HyperAI
Command Palette
Search for a command to run...
PlayDiffusion: オープンソースのオーディオローカル編集モデル
1. チュートリアルの概要

主な機能:
- 部分的なオーディオ編集: オーディオ セグメント全体を再生成せずに、オーディオの部分的な置き換え、変更、または削除をサポートし、音声を自然でシームレスに保ちます。
- 効率的な TTS: 音声全体をマスキングする場合、効率的な TTS モデルとして、推論速度は従来の TTS より 50 倍速く、音声の自然さと一貫性も向上します。
- 音声の連続性を維持: 編集時にコンテキストを保持して、音声の連続性と話者の一貫した音色を確保します。
- 動的な音声修正: 新しいテキストに応じて音声の発音、トーン、リズムを自動的に調整します。リアルタイムのインタラクションなどのシナリオに適しています。
技術原理:
- オーディオエンコーディング:入力されたオーディオシーケンスを、各トークンがオーディオの単位を表す個別のトークンシーケンスにエンコードします。実際の音声と、テキスト読み上げモデルによって生成されたオーディオに適用できます。
- マスク処理: オーディオの一部を変更する必要がある場合は、後続の処理を容易にするために、その部分をマスクとしてマークします。
- 拡散モデルによるノイズ除去:テキストを更新する拡散モデルに基づいて、マスクされた領域のノイズを除去します。拡散モデルは、段階的なノイズ除去に基づいて高品質な音声トークンのシーケンスを生成します。すべてのトークンは、非自己回帰法を用いて同時に生成され、固定数のノイズ除去ステップに基づいて調整されます。
- オーディオ波形へのデコード: 生成されたトークン シーケンスは、BigVGAN デコーダー モデルに基づいて音声波形に変換され、最終的な出力音声が自然で一貫性のあるものになることが保証されます。
このチュートリアルでは、RTX A6000 コンピューティングリソースを1つ使用し、インペイント、テキスト読み上げ、音声変換の3つのテスト例を紹介します。このチュートリアルは英語のみに対応しています。
2. エフェクト表示
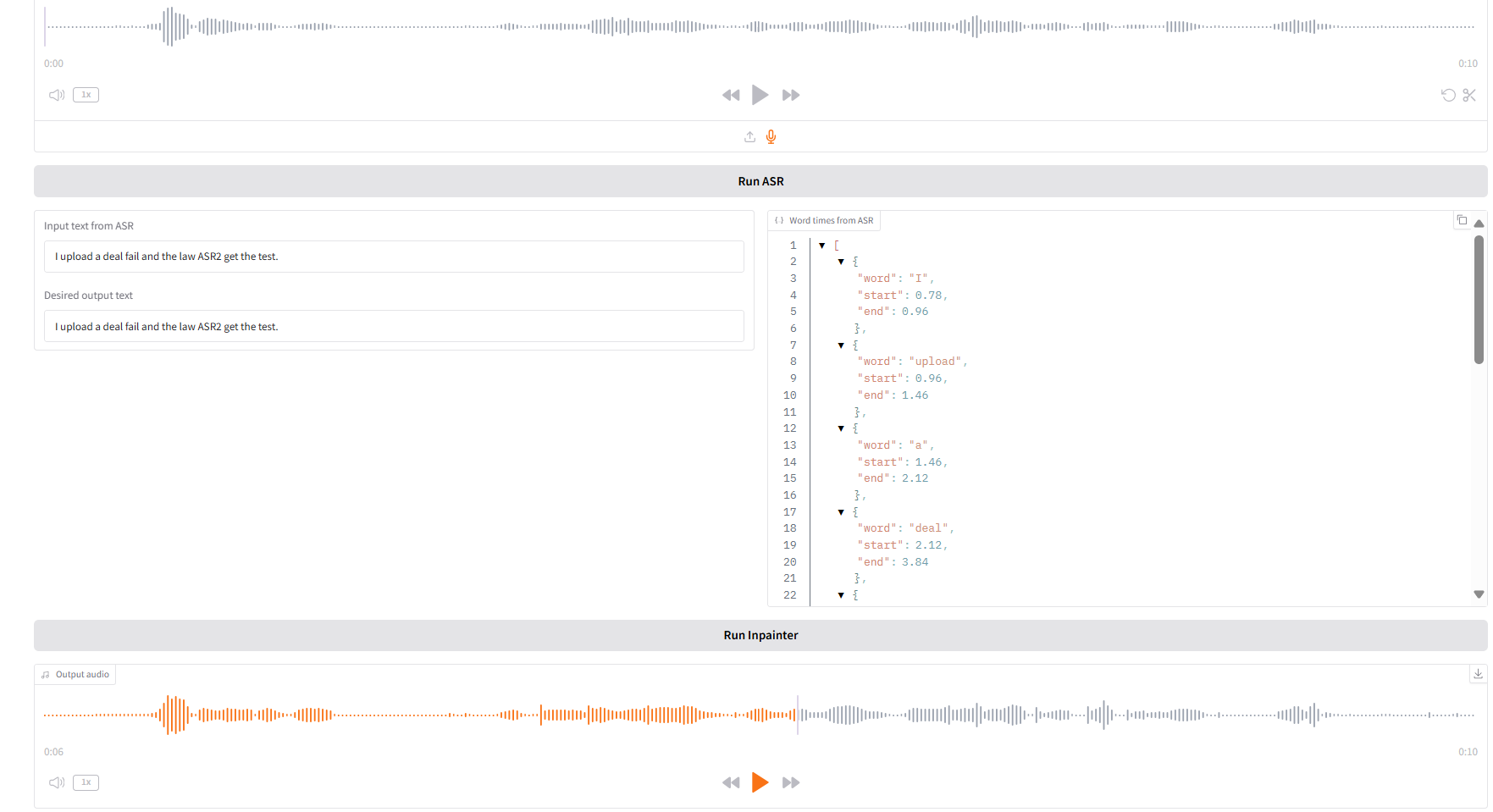
1. インペイント
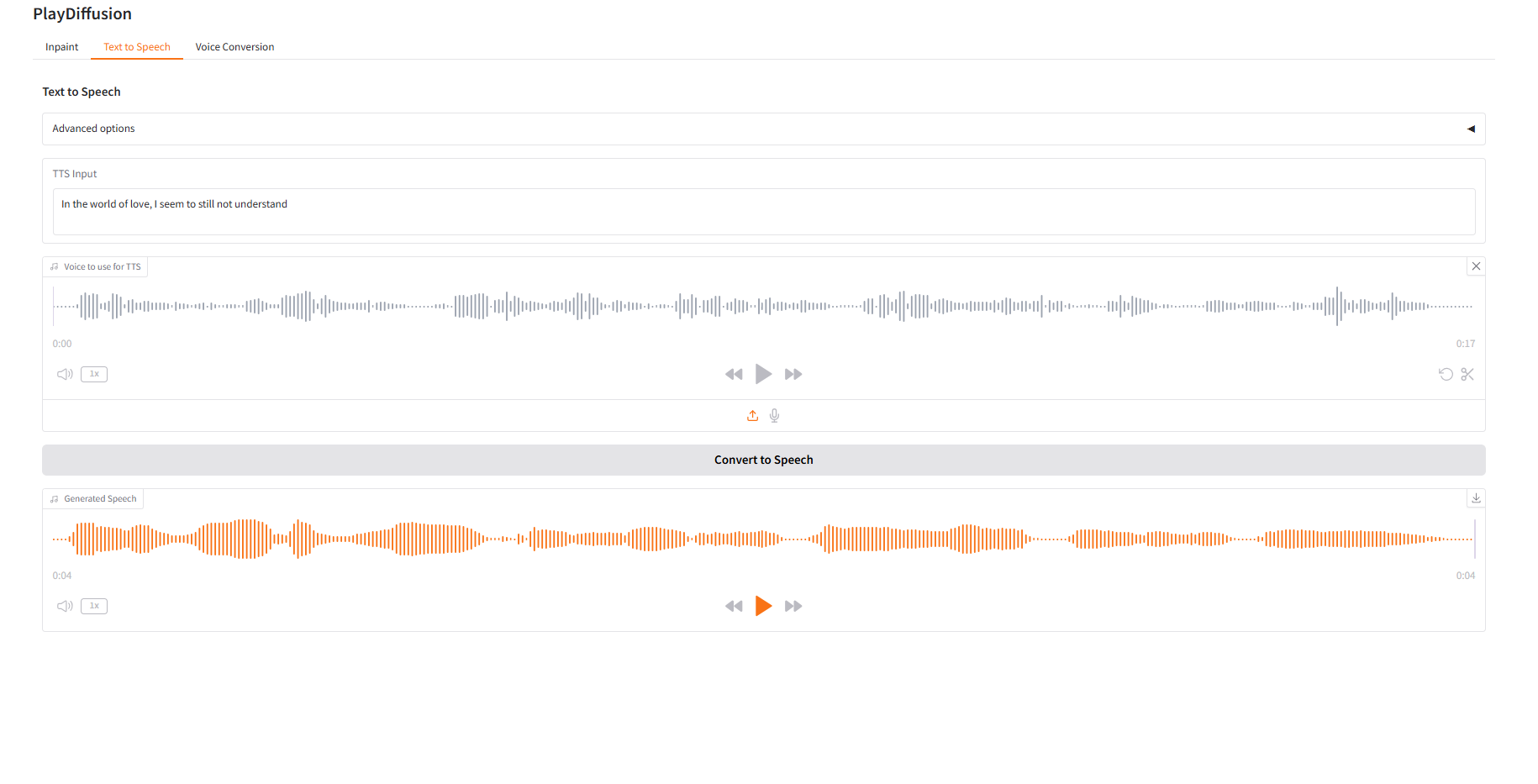
2. テキスト読み上げ
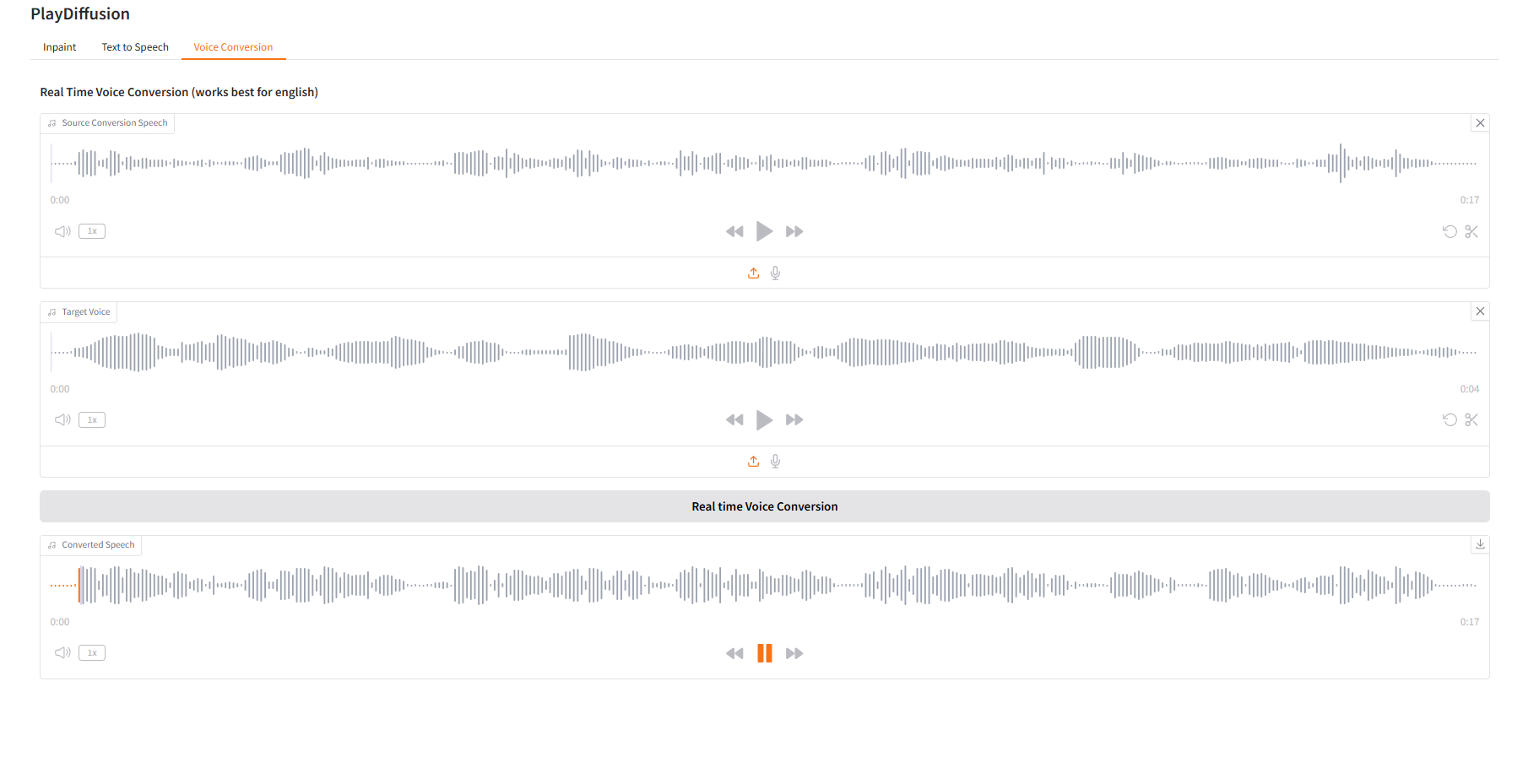
3. 音声変換
3. 操作手順
1. コンテナを起動します
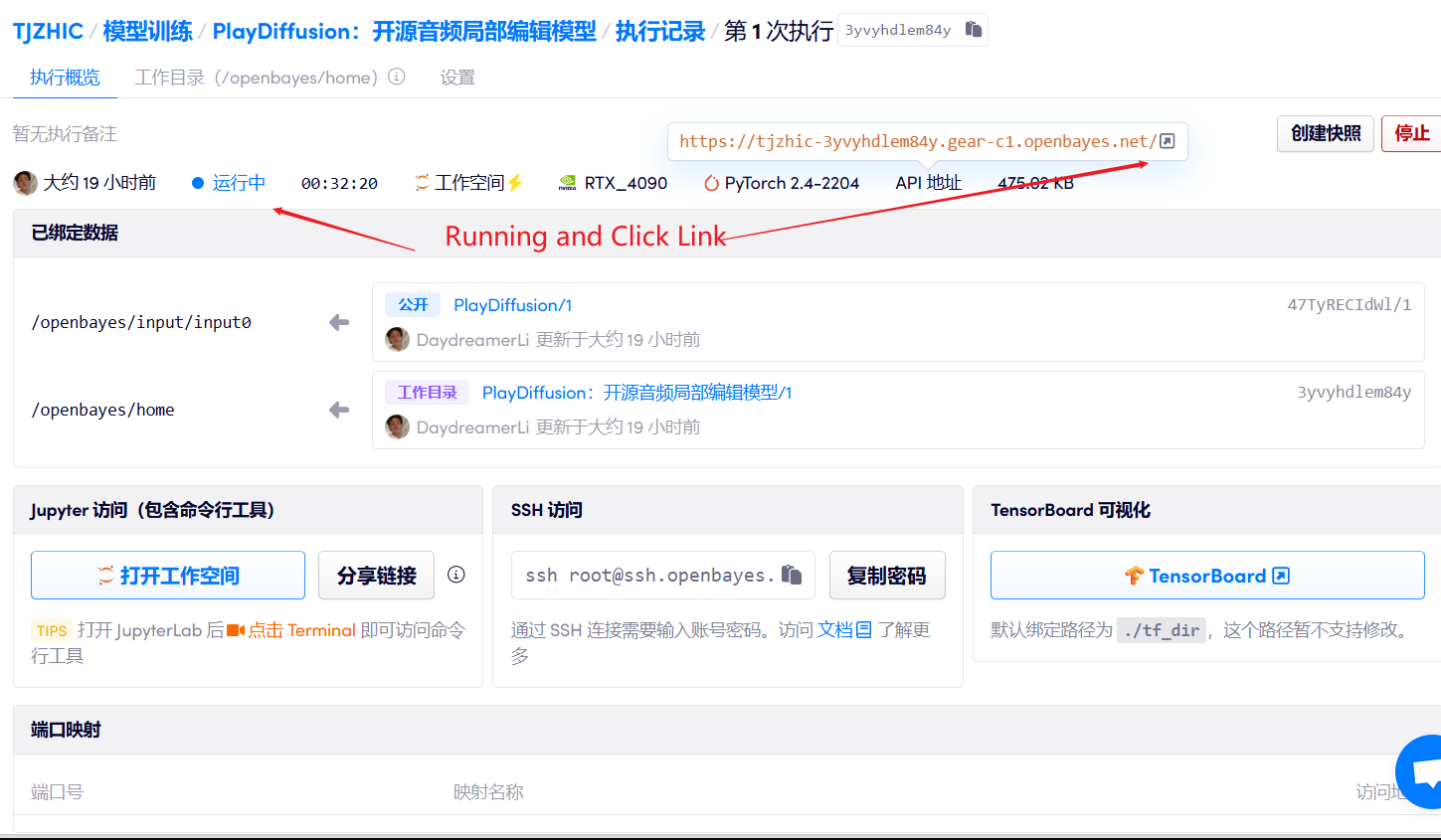
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
1. インペイント
このモジュールは、オーディオ全体を再生成せずに、オーディオの一部を置き換えたり、変更したり、削除したりできるため、スピーチは自然でシームレスに保たれます。
- 元の音声をアップロードし、「SAR 実行」をクリックして実行した後、「希望する出力テキスト」で出力する音声コンテンツを修正・編集します。
- 次に、「Inpainter を実行」をクリックして、編集したオーディオを生成します。
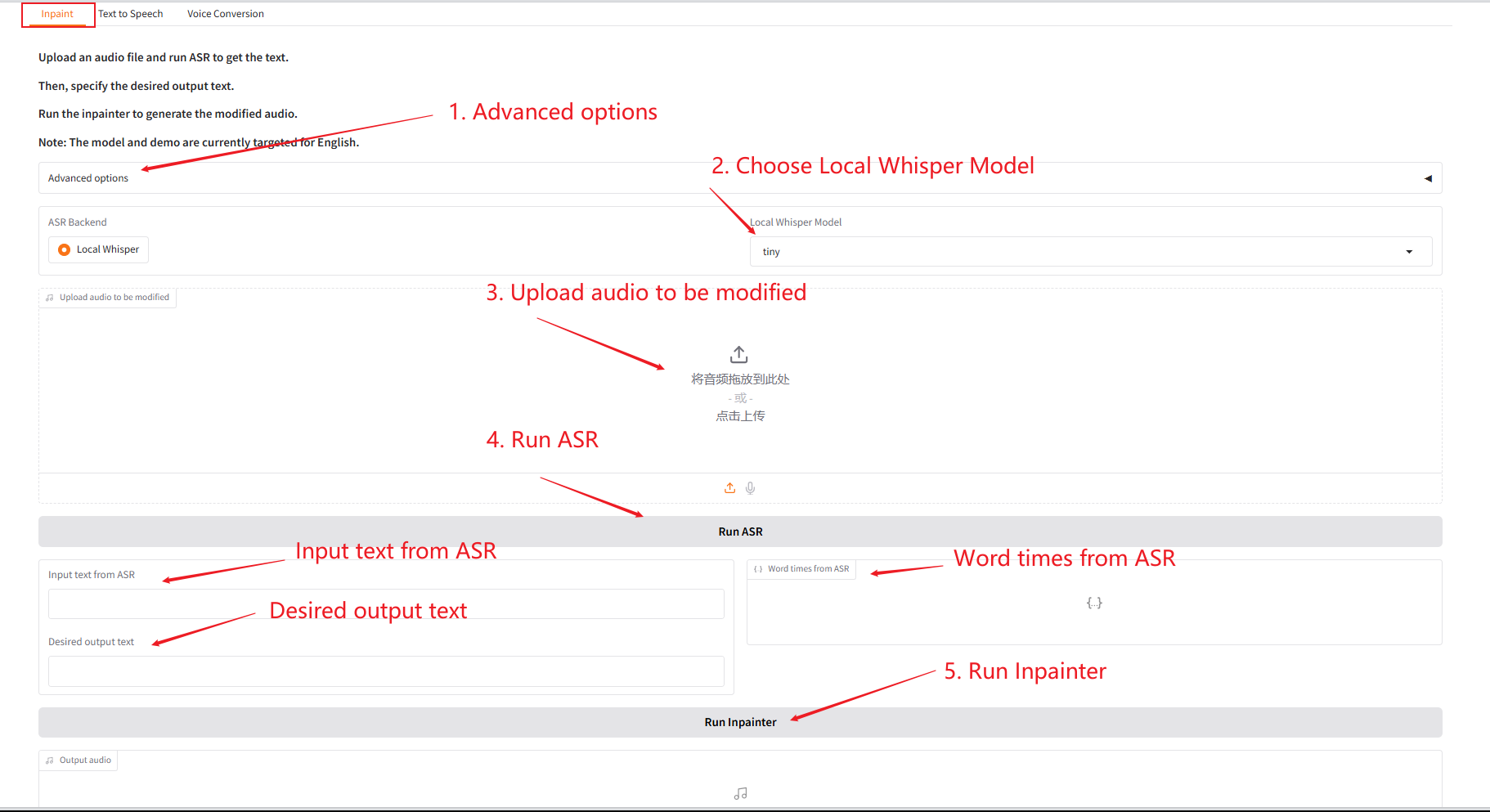
パラメータの説明:
- サンプリングステップ数:拡散モデル生成プロセスにおける反復回数。ステップ数が多いほど生成品質は向上しますが、時間は長くなります。
- コードブック: ベクトル量子化レイヤー内の離散シンボルの辞書。連続的な特徴を離散的な表現にマッピングするために使用されます。
- 初期温度:サンプリングのランダム性を制御するパラメータ。値が高いほど多様性が増し、値が低いほど結果の確実性が増します。
- 初期多様性: 生成されたサンプルの変動の度合いを制御し、あまりにも類似した結果が生成されないようにするパラメーター。
- ガイダンス: 生成された結果に対する条件情報 (テキストなど) の影響度を調整します。
- ガイダンス再スケール係数: 条件付きガイダンスと無条件生成のバランスをとるために使用される重み比。
- 上位 k ロジットからのサンプリング: 生成品質を向上させるために、最も確率の高い K 個の候補のみを選択します。
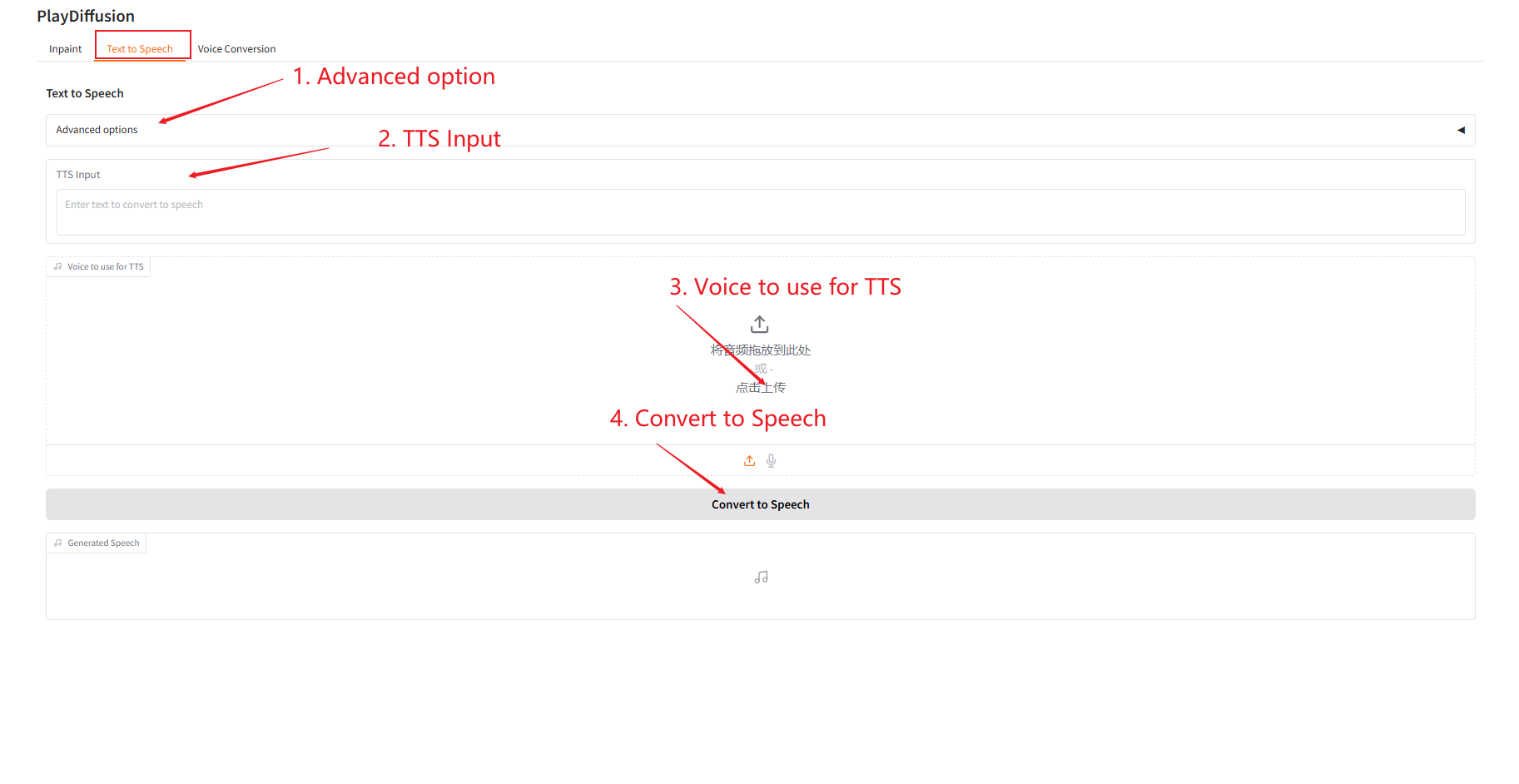
2. テキスト読み上げ
効率的な TTS モデルとして、推論速度は従来の TTS より 50 倍速く、音声の自然さと一貫性も優れています。
- 「TTS 入力」にオーディオを生成するテキスト コンテンツを入力し、対象のオーディオをアップロードします。
- 次に、「音声に変換」をクリックして音声を生成します。
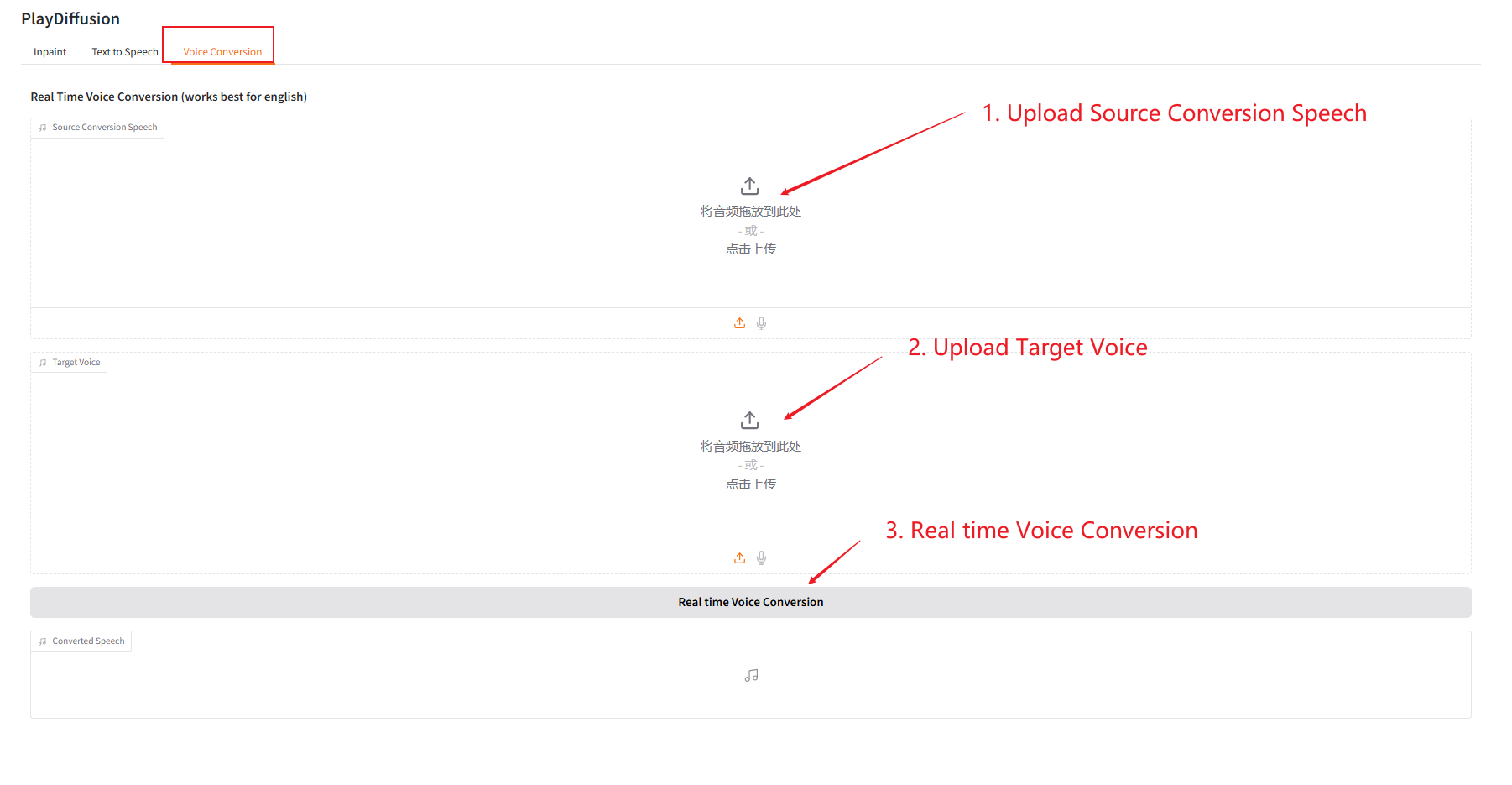
3. 音声変換
音声コンテンツを動的に調整し、元のオーディオコンテンツをターゲットの音色に直接複製できます。
- 元のオーディオをアップロードしてから、ターゲットオーディオをアップロードします。
- 次に、「リアルタイム音声変換」をクリックして、対象トーンの元のオーディオコンテンツを直接生成します。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。