Command Palette
Search for a command to run...
vLLM の使用を開始する: ステップバイステップ ガイド

目次
1. チュートリアルの概要
vLLM (Virtual Large Language Model) は、大規模言語モデルの推論を高速化するために特別に設計されたフレームワークであり、その優れた推論効率とリソース最適化機能により、世界中で広く注目を集めています。カリフォルニア大学バークレー校(UCバークレー)の研究チームは2023年に、アテンションキーとアテンション値を効果的に管理できる画期的なアテンションアルゴリズム「PagesAttention」を提案した。これに基づいて、研究者らは高スループットの分散 LLM サービス エンジン vLLM を構築しました。これにより、KV キャッシュ メモリの無駄がほぼゼロになり、大規模言語モデル推論におけるメモリ管理のボトルネック問題が解決されました。 Hugging Face Transformers と比較して、スループットは 24 倍増加し、このパフォーマンスの向上にはモデル アーキテクチャを変更する必要はありません。関連する論文結果は「PagedAttention を使用した大規模言語モデルの効率的なメモリ管理”。
このチュートリアルでは、vLLM を構成して実行する方法を段階的に示し、インストールから起動までの完全なスタート ガイドを提供します。
このチュートリアルでは使用します Qwen3-0.6B デモンストレーション用に、他のパラメータ量を持つモデルも提供されています。
2.vLLMのインストール
このプラットフォームは完成しました vllm==0.8.5 インストール。プラットフォームで作業している場合は、この手順をスキップしてください。ローカルに展開している場合は、以下の手順に従ってインストールしてください。
vLLM のインストールは非常に簡単です。
pip install vllmvLLM は CUDA 12.4 でコンパイルされているため、マシンでそのバージョンの CUDA が実行されていることを確認する必要があります。
CUDA のバージョンを確認するには、次のコマンドを実行します。
nvcc --versionCUDA バージョンが 12.4 でない場合は、現在の CUDA バージョンと互換性のある vLLM のバージョンをインストールするか (詳細についてはインストール手順を参照)、CUDA 12.4 をインストールします。
3. 使用を開始する
3.1 モデルの準備
方法 1: プラットフォームのパブリック モデルを使用する
まず、プラットフォームのパブリック モデルがすでに存在するかどうかを確認できます。モデルがパブリック リポジトリにアップロードされている場合は、それを直接使用できます。見つからない場合は、方法2を参照してダウンロードしてください。
たとえば、プラットフォームには次の情報が保存されています。 Qwen3 シリーズモデル。モデルをバインドする手順は次のとおりです(このチュートリアルでは既にこのモデルがバインドされています)。
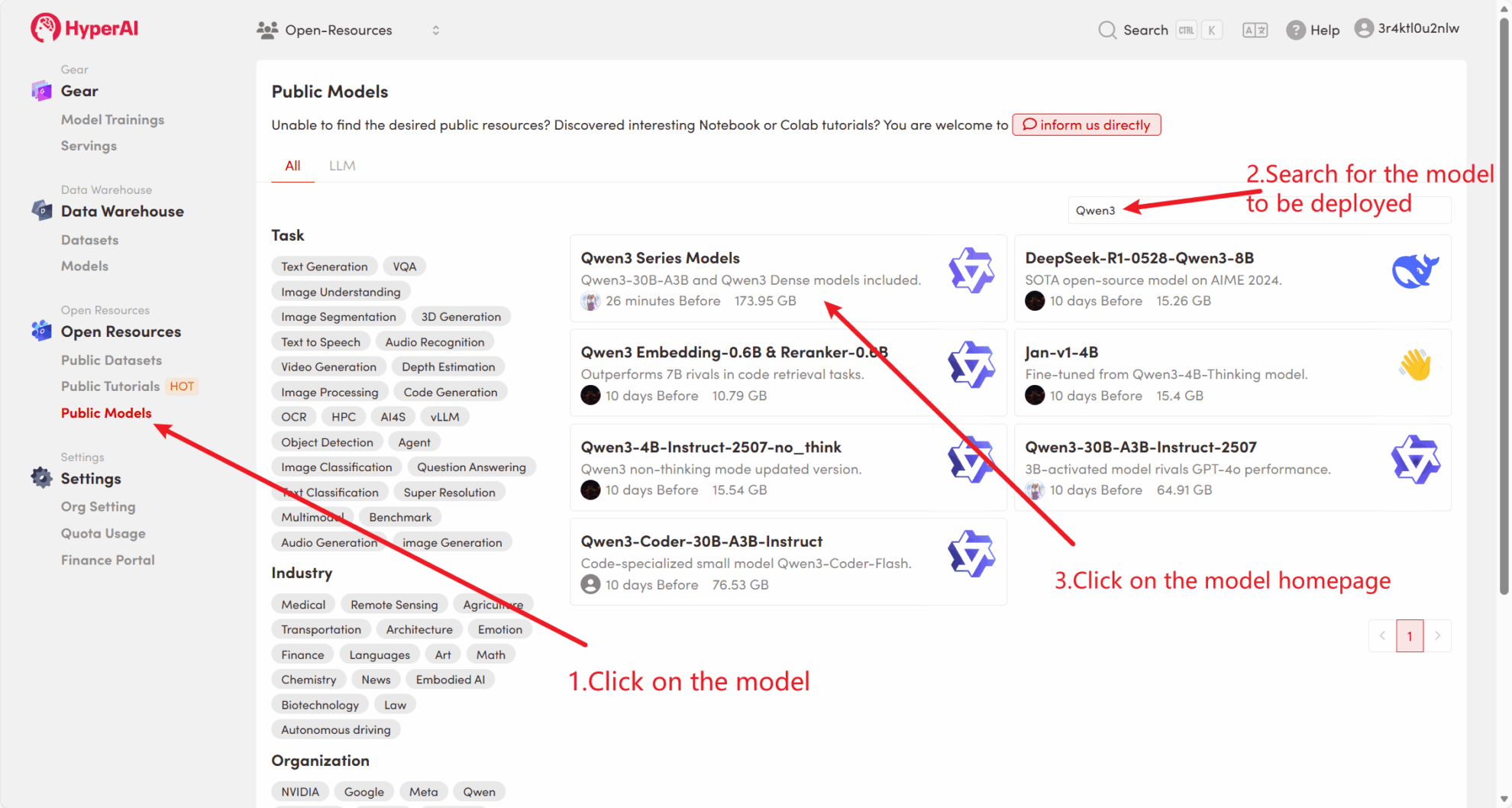
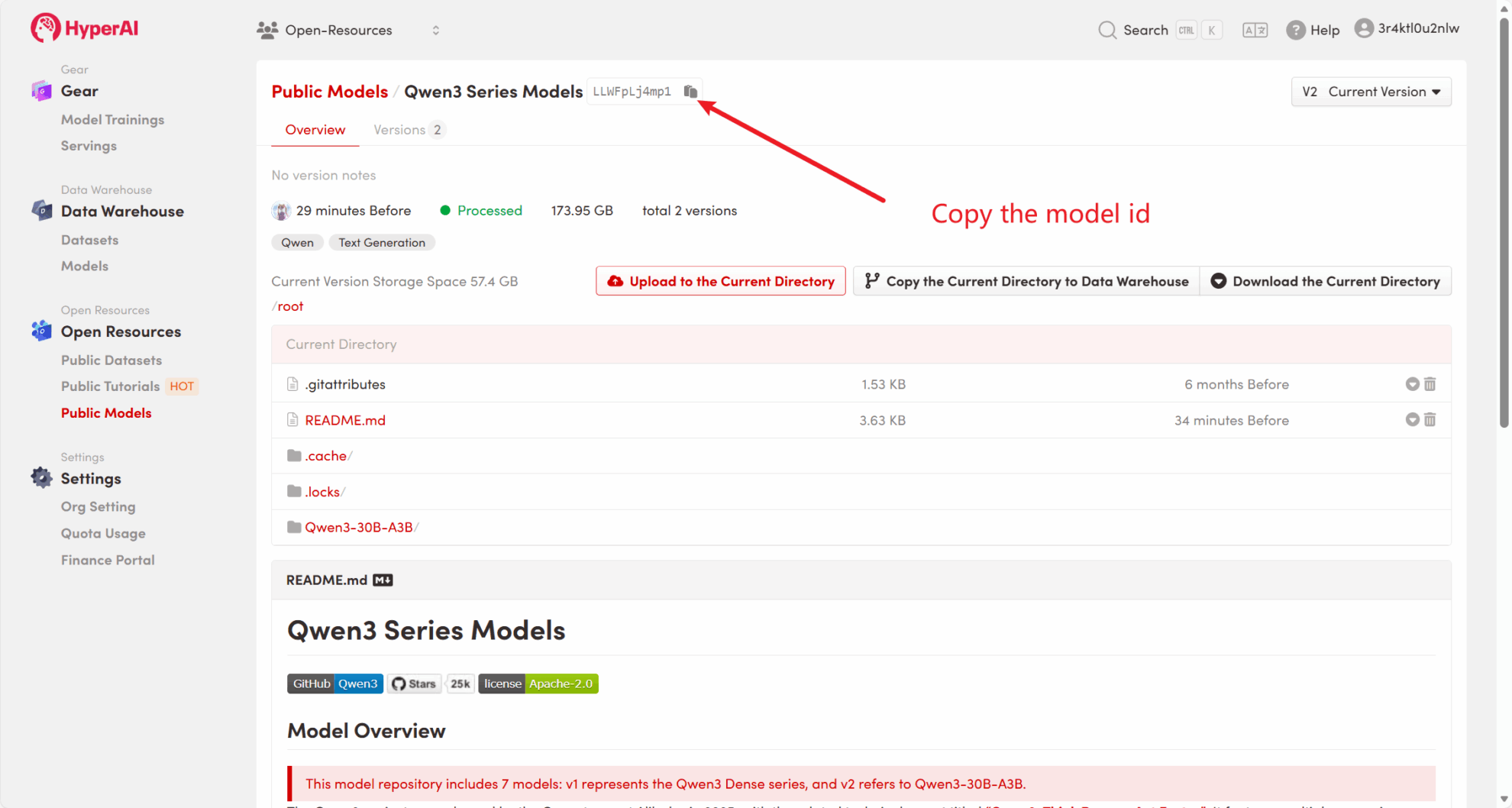
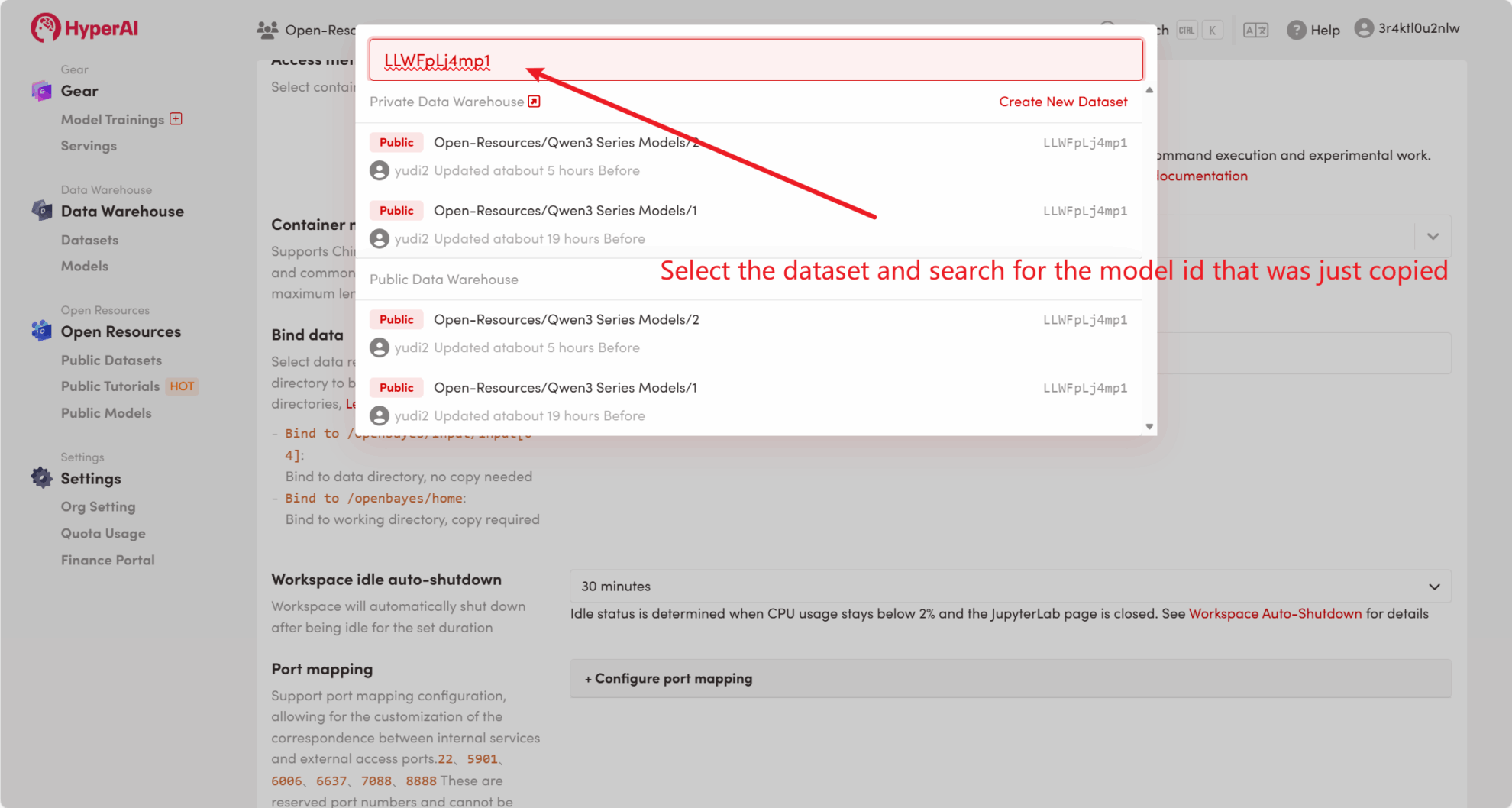
方法 2: HuggingFace からダウンロードするか、カスタマー サービスに連絡してプラットフォームへのアップロードのサポートを受けてください。
vLLM でサポートされているモデルのリストについては、次の公式ドキュメントを参照してください。 vllm でサポートされるモデル 。
huggingface-cli を使用してモデルをダウンロードするには、以下の手順に従ってください。
huggingface-cli download --resume-download Qwen/Qwen3-0.6B --local-dir ./input03.2 オフライン推論
オープンソース プロジェクトとして、vLLM は Python API を通じて LLM 推論を実行できます。以下は簡単な例です。コードを次のように保存してください。 offline_infer.py 書類:
from vllm import LLM, SamplingParams
# 输入几个问题
prompts = [
「こんにちは、あなたは誰ですか?」、「フランスの首都はどこですか?」,]
# 设置初始化采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 加载模型,确保路径正确
llm = LLM(model="/input1/Qwen3-0.6B/", trust_remote_code=True, max_model_len=4096)
# 展示输出结果
outputs = llm.generate(prompts, sampling_params)
# 打印输出结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
次に、スクリプトを実行します。
python offline_infer.pyモデルがロードされると、次の出力が表示されます。

4. vLLMサーバーを起動します。
vLLM を使用してオンライン サービスを提供するには、OpenAI API 互換サーバーを起動できます。起動に成功すると、デプロイされたモデルを GPT と同様に使用できます。
4.1 主なパラメータの設定
以下は、vLLM サーバーを起動するときに一般的に使用されるパラメーターの一部です。
--model: 使用する HuggingFace モデル名またはパス (デフォルト:facebook/opt-125m)。--hostそして--port:サーバーアドレスとポートを指定します。--dtype:モデルの重みとアクティベーションの精密タイプ。可能な値:auto、half、float16、bfloat16、float、float32。デフォルト値:auto。--tokenizer: 使用する HuggingFace タガーの名前またはパス。指定しない場合、デフォルトでモデル名またはパスが使用されます。--max-num-seqs: 反復ごとのシーケンスの最大数。--max-model-len: モデルのコンテキスト長。デフォルト値はモデル設定から自動的に取得されます。--tensor-parallel-size、-tp: テンソルの並列コピーの数 (GPU の場合)。デフォルト値:1。--distributed-executor-backend=ray: 分散サービスのバックエンドを指定します。可能な値は次のとおりです。ray、mp。デフォルト値:ray(複数の GPU を使用する場合、自動的に に設定されます)ray)。
4.2 コマンドラインの起動
OpenAI APIインターフェースと互換性のあるサーバーを作成します。次のコマンドを実行してサーバーを起動します。
python3 -m vllm.entrypoints.openai.api_server --model /input1/Qwen3-0.6B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-code正常に起動すると、次のような出力が表示されます。

vLLM は、OpenAI API プロトコルを実装するサーバーとしてデプロイできるようになり、デフォルトで http://localhost:8080 サーバーを起動します。合格できます --host そして --port パラメータは他のアドレスを指定します。
5. リクエストをする
このチュートリアルで起動する API アドレスは次のとおりです。 http://localhost:8080, このアドレスにアクセスすることでAPIを利用することができます。 localhost プラットフォームネイティブを指します。8080 API サービスがリッスンするポート番号です。
次の図に示すように、ワークスペースの右側で、API アドレスがローカル 8080 サービスに転送され、実際のホストを通じてリクエストできます。
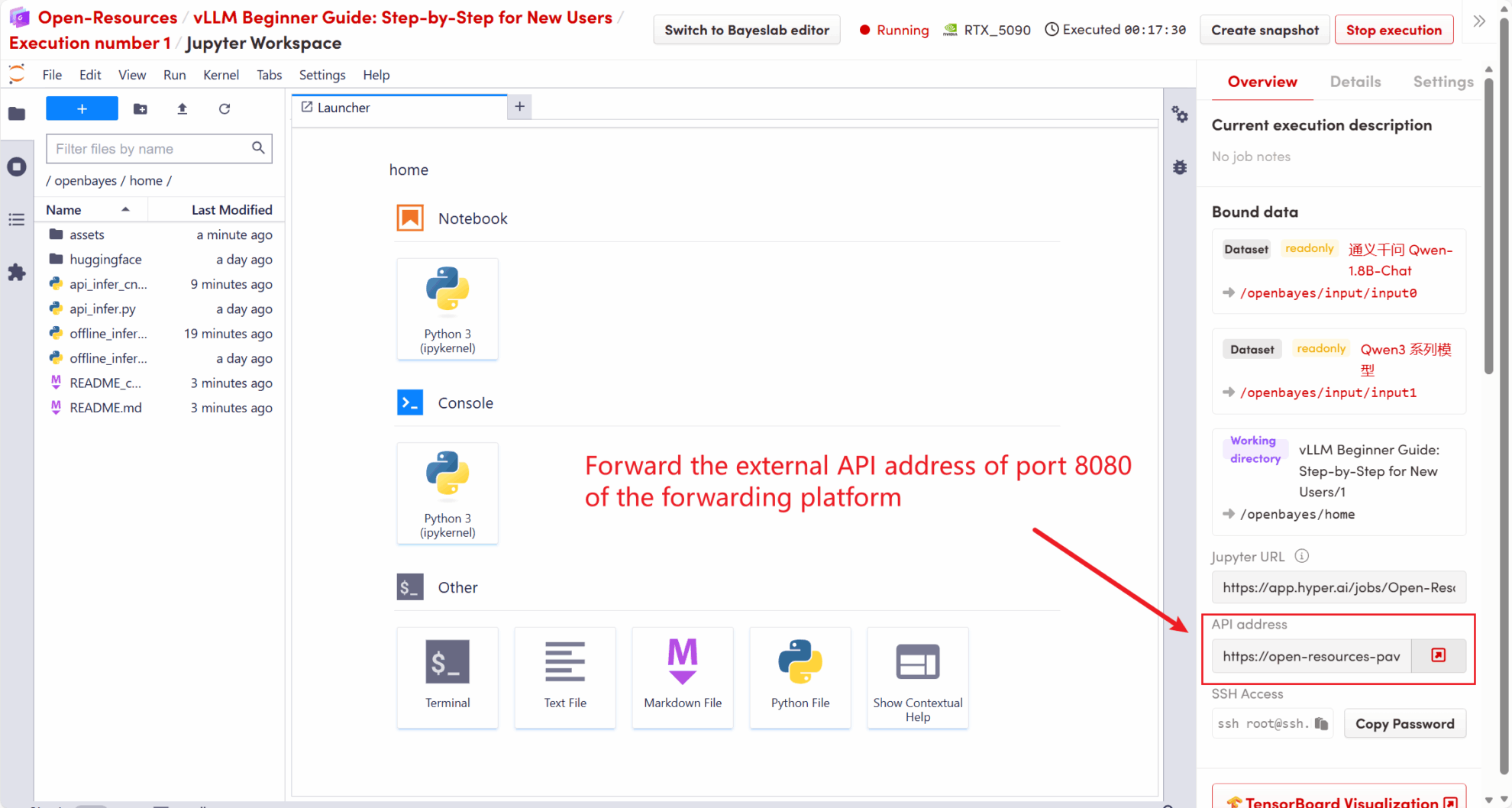
5.1 OpenAIクライアントの使用
手順 4 で vLLM サービスを開始した後、OpenAI クライアントを通じて API を呼び出すことができます。簡単な例を次に示します。
# 注意:请先安装 openai
# pip install openai
from openai import OpenAI
# 设置 OpenAI API 密钥和 API 基础地址
openai_api_key = "EMPTY" # 请替换为您的 API 密钥
openai_api_base = "http://localhost:8080/v1" # 本地服务地址
client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)
models = client.models.list()
model = models.data[0].id
prompt = "Describe the autumn in Beijing"
# Completion API 调用
completion
= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")コマンドを実行します:
python api_infer.py次の出力が表示されます。

5.2 Curl コマンドを使用してリクエストする
次のコマンドを使用してリクエストを直接送信することもできます。プラットフォームでアクセスしたら、次のコマンドを入力します。
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 512
}'次のような応答が返されます。

OpenBayes プラットフォームを使用している場合は、次のコマンドを入力します。
curl https://hyperai-tutorials-8tozg9y9ref9.gear-c1.openbayes.net/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/input1/Qwen3-0.6B/",
"prompt": "Describe the autumn in Beijing", "max_tokens": 128
}'応答結果は次のとおりです。
