Command Palette
Search for a command to run...
Whisper-large-v3-turbo 音声認識と翻訳のデモ

1. チュートリアルの概要
Whisper は汎用の音声認識モデルです。大規模で多様な音声データセットでトレーニングされており、多言語音声認識や音声翻訳などのマルチタスク。
- 多言語音声認識: 音声内の言語を自動的に認識し、元の音声内の言語に変換して出力します。
- 言語翻訳: 認識に基づいて、言語を中国語 (デフォルト) に翻訳して出力します。
2024 年 10 月 1 日に開催された DevDay イベントで、OpenAI は、品質をほとんど損なうことなく、合計 8 億 900 万個のパラメーターを備えた Whisper ラージ v3 ターボ音声文字起こしモデルのリリースを発表しました。Large-v3 よりも 8 倍高速
Whisper Large-v3-turbo 音声転写モデルは、large-v3 の最適化されたバージョンであり、デコーダー層 (デコーダー層) が 4 つしかありません。これに対し、large-v3 には合計 32 層があります。モデルシェア 8億900万のパラメータ、7 億 6,900 万のパラメータを持つ中型モデルよりわずかに大きいですが、15 億 5,000 万のパラメータを持つ大規模モデルよりははるかに小さいです。また、必要な VRAM は 6 GB ですが、大型モデルでは 10 GB が必要です。
2. 操作手順
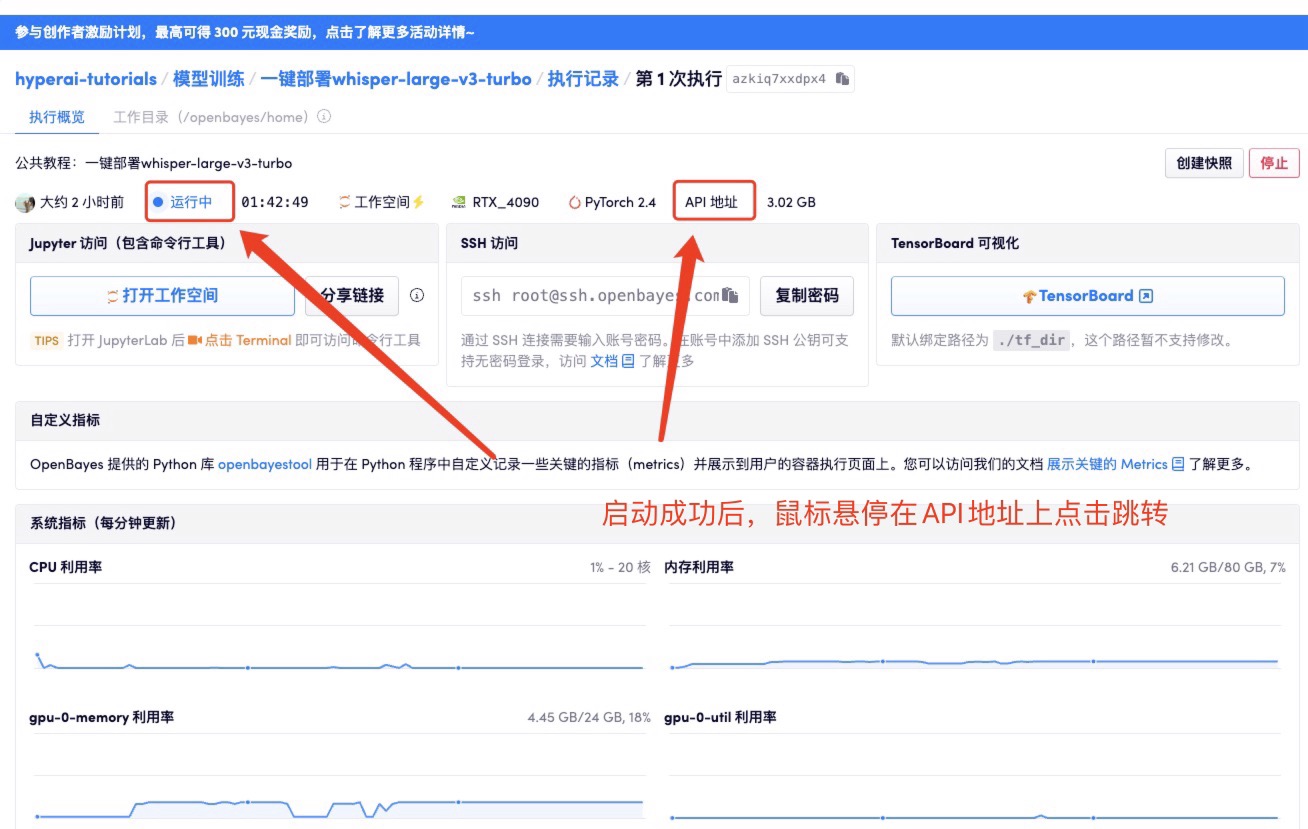
コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
音声認識 (transcribe) または翻訳 (translate) のための 3 つの関数を提供します。
- マイクはデバイスを直接使用してリアルタイム録音します
- オーディオ ファイルのアップロード オフライン オーディオ
- YouTubeオンラインビデオ
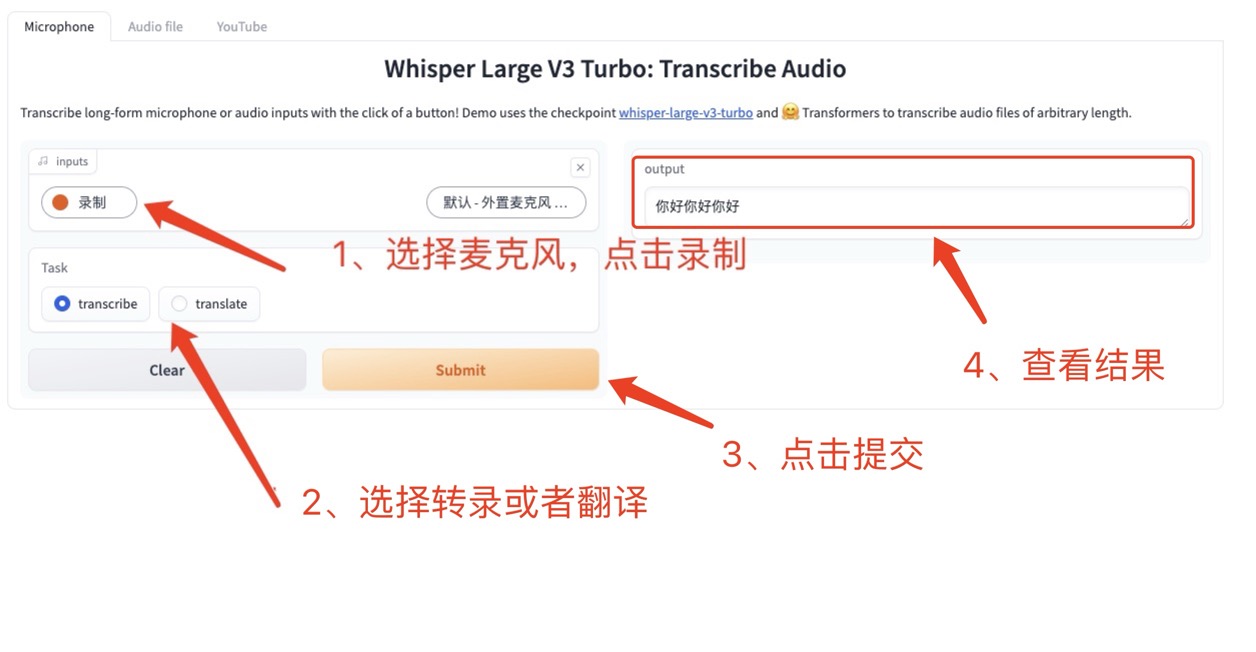
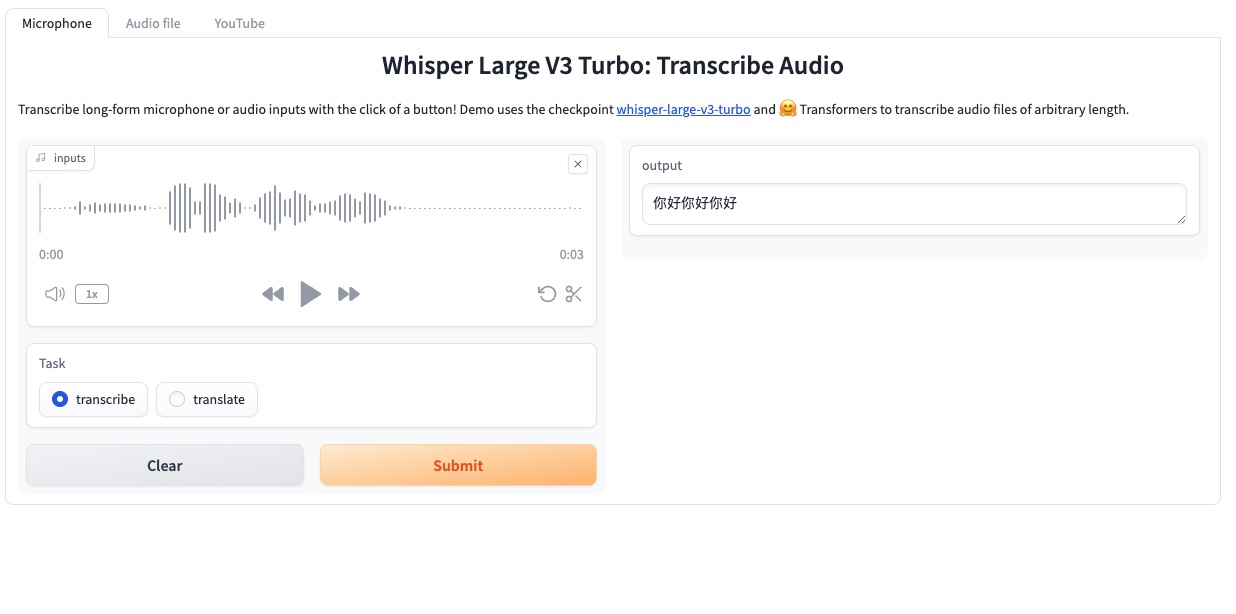
1. マイクはデバイスを直接使用してリアルタイム録音します
クリック マイク (デフォルト)、デバイスのマイクを使用して音声を録音すると、録音が完了すると音声がプラットフォームにアップロードされ、文字起こしまたは翻訳を選択して、[送信] をクリックして指定したテキストを生成します。 (モデルのパフォーマンス上の理由により、不正確な翻訳が発生する可能性があります)
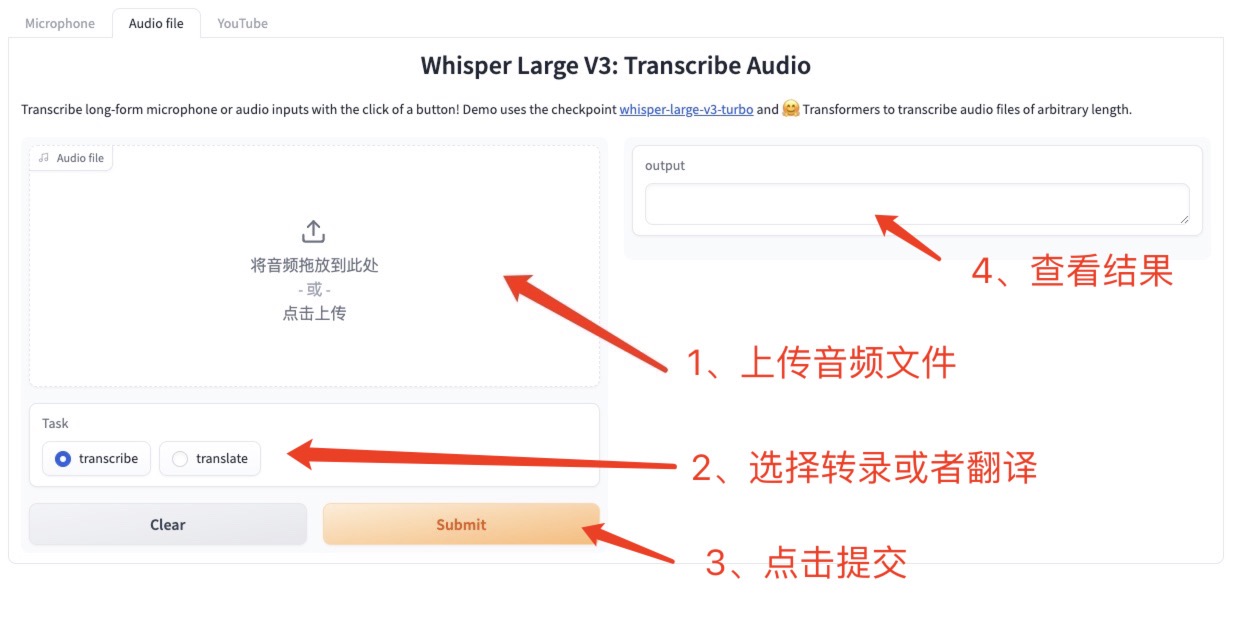
2. オーディオファイルのアップロードオフラインオーディオ
クリック 音声ファイル、実行する音声をインターフェースにアップロードまたはドラッグし、文字起こしまたは翻訳を選択して、「送信」をクリックして指定したテキストを生成します。
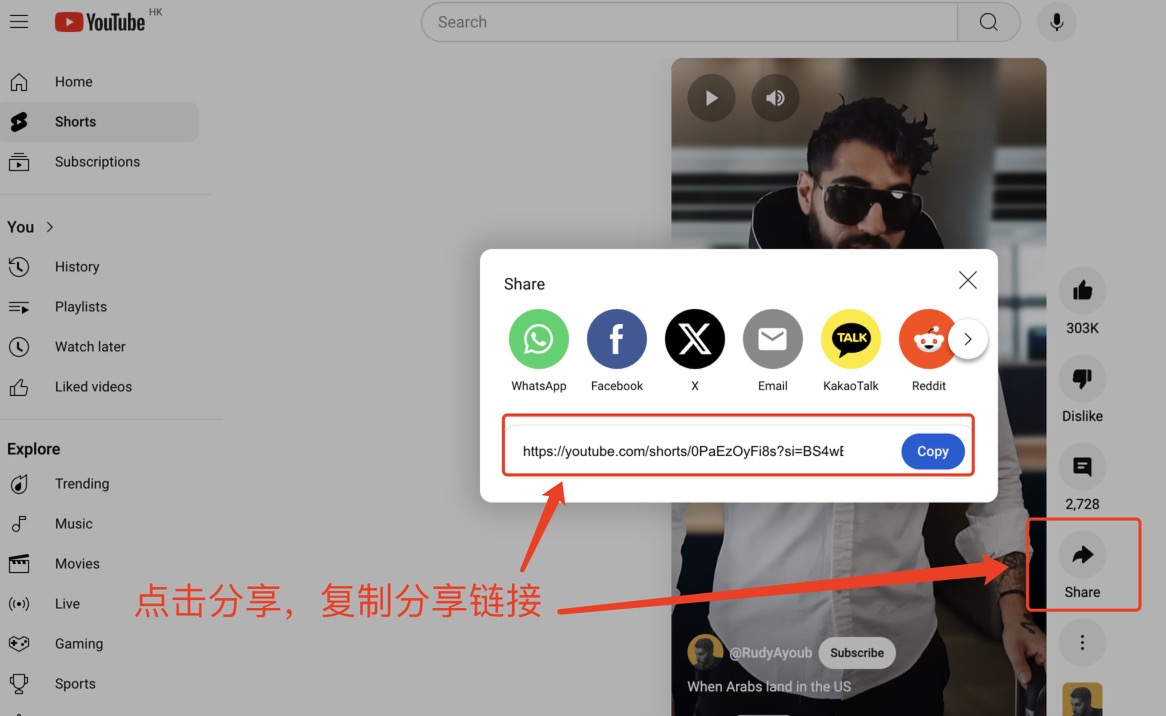
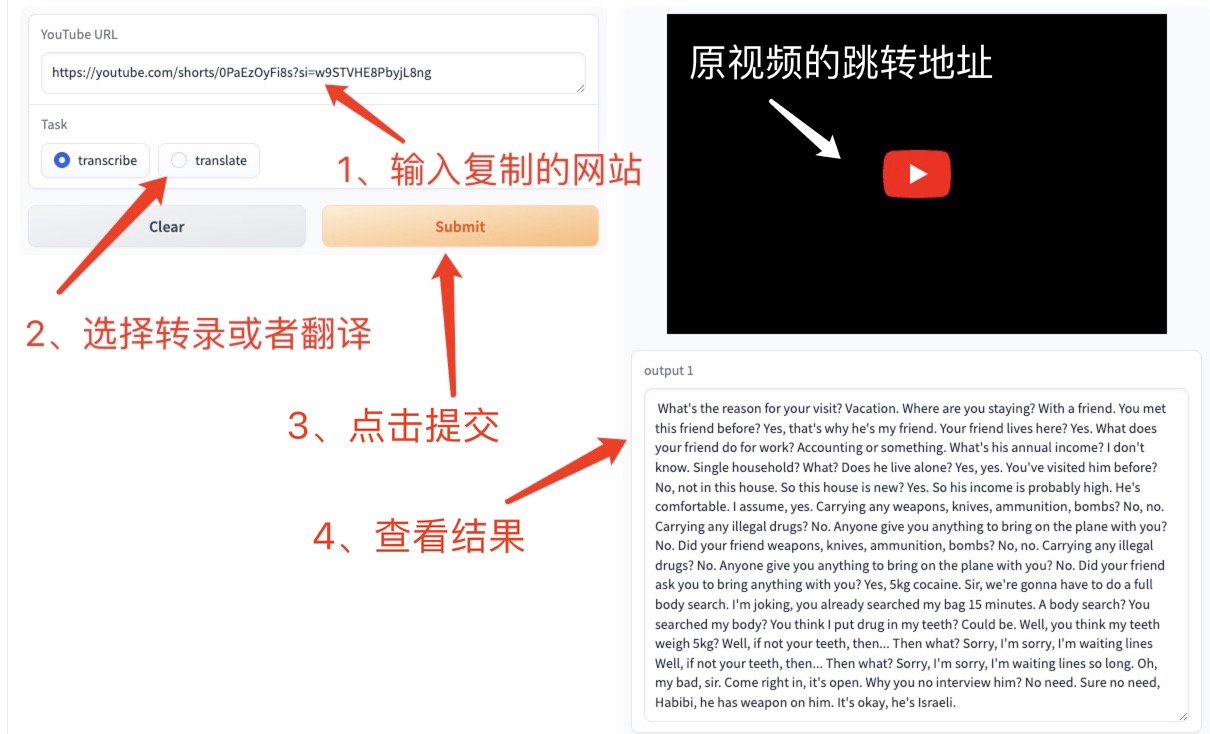
3. YouTube オンラインビデオ (ネットワークの問題により、認識されない可能性があり、複数回試行する必要があります。デモは参考用です)
Youtube Web ページを参照して必要なビデオを見つけ、右側の [共有] をクリックすると、この URL が Web ページ上のテキスト ボックスにコピーされます。 YouTubeのURL をクリックし、「文字起こし」または「翻訳」を選択し、「送信」をクリックして指定したテキストを生成します。
交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。
