Command Palette
Search for a command to run...
InfiniteYou の高忠実度画像生成デモ
1. チュートリアルの概要

InfiniteYou(略称InfU)は、ByteDanceの知能創造チームが2025年に発表した、Diffusion Transformers(FLUXなど)に基づくアイデンティティ保存画像生成フレームワークです。高度な技術により、画像を生成する際に人物のアイデンティティの一貫性を維持し、アイデンティティの類似性、テキストと画像の整合、生成品質における既存の方法の欠点を解決します。
InfU は、Diffused Transformers (DiTs) を利用するこの分野で最も初期の堅牢なフレームワークの 1 つとして、既存の方法の 3 つの主要な問題 (不十分な ID 類似性、画像とテキストの配置バイアス、生成品質と美的パフォーマンスの低下) に体系的に対処します。その中核となるイノベーションである InfuseNet は、残余接続を通じて DiT ベースのモデルに ID 機能を注入し、生成機能を維持しながら ID の忠実度を大幅に向上させます。事前トレーニングと、合成単一人物マルチサンプル (SPMS) データを使用した教師あり微調整 (SFT) を含む多段階トレーニング戦略を採用することで、画像とテキストの位置合わせをさらに最適化し、生成品質を向上させ、顔の重複効果を効果的に軽減します。広範囲にわたる実験により、InfU はあらゆる面で既存のベースライン メソッドを上回り、最先端のパフォーマンスを実現することが示されています。プラグアンドプレイ設計により、さまざまな既存の方法との互換性が確保され、学術コミュニティに重要な技術的貢献をもたらします。
このチュートリアルでは、InfiniteYou-FLUX v1.0 をデモとして使用し、コンピューティング パワー リソースは A6000 です。
チュートリアルでは 2 つのモデル バージョンが提供されます。
| InfiniteYouバージョン | モデルバージョン | トレーニングに使用されるベースモデル | 特徴 |
|---|---|---|---|
| インフィニットユー-FLUX v1.0 | 翻訳: | FLUX.1-開発 | 教師あり微調整(SFT)後の第2段階モデルは、画像とテキストの配置と美的パフォーマンスが向上しています。 |
| インフィニットユー-FLUX v1.0 | シムステージ1 | FLUX.1-開発 | 教師あり微調整前の第1段階モデルは、より高いアイデンティティ特徴類似性を提供する。 |
エフェクト例

2. 操作手順
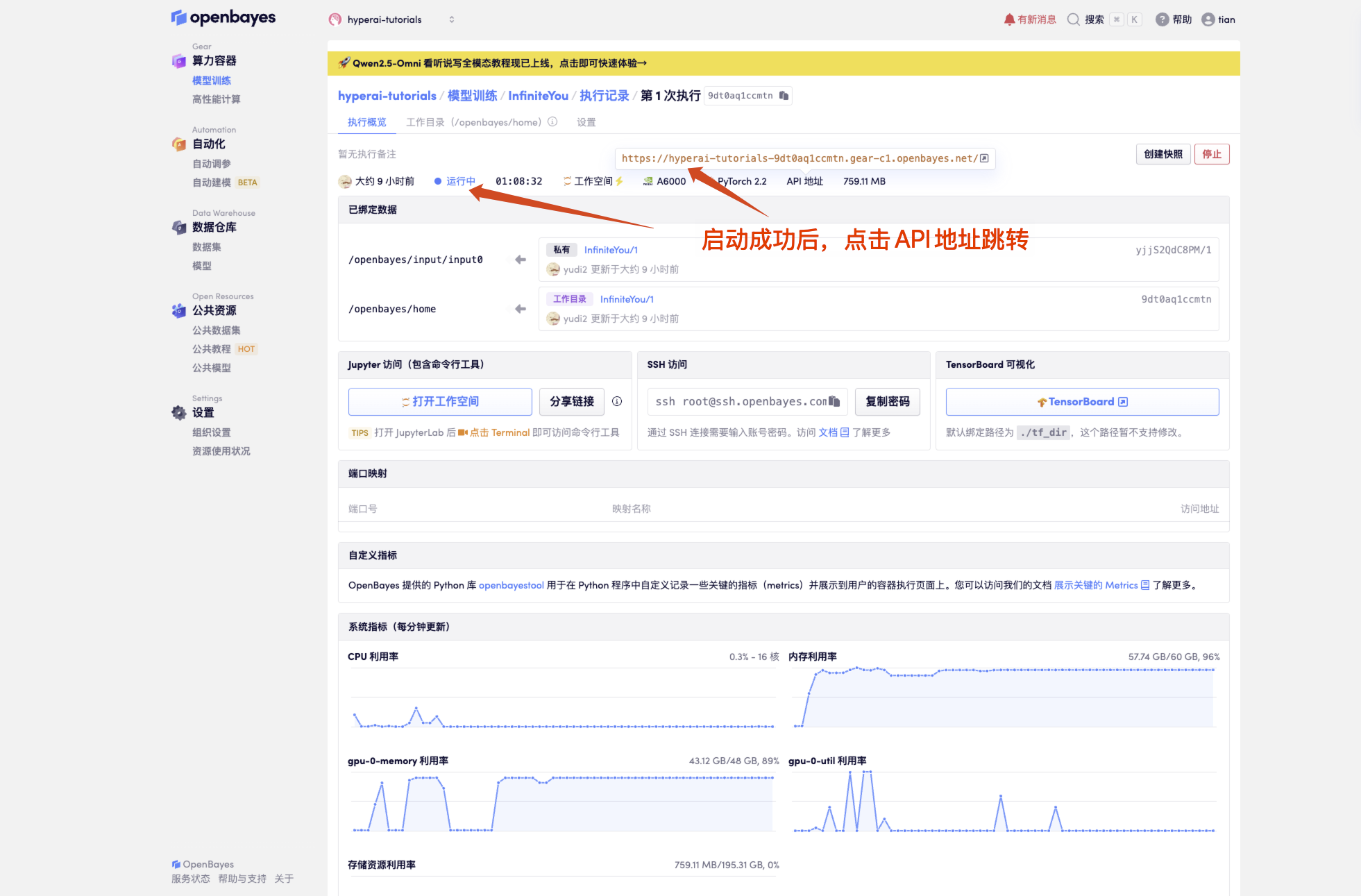
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「モデル」が表示されない場合は、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってからページを更新してください。
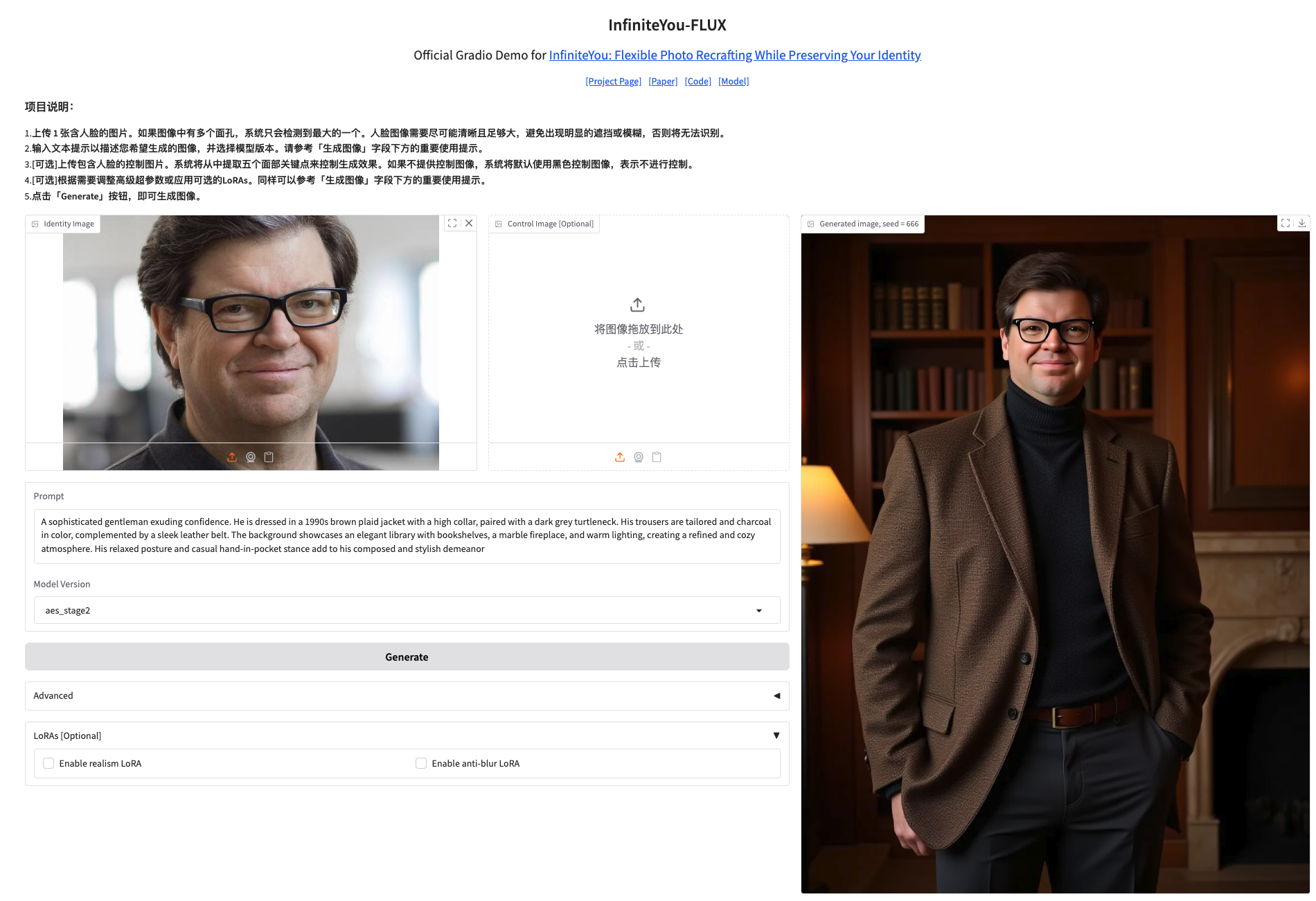
2. ウェブサイトにアクセスしたら、使用を開始できます。
❗️重要な使用上のヒント:
- モデルバージョン: デフォルトで使用する
aes_stage2画像とテキストの配置と美的効果を向上させるため。 IDの類似性を高めるには、sim_stage1。 - 有用なハイパーパラメータ: 通常、それ以上の調整は必要ありません。必要に応じて、少し大きめのサイズをお試しください
--infusenet_guidance_start(例えば0.1)(右sim_stage1は特に効果的です。それでも効果が満足できない場合は、少し小さめのサイズを試してください。--infusenet_conditioning_scale(例えば0.9)。 - オプションのLoRA:
realism(現実的)そしてanti-blur(ぼかし防止)。対応するボックスをチェックして有効にします。これらはオプションの機能であり、この論文では使用されていません。 - 性別に関するヒント: 生成された性別が予想と異なる場合は、テキストプロンプトに「男性」、「女性」などの具体的な単語を追加してください。このプロジェクトでは、包括的かつ敬意のある言語の使用を奨励しています。
利用手順

交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。
