Command Palette
Search for a command to run...
Sa2VA: 画像と動画の高密度知覚理解に向けて
1. チュートリアルの概要

Sa2VAは、カリフォルニア大学マーセド校、ByteDance Seed、武漢大学、北京大学の研究チームによって共同開発され、2025年1月7日にリリースされました。Sa2VAは、画像と動画の高密度知覚理解のための初の統合モデルです。特定のモダリティとタスクに限定される既存のマルチモーダル大規模言語モデルとは異なり、Sa2VAは代数的セグメンテーションや対話を含む幅広い画像・動画タスクをサポートし、単一命令による微調整は最小限で済みます。関連論文は以下の通りです。 Sa2VA: SAM2とLLaVAを融合し、画像と動画の緻密な理解を実現 。
このチュートリアルでは、単一カード A6000 のリソースを使用します。
2. プロジェクト例



3. 操作手順
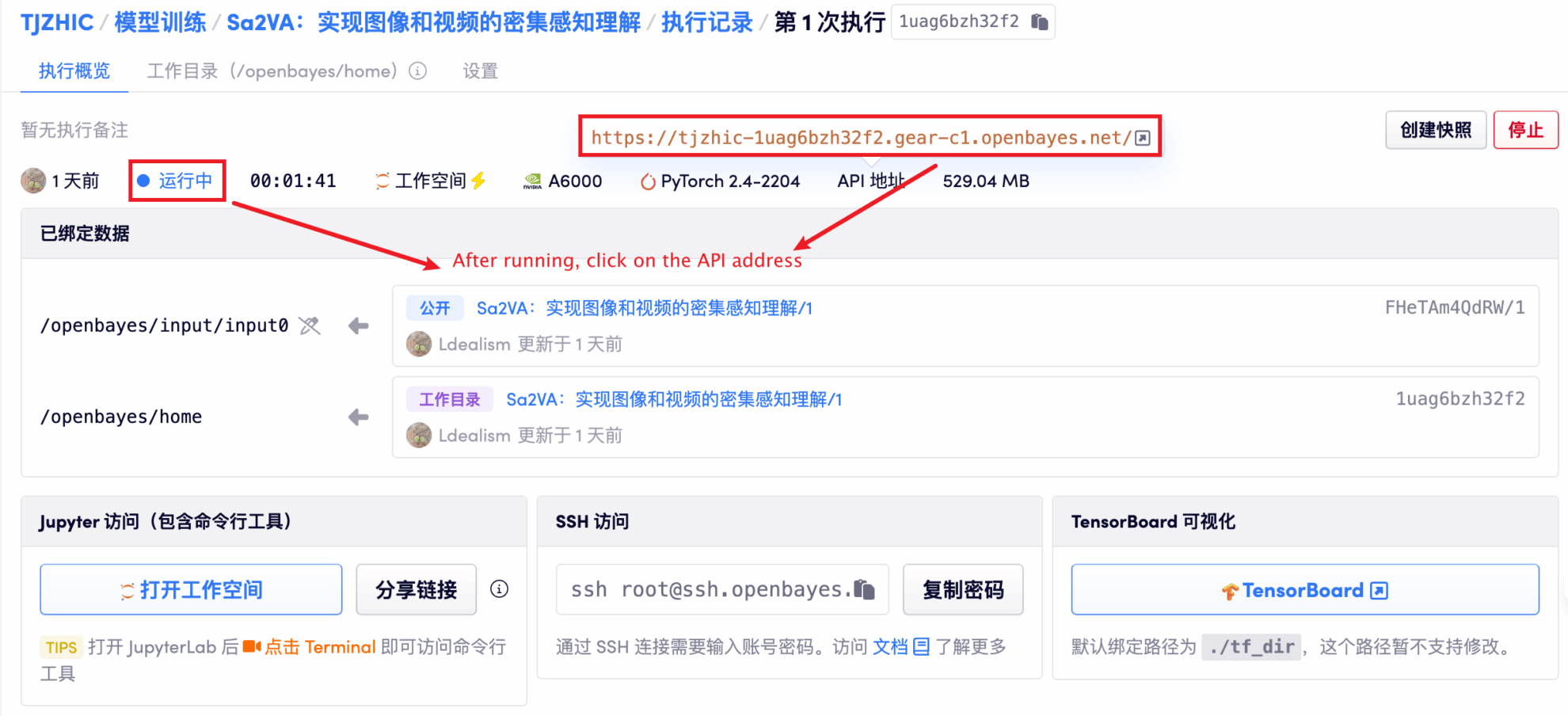
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってページを更新してください。
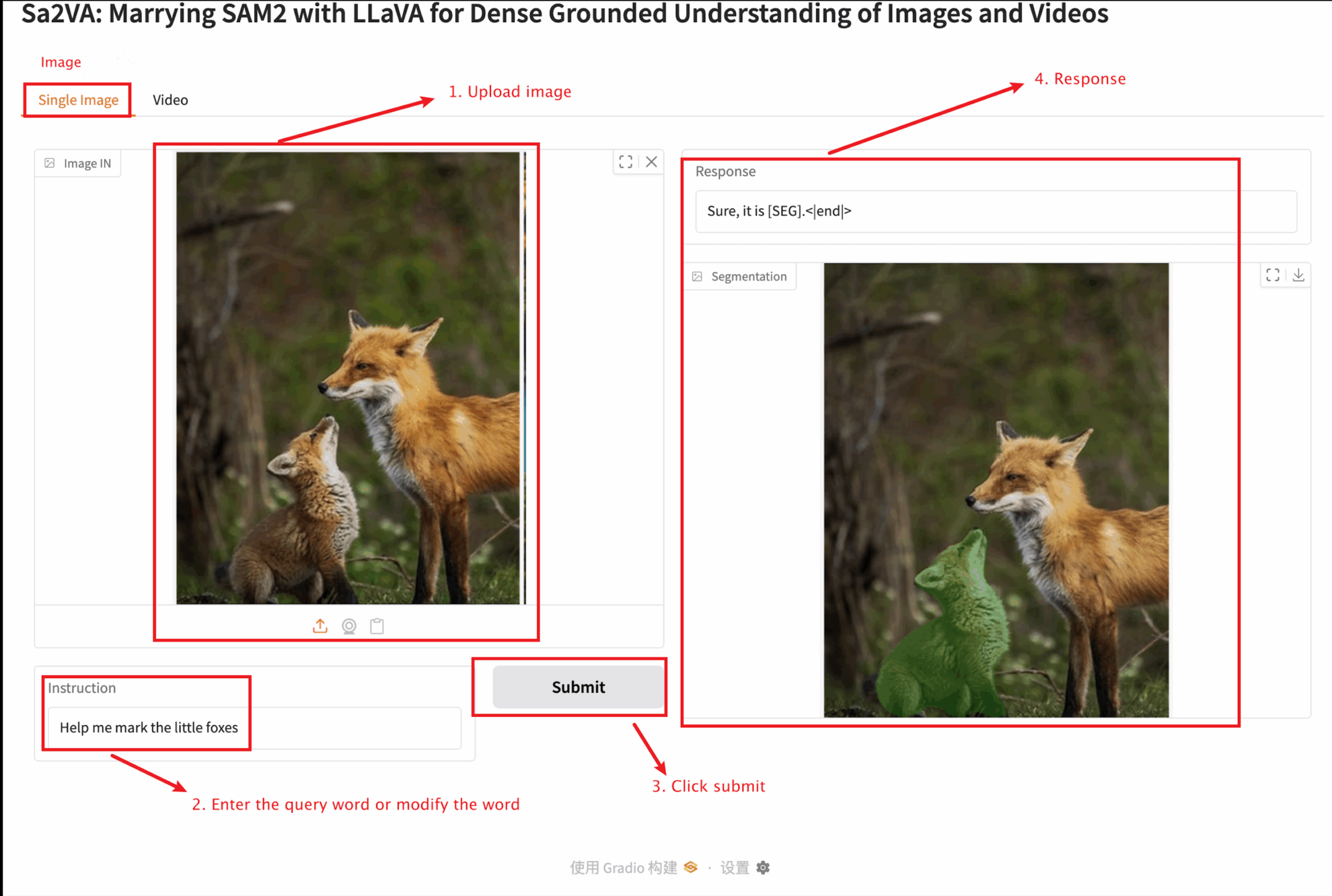
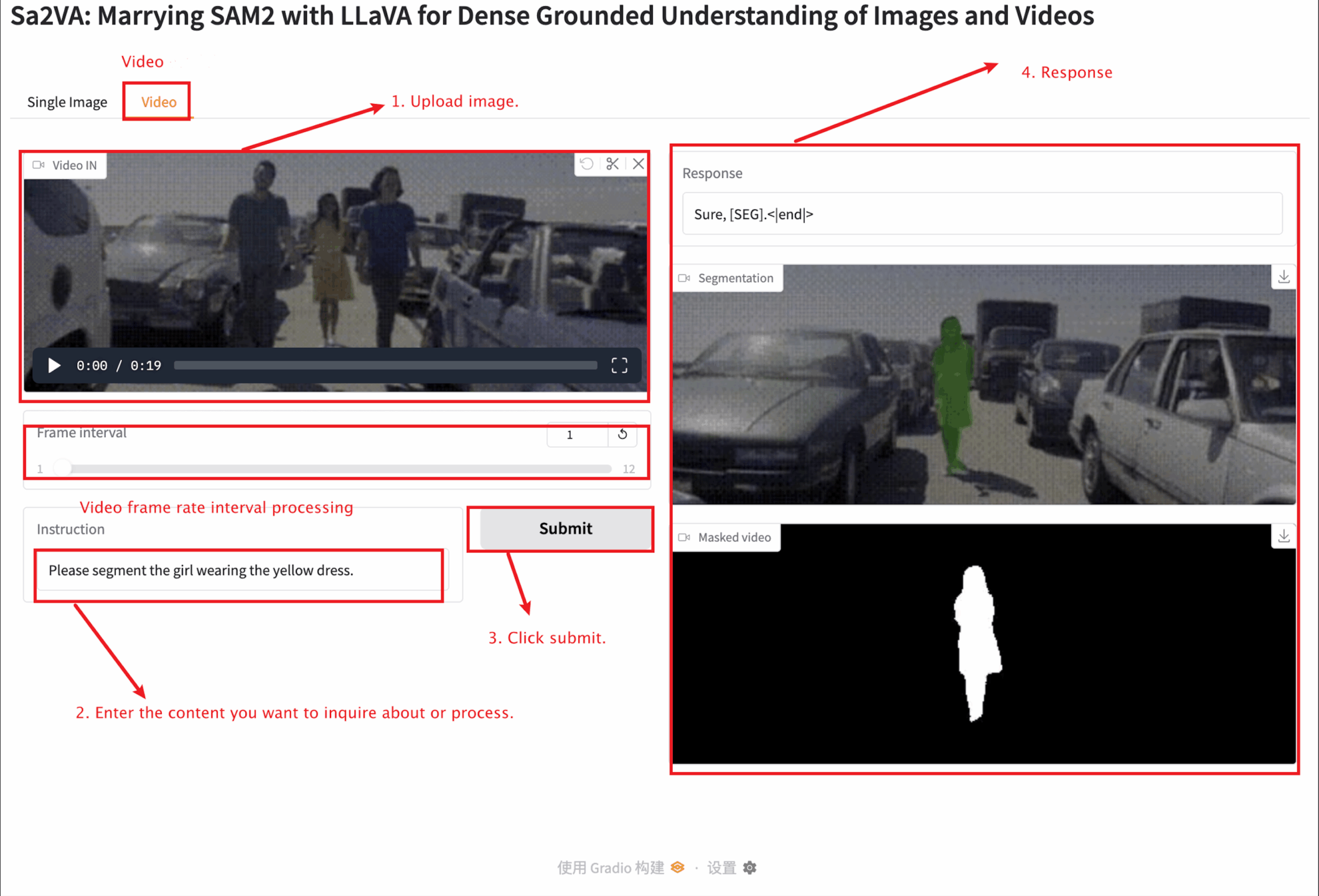
2. ウェブページに入ると、モデルと対話することができます
このチュートリアルでは、単一画像モジュールとビデオ モジュールの 2 つのモジュール テストを提供します。
アップロードする画像のサイズは 10 MB を超えてはならず、アップロードするビデオの長さは 1 分を超えてはならず、ビデオのサイズは 50 MB を超えてはなりません。そうでないと、モデルの実行速度が低下したり、エラーが報告されたりする可能性があります。
重要なパラメータの説明:
単一の画像
ビデオ
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

V. 引用情報
Githubユーザーに感謝 ジャンジュンチャン このチュートリアルの展開では、プロジェクト参照情報は次のとおりです。
@article{pixel_sail,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Zhang, Tao and Li, Xiangtai and Huang, Zilong and Li, Yanwei and Lei, Weixian and Deng, Xueqing and Chen, Shihao and Ji, Shunping and and Feng, Jiashi},
journal={arXiv},
year={2025}
}
@article{sa2va,
title={Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos},
author={Yuan, Haobo and Li, Xiangtai and Zhang, Tao and Huang, Zilong and Xu, Shilin and Ji, Shunping and Tong, Yunhai and Qi, Lu and Feng, Jiashi and Yang, Ming-Hsuan},
journal={arXiv},
year={2025}
}