Command Palette
Search for a command to run...
何でも説明できるモデルデモ
プロジェクト概要

Describe Anything Model (DAM) は、NVIDIA、カリフォルニア大学バークレー校、UCSF のチームが共同で開発し、2025 年にリリースされた革新的な画像および動画記述モデルです。このモデルは、ユーザーが指定した領域(点、ボックス、落書き、マスク)に基づいて詳細な記述を生成できます。動画コンテンツの場合、任意のフレームの領域に注釈を付けるだけで、完全な記述が得られます。関連研究論文も公開されています。 何でも説明:詳細なローカライズ画像と動画のキャプション 。
このチュートリアルでは、単一の RTX 4090 カードのリソースを使用します。
プロジェクト例
ステップの実行
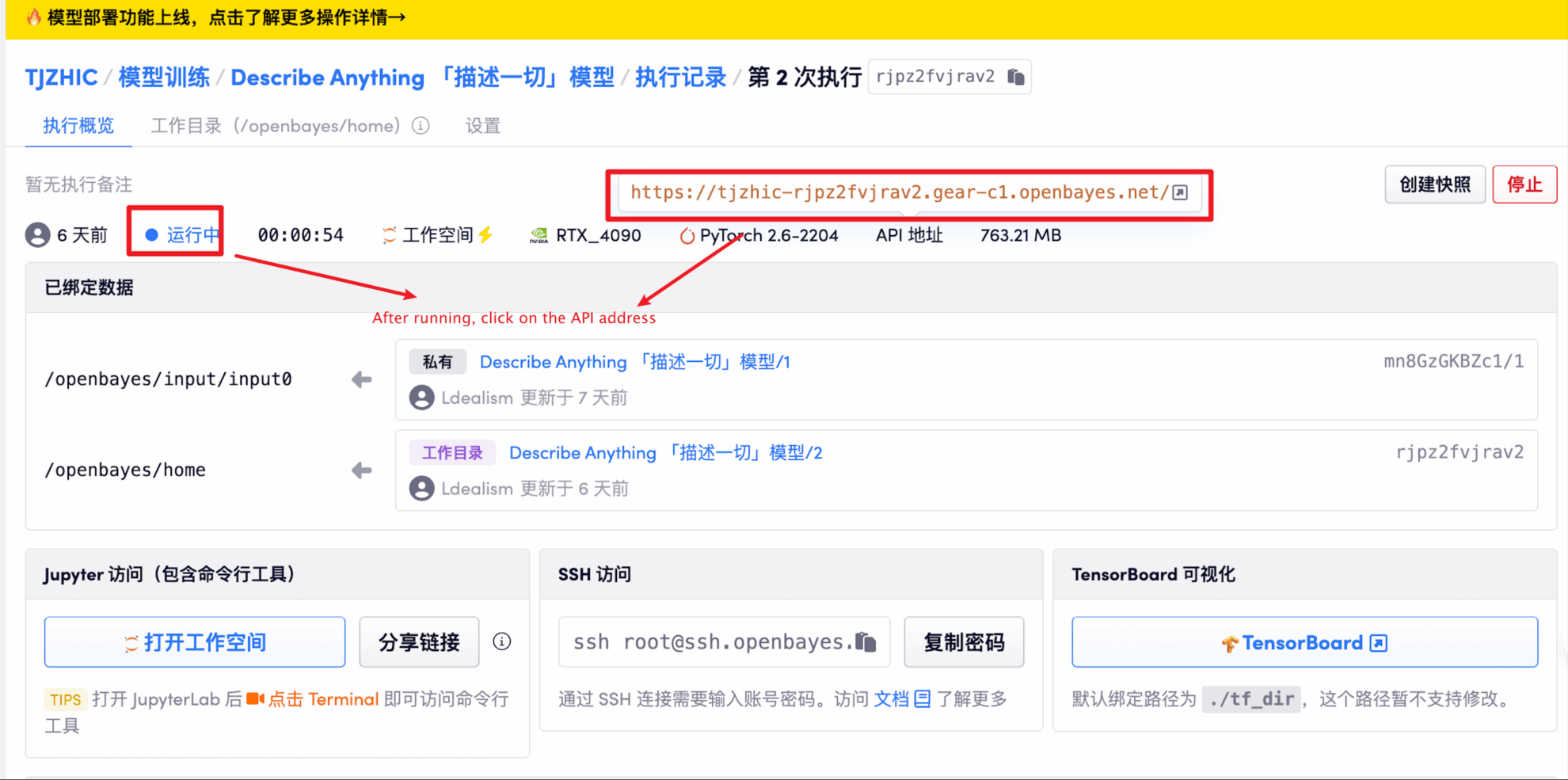
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってページを更新してください。
2. ウェブページに入ると、モデルと対話することができます
画像サイズは5MB以下、動画の長さは20秒以下、動画サイズは5MB以下にしてください。これを超えると、モデルの動作が遅くなったり、エラーが発生したりする可能性があります。説明領域は適切に選択してください。
このチュートリアルでは、画像モード モジュールとビデオ モード モジュールの 2 つのモジュール テストを提供します。
各モジュールの機能は次のとおりです。
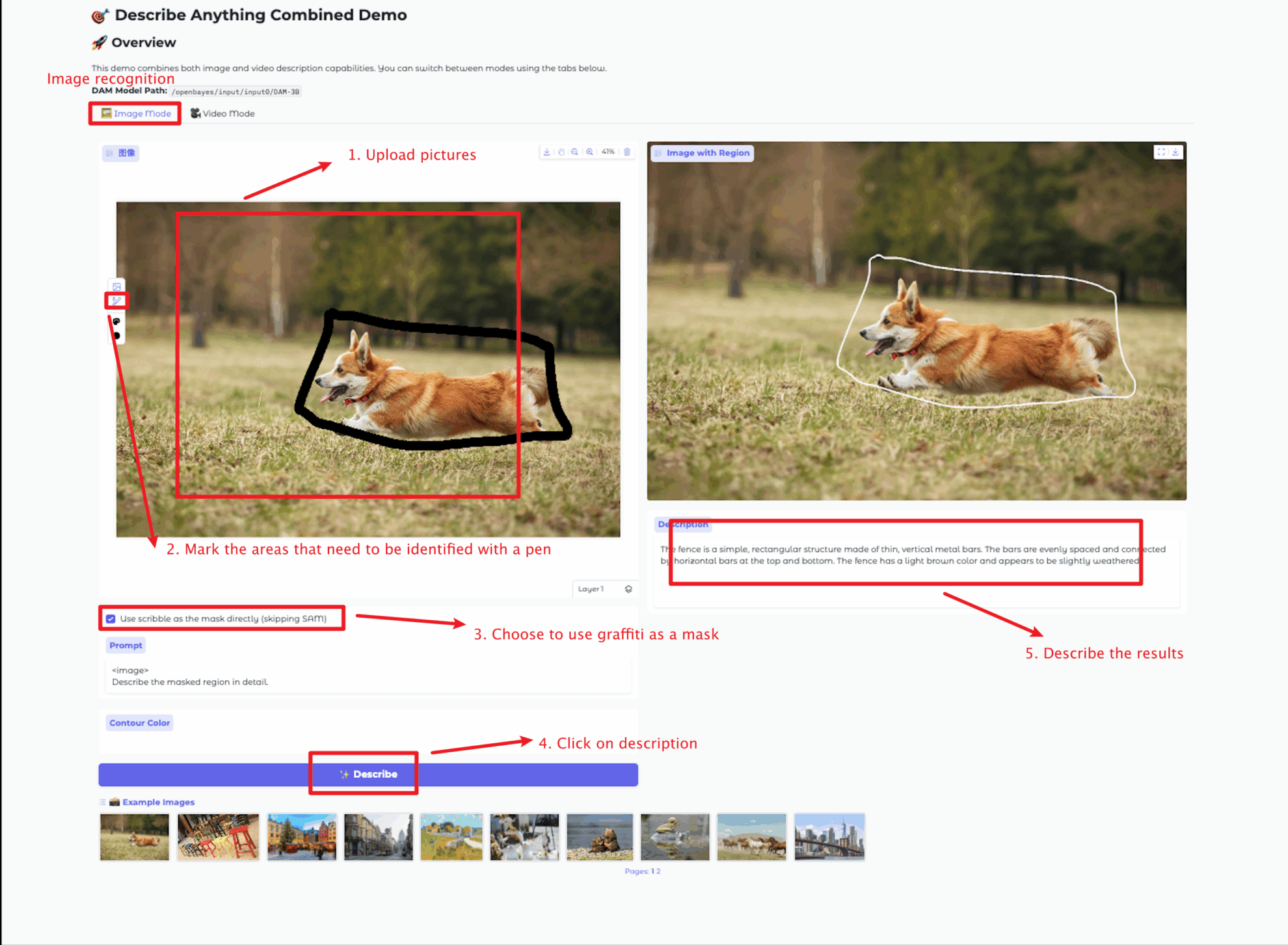
画像モード
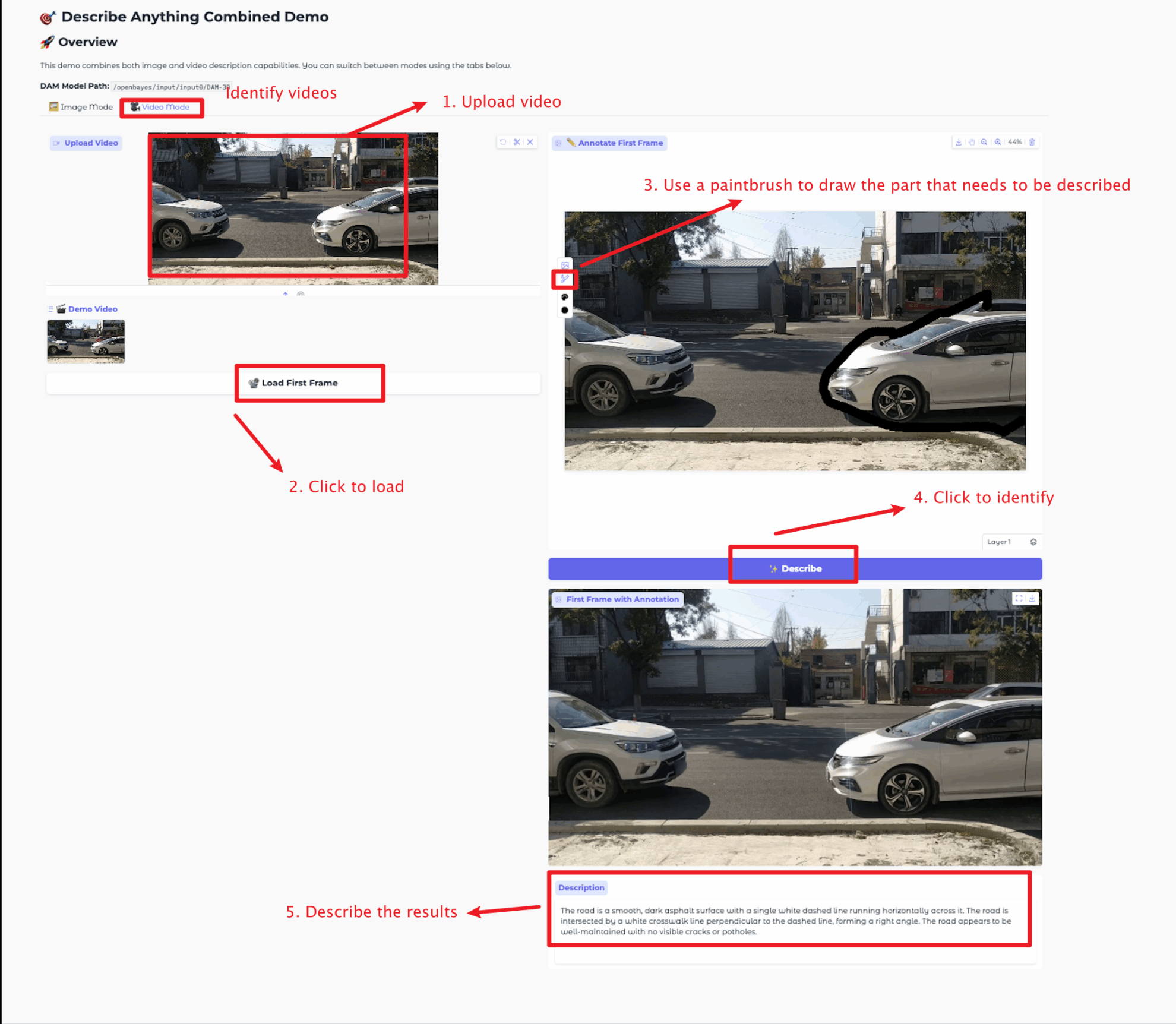
ビデオモード
交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
Githubユーザーに感謝 ジャンジュンチャン このチュートリアルの展開では、プロジェクト参照情報は次のとおりです。
@article{lian2025describe,
title={Describe Anything: Detailed Localized Image and Video Captioning},
author={Long Lian and Yifan Ding and Yunhao Ge and Sifei Liu and Hanzi Mao and Boyi Li and Marco Pavone and Ming-Yu Liu and Trevor Darrell and Adam Yala and Yin Cui},
journal={arXiv preprint arXiv:2504.16072},
year={2025}
} GitHub Stars arXiv