HyperAI
Command Palette
Search for a command to run...
Fish Speech v1.4 サウンド クローンテキスト読み上げツールのデモ
チュートリアルの紹介

Fish Speech の主な機能には、テキスト読み上げ、多言語サポート、音声カスタマイズ、高品質サウンド ライブラリ、無料のオープン ソースが含まれます。コンテンツ制作、教育、カスタマーサービス、補助ツールなど、さまざまなシーンに適しています。このモデルは API 統合とモデルの微調整のサポートも提供し、ユーザーが独自のニーズに応じてカスタマイズおよび最適化できるようにします。
最新バージョン 1.4 では、多言語サポートとパフォーマンスが大幅に向上し、トレーニング データの量が 700,000 時間に倍増しました。は、英語、中国語、ドイツ語、日本語、フランス語、スペイン語、韓国語、アラビア語を含む 8 つの主要言語をサポートしています。新しいバージョンでは、インスタント音声クローン機能も導入されており、ユーザーが特定の音声スタイルをすばやくコピーできるようになり、柔軟な展開オプションと API サービスが提供されます。
このチュートリアルでは、モデルと環境をデプロイしました。チュートリアルのガイドラインに従って、音声のクローン作成またはテキスト読み上げタスクを直接実行できます。
実行メソッド
1. 首先克隆容器, 按步骤启动容器
2. 复制生成的 API 地址到浏览器即可使用
3. 该教程主要包含 2 个功能:文本转语音和声音克隆
3.1 文本转语音:在「Input Text」输入生成的文本,点击「Generate」即可生成结果

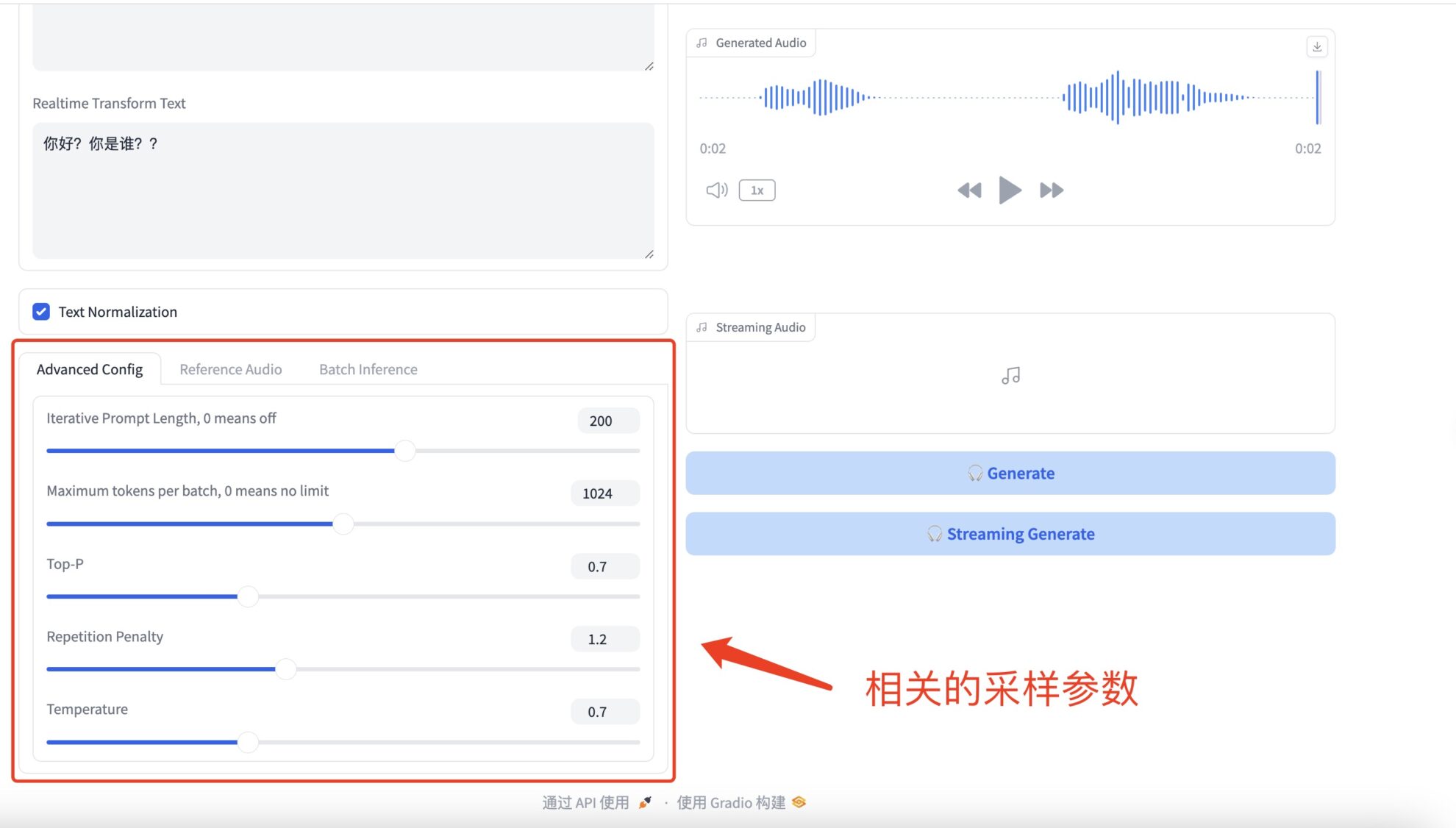
* Advanced Configs
相关的采样参数具体如下:
- 反復プロンプトの長さ: モデルがテキストを生成するときに考慮する前のテキストの長さを指します。ゼロ以外の値に設定すると、モデルは、指定された数の最近の単語またはトークンを各生成ステップのコンテキストとして考慮します。 0 に設定すると、この機能はオフになり、モデルは利用可能なすべてのコンテキストを考慮するか、他のパラメーター (モデル ウィンドウ サイズなど) に基づいてコンテキストの長さを決定します。
- バッチあたりの最大トークンは、モデルが各バッチで生成できるトークンの最大数を制限します。マーカーは通常、単語、句読点などを指します。 0 に設定すると、制限がなく、モデルは必要に応じて、またはモデルの内部最大長制限に達するまで、任意の長さのテキストを生成します。
- Top-P (カーネル サンプリングまたは確率サンプリングとも呼ばれる) は、新しい単語を生成するときに、モデルは累積確率が P より大きい最小の単語セットのみを考慮します。これは、モデルがこのセットから次の単語をランダムに選択し、確率の低い無関係な単語の生成を回避しながら、生成されるテキストの多様性を高めることを意味します。
- 反復ペナルティは、生成されたテキスト内の重複コンテンツを減らすために使用されます。モデルがすでに生成された単語やフレーズを繰り返す傾向がある場合、このパラメーターを適用すると、これらの単語が選択される確率が低下する可能性があります。これは、モデルが別の単語を選択するように、すでに生成された単語の確率スコアを調整 (通常は下げる) することで行われます。
- 温度は、生成されるテキストのランダム性を制御します。
3.2 声音克隆:选择「Reference Audio」并点击「Enable Reference Audio」,
上传「Reference Audio(参考音频)」,以及「Reference Text(参考文本)」,在「Input Text」输入生成的文本,点击「Generate」即可生成声音克隆结果

4. 其他参数说明
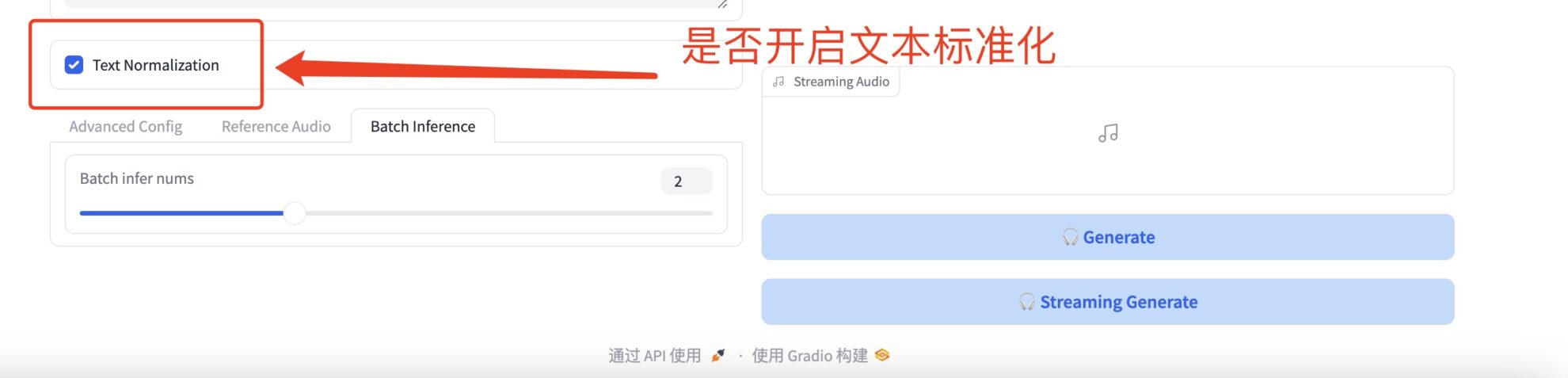
* Text Normalization
是否开启文本标准化(例如日期、固话、金钱等等)
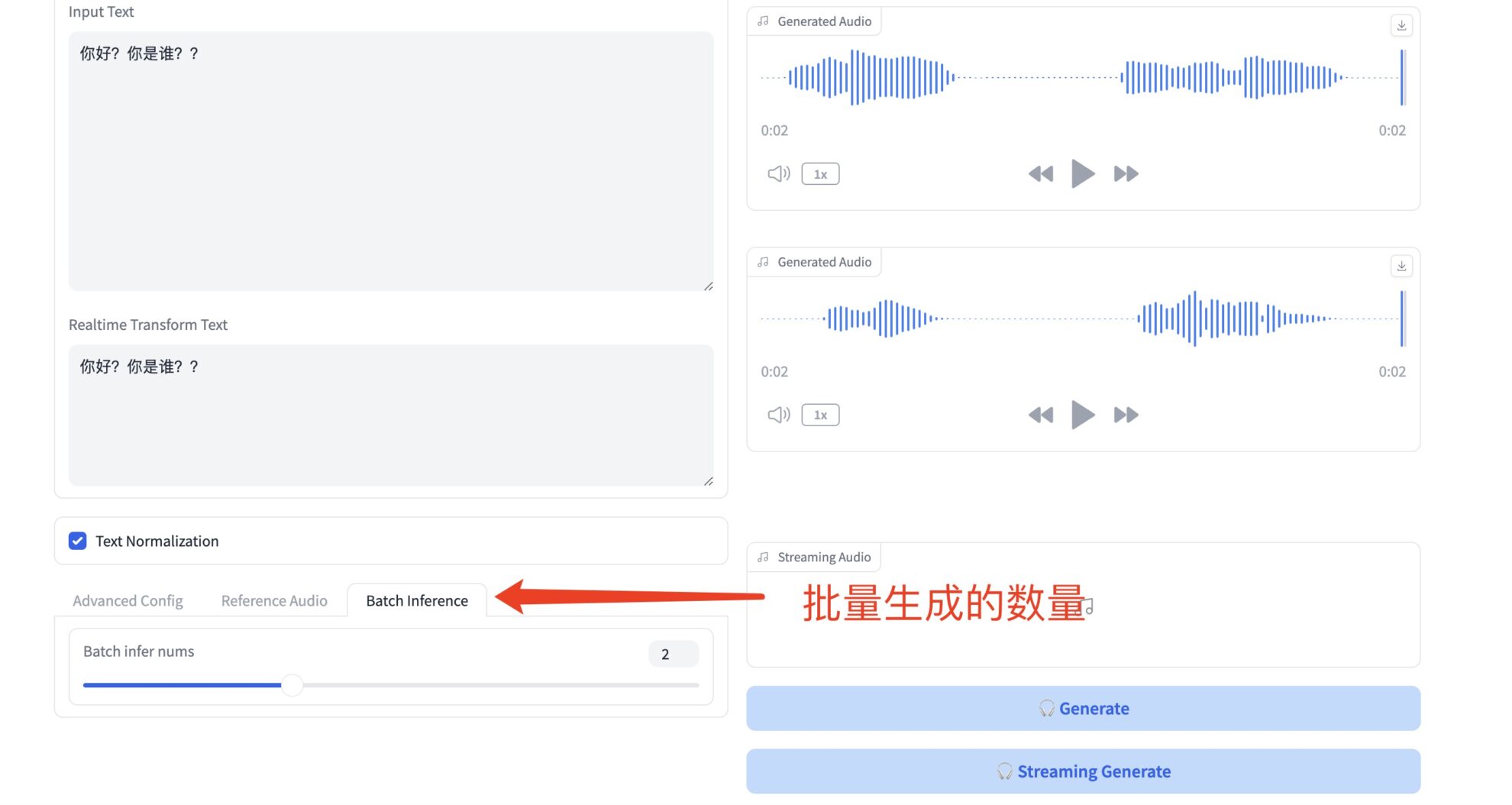
* Batch Inference
设置生成语音数量
交流とディスカッション
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【教程交流】入群探讨各类技术问题、分享应用效果↓

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。