HyperAI
Command Palette
Search for a command to run...
vLLMを使用してGemma-3-27B-ITを展開する
1. チュートリアルの概要
Gemma-3-27B-IT は、2025 年に Google がオープンソース化した第 3 世代 Gemma 大規模モデルであり、270 億のパラメータを持つ命令最適化バージョンです。
Gemma シリーズは、Google がオープンソース化した大規模なモデル シリーズであり、Gemini モデルと同じ研究とテクノロジーに基づいて構築されています。 Gemma 3 は、テキストと画像の入力を処理してテキスト出力を生成できる大規模なマルチモーダル モデルであり、事前トレーニング済みと命令調整済みの両方のバリアントでオープン ウェイトが利用可能です。このモデルには 128K のコンテキスト ウィンドウがあり、140 を超える言語をサポートし、以前のバージョンよりも多くのモデル サイズを提供します。 Gemma 3 モデルは、質問への回答、要約、推論など、さまざまなテキスト生成および画像理解タスクに適用できます。比較的小型なので、ラップトップ、デスクトップ、クラウド インフラストラクチャなど、リソースが限られた環境に導入できます。
このチュートリアルでは、デモとして gemma-3-27b-it を使用し、コンピューティング パワー リソースとして単一のカード A6000 を使用します。
2. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります。モデルが大きいため、WebUI インターフェイスが表示されるまでに約 3 分かかります。それ以外の場合は、「Bad Gateway」と表示されます。
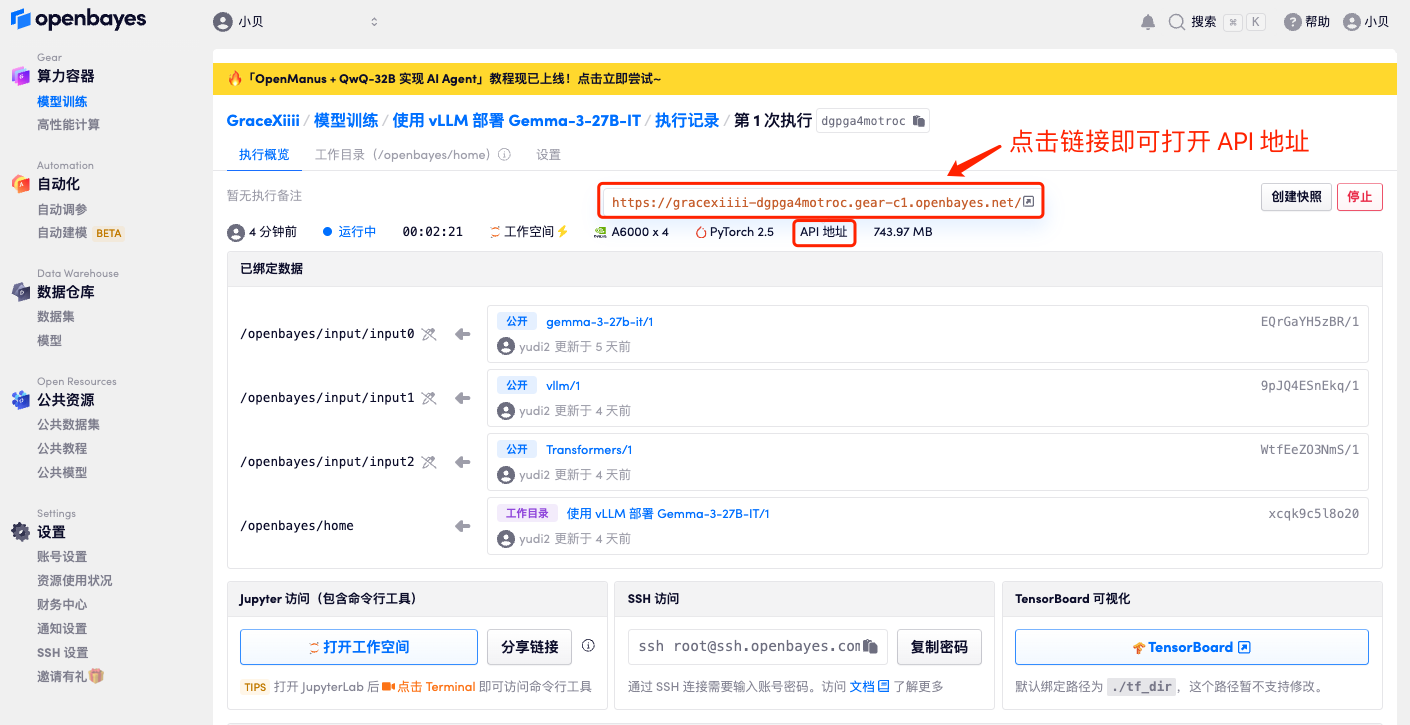
2. ウェブページに入った後、モデル推論を実行できます
- テキスト会話: 写真をアップロードせずにテキストを直接入力してテキスト会話をします
- 画像理解: テキストと画像を入力して対応するモデル理解を生成する
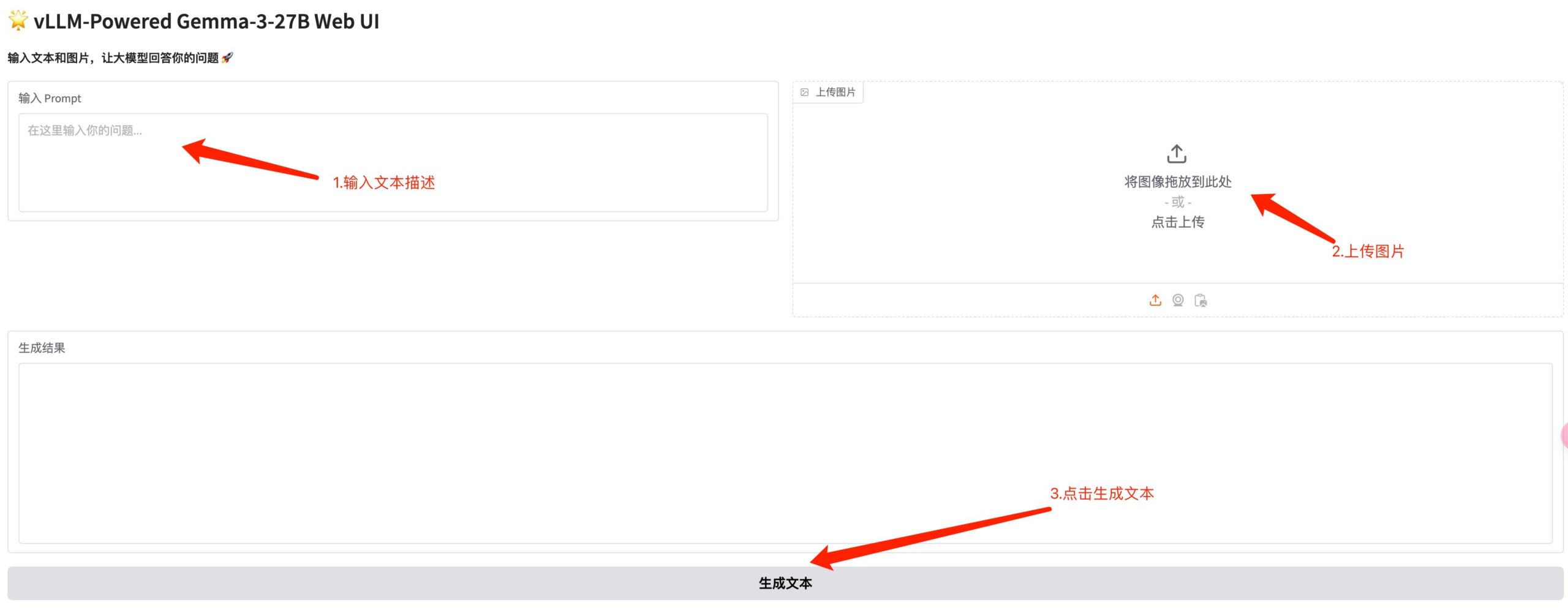
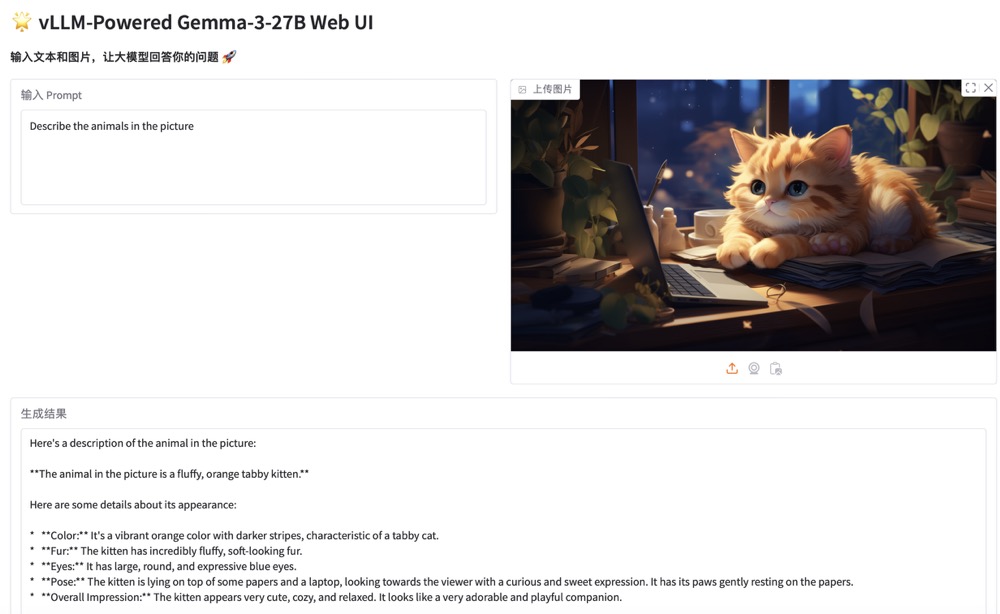
* 例を実行する
交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。