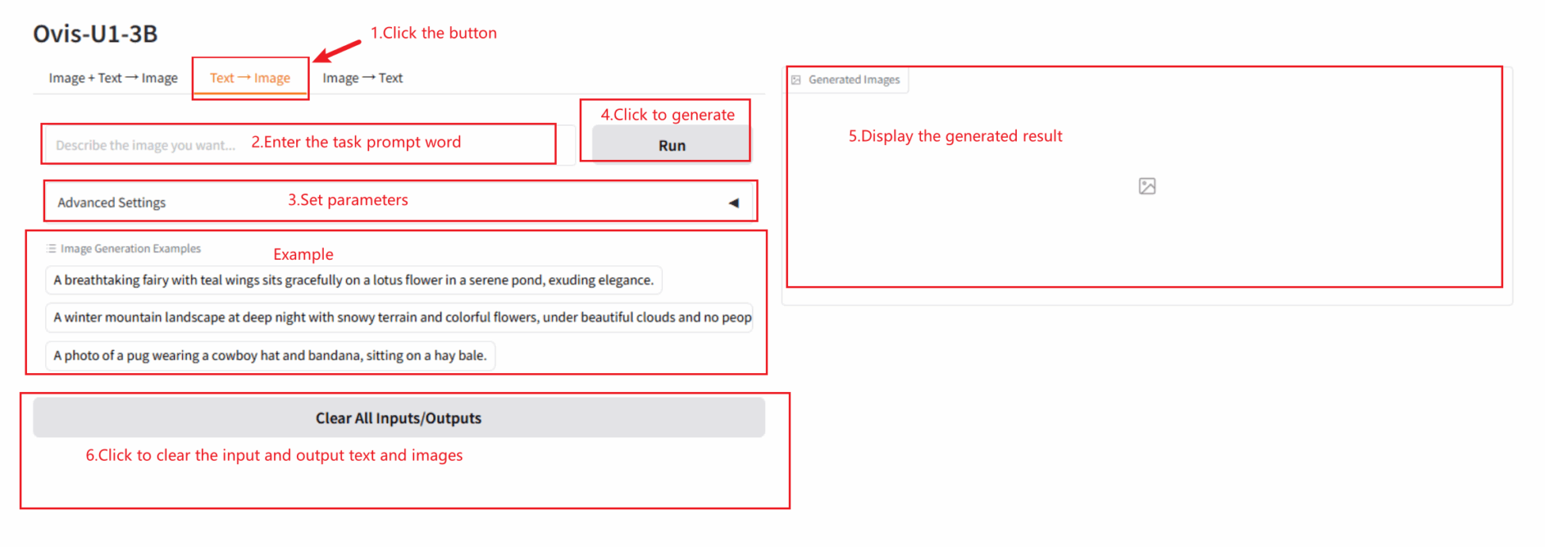
2.2 テキスト → 画像
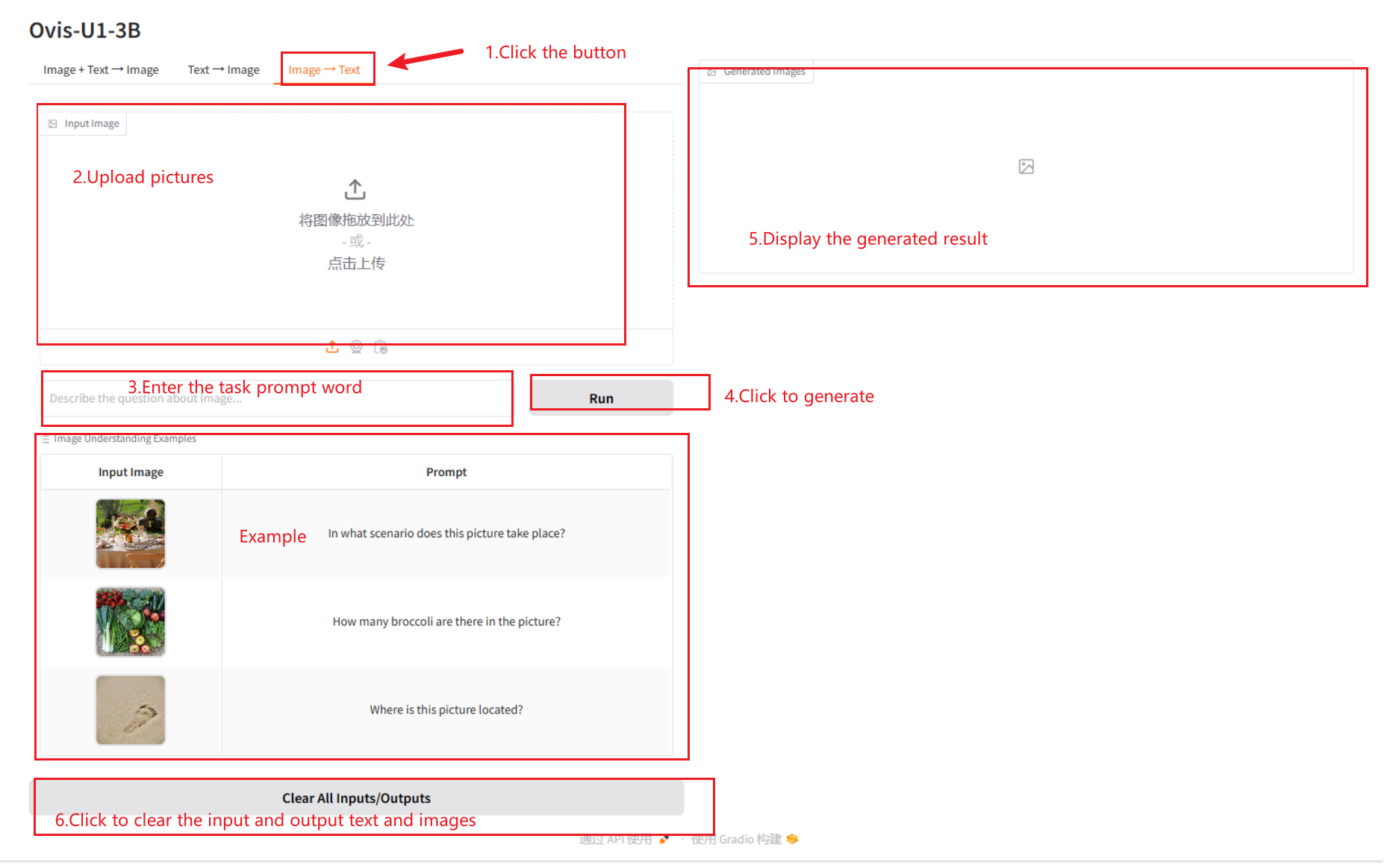
2.3 画像 → テキスト
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
このプロジェクトの引用情報は次のとおりです。
@article{wang2025ovisu1,
title={Ovis-U1 Technical Report},
author={Wang, Guo-Hua and Zhao, Shanshan and Zhang, Xinjie and Cao, Liangfu and Zhan, Pengxin and Duan, Lunhao and Lu, Shiyin and Fu, Minghao and Zhao, Jianshan and Li, Yang and Chen, Qing-Guo},
journal={arXiv preprint arXiv:2506.23044},
year={2025}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。