HyperAI
Command Palette
Search for a command to run...
GOT-OCR-2.0 世界初のユニバーサルエンドツーエンドOCRモデル

プロジェクト紹介
GOT-OCR-2.0 これは、光学式文字認識(OCR)の精度と効率の向上に焦点を当てた、汎用OCR理論に基づく統合エンドツーエンドモデルです。このプロジェクトは、StepFun、Megvii Technology、中国科学院大学、清華大学の研究チームによって共同で発表され、関連論文は以下の通りです。 一般的な OCR 理論: 統合されたエンドツーエンド モデルによる OCR-2.0 に向けてシーンテキスト認識や文書認識など、様々なアプリケーションシナリオに適しています。統合アーキテクチャを採用し、テキストの多様性と複雑性を効率的に処理できます。GOT-OCR 2.0は、シーンテキスト認識だけでなく、複数ページの文書にも対応しており、OCR分野にさらなる柔軟性をもたらします。
GOT-OCR-2.0 特徴は次のとおりです。
- 強力な汎用性: 普遍的な OCR 理論に基づいて、シーンのテキストや表、数式などの複雑な文書構造を処理できます。
- エンドツーエンド モデル: 統合されたエンドツーエンド アーキテクチャにより、画像入力からテキスト出力までを統合する OCR プロセス全体が簡素化されます。
- 効率的なパフォーマンス: 統合された Flash-Attendant テクノロジーにより、認識速度とパフォーマンスが向上します。
- マルチプラットフォームのサポート: CUDA アクセラレーションをサポートし、GOT-OCR2.0 プラットフォームと統合し、事前トレーニングされたモデルをロードできます。
- 幅広いアプリケーション: 複数ページのドキュメントやシーンテキストなど、幅広いアプリケーションシナリオに適しています。
エフェクト例
 |
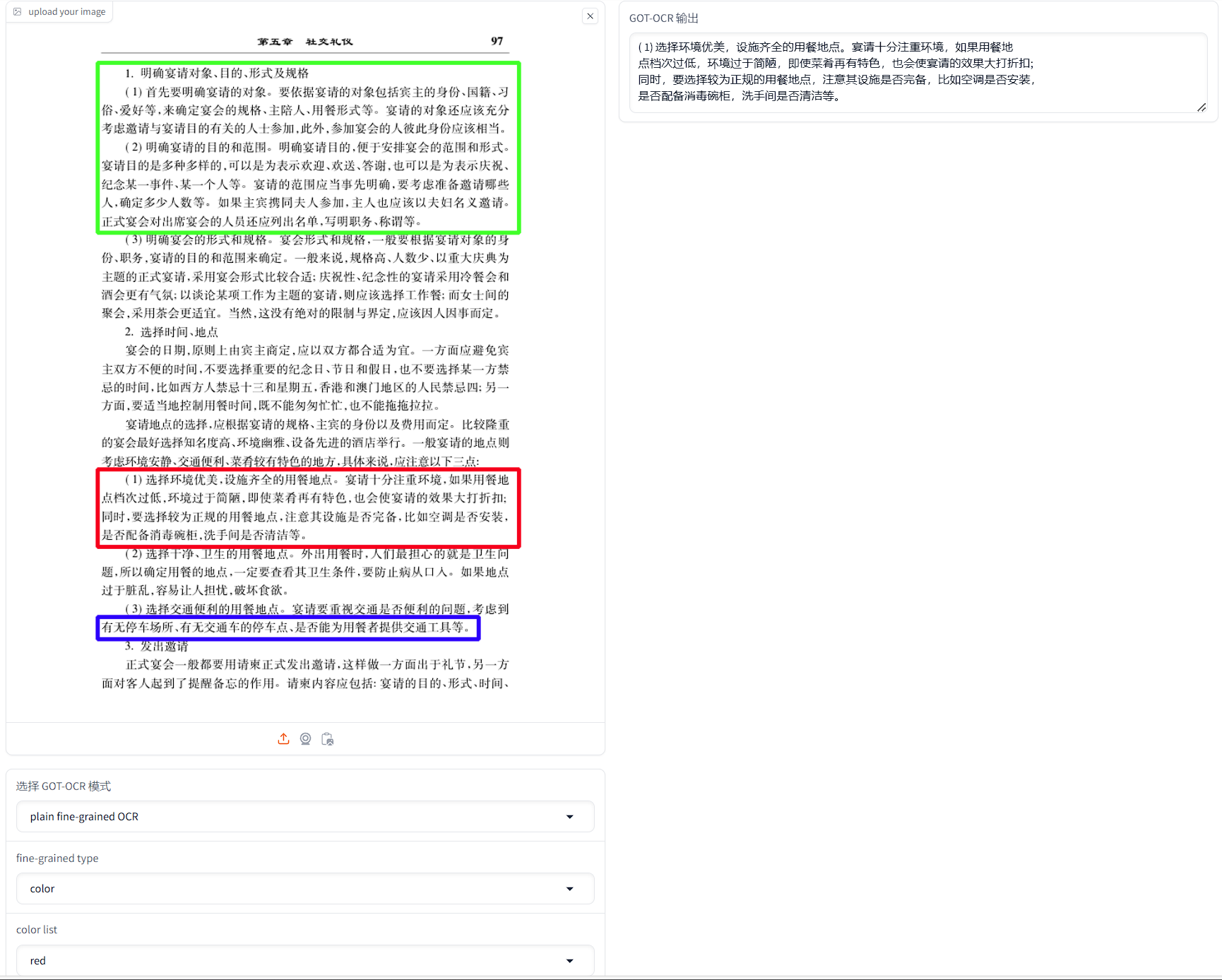 |
ステップの実行
1. プロジェクトの右上隅にある [クローン] をクリックし、[次へ] をクリックして完了します。 [基本情報] > [計算能力の選択] > [確認]。最後に、「続行」をクリックして、個人コンテナでプロジェクトを開きます。
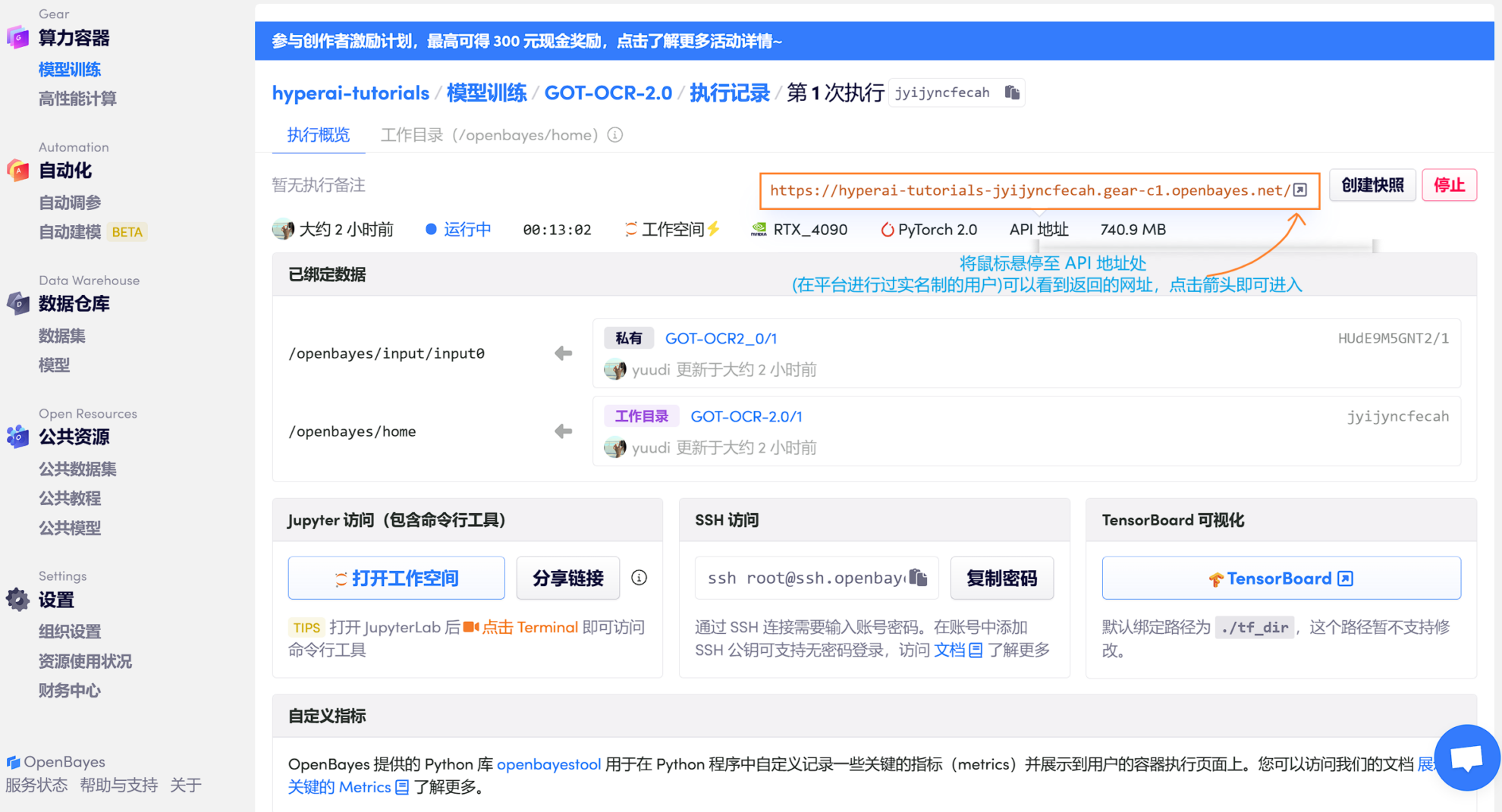
2. リソースの割り当てが完了すると、バックグラウンドでモデルが自動的に初期化され ()、プラットフォームが提供する API アドレスを直接使用して操作ページにアクセスできます (実名認証が完了する必要があり、認証はありません)。このステップのためにワークスペースを開く必要があります)
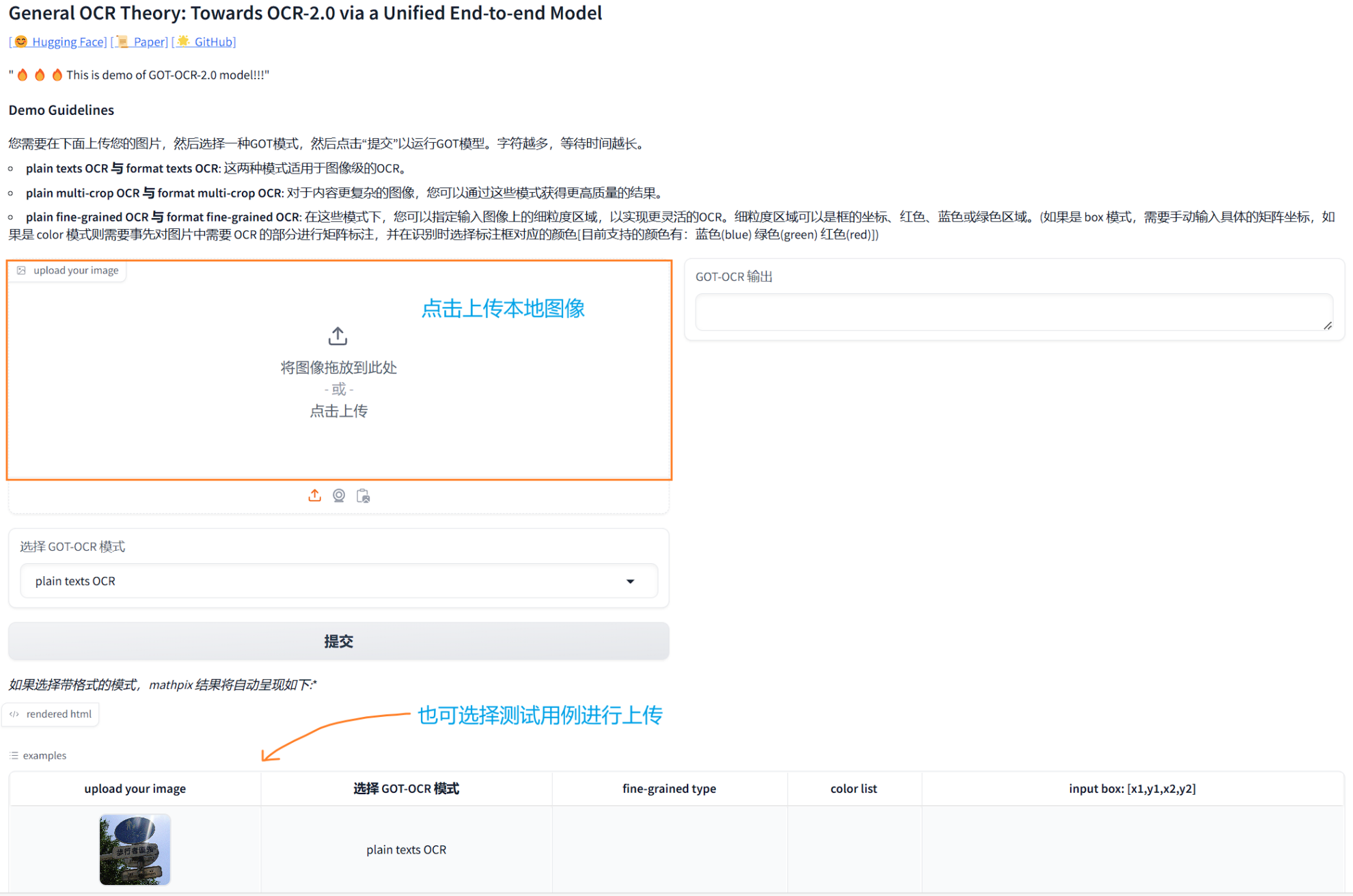
3.対象画像をアップロードする
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。