HyperAI
Command Palette
Search for a command to run...
vLLMを使用してQwQ-32Bをデプロイする
日付
1年前
サイズ
143.31 MB

1. チュートリアルの概要
QwQ は Qwen シリーズの推論モデルです。従来の命令チューニング モデルと比較して、QwQ は思考および推論機能を備えており、下流のタスク、特に難しい問題で大幅なパフォーマンス向上を実現できます。 QwQ-32Bは、DeepSeek-R1やo1-miniなどの最先端の推論モデルと競合できる性能を実現できる中規模推論モデルです。
このチュートリアルでは、デモンストレーションとして QwQ-32B を使用し、コンピューティング リソースは A6000*2 です。
2. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります (「モデル」が表示されない場合は、モデルが初期化中であることを意味します。モデルが大きいため、1 ~ 2 分ほど待ってからページを更新してください)。
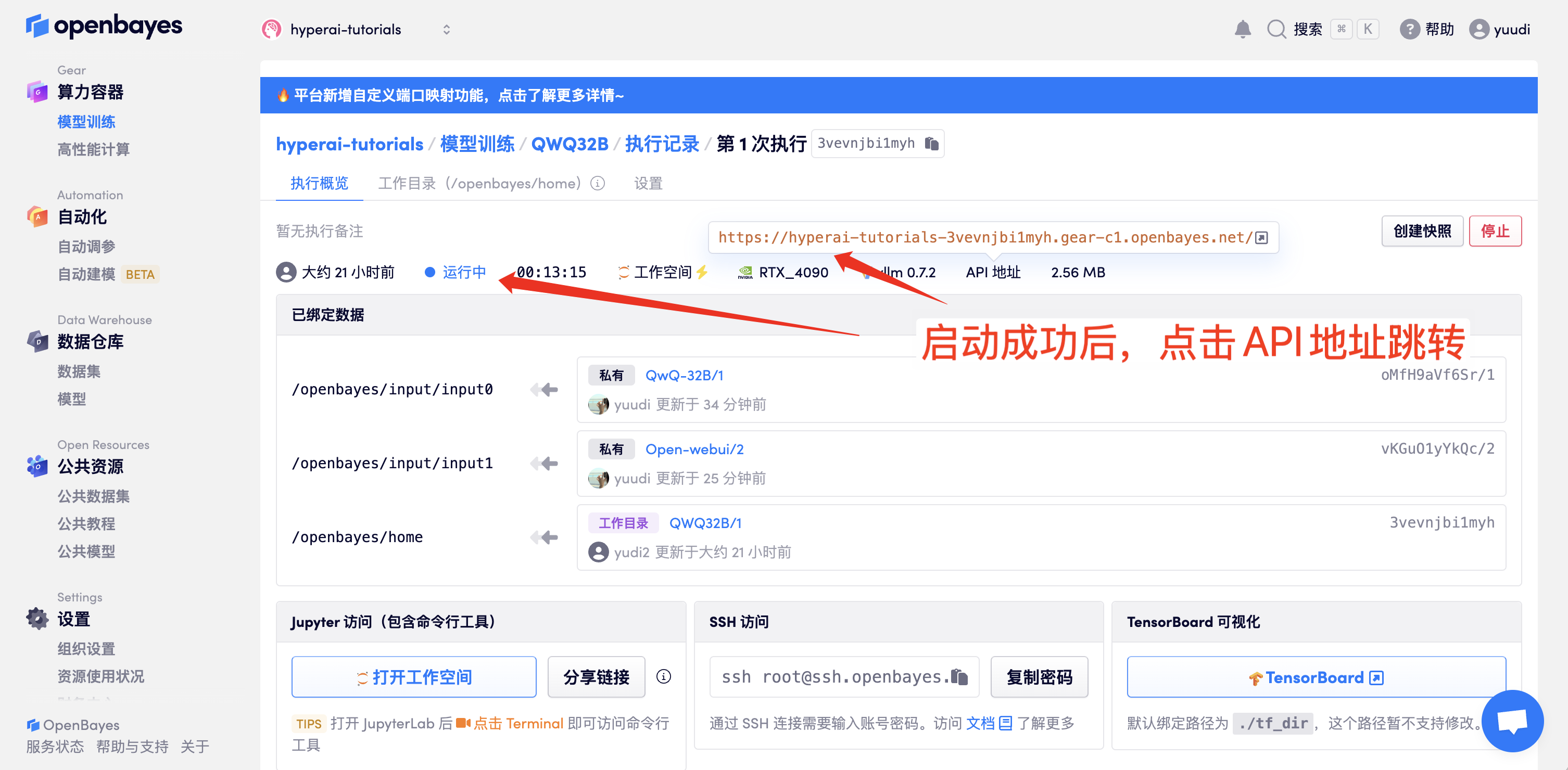
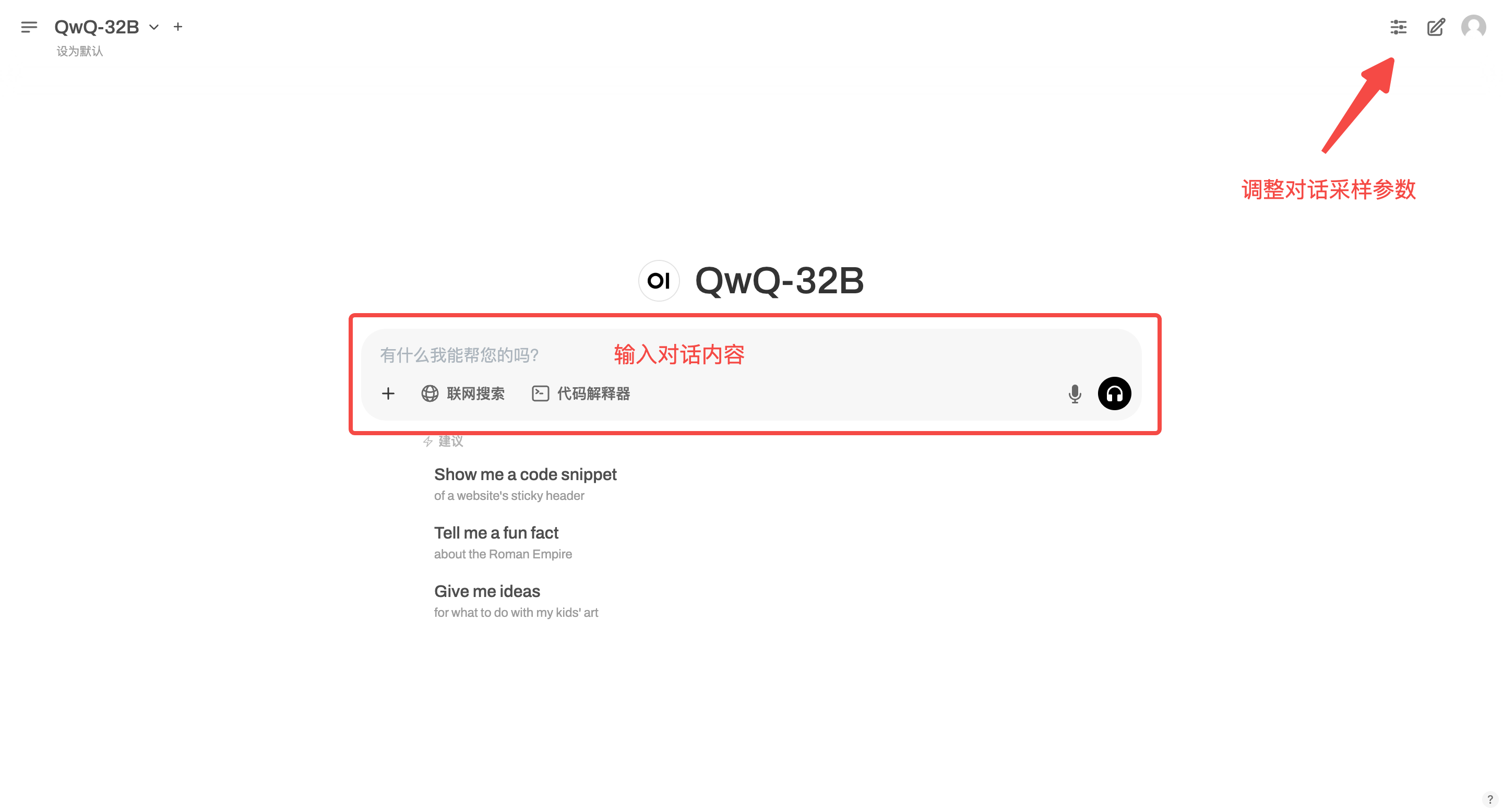
2. Web ページに入ると、モデルと会話を開始できます。
このチュートリアルは「オンライン検索」をサポートしています。この機能をオンにすると、推論速度が低下しますが、これは正常です。
交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。 
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。