HyperAI
Command Palette
Search for a command to run...
Ollama と Open WebUI を使用した DeepSeek R1 の導入
1. チュートリアルの概要
DeepSeek-R1 は、効率的で軽量な自然言語処理タスクに重点を置いて、DeepSeek が 2025 年にリリースした言語モデル シリーズの最初のバージョンです。このモデル ファミリは、知識蒸留などの高度な手法を通じて最適化されており、高いパフォーマンスを維持しながらコンピューティング リソースの要件を削減することを目的としています。 DeepSeek-R1 は、実用的なアプリケーション シナリオに重点を置いて設計されており、迅速な導入と統合をサポートし、テキスト生成、対話システム、翻訳、要約生成など、さまざまなタスクに適しています。
技術的なレベルでは、DeepSeek-R1 は知識蒸留技術を使用して大規模なモデルから知識を抽出し、同様のパフォーマンスを持つ小規模なモデルをトレーニングします。同時に、効率的な分散トレーニングと最適化アルゴリズムにより、トレーニング時間がさらに短縮され、モデル開発の効率が向上します。これらの技術的なハイライトにより、DeepSeek-R1 は実際のアプリケーションで優れたパフォーマンスを発揮します。
本教程预设 DeepSeek-R1-Distill-Qwen-1.5B 、 DeepSeek-R1-Distill-Qwen-7B 、 DeepSeek-R1-Distill-Qwen-8B 、 DeepSeek-R1-Distill-Qwen-32B 四种模型作为演示,算力资源采用「单卡 RTX4090」。
2. 操作手順
- コンテナをクローンして起動したら、API アドレスをクリックして Web インターフェイスに入ります (「Bad Gateway」と表示される場合は、モデルが初期化中であることを意味します。モデルが大きいため、5 分ほど待ってからもう一度お試しください)。
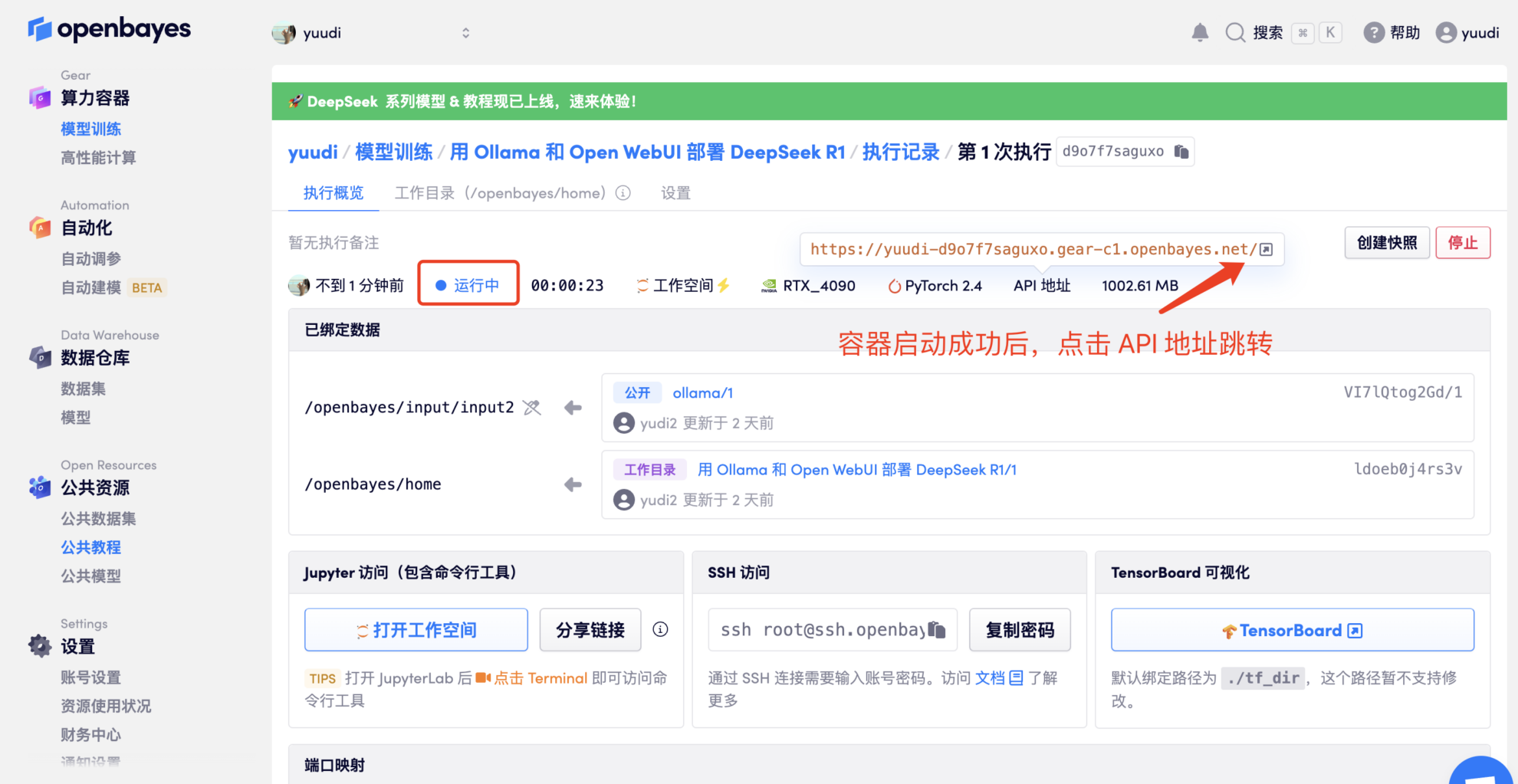
2. Web ページに入ると、モデルと会話を開始できます。
知らせ:
- このチュートリアルは「オンライン検索」をサポートしています。この機能をオンにすると、推論速度が低下しますが、これは正常です。
- インターフェースの左上隅でモデルを切り替えることができます。
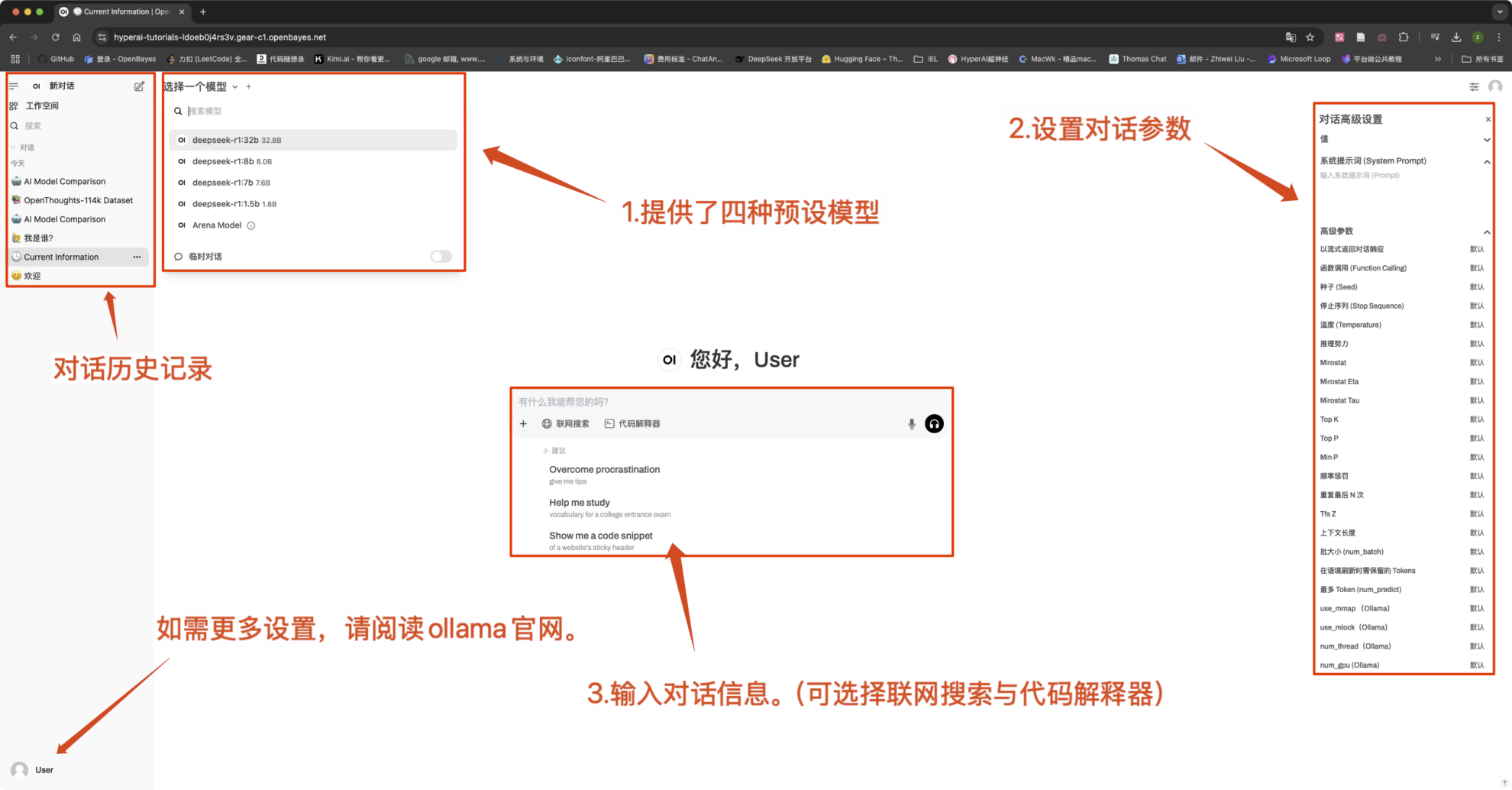
一般的な会話設定
1. 温度
- 出力のランダム性を制御します。一般的には、 0.0-2.0 間。
- 低い値(0.1など): より確実で、一般的な単語に偏っています。
- 高い値(1.5など): よりランダムで、潜在的にもっとクリエイティブだが不安定なコンテンツ。
2. トップkサンプリング
- からのみ 最も確率の高いk 確率の低い単語を除いた単語単位でのサンプリング。
- k は小さい (例: 10): 確実性は高まり、ランダム性は減少します。
- k は大きい(例:50): 多様性が増すと、革新性も高まります。
3. Top-pサンプリング(核サンプリング、Top-pサンプリング)
- 選ぶ累積確率がpに達する単語集合、k値は固定されていません。
- 低い値(0.3など): 確実性は高まり、ランダム性は減少します。
- 高い値(0.9など): 多様性が増し、流暢性が向上しました。
4. 繰り返しペナルティ
- テキストの繰り返しを制御します。通常は 1.0-2.0 間。
- 高い値(1.5など): 繰り返しを減らして読みやすさを向上します。
- 低い値(1.0など): ペナルティはありませんが、モデルが単語や文を繰り返す可能性があります。
5. 最大トークン数(最大生成長)
- 制限モデル生成されるトークンの最大数出力が長くなりすぎないようにするためです。
- 通常の範囲:50-4096(モデルによって異なります)。
交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。