Command Palette
Search for a command to run...
MAGI-1: 世界初の大規模自己回帰ビデオ生成モデル
1. チュートリアルの概要

中国のAI企業SendAIが2025年4月21日に正式リリースしたMagi-1は、世界初の大規模自己回帰動画生成モデルです。連続するフレームの固定長セグメントとして定義される自己回帰を用いて、一連の動画ブロックを予測することで動画を生成します。学習後、Magi-1は時間の経過とともに単調に増加するノイズブロックをそれぞれ除去し、因果的な時間的モデリングをサポートし、ストリーミング生成を自然にサポートします。テキスト指示を条件とする画像から動画への変換タスクにおいて強力なパフォーマンスを発揮し、複数のアルゴリズム革新と専用のインフラストラクチャスタックを通じて、高い時間的一貫性とスケーラビリティを実現します。関連研究論文も入手可能です。 MAGI-1: 大規模な自己回帰ビデオ生成 。
このチュートリアルでは、単一の RTX 4090 カードのリソースを使用し、テキストは英語のみをサポートしています。
2. プロジェクト例
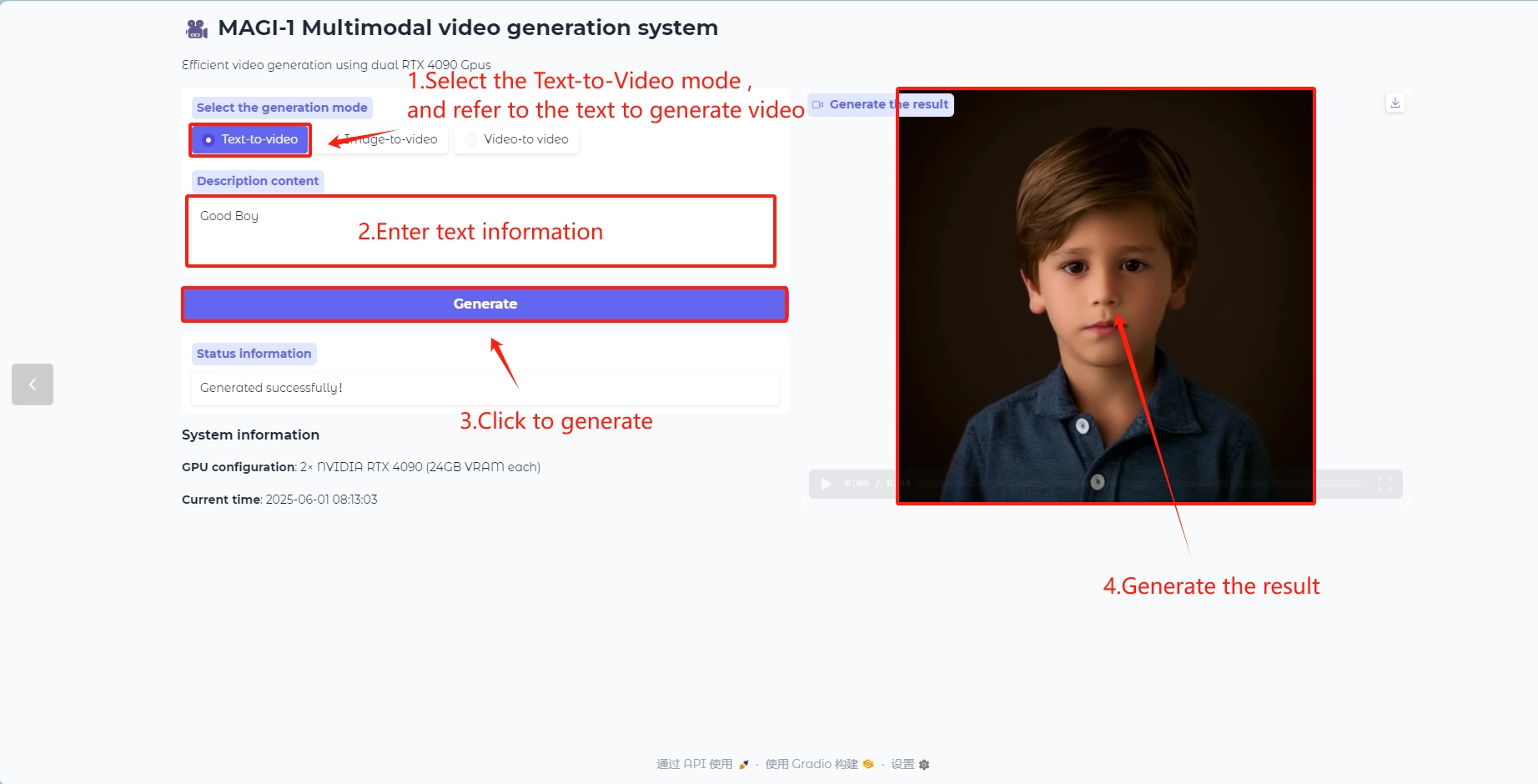
テキストビデオモード
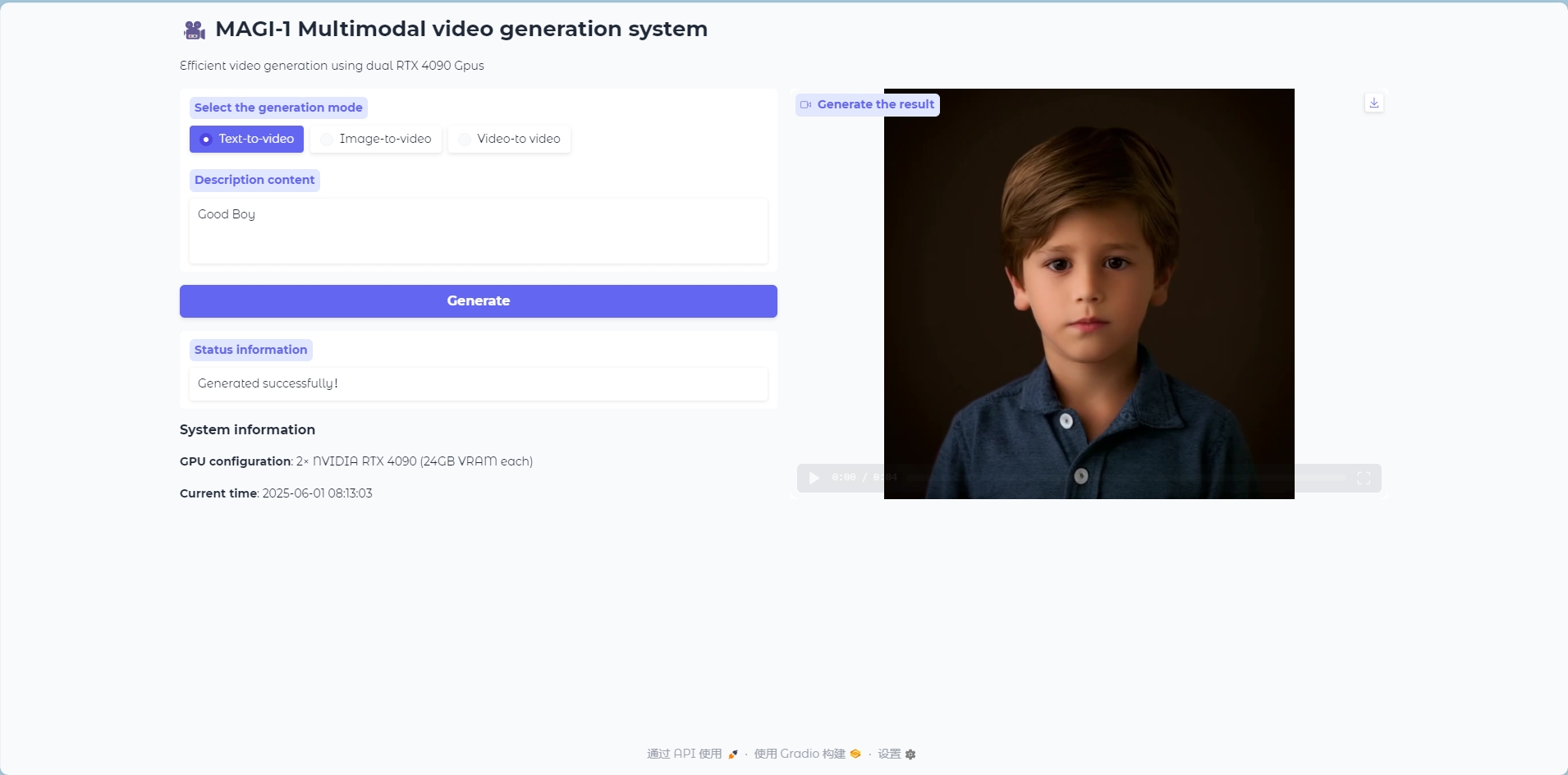
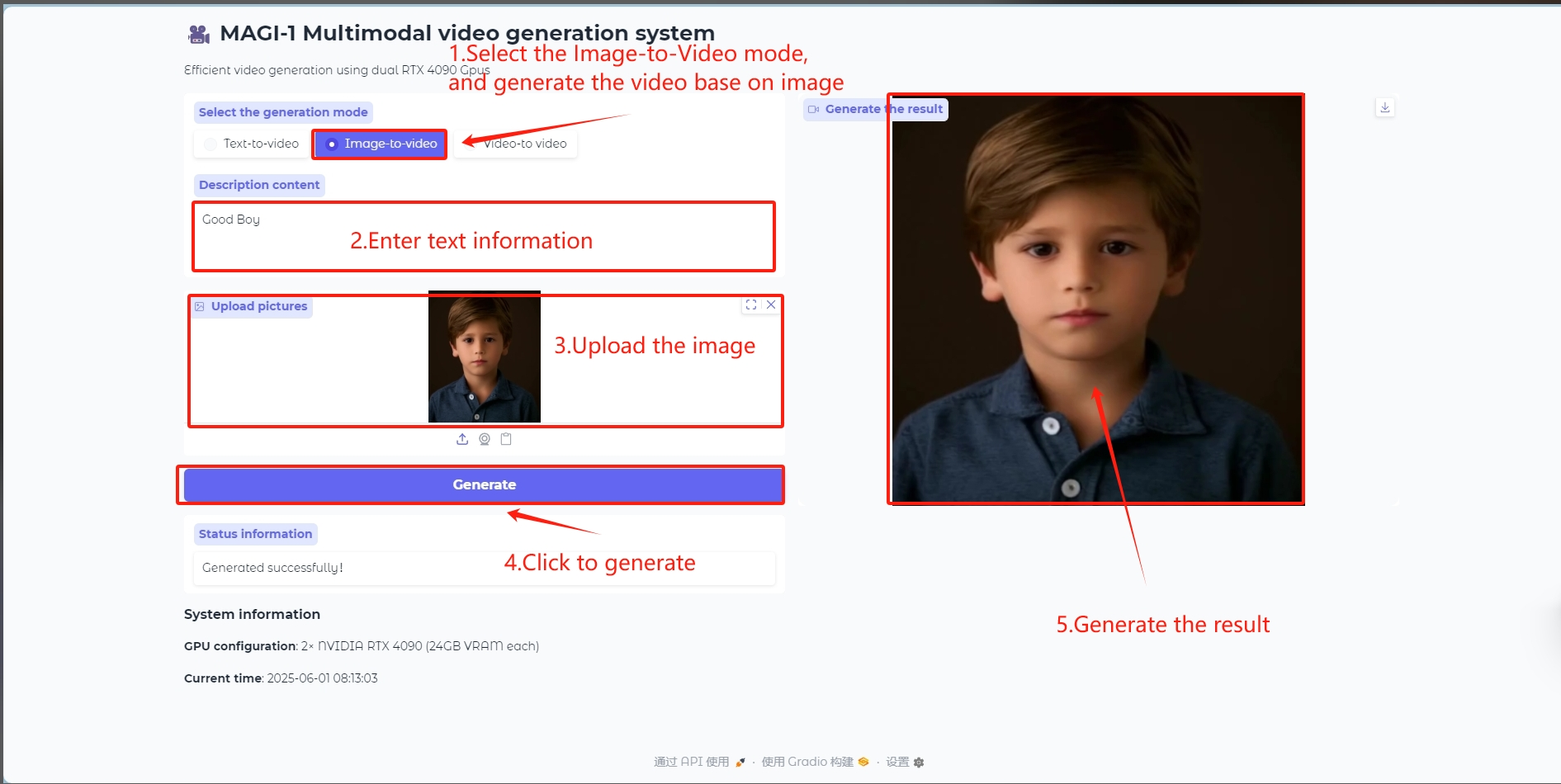
画像からビデオへのモード
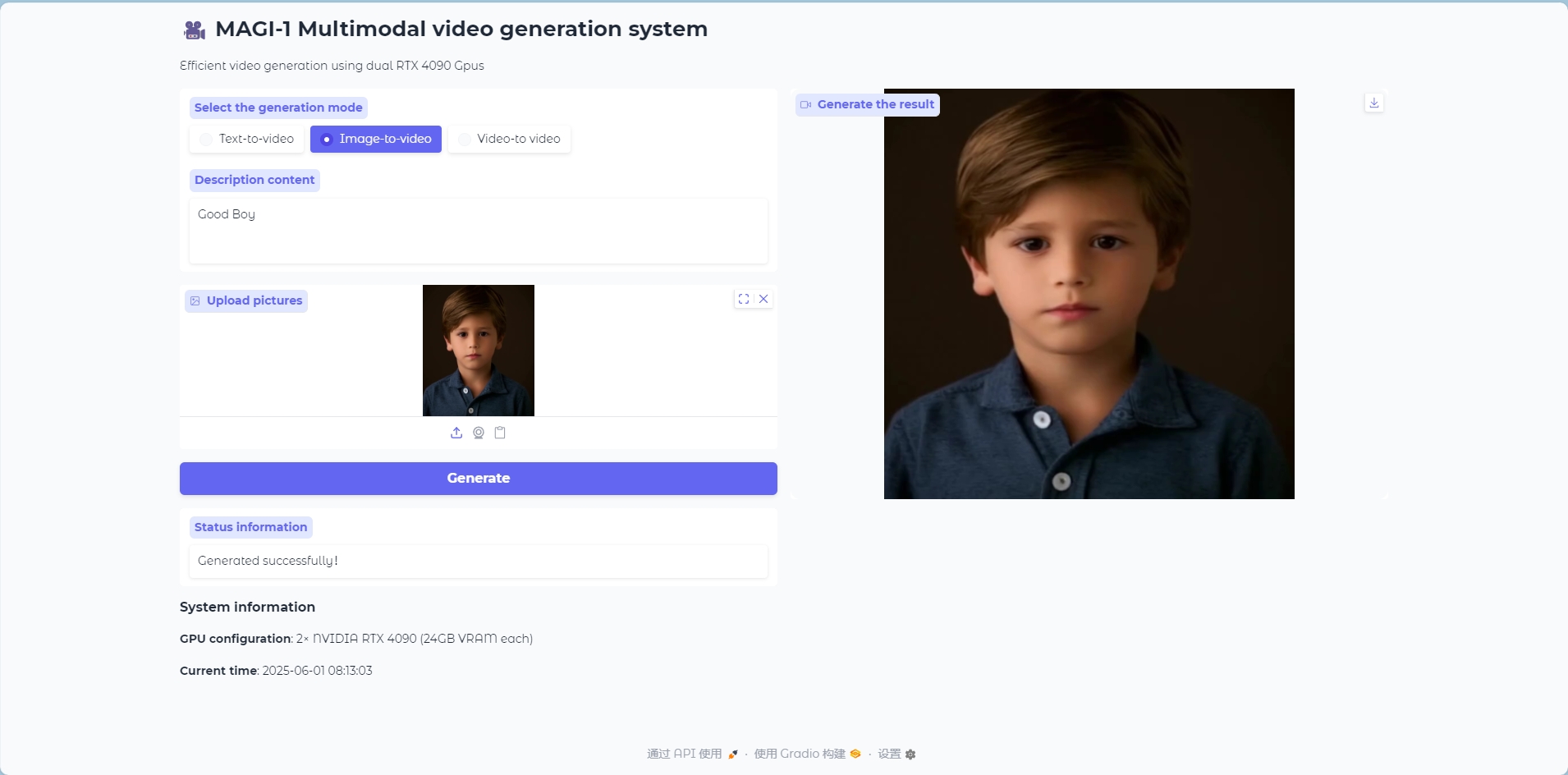
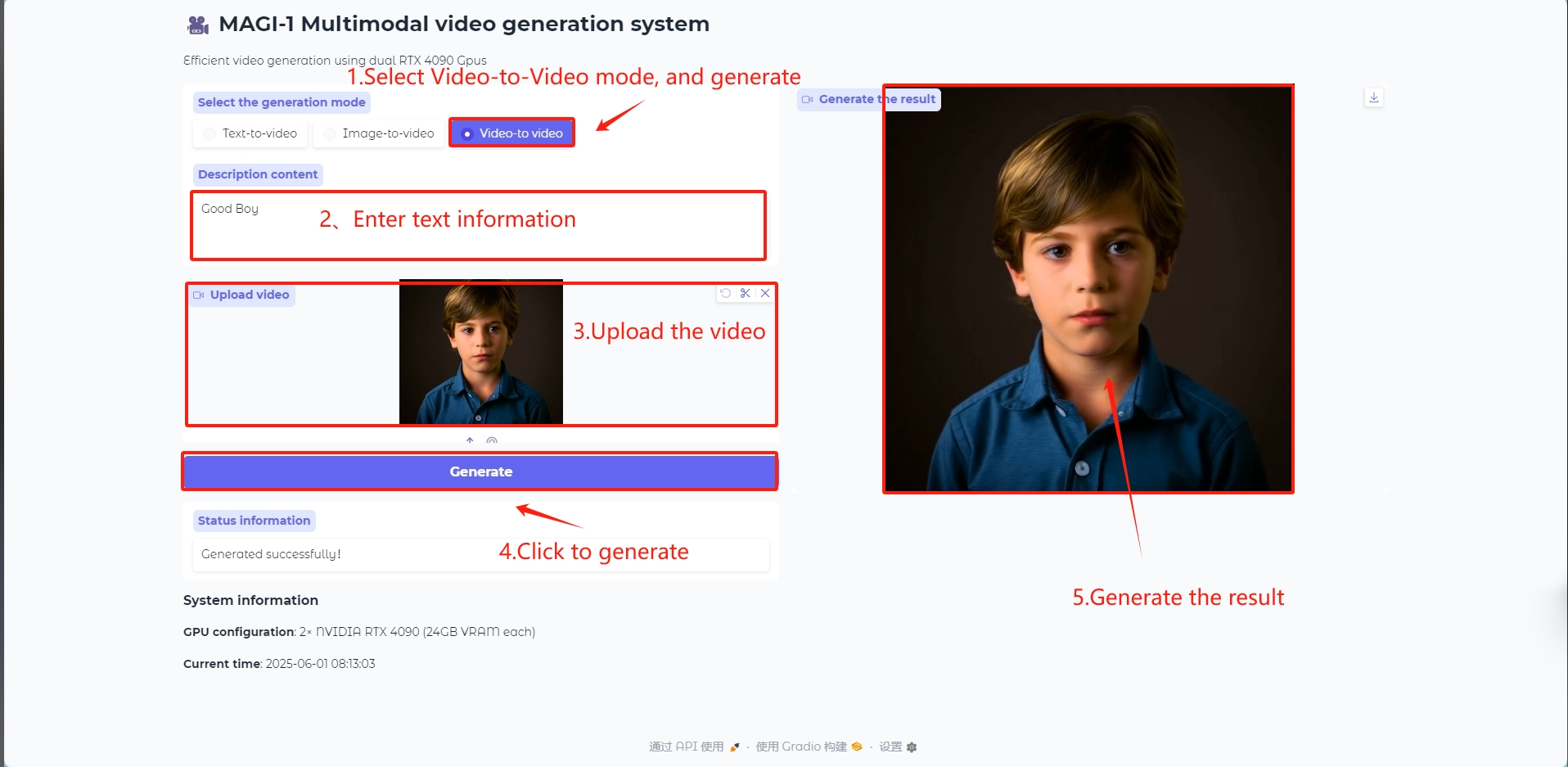
ビデオからビデオへのモード
3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
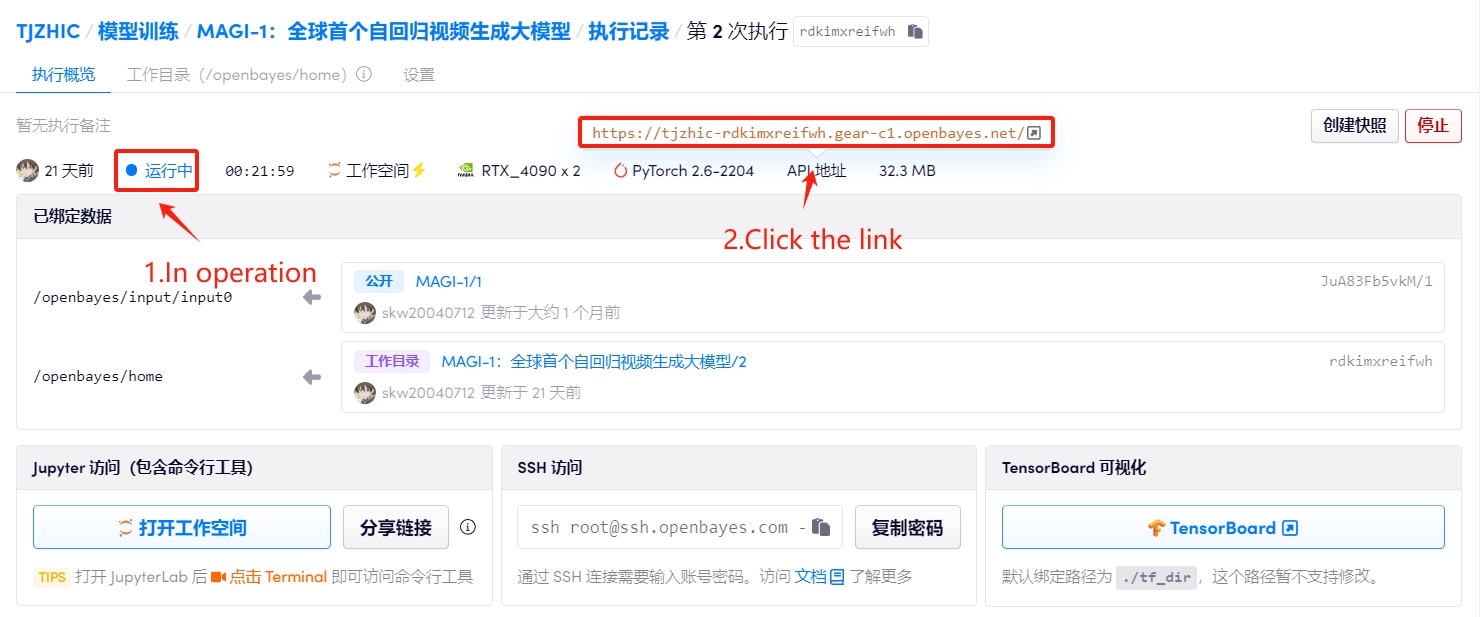
2. ウェブページにアクセスしたら、モデルとの言語対話を開始できます。
「Bad Gateway」と表示される場合は、モデルが初期化中です。モデルのサイズが大きいため、1~2分ほどお待ちいただき、ページを更新してください。モデルが動画を生成するまで約5分かかりますので、しばらくお待ちください。
利用手順
テキストからビデオへのモデル
テキストコンテンツを含むビデオフレームを生成する
画像からビデオへのモデル
ビデオフレームを生成するための参照として画像を入力します
ビデオからビデオへのモデル
ビデオフレームを生成するために参照としてビデオを入力します
/openbayes/home/MAGI-1/example/4.5B パスの 4.5B_distill_quant_config.json ファイルの runtime_config では、num_frames、video_size_h、video_size_w、fps など、生成されたビデオのパラメータを変更できます。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

V. 引用情報
GitHubユーザーに感謝 クヤシュドク このチュートリアルの展開では、プロジェクト参照情報は次のとおりです。
@misc{ai2025magi1autoregressivevideogeneration,
title={MAGI-1: Autoregressive Video Generation at Scale},
author={Sand. ai and Hansi Teng and Hongyu Jia and Lei Sun and Lingzhi Li and Maolin Li and Mingqiu Tang and Shuai Han and Tianning Zhang and W. Q. Zhang and Weifeng Luo and Xiaoyang Kang and Yuchen Sun and Yue Cao and Yunpeng Huang and Yutong Lin and Yuxin Fang and Zewei Tao and Zheng Zhang and Zhongshu Wang and Zixun Liu and Dai Shi and Guoli Su and Hanwen Sun and Hong Pan and Jie Wang and Jiexin Sheng and Min Cui and Min Hu and Ming Yan and Shucheng Yin and Siran Zhang and Tingting Liu and Xianping Yin and Xiaoyu Yang and Xin Song and Xuan Hu and Yankai Zhang and Yuqiao Li},
year={2025},
eprint={2505.13211},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.13211},
}