HyperAI
Command Palette
Search for a command to run...
Qwen2.5-Omniは、読む、聞く、話す、書くというすべてのモードを開きます
1. チュートリアルの概要
Qwen2.5-Omniは、2025年3月27日にAlibaba Tongyi Qianwenチームによってリリースされた最新のエンドツーエンドのマルチモーダルフラッグシップモデルです。包括的なマルチモーダル認識のために設計されており、テキスト、画像、オーディオ、ビデオなどのさまざまな入力をシームレスに処理するとともに、ストリーミングテキスト生成と自然な音声合成出力をサポートします。
主な特徴
- オールラウンドな革新的建築: テキストと自然な音声応答をストリーミング方式で生成しながら、テキスト/画像/音声/ビデオのクロスモーダル理解をサポートするように設計されたエンドツーエンドのマルチモーダル モデルである、新しい Thinker-Talker アーキテクチャを採用しています。研究チームは、時間軸の調整によりビデオとオーディオの入力の正確な同期を実現する、TMRoPE(Time-aligned Multimodal RoPE)と呼ばれる新しい位置コーディング技術を提案しました。
- リアルタイムのオーディオとビデオのインタラクション: このアーキテクチャは、チャンク入力と即時出力をサポートし、完全なリアルタイムのインタラクションをサポートするように設計されています。
- 自然で流暢な音声生成: 音声生成の自然さと安定性の点で、既存の多くのストリーミングおよび非ストリーミングの代替手段を上回ります。
- オムニモーダルパフォーマンスの優位性: 同様のサイズの単峰性モデルと比較した場合、優れたパフォーマンスを発揮します。 Qwen2.5-Omni は、オーディオ機能において同サイズの Qwen2-Audio を上回り、Qwen2.5-VL-7B と同等です。
- 優れたエンドツーエンドの音声コマンド追従機能Qwen2.5-Omni は、エンドツーエンドの音声コマンド追跡においてテキスト入力処理と同等の結果を示し、MMLU 一般知識理解や GSM8K 数学的推論などのベンチマークで優れています。
このチュートリアルでは、デモンストレーションとして Qwen2.5-Omni を使用し、コンピューティング リソースは A6000 です。
サポート機能:
- オンラインマルチモーダルダイアログ
- オフラインマルチモーダル会話
2. 操作手順
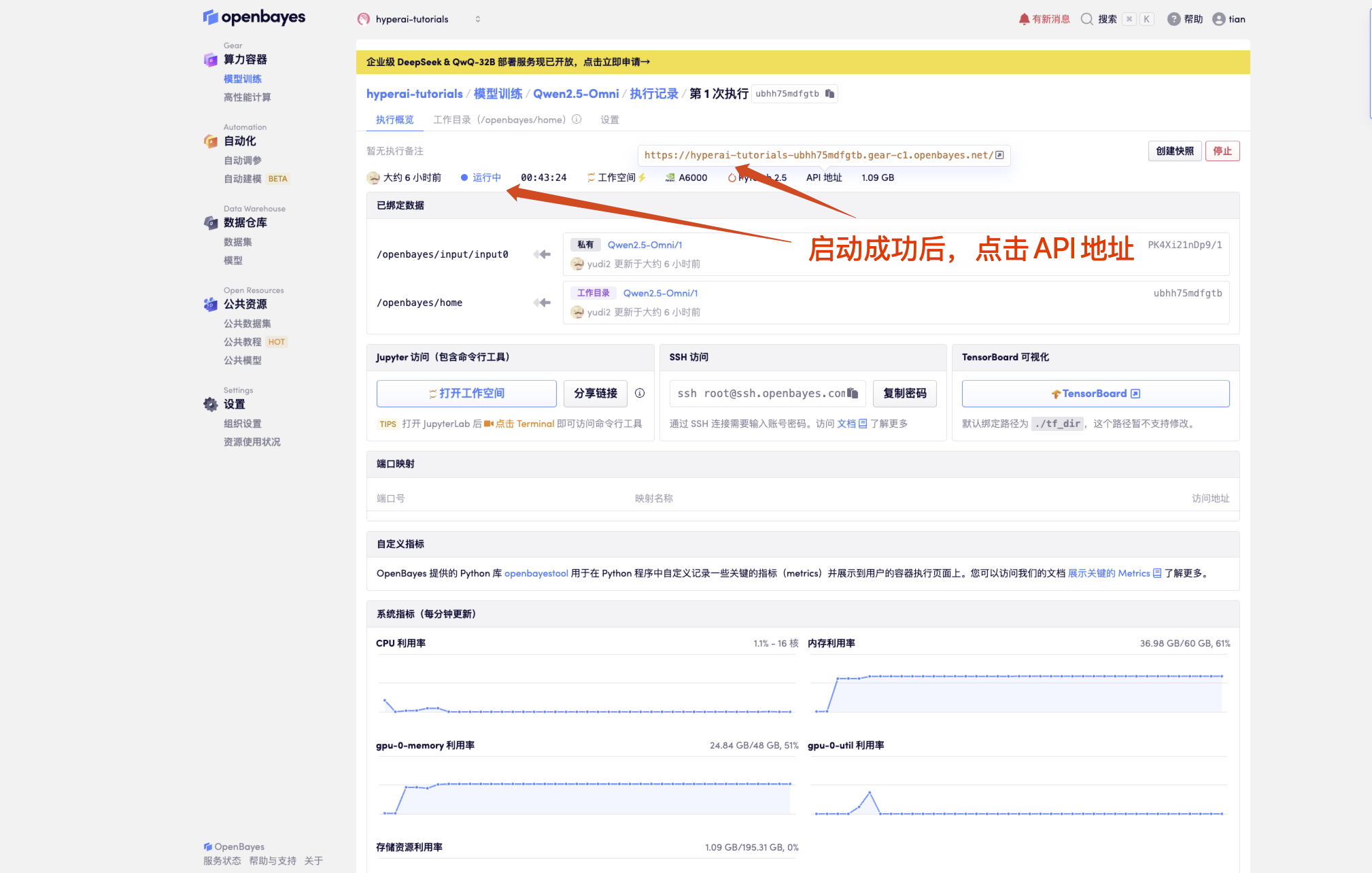
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
「モデル」が表示されない場合は、モデルが初期化中であることを意味します。モデルが大きいため、1〜2分ほど待ってからページを更新してください。
2. Web ページに入ると、モデルと会話を開始できます。
入力ボックスがオレンジ色の場合は、モデルが応答していることを意味します。
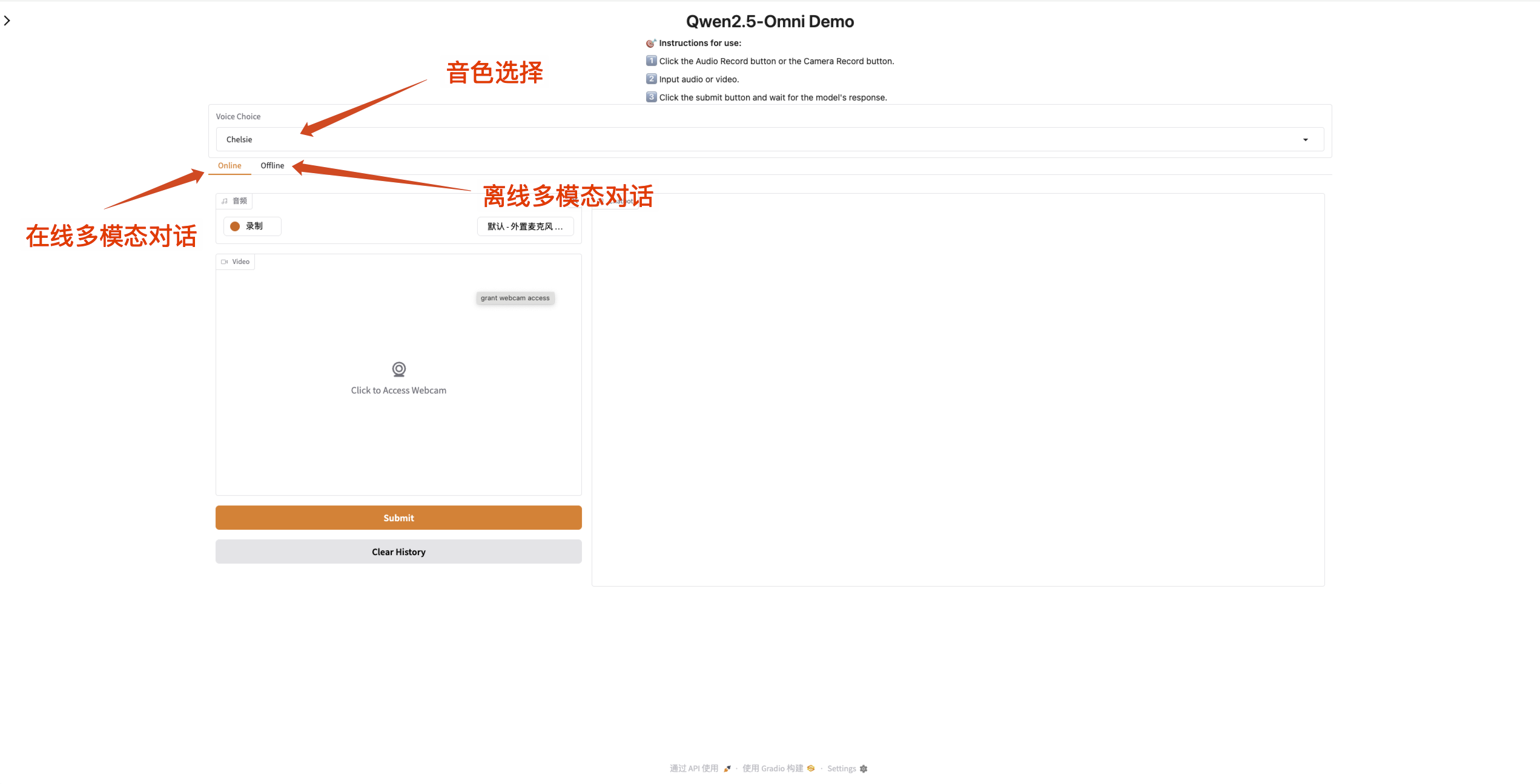
Qwen2.5-Omni は出力オーディオのサウンドの変更をサポートしています。 「Qwen/Qwen2.5-Omni-7B」チェックポイントは、次の 2 つのサウンド タイプをサポートしています。
| トーンタイプ | 性別 | 説明する |
|---|---|---|
| チェルシー | 女性 | 甘く、優しく、明るく、柔らかい |
| イーサン | 男 | 太陽の光、活力、明るさ、親近感 |
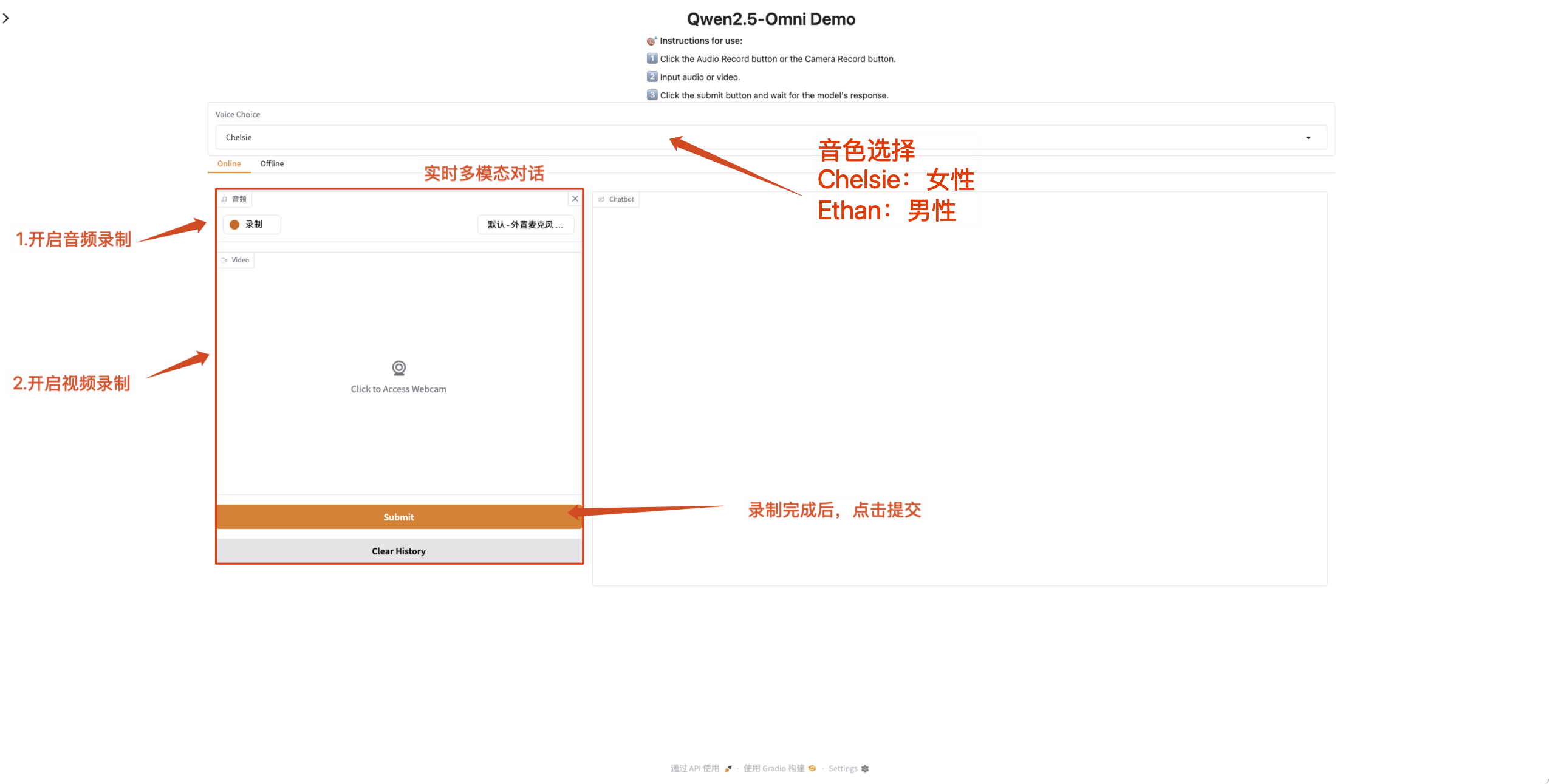
- オンラインマルチモーダルダイアログ
録音が完了した後、Qwen2.5-Omni とリアルタイムで会話できるように、Web ページでマイクとカメラのアクセス許可を有効にします。
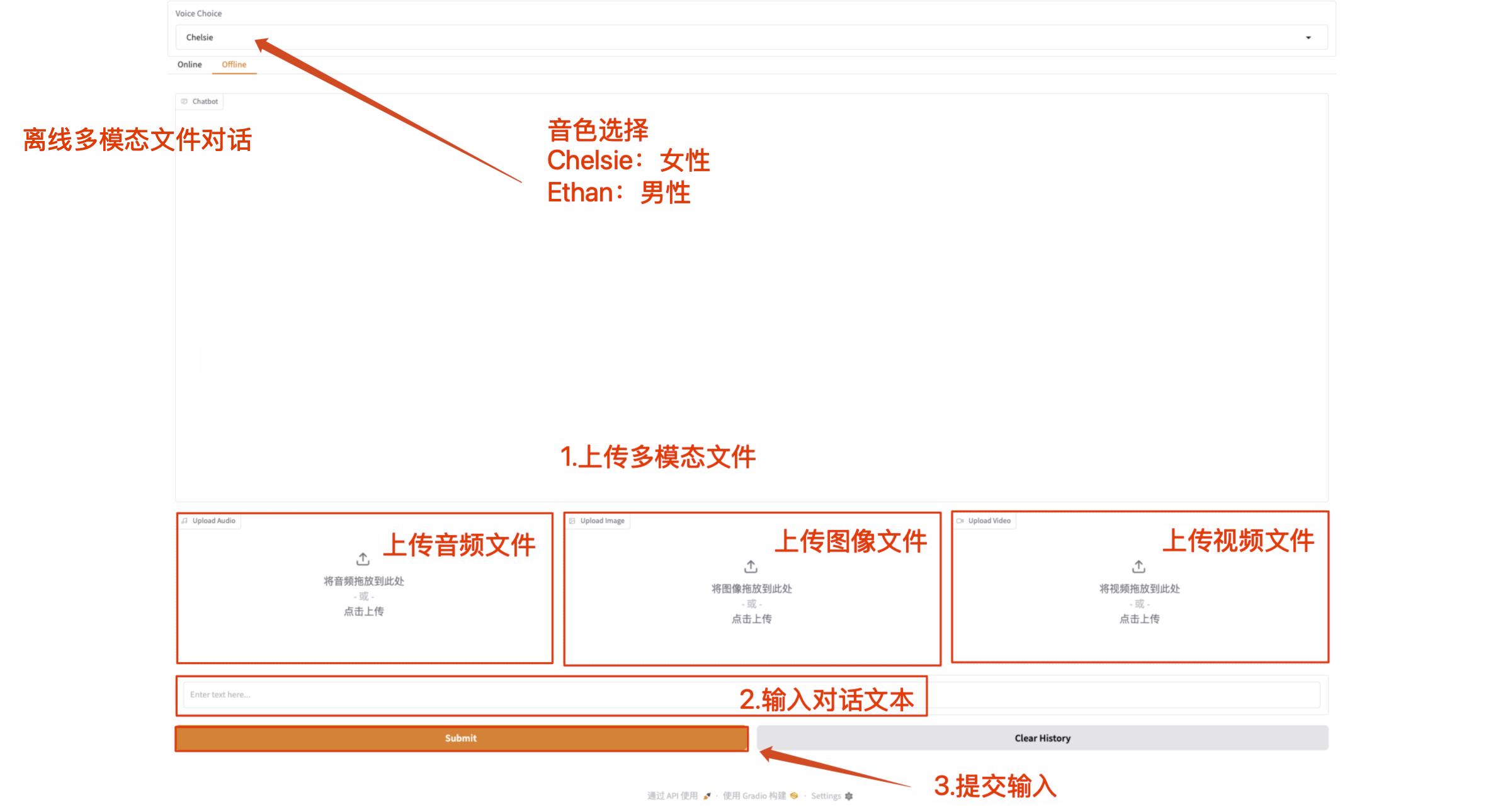
- オフラインマルチモーダル会話
マルチモーダルファイルを直接アップロードし、テキストコンテンツで Qwen2.5-Omni と通信します。
注意: ビデオ ファイルには音声が含まれている必要があります。音が出ない場合はエラーメッセージが表示されます。
交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。 
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。